

ICML 2025 | 自回归OUT!TokenSwift实现无损3倍加速,超长文本也能飞起来
前言 生成超长文本的背后,却隐藏着令人咋舌的计算成本 —— 长时间的等待、巨大的内存负担以及偶尔重复乏味的输出,严重制约了这些模型的真正潜力。面对这一挑战,BIGAI NLCo 团队提出了一项全新的推理加速框架 —— TokenSwift,该工作已成功被 ICML 2025正式接收!
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
本文转载自PaperWeekly
仅用于学术分享,若侵权请联系删除
招聘高光谱图像、语义分割、diffusion等方向论文指导老师
在这项研究中提出了一套可插拔、无损、高效的生成加速策略,专为 100K Token 级别的长文本推理而设计。在保持原始模型输出一致性的前提下,加速比达到 3 倍以上,极大提升了推理效率。

论文标题:
From Hours to Minutes: Lossless Acceleration of Ultra Long Sequence Generation up to 100K Tokens
论文地址:
https://arxiv.org/abs/2502.18890
Blog 地址:
https://bigai-nlco.github.io/TokenSwift/
Github 地址:
https://github.com/bigai-nlco/TokenSwift

重新定义超长生成:为什么传统方法「慢」?
为了更好地理解 TokenSwift 的意义,我们先看一下目前主流大模型(如 LLaMA、Qwen 等)在长文本生成中的瓶颈所在。
尽管这些模型具备了强大的生成长上下文的能力,但大多数依然采用传统的自回归(Autoregressive)生成方式——每次仅生成一个新的 Token,并以其作为输入接着生成下一个。这种方式本身在短文本生成中问题不大,但当序列长度扩展至 10 万甚至更多时,性能就会急剧下降。
主要原因有三:
- 模型重复重载:每生成一个 Token,都会触发一次完整的前向推理过程;在多进程或流水线执行时,模型需要不断读取参数,造成 I/O 瓶颈。
- KV 缓存无限膨胀:Transformer 架构要求保留所有历史 Token 的 Key/Value 信息,用于后续 Token 的注意力计算。随着生成进程推进,KV 缓存占用不断增加,导致计算与内存开销雪上加霜。
- 语义重复堆叠:生成越长,模型越容易陷入句式与主题的复读循环,降低输出多样性与用户体验。
尤其在当前日益增长的多轮对话、大模型代理(Agent)、逐步推理等任务中,一个 Query 可能会触发几千甚至上万的推理 Token 输出。传统自回归的效率显然已经难以满足需求。

TokenSwift:拥抱并行的超长推理时代
TokenSwift 的提出,正是为了解决上述超长生成中的三大瓶颈。它通过一个极为轻量且高效的框架,对传统自回归推理进行了「重构」,提出了以「多 Token 草拟 + 并行验证 + 动态缓存更新」 为核心的全新机制。
让我们来逐步拆解 TokenSwift 的关键技术理念:
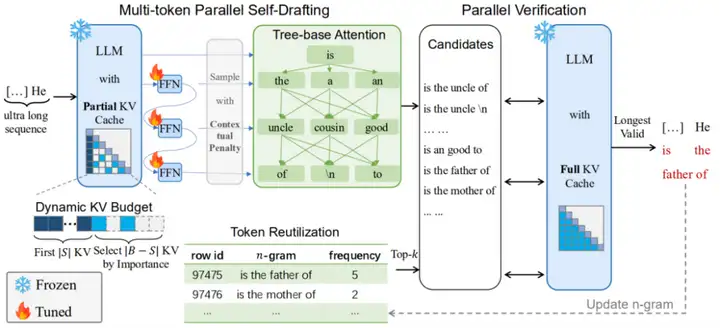

多Token并行草拟:告别一次一Token的低效时代
在 TokenSwift 中,不再坚持 「一步一 Token」 的生成模式,而是通过对已有模型的最小化修改(添加极少量的线性层),实现了「一次性草拟多个 Token」。
这意味着,模型每一次前向传播,都可以并行生成 γ 个候选 Token,大幅降低模型重载频率,显著节省 I/O 时间。
更关键的是,草拟阶段并非 「胡乱猜测」。引入了上下文引导机制,使草拟结果具备较高的语义相关性与语法一致性,随后通过结构化的验证机制确保其与标准 AR 路径一致。

n-gram启发式补全:巧用历史片段,精确草拟结构
为了避免粗略草拟带来的语义偏离,TokenSwift 设计了基于历史生成内容的 n-gram 片段缓存机制。会定期保存频率较高的 n-gram 序列,并在草拟新 Token 时,借助这些高频片段进行 「自动补全」。
此外,TokenSwift 还引入了 「随机筛选器」,在多个 n-gram 片段中选择语义最优的一组进行结构构建。这不仅提升了草拟的准确性,也保证了后续验证的成功率。

树结构验证机制:确保与AR一致,输出「无损」保障
有了草拟机制,还需要验证其 「正当性」。TokenSwift 的另一大亮点在于提出了树结构的并行验证模块,通过构建多个验证路径,对草拟的多个 Token 并行进行预测评分判断,并筛选出与标准 AR 路径一致的候选。
换句话说,TokenSwift 不仅快,而且不牺牲任何输出质量,生成内容与原始模型保持一致,是一套真正 「无损」 的加速方案。

动态KV管理 + 重复惩罚:越长越快,越长越优
为了解决 KV 缓存膨胀的问题,TokenSwift 实现了动态的 KV 裁剪机制。模型会根据 Token 重要度与时间衰减策略,对 KV 对进行 「主动淘汰」,在保证上下文保留质量的同时,显著减轻缓存负担。
与此同时,为了缓解长文本生成过程中的重复问题,设计了重复惩罚机制,在生成过程中动态降低重复 n-gram 的概率,确保最终输出具备更高的多样性和可读性。

实验评估:全面剖析TokenSwift的性能与质量
在多个主流模型上,包括 YaRN-LLaMA2-7b-128k、LLaMA3.1-8b、Qwen2.5-1.5B, 7B, 14B 等,进行了大规模实验,序列长度涵盖从 20K 到 100K,TokenSwift 表现均极其亮眼:
- 加速比普遍在 3 倍以上
- 生成质量与原模型一致
- Distinct-n 指标显著优于原始 AR 路径
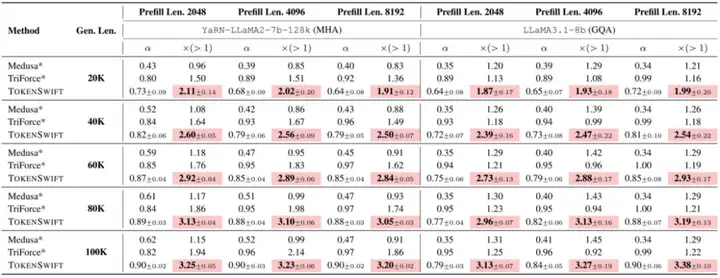

更令人振奋的是,随着序列越长,TokenSwift 的加速效果越显著。在 100K Token 生成任务中,LLaMA3.1-8B 的生成时间从近 5 小时缩短至 1.5 小时,极大降低了实际使用成本。
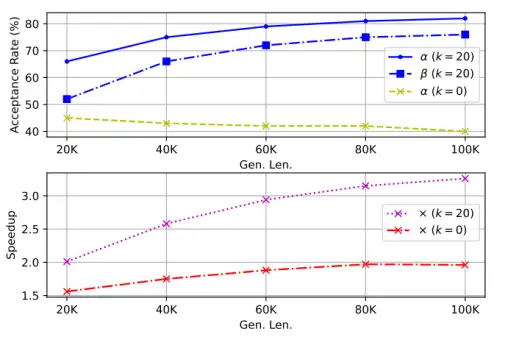
Token重用的决定性作用
我们对比了禁用(k=0)与启用状态下的接受率和加速比。结果显示,未启用重用时,随着生成长度增长,接受率和加速比均出现明显下滑;而在 k=20 时,接受率不仅维持在 70–90% 的高水平,还随序列越长而略有提升,加速比亦从~2.1× 提升至~3.1×,凸显 Token 重用在减少模型重载和保持验证高效中的关键作用 。
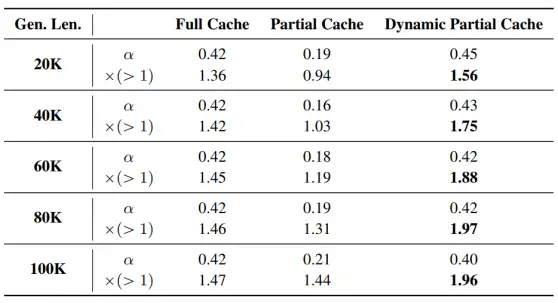
动态KV更新的巧妙平衡
针对 KV 缓存管理,我们进一步实验了「全量缓存」、「仅预填后一次更新」与 TokenSwift 中的「动态部分缓存」三种策略。
在关闭 Token 重用的前提下,「部分缓存」因接受率低而加速有限,「全量缓存」虽保证了较高接受率,却因管理成本抵消了速度收益;而 TokenSwift 的动态更新策略恰好在接受率与计算开销之间取得平衡,使得在 100K Token 任务上依然能保持近 2× 以上的加速效果 。
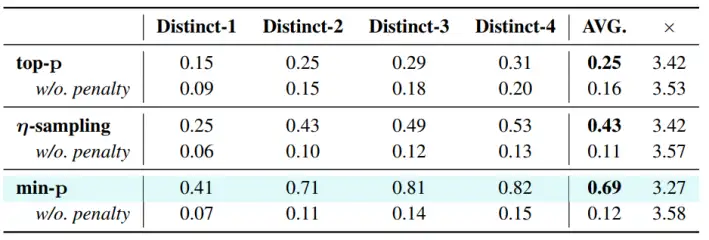
上下文惩罚对多样性的提升
为了抑制超长生成中的机械复读,TokenSwift 采用了仅对最近 W Token 应用惩罚值 θ 的「上下文惩罚」机制。
在与 top-p、η-sampling、min-p 等多种采样方法结合的实验中,未启用惩罚时 Distinct-n 平均值仅约 0.12;引入 θ=1.2、W=1024 后,平均多样性飙升至 0.43–0.69,同时加速比仅轻微下降~2–8% 左右,证明了该机制在保持质量一致性与提升文本多样性上的高效性 。

小结
TokenSwift 摆脱了传统自回归生成的性能枷锁,让我们在面对超长文本推理任务时,不再被时间与内存所拖累。
它并非一个「另起炉灶」的新模型,而是一种可直接嵌入现有主流模型(LLaMA、Qwen 等)的通用加速策略,具备极强的兼容性与部署便利性。
更重要的是,TokenSwift 对推理质量的 「无损」 保证,让我们在享受速度提升的同时,不牺牲任何精度与语义一致性。我们相信,这一框架将为未来多轮推理、代码生成、Agent 计划编排等长文本场景提供坚实的技术支撑。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
CVPR 2023 | TinyMIM:微软亚洲研究院用知识蒸馏改进小型ViT
ICCV2023|涨点神器!目标检测蒸馏学习新方法,浙大、海康威视等提出
ICCV 2023 Oral | 突破性图像融合与分割研究:全时多模态基准与多交互特征学习
HDRUNet | 深圳先进院董超团队提出带降噪与反量化功能的单帧HDR重建算法
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香
1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
SAM-Med2D:打破自然图像与医学图像的领域鸿沟,医疗版 SAM 开源了!
GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
Meta推出像素级动作追踪模型,简易版在线可玩 | GitHub 1.4K星
CSUNet | 完美缝合Transformer和CNN,性能达到UNet家族的巅峰!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号