CVPR2021|一个高效的金字塔切分注意力模块PSA
前言:
前面分享了一篇《继SE,CBAM后的一种新的注意力机制Coordinate Attention》,其出发点在于SE只引入了通道注意力,CBAM的空间注意力只考虑了局部区域的信息,从而提出考虑全局空间信息的注意力机制。
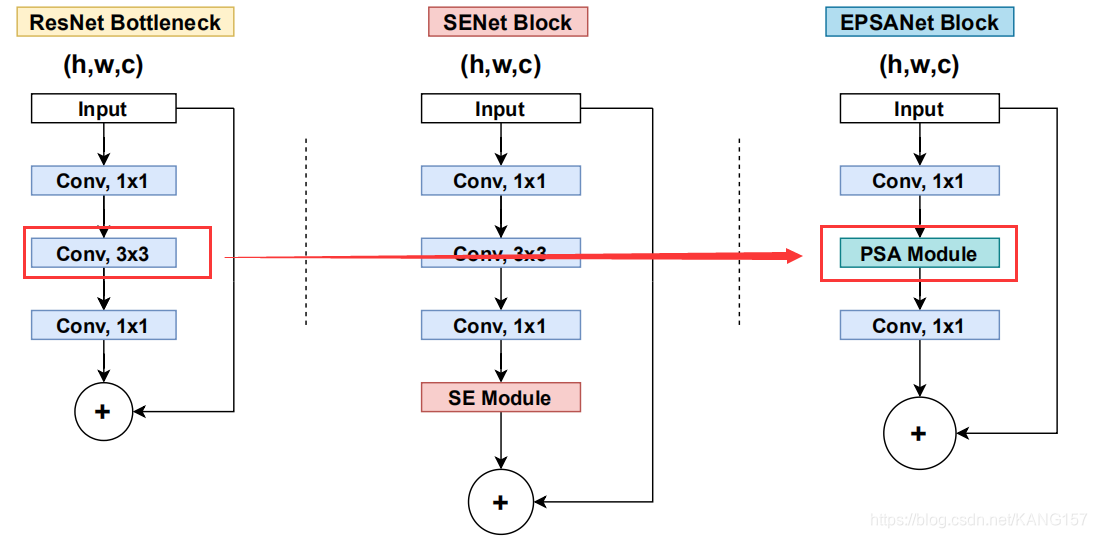
在本文,将介绍另一个基于同样出发点的注意力模块,即Pyramid Split Attention (PSA)。PSA具备即插即用、轻量、简单高效的特点。该模块与ResNet结合,通过PSA替代ResNet的bottleneck中的3x3卷积,组成了EPSANet。
EPSANet用于图像识别,比SENet top-1acc高了1.93%。PSA用在Mask RCNN上,目标检测高了2.7 box AP,实例分割高了1.7 mask AP。
论文:https://arxiv.org/pdf/2105.14447v1.pdf
代码:https://github.com/murufeng/EPSANet
本文出发点
1. SE仅仅考虑了通道注意力,忽略了空间注意力。
2. BAM和CBAM考虑了通道注意力和空间注意力,但仍存在两个最重要的缺点:(1)没有捕获不同尺度的空间信息来丰富特征空间。(2)空间注意力仅仅考虑了局部区域的信息,而无法建立远距离的依赖。
3. 后续出现的PyConv,Res2Net和HS-ResNet都用于解决CBAM的这两个缺点,但计算量太大。
基于以上三点分析,本文提出了Pyramid Split Attention。
PSA
主要操作:将input tensor从通道上分成S组。每一组进行不同卷积核大小的卷积,以获取不同尺度的感受野,提取不同尺度的信息。再通过SE模块,提取每组的通道的加权值,最后对S组的加权值进行softmax归一化并加权。
具体将input tensor分成S组,并对每组进行不同卷积的SPC模块如下图所示。

![]()
SPC先将input tensor分成S组,每组的卷积核大小依次增大,如k=3,5,7,9。考虑到当卷积核比较大时,计算量也大,因此,对每一组再进行分组卷积,具体分组数量G = exp(2,(k-1)/2),即2的(k-1)/2次幂。当K = 3,5,7,9时,G=1,2,3,4。
在经过不同大小的卷积后,在通道上拼接。
经过SPC模块后,PSA再将SPC模块的输出通过SE Weight Module获得通道注意力值,这样做的目的是获得不同尺度特征图的注意力权值。
通过这样的做法,PSA融合了不同尺度的上下文信息,并产生了更好的像素级注意力。
最后将每组通道注意力权值拼接,进行softmax归一化,对SPC模块的输出进行加权。
完整的PSA模块如下图所示。
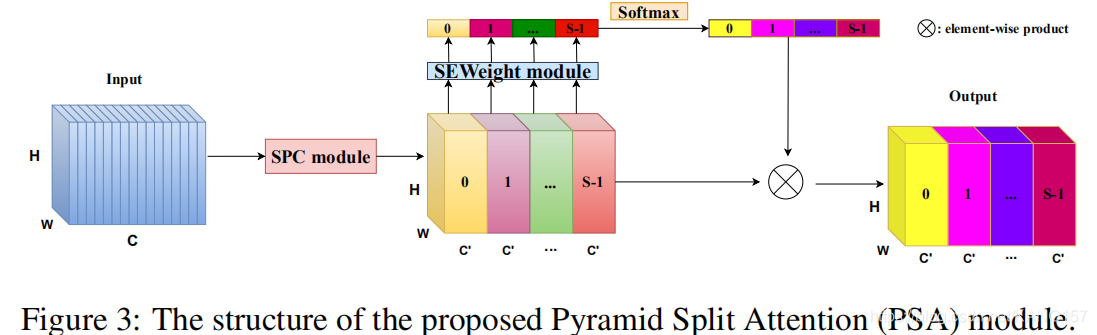
这里补充一下pyramid split attention中的pyramid。在《特征金字塔技术总结》中介绍了特征金字塔的两种构建方式,其中一种就是通过不同大小卷积核的卷积来构建特征金字塔。因此,这里PSA中的Pyramid是由SPC模块中的每组不同大小卷积核的卷积所构建。
EPSANet
![]()
如上图所示,将PSA替代ResNet的bottleneck中的3x3卷积,再堆叠几个这样的模块就构成了EPSANet,这里的E,指的是efficient。
网络设计如下图所示。

![]()
Conclusion
EPSANet用于图像识别,比SENet top-1acc高了1.93%。PSA用在Mask RCNN上,目标检测高了2.7 box AP,实例分割高了1.7 mask AP。
以ResNet-50和ResNet-101为backbone,加入各种注意力模块的图像识别效果对比

![]()

![]()
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “入门指南“可获取计算机视觉入门所有必备资料。

其它文章
在公众号《CV技术指南》中回复“技术总结”可获取以上所有总结系列文章的汇总pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号