爬了个寂寞-2
下面是我自己纯手工敲出来的代码
# -*- codeing = utf-8 -*-
# @Time : 2022/9/7 14:43
# @Name : 王星
# @File :kfc.py
# @Software: PyCharm
import requests
import json
if __name__ == '__main__':
# 第一步,获取post请求的连接
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
# 第二步,ua伪装
header = {
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 104.0.0.0Safari / 537.36'
}
# 第三步,放入所需要的参数
op = input("输入一座城市:")
param = {
'cname':'',
'pid':'',
'keyword': op,
'pageIndex': '1',
'pageSize': '10'
}
# 第四步,开始爬取
response = requests.post(url=url,params=param,headers=header)
# 第五步,准备保存到当前的文件夹
dic_obj = response.json()
# 持续化储存
fileName = op + '.json'
fp = open(fileName, 'w', encoding='utf-8')
json.dump(dic_obj, fp=fp, ensure_ascii=False)
print('over')
期间出了一些岔子,比如一开始看那个网页信息,我以为网站是get方法来跳转的,其实ajax大部分都是post请求,其次就是那个header的ua伪装了,如果直接复制的话就会自动在里面添加一些空格非常的烦人,我之前没注意在这一步疯狂报错,我还看不懂错在哪,最后就是我不咋能理解的地方了
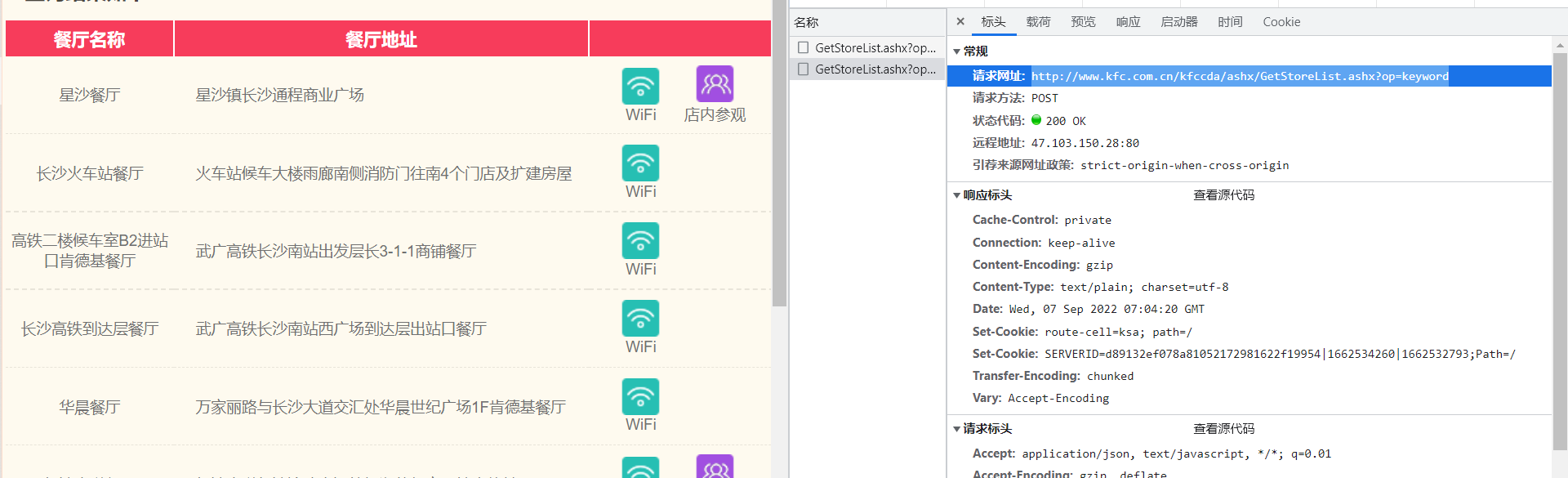
我看了这个,他显示的类型是text,但是如果获取可以用json来获取,不是json的数据不可以用json方式来存储吗,有点不咋能理解
数据解析操作

聚焦爬虫

17
通过context来获取图片

 浙公网安备 33010602011771号
浙公网安备 33010602011771号