【模仿学习】论文阅读
模仿学习简洁教程
模仿学习介绍
针对这些约束设计特定的监督信息信号来引导智能体是一个比较困难的任务。相反之下,人类却能比较容易地完成这些任务,并且为智能体提供大量的示例行为。利用这些专家示例来教会智能体进行智能决策就是模仿学习主要解决的问题。
普遍认为模仿学习有两大类算法:行为克隆和对抗式模仿学习。
- 行为克隆算法尝试最小化智能体策略和专家策略的动作差异,把模仿学习任务归约到常见的回归或者分类任务 [48, 66]。
- 而对抗式模仿学习算法则是通过逆强化学习 [36, 50](Inverse Reinforcement Learning)来构建一个对抗的奖赏函数,然后最大化这个奖赏函数去模仿专家行为。
模仿学习问题设定
在模仿学习里,我们假设有一个专家策略是表现不错的,我们希望智能体能够模仿专家策略进行决策。具体而言,我们希望智能体的累计回报与专家策略的累计回报比较接近。
行为克隆
行为克隆在实际应用中存在复合误差。
公式 (3.1) 和公式 (3.4) 对应问题的训练数据集都是经策略\(π^E\)采集的;但是,我们评估学习到的策略\(\hat{\pi }\)却是基于策略\(\hat{\pi }\)采集到的轨迹。可以看到评估测试时用到策略\(\hat{\pi }\)的状态-动作访问分布和训练数据集的状态-动作分布不太一致。
如果在这些未被访问的状态上,BC 会采取一个均匀分布的策略。
DAgger 算法
其把行为克隆得到的策略与环境不断的交互,来产生新的数据。
对抗式模仿学习
状态-动作分布匹配是对抗式模仿学习的核心思想。
即使在数据集未被访问的状态上,‘‘状态-动作分布匹配’’ 准则也会帮助选择能够接近专家状态-动作分布的动作。
相比于行为克隆中 ‘‘策略分布匹配’’的准则,生成对抗式模仿学习中 ‘‘状态-动作分布匹配’’ 的准则可以降低复合误差,提升模仿策略的累计回报。
智能体会倾向于选择任何可以使得产生的状态-动作分布能够与专家匹配的动作,而这样的动作不一定只是专家动作。
给定策略 π,变量 w 的目的是找到一个奖赏函数来最大化专家策略和模仿策略的价值差距;给定奖函数 w,变量 π 的目的是找到一个策略来最大化在奖赏函数 w 下的价值函数 \(V_π^w\) ,这与强化学习的目标一样。
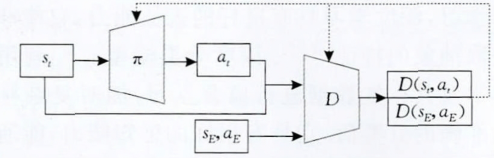
生成对抗式模仿学习算法
其中 D可以看作 GAN 中的判别器,作用是区分某个状态-动作对 (s, a) 是由专家策略 πE 还是由模仿策略 π 产生,是一个二分类问题。π 是生成器,目标是产生与专家数据相似的状态-动作对,提升判别器的打分,混淆判别器。
环境模仿
如果我们可以学到一个近似的奖赏和转移函数,我们便可以在这个近似的环境中进行策略学习,从而降低样本复杂度,这便是基于模仿的强化学习的主要思想。(通过构建模型加快收敛速度?)
在基于模型的强化学习中,由于智能体可以在经验环境模型上完成采样,从而降低了在真实环境
的样本复杂度,有助于提升强化学习算法的样本效率。
构建环境模型的过程中,可以把真实环境的奖赏转移函数以及初始状态分布视作 ‘‘专家’’,因此模仿(策略)学习的算法可以被应用到模仿环境模型的任务中。
其中,模仿奖励函数和初始状态分布比较简单:对于前者,我们只需要利用回归模型构建一个从 S × A 到 R 的映射即可1;对于后者,我们只要学习一个生成模型来模拟初始状态分布。而模仿转移函数则比较困难,这是因为转移函数一般是一个高维的条件概率分布。
强化学习传说:第一章 模仿学习
DAgger算法
- 从已抽取的data中训练策略网络\(\pi_\theta(a_t|o_t)\)
- 运行学习策略\(\pi_\theta(a_t|o_t)\)后获得的\(o_t\)
- 对获得的\(o_t\)执行专家策略得到其label:\(a_t\);
- 将获得的(\(o_t\), \(a_t\)) 加入data重新训练策略。
这里好像没和强化学习结合起来
基于生成对抗网络的模仿学习综述
模仿学习研究如何从专家的决策数据中进行学习,以得到接近专家水准的决策模型。
它可以分为行为克隆、基于逆向强化学习的模仿学习两类方法。
基于逆向强化学习的模仿学习把模仿学习的过程分解成逆向强化学习和强化学习两个子过程,并反复迭代。逆向强化学习用于推导符合专家决策数据的奖赏函数,而强化学习基于该奖赏函数来学习策略。
模仿学习方法通过模仿专家演示的样本以解决决策问题。它不需要从环境中获得奖赏反馈,其
反馈信息来自于专家的决策样本。
在许多实际问题中,相较于设置合适的奖赏函数,获取专家样本往往更容易且代价更小。
行为克隆的主要思想是直接克隆专家样本在各状态处的单步动作映射,即对专家样本进行监督学习。(那篇LSTM的论文估计就是行为克隆,根据预测校正方法获取大量轨迹)
由于不考虑长远影响,行为克隆会将细微的误差在序贯的决策过程中逐步放大,即产生级联误差问题。因而在很多模仿学习任务中,鲁棒性、泛化性较差。
基于逆向强化学习的模仿学习方法假设专家策略等价于由未知的真实奖赏函数推导出的最优策略。是RL的逆向过程,它根据给定的专家样本求解未知的奖赏函数。基于解得的奖赏函数,IRL-IL通过RL方法求解最优策略的方式,间接地还原专家策略。
在GAIL中,根据输入状态输出动作的策略可类比为生成器,而根据输入专家样本或生成样本输出奖赏值的奖赏函数可类比为判别器。从而,GAIL 将求解奖赏函数的过程类比作判别器的训练过程,将策略的学习过程类比作生成器的训练过程。
GAIL具有更强的表征能力。并且,GAIL直接将策略作为学习的目标,它运用高效的策略梯度方 法 训 练策略 模型.从而,GAIL 能避开IRL-IL需消耗大量计算资源的内部计算过程,具有更高效的计算能力。
模态崩塌问题源于GANs,它将导致GAIL 产生的样本丧失多样性.生成样本利用效率低问题源于GAIL的随机性策略假设 和 无模型策略学习方式,它将导致GAIL无法适用于获取样本成本高的实际应用。
通过求解IRL问题得到的奖赏函数能理解专家样本数据背后的决策动机或偏好。
通过运用强化学习方法,IRL-IL能够基于奖赏函数考虑策略的长远影响而不局限于单步的即时反馈。
Wasserstein散度能够度量未发生重叠的分布的差异,并具有对称性。缓解了由原先散度造成的梯度消失和模态崩塌的问题。
包括结合了GANs的对抗原理的对抗式 VAE算法。
策略基于当前奖赏函数的优化过程可类比为生成器的训练过程,奖赏函数的优化过程可类比为判别器的训练过程。
专家样本中存在具有一定意义的高层特征,这些特征被称为模态。模态崩塌是指生成模型产生的生成样本塌缩于真实样本分布的某一模态下的子分布,而无法覆盖全部真实样本分布。
由于无法端到端可微分,GAIL中的策略π无法根据 奖 赏函数模 型 D 的 内 部参数进 行 更新.从而,π只能通过D 输出的立即奖赏值估计期望累积奖赏,接着获得对策略梯度的估计,即通过策略梯度方法实现更新.
在模仿学习中,获取专家样本集合的方式主要有以下两种:(1)由人类专家示范而获得专家样本
集合;(2)通过RL方法对专家手工定义的标准奖赏函数学习,得到贪婪策略,再由贪婪策略得到专家样本集合。
对于模态崩塌问题,GAIL改进方法可分为以下两类:(1)基于多模态假设的改进;(2)基于生成模型的改进。
通过将专家样本中额外的模态标签数据作为条件约束,CGAIL使奖赏函数在各个模态的约束下有监督地指导策略生成相应模态的样本,从而缓解了模态崩塌问题.
CGAIL仅将模态标签作为建模的条件约束,而并不将其用于训练网络模型,它并没有充分利用样本中额外的模态标签数据.
在更多的情景下,模态标签数据并没有显式地存在于专家样本中.模态数据往往作为隐变量藏于样本之中,它无法从专家样本中直接获得.
InfoGAIL能增强策略产生的样本与模态隐变量之间的相关性,从而实现无监督的多模态学习.进一步考虑最大化待学习策略产生的状态 -动作对与模态隐变量之间的互信息。
基于生成模型的改进方法.它将GAIL中的生成模型改进为变分自编码器,但依然保留对抗式学习机制.其特点是,变分自编码器能够通过自编码器的自监督学习得到模态信息.该方法同样放宽了原始GAIL中单一专家模态的假设,能实现多模态的模仿学习。
VAE-GAIL运用VAE推断 专 家 轨 迹 样 本 中 的 模 态 隐 变 量.接 着,VAE-GAIL基于 CGAIL中的对抗式学习方法将推断得出的模态变量作为奖赏函数和策略模型的条件约束,从而实现多模态学习。
基于模型的改进
为了解 决GAIL无 法 端 到 端 可 微 分 的 问 题,Baram等人运用基于模型的强化学习方法对 GAIL 进行了改进.他们提出了基于动态模型的生成对抗模仿学习方法。
基于确定性策略的改进
在 RL中,策 略 不 仅 可 以 是 随 机 性 策略,还可以是确定性策略.通过将样本保存入经验池,基于确定性策略的RL方法能够重复利用样本。
与随机性策略相比,由于动作是唯一确定的,确定性策略的梯度期望值不涉及关于动作的估计运算.因此,确定性策略算法能够避开随机性策略产生的高方差问题。
在DPG中,确定性策略的策略梯度在一定条件下能够近似 等 价于动作值 函 数的梯度。
在DDPG中,确定性策略的试错可通过在策略中加入噪声实现.策略产生的试错样本被保存在经验池中.经验池可以类比作一种记忆机制.它可以不断回忆起智能体以往的经历,重复利用以往的试错样本来更新动作值函数,进而学习策略.
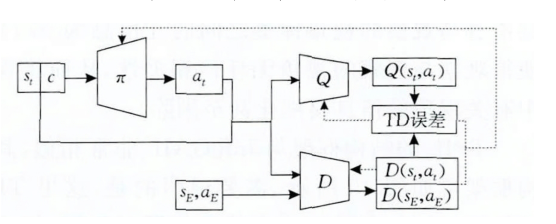
基于上下文的生成对抗模仿学习
在许多现实应用场景中,当前观察并不能表示所有信息.因而这些应用场景不具有严格的马尔可
夫性质.比如,在自动驾驶的过程中,汽车(智能体)的决策不仅依赖于当前的观察,还依赖于以往的观察.汽车结合以往的观察才能预知附近行人或汽车等的运动趋势.
当前观察结合历史观察构成了上下文观察信息,它能够表示环境的变化。
Kuefluer等人把深度学习中的循环神经网络结合到策略的模型中。
基于观察的生成对抗模仿学习
但是在很多情况下,观察样本大量存在且极易获取,而动作数据则难以获取.比如,YouTube等互联网平台保存了海量的游戏视频样本,但没有保存玩家具体所执行的动作数据。
IRL实际上是寻找一个真实奖赏函数,它能够分配给专家的状态-动作对样本高的奖赏值,而给其他策略产生的状态-动作对样本低的奖赏值.
寻找一个奖赏函数,它使得策略产生的从当前观察到下一观察的迁移样本能拟合专家的观察迁移样本分布。
在 GAIfo中,奖赏函数分配给专家的观察迁移样本更高的奖赏值,而策略则试图对抗式地产生与专家相似的观察迁移样本,从而获得更大的奖赏值。
总结
相较于强化学习(RL)方法,模仿学习方法不需要专家手工设置合适的奖赏函数.它模仿专家演示的样本,从而学习得到与人类相当的策略.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号