Java中的函数式编程
写在前面
虽然JDK8已经是非常古老的版本了(截止到文章发布,目前最新JDK版本为JDK19.。。。),但JDK8中的函数式编程一直没有系统的学过。这次由于工作中的使用加上国庆假期,索性过了一遍。
Lambda省略规则
这方面虽然有很多可以说的点,但与其去记这些规则,不如还是依赖于智能的IDE吧。因此这里只把省略规则列出来供参考,不做详细描述:
-
小括号内的参数类型可以省略
-
如果小括号内有且仅有一个参数,则小括号可以省略
-
如果大括号内有且仅有一个语句,可以同时省略大括号,return关键字以及语句分号
;
例子:
-
非省略写法:
List<Person> personList = new ArrayList<>(); personList.add(new Person("张三",19,175)); personList.add(new Person("李四",33,170)); personList.add(new Person("小美",18,162)); personList.add(new Person("小明",23,171)); // Lambda标准写法 Collections.sort(personList,(Person o1,Person o2)->{ return o1.getHeight() - o2.getHeight(); }); -
省略写法:
Collections.sort(personList,(o1,o2)->o1.getAge() - o2.getAge());
创建流
介绍
由于Java是完全的面向对象语言,因此想要使用函数式编程就要先将Java对象转换为流对象(Stream)才能使用函数式编程的写法。
方式一:单列集合
这种方式是最为常见也是最简单的方式,如下代码:
list.stream();
set.stream();
方式二:数组
对于数组来说,我们有两种方式:
Arrays.stream() // method1
Stream.of() // method2
对于方法一的传参,可以看一下:
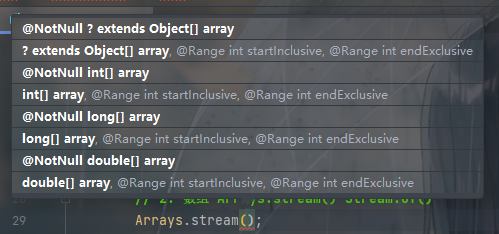
可以看到都是常用的数组类型。
而方法二的传参:
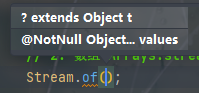
这里涉及到一个知识点,可变参数。本质上来讲可变参数其实就是数组,因此这个方法也是可以传数组的。
方式三:双列集合
这里其实就是特指Map这种集合,我们可以把Map的key或者value然后变成流,也可以直接使用entrySet()这个方法将Map转换为Set这种单列集合:
map.keySet().stream();
map.values().stream();
map.entrySet().stream()
中间操作
介绍
在我们创建了流之后,我们就可以对数据集合进行各自各样的操作了,这种就叫做中间操作,需要注意的是中间操作和终结操作(后面介绍)最大的区别是中间操作的返回值还是一个流对象,意味着我们还可以继续进行操作。而且一堆对流操作的代码要是不执行终结操作是不会真正执行。
1.filter
这个操作其实非常好理解,就是对数据进行过滤。我们在filter中需要传入一个Predicate对象,不过这并不重要,因为这是函数式编程,我们只需要关注入参和要返回的值即可。这里的入参是集合中每个对象,返回值是一个布尔值,即我们可以在里面做判断,如下示例:
private static void test03(){
List<Author> authors = getAuthors();
// 打印所有姓名长度大于1的作家的姓名
authors.stream()
.filter(author -> author.getName().length() > 1)
.forEach(author -> System.out.println(author.getName()));
}
2.map
map操作就是将数据中的其中一个维度拿出来变成一个新的集合,比如如下代码:
private static void test04() {
List<Author> authors = getAuthors();
// 打印所有作家的姓名
authors.stream()
.map(author -> author.getName())
.forEach(System.out::println);
}
这里我们在IDE提示中可以看到,经过map后的流对象中的泛型变成了String:
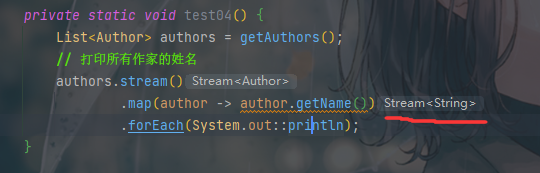
所以当我们需要对集合中某个属性的集合进行处理时我们就可以使用map函数。
3.distinct
去重,很显而易见,没有入参。但需要注意的是这里的去重依赖于对象中的equals和hashCode方法,因此我们要重载这两个方法去重才好用:
private static void test05() {
// 打印名字 且不允许重复
List<Author> authors = getAuthors();
authors.stream()
.distinct()
.forEach(author -> System.out.println(author.getName()));
}
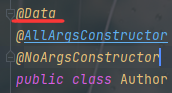
这里的Author对象使用了lombok,Data注解中包含了重载equals和hashcode的注解。
4.sorted
排序,也十分显然。这里要注意的是实现排序有两种方式,一种是对象实现Comparable接口,然后重写compareTo方法,这样sorted函数就不需要传参了:
另一种是直接在sorted方法中使用Comparator接口:
private static void test06() {
// 按照年龄进行降序排序 且不允许有重复元素
List<Author> authors = getAuthors();
authors.stream()
.distinct()
.sorted((o1, o2) -> o2.getAge() - o1.getAge())
.forEach(author -> System.out.println(author.getAge()));
}
5.limit
这个就很简单了,限制返回个数。入参是允许的最多返回个数:
private static void test07() {
// 对年龄进行降序排序 不允许有重复 且打印年龄最大的两个作家的姓名
List<Author> authors = getAuthors();
authors.stream()
.distinct()
.sorted()
.limit(2)
.forEach(author -> System.out.println(author.getName()));
}
6.skip
跳过某几个元素,入参是跳过的元素个数,直接看代码:
private static void test08() {
// 打印除了年龄最大的作家外的其他作家,不得重复且按年龄降序排序
List<Author> authors = getAuthors();
authors.stream()
.distinct()
.sorted()
.skip(1)
.forEach(author -> System.out.println(author.getName()));
}
7.flatMap
相比于前面几个,flatMap要复杂一些。它可以将集合拆解到最小,比如我们一个对象A内的一个属性包含了另一个对象B的集合,如果使用map生成的流不会得到对象B的流,而是对象B的集合的流。这时我们使用flatMap就可以直接得到对象B的流,如下代码示例:
private static void test09() {
List<Author> authors = getAuthors();
// 打印现有数据的所有分类,对分类进行去重,且不允许出现哲学,爱情这种格式
authors.stream()
.flatMap(author -> author.getBookList().stream())
.distinct()
.flatMap(book -> Arrays.stream(book.getCategory().split(",")))
.distinct()
.forEach(category -> System.out.println(category));
}
根据IDE的提示,我们可以看到:
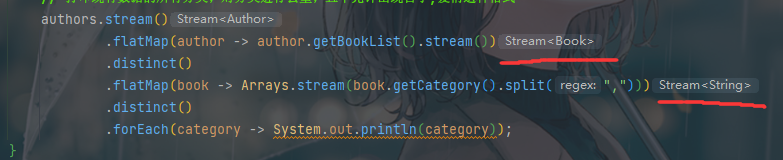
经过flatMap后流对象直接变成了该对象的流,这样当我们处理一些嵌套集合的时候会很方便。
小结
这里只是介绍了一些较为常用的中间操作,其实我们最开始使用的时候如果不熟可以先写匿名内部类,用IDE生成Lambda,熟练后再尝试直接写。
终结操作
介绍
在执行了终结操作后,流才会真正开始执行,返回值也不再是流。流也会关闭,无法再次使用。
1.forEach
这东西就不用介绍了,遍历集合,上面的代码示例一直在用。
2.count
这个也很简单,就是获取集合中的个数,也不再添加示例了。
3.min&max
最小值与最大值,很好理解,使用也很简单:
private static void test10() {
// 获取作家的所有书籍的最高分和最低分
List<Author> authors = getAuthors();
Optional<Integer> max = authors.stream()
.flatMap(author -> author.getBookList().stream())
.map(book -> book.getScore())
.max((o1, o2) -> o1 - o2);
System.out.println(max.get());
Optional<Integer> min = authors.stream()
.flatMap(author -> author.getBookList().stream())
.map(book -> book.getScore())
.min((o1, o2) -> o1 - o2);
System.out.println(min.get());
}
4.collect
可能是使用最为频繁的一个终结操作。当我们想将经过一系列处理的集合变成新的集合时,就要使用这个方法:
private static void test11() {
// 获取一个存放所有作者名字的List集合
List<Author> authors = getAuthors();
List<String> nameList = authors.stream()
.map(author -> author.getName())
.collect(Collectors.toList());
System.out.println(nameList);
// 获取一个书名的Set集合
Set<String> bookSet = authors.stream()
.flatMap(author -> author.getBookList().stream())
.map(book -> book.getName())
.collect(Collectors.toSet());
System.out.println(bookSet);
// 获取一个Map集合 key为作者名 value为List<Book>
Map<String, List<Book>> map = authors.stream()
.distinct()
.collect(Collectors.toMap(author -> author.getName(), author -> author.getBookList()));
System.out.println("map = " + map);
}
5.查找与匹配
这个感觉用处不是很大,就是查找。基本上方法名就表示了作用:anyMatch(任一符合) allMatch(都符合) noneMatch(都不符合) findAny(查找任意) findFirst(查找第一个)。这里就不再举代码示例了。
6.reduce
如果了解过hadoop,现在应该会冒出来一个大胆的想法,有map有reduce,那不就是mapReduce吗。还真是。这里的reduce就是求和,如下代码示例:
private static void test12() {
// 使用reduce求所有作者年龄的和
List<Author> authors = getAuthors();
Integer reduce = authors.stream()
.distinct()
.map(author -> author.getAge())
.reduce(0, (result, element) -> result + element);
System.out.println("reduce = " + reduce);
// 使用reduce求所有作者中年龄的最大值
Integer reduce1 = authors.stream()
.map(author -> author.getAge())
.reduce(Integer.MIN_VALUE, (result, element) -> result < element ? element : result);
System.out.println("reduce1 = " + reduce1);
// 求年龄的最小值
Integer reduce2 = authors.stream()
.map(author -> author.getAge())
.reduce(Integer.MAX_VALUE, (result, element) -> result > element ? element : result);
System.out.println("reduce2 = " + reduce2);
}
方法引用
最后来介绍一个规则十分复杂的语法糖,方法引用,一般是长这个样子:
Integer reduce2 = authors.stream()
.map(Author::getAge)
.reduce(Integer.MAX_VALUE, (result, element) -> result > element ? element : result);
这里的Author::getAge就是方法引用。具体的规则这里就不再说了,建议不要使用,因为感觉会很错乱。。。
总结
总的来说,还是多了一种思想吧。毕竟对集合进行过滤什么的处理还是蛮常见的。在Java这么纯种的面向对象语言里,能够看到函数式编程的思想还是很难得的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号