

Flink-介绍
Flink 运行模式
|
模式名称
|
依赖环境
|
高可用支持
|
弹性伸缩
|
部署复杂度
|
适用场景
|
优点
|
缺点
|
|
Local 模式
|
无
|
否
|
否
|
★
|
个人开发、功能调试、学习测试:适用于单机运行,快速验证逻辑,不需要集群。
|
部署最简单,只需本地安装 Flink;无需额外配置;启动速度快;调试方便。
|
只能在单机运行,无法利用多节点计算能力;不能用于生产环境;无容错能力。
|
|
Standalone 模式(独立集群模式)
|
无
|
否
|
否
|
★★
|
小型测试集群、简单生产环境:适用于固定规模、不需要频繁扩容的任务。
|
不依赖外部系统;部署简单;可运行在多台机器组成的小集群;资源可控。
|
无自动弹性伸缩;高可用需额外配置;集群维护需要人工操作;容错能力弱。
|
|
Standalone HA 高可用模式
|
ZooKeeper
|
是
|
否
|
★★★
|
中小型生产环境:适用于需要高可用,但不需要自动扩容的任务。
|
通过 ZooKeeper 提供 JobManager 主备切换;比普通 Standalone 更稳定;部署相对简单。
|
仍无自动伸缩;需要维护 ZooKeeper;扩容需人工执行;不适合频繁变化的任务负载。
|
|
Yarn 会话模式
|
Hadoop/Yarn
|
是
|
是
|
★★★
|
多任务共享集群:适用于多个 Flink 作业同时运行,共享 Yarn 集群资源。
|
利用 Yarn 提供的资源调度和容错;无需单独维护集群;任务启动速度快(因为集群已存在);可动态分配资源。
|
需要 Hadoop/Yarn 环境;任务间可能竞争资源;集群生命周期需人工管理。
|
|
Yarn 单任务模式
|
Hadoop/Yarn
|
是
|
是
|
★★★
|
独立任务运行:适用于一次性任务或任务隔离要求高的场景。
|
每个任务独立集群,互不影响;任务结束自动释放资源;更好隔离。
|
启动开销大(每次都要创建集群);需要 Hadoop/Yarn 环境;不适合频繁短任务。
|
|
Kubernetes 会话集群模式
|
Kubernetes
|
是
|
是
|
★★★★
|
云原生多任务共享:适用于云环境中多个 Flink 作业共享同一个 K8s 集群。
|
云原生弹性伸缩;容器化部署方便;与其他云服务集成容易;任务启动快(集群已存在)。
|
需要 Kubernetes 环境;任务间可能竞争资源;集群生命周期需人工维护。
|
|
Kubernetes 应用集群模式
|
Kubernetes
|
是
|
是
|
★★★★
|
云原生单任务运行:适用于云环境中一次性任务或任务隔离要求高的场景。
|
每个任务独立集群,自动销毁;隔离性好;利用 K8s 弹性伸缩;资源利用率高。
|
启动开销大;需要 Kubernetes 环境;不适合频繁短任务;集群启动时间依赖 K8s 资源调度速度。
|
额外说明
- 高可用支持:指 JobManager 能否在故障时自动切换到备用节点,保证作业继续运行。
- 弹性伸缩:指能否根据任务负载自动增加或减少 TaskManager 数量。
- 部署复杂度:★ 越少表示越简单,★ 越多表示依赖环境和配置越复杂。
建议如果是 **开发/测试**:
- 用 Local 模式 或 **Standalone 模式**(简单快速)
如果是 **生产环境**:
- 小规模稳定任务 → Standalone HA
- 大数据平台(Hadoop) → Yarn 模式
- 云原生环境 → Kubernetes 模式
Flink Standalone 模式
1. 什么是 Flink Standalone 模式?
Flink Standalone 模式,顾名思义,就是 **Flink 自己管理集群,不依赖外部资源管理平台(如 Yarn、Kubernetes、Mesos)**。
在这种模式下,**JobManager** 和 TaskManager 进程由你自己启动和维护,集群的生命周期完全由你掌控。
📌 **关键词**:
- 独立运行(Standalone = 独立)
- 无外部依赖(只需要 Java 环境)
-
手动管理集群
2. 架构原理
在 Standalone 模式下,Flink 集群主要由两类进程组成:
-
JobManager
- 负责作业调度、任务分配、容错管理。
-
类似于“指挥官”,告诉 TaskManager 要执行哪些任务。
-
TaskManager
- 负责实际执行任务(算子),并与其他 TaskManager 交换数据。
-
类似于“工人”,执行 JobManager 下发的任务。
架构示意图:
+-------------------+
| JobManager | <-- 调度、协调、容错
+-------------------+
|
v
+-------------------+ +-------------------+
| TaskManager 1 | | TaskManager 2 | <-- 执行算子任务
+-------------------+ +-------------------+client客户端提交任务给JobManager
JobManager负责Flink集群计算资源管理,并分发任务给TaskManager执行
TaskManager定期向JobManager汇报状态
flink的TM就是运行在不同节点上的JVM进程(process),这个进程会拥有一定量的资源。比如内存,cpu,网络,磁盘等。flink将进程的内存进行了划分到多个slot中.图中有2个TaskManager,每个TM有2个slot的,每个slot占有1/2的内存。
3. 优点
- 部署简单:只要有 Java 环境即可运行,适合快速搭建测试集群。
- 无外部依赖:不需要 Yarn、Kubernetes 等复杂环境。
- 资源可控:你可以完全掌握集群资源分配。
-
轻量级:适合小规模任务或学习测试。
4. 缺点
- 无自动弹性伸缩:不能根据负载自动增加或减少节点。
- 高可用需额外配置:需要手动配置 ZooKeeper 才能实现 HA。
- 集群维护成本高:节点故障需要人工处理,无法自动恢复。
-
不适合大规模生产环境:资源调度和管理能力有限。
5. 适用场景
- 开发测试:本地或简单集群环境中快速验证 Flink 程序。
- 小规模生产环境:任务量稳定、节点数量固定的场景。
-
学习实验:初学者用来熟悉 Flink 集群运行机制。
部署方式
安装包下载https://flink.apache.org/downloads/
先安装java11
JobManager
修改配置文件
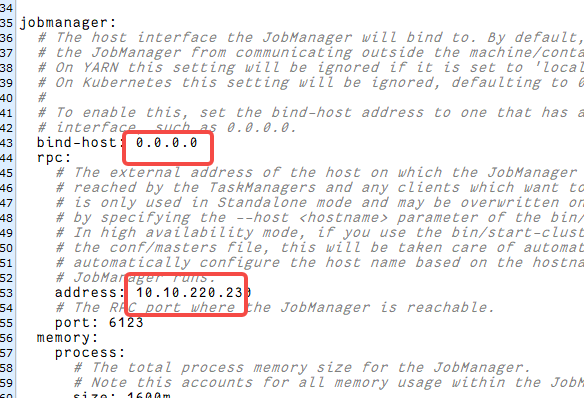
./bin/jobmanager.sh start
workers
修改配置文件
./bin/taskmanager.sh start
3.6、查看WebUI
通过JobManager节点访问WebUI,可以看到此时是1个JobManager,2个TaskManager,也能以上执行完毕的任务,如下图: ip:8081
Docker部署
1、配置文件
docker run --name flink-temp flink:2.1 sleep 5
docker cp flink-temp:/opt/flink/conf /home/flink/
docker rm flink-temp
docker run -d \
--name jobmanager \
-p 6123:6123 \
-p 8081:8081 \
-v /home/flink/conf:/opt/flink/conf \
-v /home/flink/log:/opt/flink/log \
-e FLINK_PROPERTIES="jobmanager.rpc.address: 10.10.220.230" \
flink:2.1 jobmanager
docker run -d \
--name flink-taskmanager \
-v /home/flink/conf:/opt/flink/conf \
-v /home/flink/log:/opt/flink/log \
-e FLINK_PROPERTIES="jobmanager.rpc.address: 10.10.220.230" \
flink:2.1 taskmanager
注意:修改了配置文件中"jobmanager.rpc.address为10.10.220.230 但是启动后还是会被重置。所以加了-e FLINK_PROPERTIES="jobmanager.rpc.address: 10.10.220.230" \
如果要使用streampark
那么streampark和jobmanager只能二进制安装在同一台机器上。
https://github.com/apache/streampark
https://streampark.apache.org/zh-CN/docs/get-started/installation

 浙公网安备 33010602011771号
浙公网安备 33010602011771号