模型剪枝
模型剪枝
一. 基础回顾
-
首先回顾一下卷积的过程,输入:\(x=[16,3,224,224]\),卷积核:\(k=[in\_chs=3,out\_chs=12,strides=1,kernel=1...]\),输出;\(y=[16,12,224,224]\)。对于剪枝(通道剪枝)而言,修剪的是 \(out\_chs\) 这个分支。
-
当修剪卷积通道之后,相应的后面卷积都应对应的调整。例如:\(conv\_1=[in\_chs=3,out\_chs=12],conv\_2=[in\_chs=12,out\_chs=64]\),对conv_1进行修剪四个通道,对应conv2也随之变化:\(conv\_1=[in\_chs=3,out\_chs=8],conv\_2=[in\_chs=8,out\_chs=64]\)。当然修剪的通道具有Index信息,在操作过程得保留。
-
再回顾一下BN层的操作流程BN详解(公式+代码),这里的 \(\gamma\) 表示尺度(乘积),当这个值很小时,BN的输出就很小。在剪枝过程可以把 \(\gamma\) 看做是重要程度衡量参数。例如:\(conv\_1=[in\_chs=3,out\_chs=12],BN=[12],conv\_2=[in\_chs=12,out\_chs=64]\),对BN中的 \(\gamma\) 进行排序,修剪掉最小的四个通道,那么结果为:\(conv\_1=[in\_chs=3,out\_chs=8],BN=[8],conv\_2=[in\_chs=8,out\_chs=64]\),同理修剪的时候是根据index进行的。
-
(1)都是自己设计小网络然后进行蒸馏+量化增加精度和加速。(2)大网络进行剪枝,小网络剪枝效果很差。
二. Pruning Filters for Efficient ConvNets
论文:链接地址
代码:链接地址
论文比较简单,直接按照上面第一、第二点进行即可,具体操作可阅读源代码
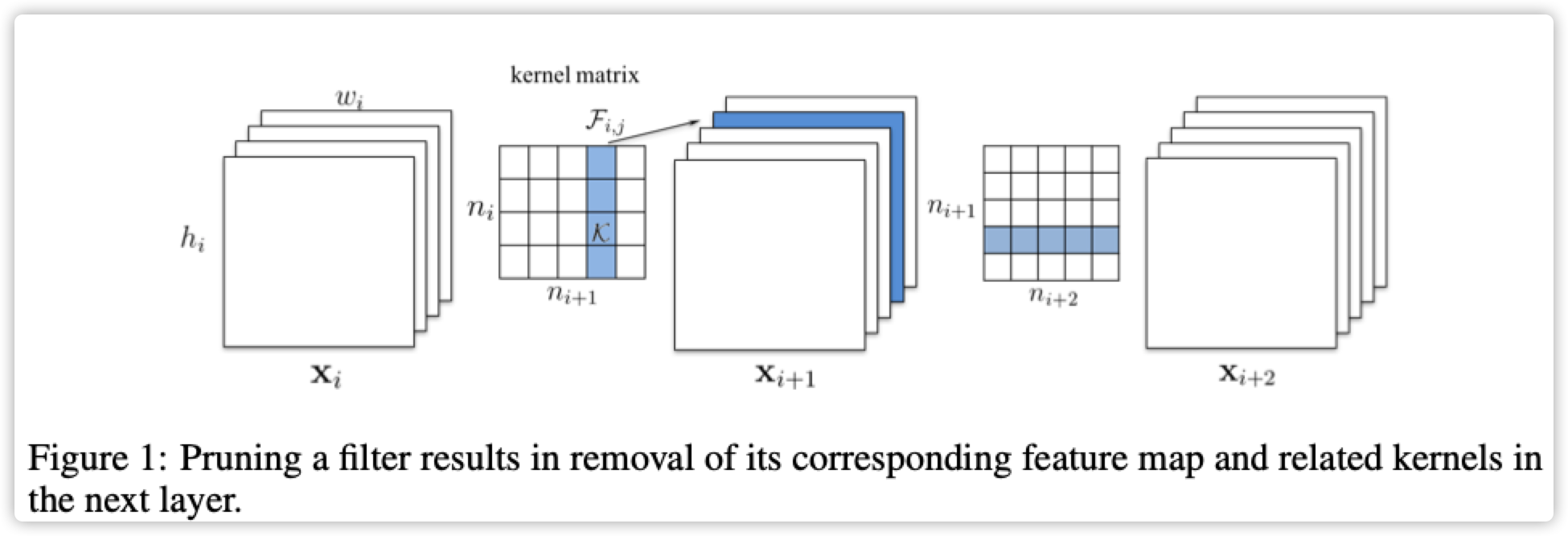
三. Learning Efficient Convolutional Networks through Network Slimming
论文:链接地址
代码:链接地址
主要使用稀疏训练和BN层剪枝
# 直接在原始梯度基础上增加L1梯度反向传播
def updateBN():
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
m.weight.grad.data.add_(args.s*torch.sign(m.weight.data)) # L1梯度反向传播替换
# 也可使用torch hook机制修改层的梯度计算方式
******
BN层的剪枝参考上面第三点方式进行
关于Resnet等skip-connect的剪枝:
# 预先定义channel_selection层,前向传播的时候不影响任何操作,在进行剪枝的时候如下所示
# 不影响上一层的结果,但会选择通道和下一层对应
if isinstance(old_modules[layer_id + 1], channel_selection):
# If the next layer is the channel selection layer,
# then the current batchnorm 2d layer won't be pruned.
m1.weight.data = m0.weight.data.clone()
m1.bias.data = m0.bias.data.clone()
m1.running_mean = m0.running_mean.clone()
m1.running_var = m0.running_var.clone()
# 这里是核心,将selectlayer里面的index更改为下一层的idx
# We need to set the channel selection layer.
m2 = new_modules[layer_id + 1]
m2.indexes.data.zero_()
m2.indexes.data[idx1.tolist()] = 1.0
layer_id_in_cfg += 1
start_mask = end_mask.clone()
if layer_id_in_cfg < len(cfg_mask):
end_mask = cfg_mask[layer_id_in_cfg]
四. Rethinking the Value of Network Pruning
论文:链接地址
代码:链接地址
论文最主要表达的思想是:大模型训练->剪枝->微调->剪枝->微调->.....->结束,这种方式不一定比直接使用小模型进行训练效果好。
那么问题来了?
既然直接训练小模型比剪枝的效果更好,为什么还要剪枝这项比较复杂的工作呢?
当前笔者查到的论文,基本都是这个 Eric 大神的作品,当前这篇推翻剪枝工作的论文也是其作品。
到现在为止,终于发现剪枝在工作中算小众方向的原因了
-------------------------------------------
个性签名:衣带渐宽终不悔,为伊消得人憔悴!
如果觉得这篇文章对你有小小的帮助的话,记得关注再下的公众号,同时在右下角点个“推荐”哦,博主在此感谢!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号