SparkStreaming消费Kafka,手动维护Offset到Mysql
说明
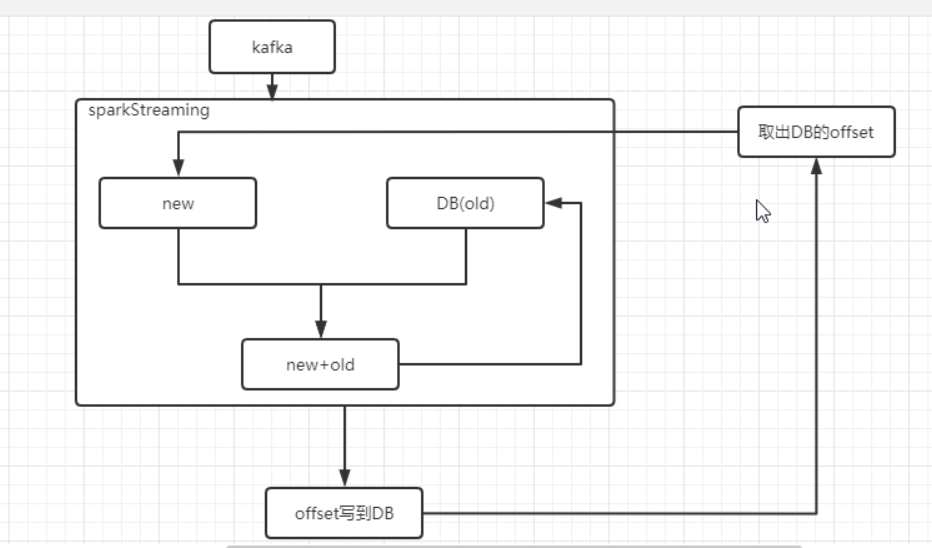
当前处理只实现手动维护offset到mysql,只能保证数据不丢失,可能会重复
要想实现精准一次性,还需要将数据提交和offset提交维护在一个事务中
官网说明
Your own data store
For data stores that support transactions, saving offsets in the same transaction as the results can keep the two in sync, even in failure situations. If you’re careful about detecting repeated or skipped offset ranges, rolling back the transaction prevents duplicated or lost messages from affecting results. This gives the equivalent of exactly-once semantics. It is also possible to use this tactic even for outputs that result from aggregations, which are typically hard to make idempotent.
您自己的数据存储
对于支持事务的数据存储,即使在失败情况下,将偏移与结果保存在同一事务中也可以使两者保持同步。 如果您在检测重复或跳过的偏移量范围时很谨慎,则回滚事务可防止重复或丢失的消息影响结果。 这相当于一次语义。 即使是由于聚合而产生的输出(通常很难使等幂),也可以使用此策略。
整体逻辑
offset建表语句
CREATE TABLE `offset_manager` (
`groupid` varchar(50) DEFAULT NULL,
`topic` varchar(50) DEFAULT NULL,
`partition` int(11) DEFAULT NULL,
`untiloffset` mediumtext,
UNIQUE KEY `offset_unique` (`groupid`,`topic`,`partition`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1

代码实现
在线教育:知识点实时统计
import java.sql.{Connection, ResultSet}
import com.atguigu.qzpoint.util.{DataSourceUtil, QueryCallback, SqlProxy}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.SparkConf
import scala.collection.mutable
/**
* @description: 知识点掌握实时统计
* @author: HaoWu
* @create: 2020年10月13日
*/
object QzPointStreaming_V2 {
val groupid = "test1"
def main(args: Array[String]): Unit = {
/**
* 初始化ssc
*/
val conf: SparkConf = new SparkConf()
.setAppName("test1")
.setMaster("local[*]")
.set("spark.streaming.kafka.maxRatePerPartition", "100")
.set("spark.streaming.backpressure.enabled", "true")
val ssc = new StreamingContext(conf, Seconds(3))
/**
* 读取mysql历史的offset
*/
val sqlProxy = new SqlProxy()
val client: Connection = DataSourceUtil.getConnection
val offsetMap = new mutable.HashMap[TopicPartition, Long]
try {
sqlProxy.executeQuery(client, "select * from `offset_manager` where groupid=?", Array(groupid), new QueryCallback {
override def process(rs: ResultSet): Unit = {
while (rs.next()) {
val model = new TopicPartition(rs.getString(2), rs.getInt(3))
val offset = rs.getLong(4)
offsetMap.put(model, offset)
}
rs.close()
}
})
} catch {
case e: Exception => e.printStackTrace()
} finally {
sqlProxy.shutdown(client)
}
/**
* 消费kafka主题,获取数据流
*/
val topics = Array("qz_log")
val kafkaMap: Map[String, Object] = Map[String, Object](
"bootstrap.servers" -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> groupid,
"auto.offset.reset" -> "earliest",
//手动维护offset,要设置为false
"enable.auto.commit" -> (false: Boolean)
)
val inStream: InputDStream[ConsumerRecord[String, String]] = if (offsetMap.isEmpty) {
//第一次启动程序消费
KafkaUtils.createDirectStream(
ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaMap))
} else {
//程序挂了,恢复程序
KafkaUtils.createDirectStream(
ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaMap, offsetMap))
}
//*************************************************处理逻辑 开始**********************************************//
/**
* 逻辑处理的套路:统计当前批 + DB中历史的数据 => 更新DB中的表数据
*/
inStream
.filter(
record => record.value().split("\t") == 6
)
//*************************************************处理逻辑 结束**********************************************//
/**
* 逻辑处理完后,更新 mysql中维护的offset
*/
inStream.foreachRDD(rdd => {
val sqlProxy = new SqlProxy()
val client = DataSourceUtil.getConnection
try {
val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
for (or <- offsetRanges) {
sqlProxy.executeUpdate(client, "replace into `offset_manager` (groupid,topic,`partition`,untilOffset) values(?,?,?,?)",
Array(groupid, or.topic, or.partition.toString, or.untilOffset))
}
/*for (i <- 0 until 100000) {
val model = new LearnModel(1, 1, 1, 1, 1, 1, "", 2, 1l, 1l, 1, 1)
map.put(UUID.randomUUID().toString, model)
}*/
} catch {
case e: Exception => e.printStackTrace()
} finally {
sqlProxy.shutdown(client)
}
})
//启动
ssc.start()
//阻塞
ssc.awaitTermination()
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号