会员
周边
新闻
博问
闪存
赞助商
Chat2DB
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
来自遥远的水星
博客园
首页
新随笔
管理
2022年8月3日
Spark源码01【搭建Spark源码调试环境】
摘要: 搭建Spark源码调试环境 1.调试环境 可以根据官网的Spark 3.2的pom依赖查看各组件的版本 Mac + Jdk1.8 + Maven 3.63 + scala 2.12.15 + antlr + Spark 分支 3.2 1.1 java环境 1)编辑vi ~/.zshrc JAVA_H
阅读全文
posted @ 2022-08-03 15:10 来自遥远的水星
阅读(899)
评论(0)
推荐(0)
2022年8月2日
【数仓开发】5-Excel模板生成HiveDDL建表SQL
摘要: 根据excel模板生成Hive DDL建表SQL 1.excel模板 2.excel_gen_ddl_sql.py #!/usr/bin/python # -*- coding: utf-8 -*- """ 功能: excel数据仓库物理模型生成 ddl_表名.sql文件 输入数据:文件名以「数据模
阅读全文
posted @ 2022-08-02 15:04 来自遥远的水星
阅读(660)
评论(0)
推荐(0)
2022年7月6日
【数仓建模】1-维度建模维度表与事实表-解读版本
摘要: 维度建模理论 - 解读版 维度建模 维度建模(Kimball):分析决策的需求出发构建模型,为分析需求服务,因此 它重点关注用户如何更快速地完成需求分析,同时具有较好的大规模复 杂查询的响应性能。其典型的代表是星形模型,以及在一些特殊场景下 使用的雪花模型 --分享解读:区别于lnmon的范式建模,
阅读全文
posted @ 2022-07-06 12:37 来自遥远的水星
阅读(2267)
评论(0)
推荐(0)
【数仓开发】4-数仓多维模型构建
摘要: 一.背景 数仓建设中经常会有多个维度灵活组合看数的需求,这种多维分析的场景一般有两种处理方式 即时查询 适合计算引擎很强,查询灵活,并发量不大的场景 数据链路:明细数据hive表-> MPP计算引擎 预计算 适合有固定模式的聚合查询。预计算的结果可以被不同下游复用 数据链路: 明细数据-> 离线计算
阅读全文
posted @ 2022-07-06 12:36 来自遥远的水星
阅读(689)
评论(0)
推荐(0)
2022年6月26日
01数仓建模99-XMind结构图
摘要: 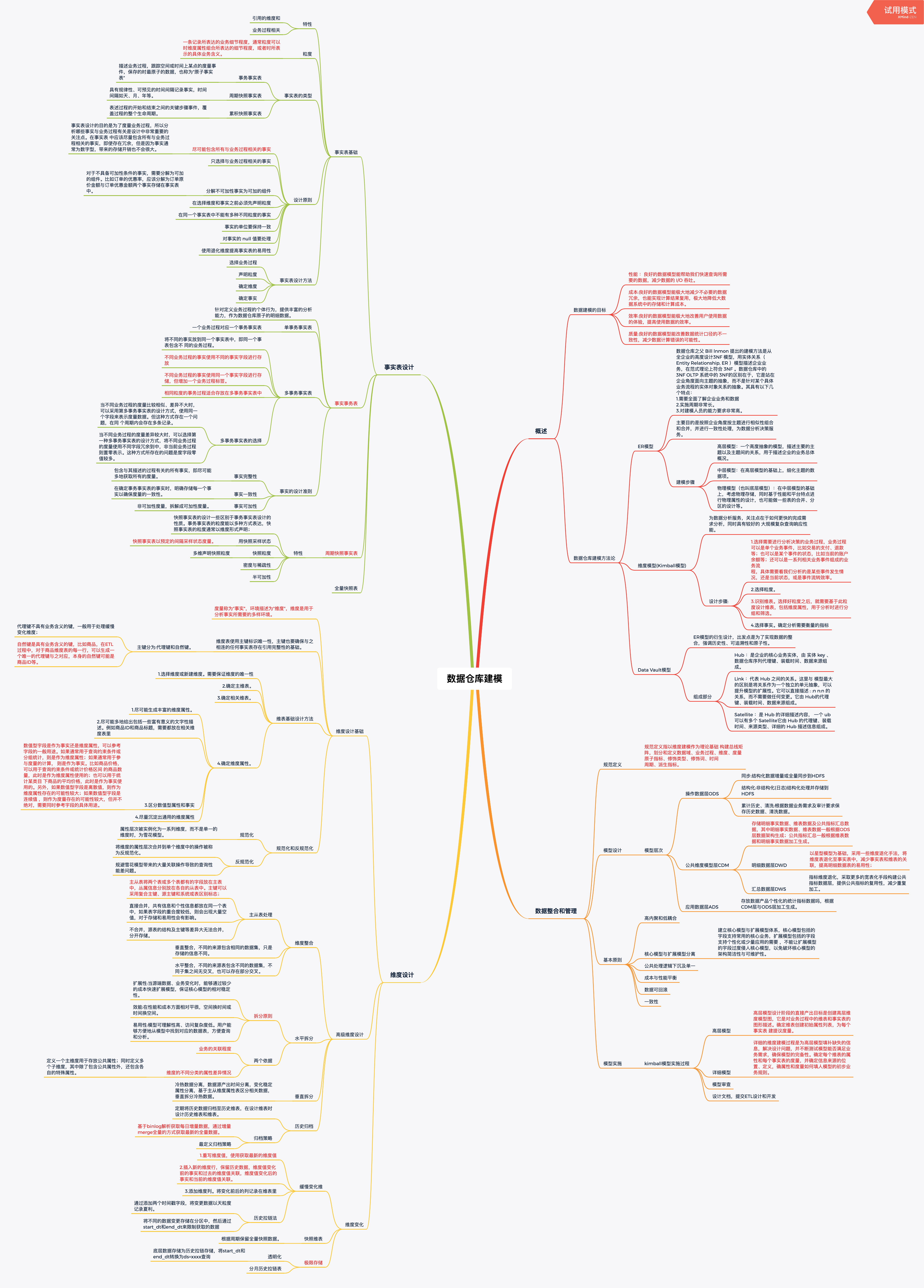
阅读全文
posted @ 2022-06-26 02:37 来自遥远的水星
阅读(118)
评论(0)
推荐(0)
Typora发布文章到博客园
摘要: Typora发布文章到博客园 1.导出脚本 cnblogs.json(配置文件) url 是MetaWeblog访问地址: https://rpc.cnblogs.com/metaweblog/wh984763176 注意:现在用户用户命名已经不能访问,需要创建个人令牌,令牌作为密码 { "url"
阅读全文
posted @ 2022-06-26 02:34 来自遥远的水星
阅读(184)
评论(1)
推荐(0)
2022年6月8日
Hive(十二)【参数调优】
摘要: 1. Limit 限制调整 一般情况下,limit语句还是需要执行整个查询语句,然后再返回部分结果。 有一个配置属性可以开启,避免这种情况:对数据源进行抽样。 hive.limit.optimize.enable=true -- 开启对数据源进行采样的功能 hive.limit.row.max.si
阅读全文
posted @ 2022-06-08 10:17 来自遥远的水星
阅读(332)
评论(0)
推荐(0)
2021年8月3日
实时数仓(二):DWD层-数据处理
摘要: 实时数仓(二):DWD层-数据处理 1.数据源 dwd的数据来自Kafka的ods层原始数据:业务数据(ods_base_db) 、日志数据(ods_base_log) 从Kafka的ODS层读取用户行为日志以及业务数据,并进行简单处理,写回到Kafka作为DWD层。 2.用户行为日志 2.1开发环
阅读全文
posted @ 2021-08-03 15:21 来自遥远的水星
阅读(1481)
评论(0)
推荐(0)
2021年7月30日
Flink(九)【Flink的重启策略】
摘要: 1.Flink的重启策略 Flink支持不同的重启策略,这些重启策略控制着job失败后如何重启。集群可以通过默认的重启策略来重启,这个默认的重启策略通常在未指定重启策略的情况下使用,而如果Job提交的时候指定了重启策略,这个重启策略就会覆盖掉集群的默认重启策略。 2.重启策略 2.1未开启check
阅读全文
posted @ 2021-07-30 17:22 来自遥远的水星
阅读(1097)
评论(0)
推荐(0)
Hbase(6)【Java Api Phoenix操作Hbase】
摘要: 两种方式操作Phoenix 官网:http://phoenix.apache.org/faq.html#What_is_the_Phoenix_JDBC_URL_syntax What is the Phoenix JDBC URL syntax? 1.Thick Driver pom依赖 <dep
阅读全文
posted @ 2021-07-30 11:56 来自遥远的水星
阅读(642)
评论(0)
推荐(0)
下一页
 浙公网安备 33010602011771号
浙公网安备 33010602011771号