Flink(一)【基础入门,Yarn、Local模式】
一.介绍
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。
Spark | Flink
-
spark
处理方式:批处理
延时性:高延迟(采集周期)
缺点:精准一次性消费,错乱延迟数据,延迟高
-
flink
处理方式:流处理(有界,无界)
延时性:低延迟
优点:①灵活的窗口 ②Exactly Once语义保证
二.快速入门:WC案例
pom依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.10.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.11</scala.binary.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
<log4j.version>2.12.1</log4j.version>
</properties>
<!-- flink的依赖 开始 -->
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<!-- flink的依赖 结束 -->
<!--打包插件 -->
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
批处理
Java代码
/**
* @description: WordCount 批处理
* @author: HaoWu
* @create: 2020年09月15日
*/
public class WC_Batch {
public static void main(String[] args) throws Exception {
// 0.创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 1.读取数据
DataSource<String> fileDS = env.readTextFile("D:\\SoftWare\\idea-2019.2.3\\wordspace\\13_flinkdemo\\input");
// 2.扁平化 ->(word,1)
AggregateOperator<Tuple2<String, Integer>> reuslt = fileDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
// 2.1切分
String[] words = s.split(" ");
// 2.2转为二元Tuple
for (String word : words) {
Tuple2<String, Integer> tuple = Tuple2.of(word, 1);
collector.collect(tuple);
}
}
}) // 3.分组
.groupBy(0)
// 4.求sum
.sum(1);
// 3.输出保存
reuslt.print();
// 4.启动
}
}
控制台
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
(flink,2)
(hello,4)
(sparksql,1)
(spark,1)
Process finished with exit code 0
流处理
有界流
Java代码
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
/**
* @description: WordCount 批处理
* @author: HaoWu
* @create: 2020年09月15日
*/
public class WC_Batch {
public static void main(String[] args) throws Exception {
// 0.创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 1.读取数据
DataSource<String> fileDS = env.readTextFile("D:\\SoftWare\\idea-2019.2.3\\wordspace\\13_flinkdemo\\input");
// 2.扁平化 ->(word,1)
AggregateOperator<Tuple2<String, Integer>> reuslt = fileDS.flatMap((FlatMapFunction<String, Tuple2<String, Integer>>) (s, collector) -> {
// 2.1切分
String[] words = s.split(" ");
// 2.2转为二元Tuple
for (String word : words) {
Tuple2<String, Integer> tuple = Tuple2.of(word, 1);
collector.collect(tuple);
}
}).returns(new TypeHint<Tuple2<String, Integer>>(){})
// 3.分组
.groupBy(0)
// 4.求sum
.sum(1);
// 5.输出保存
reuslt.print();
// 6.执行(批处理不需要启动)
}
}
控制台
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
7> (flink,1)
7> (flink,2)
1> (spark,1)
3> (hello,1)
3> (hello,2)
3> (hello,3)
3> (hello,4)
3> (sparksql,1)
Process finished with exit code 0
无界流(重要)
Java代码
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @description: 无界流(有头无尾)
* @author: HaoWu
* @create: 2020年09月15日
*/
public class Flink03_WC_UnBoundedStream {
public static void main(String[] args) throws Exception {
// 0.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 1.读取数据
DataStreamSource<String> fileDS = env.socketTextStream("hadoop102", 9999);
// 2.扁平化:转换(word,1)
SingleOutputStreamOperator<Tuple2<String, Integer>> result = fileDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
// 2.1切分
String[] words = s.split(" ");
// 2.2收集写出下游
for (String word : words) {
collector.collect(Tuple2.of(word, 1));
}
}
}) // 3.分组
.keyBy(0)
// 4.求sum
.sum(1);
// 5.输出
result.print();
// 6.执行
env.execute();
}
}
nc工具 Socket 输入
[root@hadoop102 ~]$ nc -lk 9999
a
f
d
af
dafda
fafa
a
a
b
a
控制台
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
6> (a,1)
2> (f,1)
5> (d,1)
4> (af,1)
7> (dafda,1)
3> (fafa,1)
6> (a,2)
6> (a,3)
2> (b,1)
6> (a,4)
注意
①tuple的两种写法:Tuple2.of(word, 1)、new Tuple2<>(word,1)。
②匿名对象、lamda两种写法。
③不要导错包,用java的,别选成scala的了。
三.Yarn模式部署
官网介绍:https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/deployment/yarn_setup.html#run-a-flink-job-on-yarn
有多种部署模式,local,standalone,yarn,windows等,本文只介绍yarn。
安装
前提已经部署hdfs,yarn,解压即用
将flink-1.10.0-bin-scala_2.11.tgz文件上传到Linux并解压缩,放置在指定位置,路径中不要包含中文或空格
tar -zxvf flink-1.10.0-bin-scala_2.11.tgz -C /opt/module
打包测试,命令行(无界流)
运行无界流的job,使用nc工具测试,默认提交的模式是Per-job方式。
当前yarn模式不支持webUI方式提交,standalone模式可以用webUI提交。
bin/flink run -m yarn-cluster -c com.flink.chapt01.Flink03_WC_UnBoundedStream /opt/module/testdata/flink-wc.jar
FAQ报错
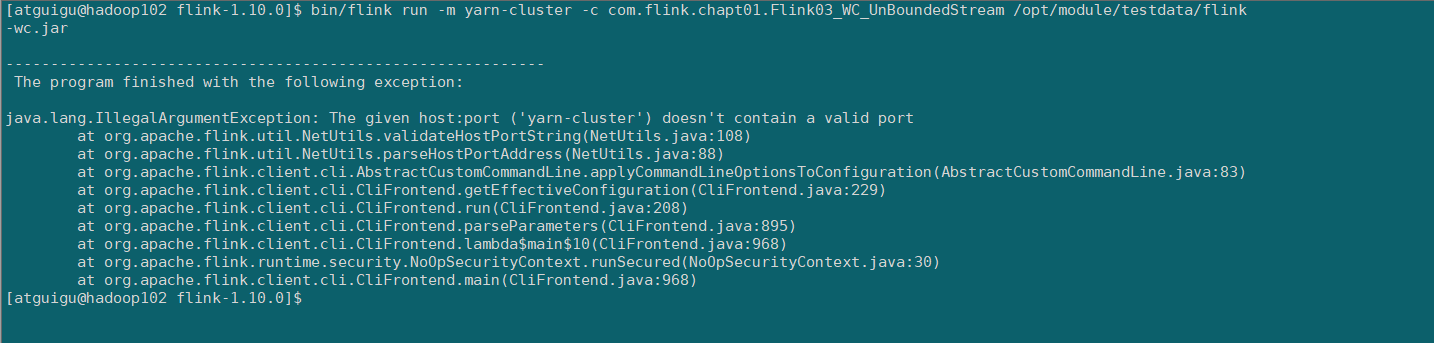
解决方案
错误的原因是Flink1.8版本之后,默认情况下类库中是不包含hadoop相关依赖的,所以提交时会发生错误,,引入hadoop相关依赖jar包即可:flink-shaded-hadoop-2-uber-3.1.3-9.0.jar
上传后,重新执行上面的指令即可。运行过程可以通过Yarn的应用服务页面查看
cp /opt/software/flink/flink-shaded-hadoop-2-uber-3.1.3-9.0.jar /opt/module/flink-1.10.0/lib/
重新执行任务提交

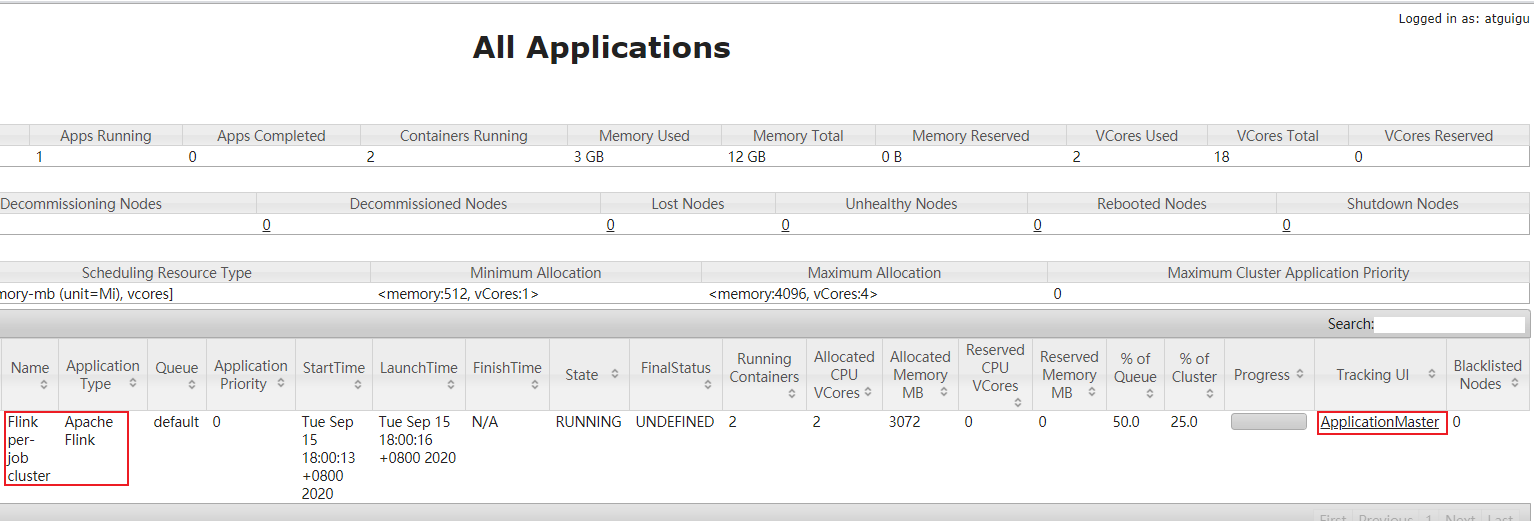
启动nc工具进行测试

Flink on Yarn
Flink提供了两种在yarn上的运行模式,分别是Session-Cluster和Per-Job-Cluster模式。
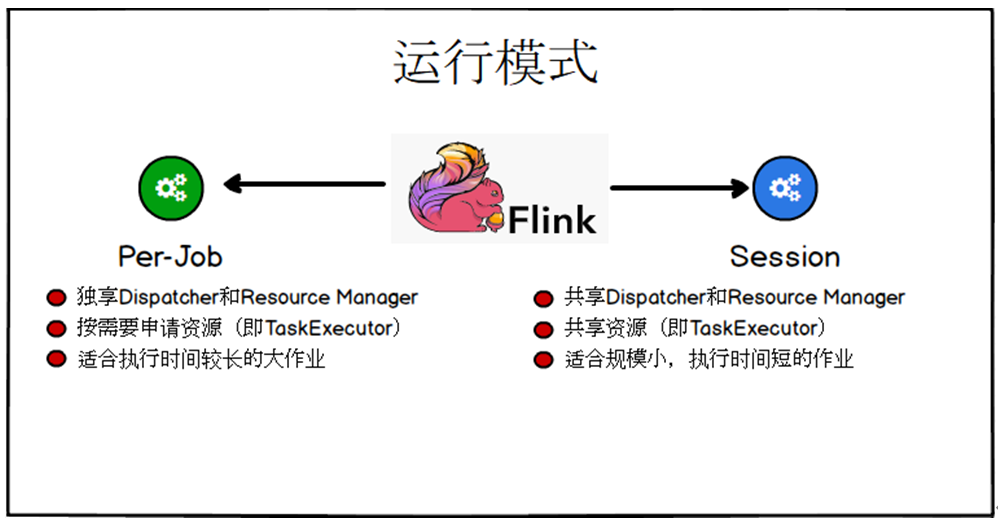
Per-Job-Cluster
在上面的应用程序提交时,一个Job会对应一个yarn-session集群,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享Dispatcher和ResourceManager,按需接受资源申请;适合规模大长时间运行的作业
通过-m yarn-cluster 参数来指定运行模式
bin/flink run -m yarn-cluster -c com.flink.chapt01.Flink03_WC_UnBoundedStream /opt/module/testdata/flink-wc.jar
查看相关参数help:bin/flink run -m yarn-cluster -h
这种方式每次提交都会创建一个新的flink集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。
Session-Cluster
在规模小执行时间短的作业执行时,频繁的申请资源并不是一个好的选择,所以Flink还提供了一种可以事先申请一定资源,然后在这个资源中并行执行多个作业的集群方式。

在yarn中初始化一个flink集群,开辟指定的资源,以后提交任务都向这里提交。这个flink集群会常驻在yarn集群中,除非手工停止。
Session-Cluster集群模式和Per-Job-Cluster不一样的是需要事先创建Yarn应用后再提交Flink应用程序
①创建Yarn应用
bin/yarn-session.sh -d -n 2 -s 2 -jm 1024 -tm 1024 -nm test
查看参数help:bin/yarn-session.s -h
注意:flink新的版本 -n,-s 参数将不再有效,Yarn会按需动态分配资源 。以后不要加这两个参数了。
webUI可以观察,当前flink版本1.10
没有任务,也没有资源分配

相关参数
| 参数 | 含义 |
|---|---|
| 守护模式,daemon | |
| -n(--container) | TaskManager的数量 |
| -s(--slots) | 每个TaskManager的slot数量,默认一个slot一个core,默认每个taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余 |
| -jm | JobManager的内存(单位MB) |
| -tm | 每个Taskmanager的内存(单位MB) |
| -nm | yarn 的appName(现在yarn的ui上的名字) |
| -d | 后台执行,需要放在前面,否则不生效 |
②再提交任务
bin/flink run -c com.flink.chapt01.Flink03_WC_UnBoundedStream /opt/module/testdata/flink-wc.jar
可以发现yarn分配了资源
HA高可用
不是传统的高可用,就是利用yarn的重试机制,job失败,再重新启动,根据配置重试4次,kill掉YarnSessionClusterEntrypoint,YarnSessionClusterEntrypoint一会又自动起来
- 配置yarn最大重试次数%HADOOP_HOME%/etc/hadoop/yarn-site.xml,分发文件
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
</property>
- 修改conf/flink-conf.yaml配置文件
配置参数中冒号后面的参数值都需要增加空格
yarn.application-attempts: 4
# Line79
high-availability: zookeeper
# Line88
high-availability.storageDir: hdfs://hadoop102:9000/flink/ha/
# Line94
high-availability.zookeeper.quorum: hadoop102:2282,hadoop103:2282,hadoop104:2282
- 修改conf/master配置文件
Hadoop102:8081
Hadoop103:8081
Hadoop104:8081
- 修改zoo.cfg配置文件
也可以用外部的zk集群
#Line 32 防止和外部ZK冲突
clientPort=2282
#Line 35
server.88=hadoop102:2888:3888
server.89=hadoop103:2888:3888
server.90=hadoop104:2888:3888
5)分发flink
xsync flink
6)启动Flink Zookeeper集群
bin/start-zookeeper-quorum.sh
- 启动Flink Session应用
bin/yarn-session.sh -d -jm 1024 -tm 1024 -nm test
如果此时将YarnSessionClusterEntrypoint进程关闭,WebUI界面会访问不了
那么稍等后,Yarn会自动重新启动Cluster进程,就可以重新访问了。
五.Linux本地模式
1.安装
-
前提、安装Java 1.8.x以上
-
下载flink安装包:flink-1.10.0-bin-scala_2.11.tgz
-
解压安装包:tar -zxvf flink-1.6.2-bin-scala_2.11.tgz
2.启动
-
本地模式启动:
1)切换目录:cd /opt/module/flink-1.10.0
2)启动/bin/start-cluster.sh -
查看webUI:http://hadoop102:8081
-
查看jps
[hadoop@hadoop102 bin]$ jps
10131 TaskManagerRunner
9831 StandaloneSessionClusterEntrypoint
15486 Jps
3.案例
-
1.启动nc工具:
nc -l 9000 -
2.提交flink程序
案例程序:WordCount在5秒的时间窗口中计算(处理时间,滚动窗口)并打印到标准输出
bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000 Starting execution of program -
3.查看webUI:程序正常启动
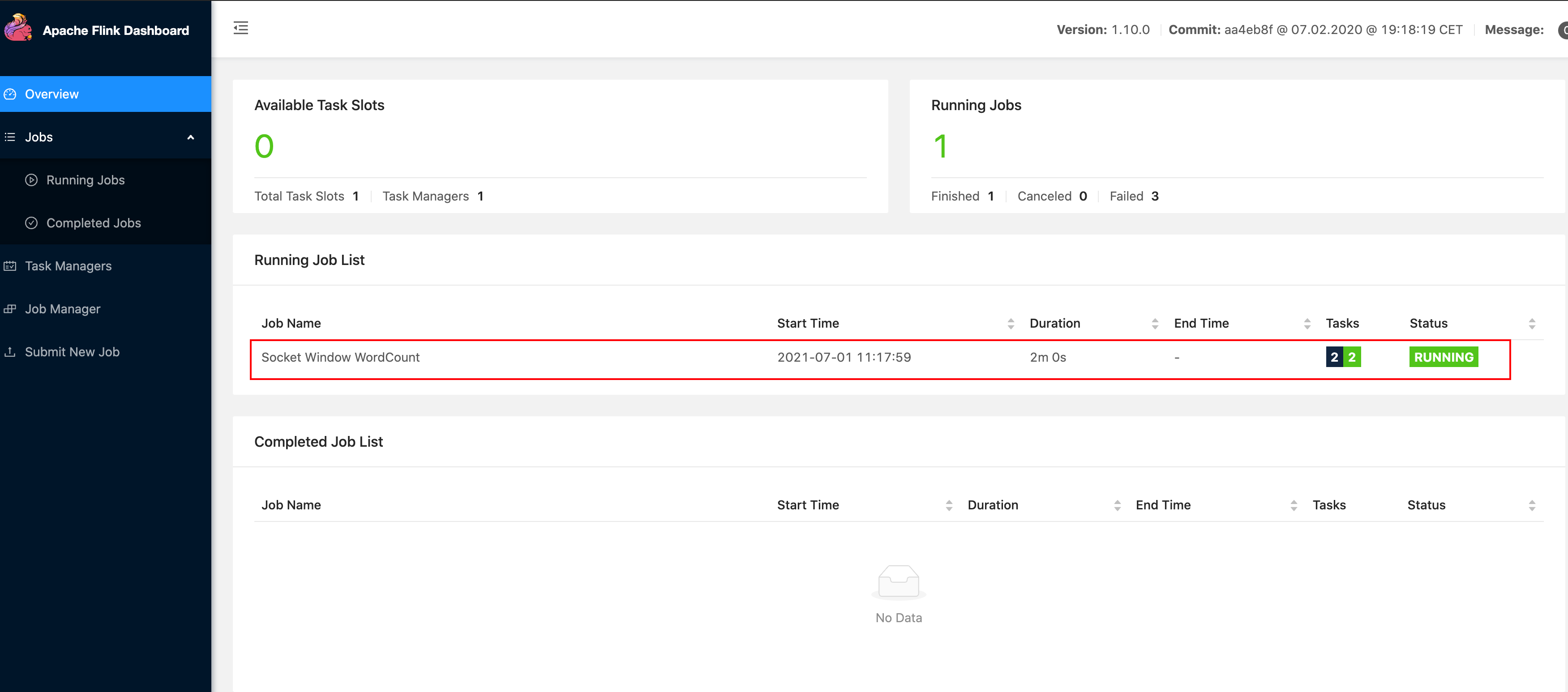
-
4.nc工具输入参数
[hadoop@hadoop102 ~]$ nc -l 9000 1 2 3 4 5 6 3 4 5 5 1 1 1 1 1 -
5.观察输出打印
-
1)方式一: 通过WebUI
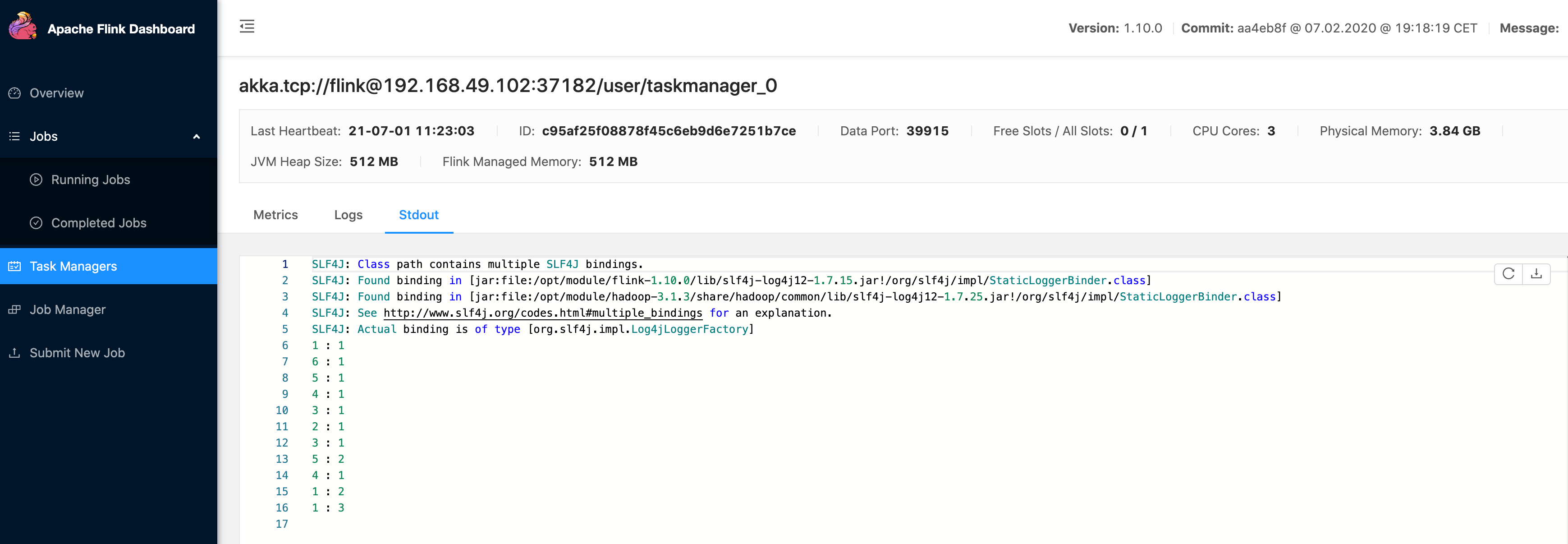
-
2)方式二:查看taskmanager的输出日志
[hadoop@hadoop102 log]$ pwd /opt/module/flink-1.10.0/log [hadoop@hadoop102 log]$ tail -f flink-atguigu-taskexecutor-0-hadoop102.out 6 : 1 5 : 1 4 : 1 3 : 1 2 : 1 3 : 1 5 : 2 4 : 1 1 : 2 1 : 3
说明:yarn模式,任务停止后可以通过
yarn logs -applicationId application_1625031122720_35602 > log下载日志到本地看 -
4.关闭
./bin/stop-cluster.sh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号