Kafka(一)【概述、入门、架构原理】
一.Kafka概述
1.1 定义
Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
消息队列是解决生产中同步异步问题,解耦,削峰。
应用场景:一般用于实时业务,离线偶尔用来削峰。
二.Kafka快速入门
2.1 安装部署
集群规划
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| zk | zk | zk |
| kafka | kafka | kafka |
Kafka下载:http://kafka.apache.org/downloads.html
安装步骤
1)下载安装包
2)解压安装包到指定目录
tar -zxvf kafka_2.11-2.4.1.tgz -C /opt/module/
3)修改解压后文件名
mv kafka_2.11-2.4.1.tgz kafka
4)修改配置文件
vim /opt/module/kafka/conf/server.properties
2.2 配置文件解析
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能,当前版本此配置默认为true,已从配置文件移除
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志存放的路径
log.dirs=/opt/module/kafka/datas
#topic在当前broker上的分区个数,默认1个分区
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,默认7天,超时将被删除
log.retention.hours=168
#配置连接Zookeeper集群地址
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
按照以上配置文件进行配置
注意
1.集群环境要求各个broker的id唯一
2.log.dir=datas(默认是将本身日志文件和数据(消息)是存在一起的,后来做了日志分离)
3.zk集群各节点的配置
5)分发安装包
xsync kafka
6)修改其他节点的broker.id
7)启动Kafka集群
先启动zookeeper集群
zk.sh start
在各节点依次启动kafka
[hadoop@hadoop102 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[hadoop@hadoop103 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[hadoop@hadoop104 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
8)关闭Kafka集群
[hadoop@hadoop102 kafka]$ bin/kafka-server-stop.sh stop
[hadoop@hadoop103 kafka]$ bin/kafka-server-stop.sh stop
[hadoop@hadoop104 kafka]$ bin/kafka-server-stop.sh stop
2.3Kafka群起脚本
#!/bin/bash
case $1 in
"start")
for i in hadoop102 hadoop103 hadoop104
do
echo "============== $i kafka============== "
ssh $i /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties
done
;;
"stop")
for i in hadoop102 hadoop103 hadoop104
do
echo "============== $i kafka============== "
ssh $i /opt/module/kafka/bin/kafka-server-stop.sh
done
;;
esac
2.4 topic(增删改查)
增
bin/kafka-topics.sh --create --bootstrap-server hadoop102:9092 --topic tn(默认单分区 单副本)
bin/kafka-topics.sh --create --bootstrap-server hadoop102:9092 --topic tn --partitions n --replication-factor n(小于或者等于 集群的数量)
删
bin/kafka-topics.sh --delete --bootstrap-server hadoop102:9092 --topic tn(一开始标记清楚,过段时间自己删除)
改
[hadoop@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter –-topic first --partitions 2
查
bin/kafka-topics.sh --list --bootstrap-server hadoop102:9092 (列出所有可用的主题)
bin/kafka-topics.sh --describe --bootstrap-server hadoop102:9092 (列出所有主题的详情信息)
bin/kafka-topics.sh --describe --bootstrap-server hadoop102:9092 --topic tn(列出指定主题的详情信息)
2.5 生产和消费者命令行操作
1.生产者的命令行
bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic tn
2.消费者的命令行
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic tn
3.消费者的命令行指定消费者组
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic tn --consumer.config config/consumer.properties
3.消费者的命令行指定消费者组
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic tn --group gn
4.消费者的命令行从头开始消费 (同一个消费者组,第一次消费这个订阅主题的数据)
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic tn --from-beginning
三.Kafka架构
3.1 基础架构
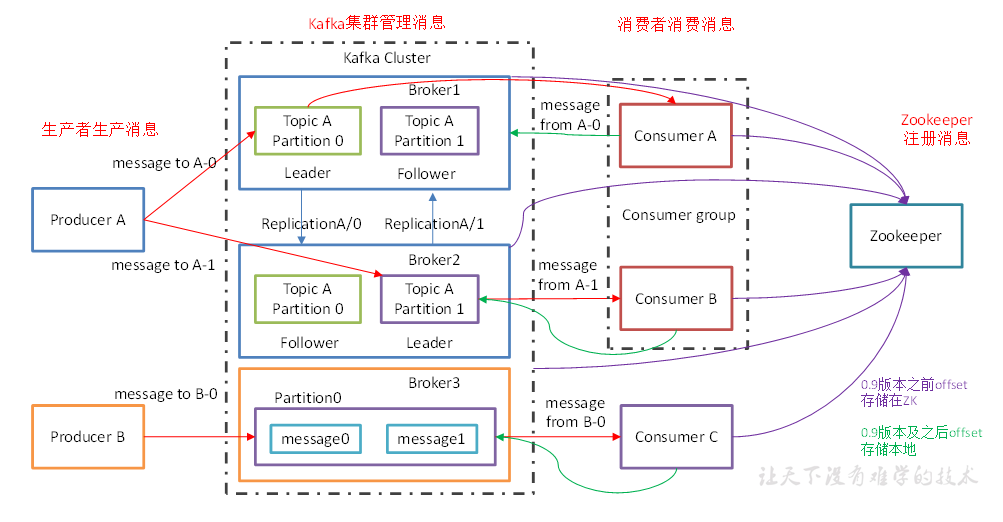
角色介绍
1)producer:消息的生产者,往kafka broker发送消息的客户端。
2)consumer:消息的消费者,从kafka broker拉取数据消费的客户端。
3)consumer group:消费者组,消费者组topic逻辑上的订阅者,由多个消费者组成。
4)broker:一台kafka服务器就是一个broer。
5)topic:可以理解为一个队列,生产者和消费者面向的都是一个队列。
6)partition:为了提高扩展性,一个topic可以分成多个partition,分布在多个broker上。
7)replica:副本,每个partition都有对应得副本,一个leader和多个follower组成。
8)leader:每个partition副本的“主节点”,生产者发送数据,消费者消费数据都是与leader交互。
9)follower:每个partition副本的“从节点”,负责实时的与leader保持数据同步,以及当leader发生故障的时候,及时的顶上去成为新的leader。
10)offset:偏移量。记录消息的位置,消费者可以知道上次消费到哪个位置。
3.2 文件存储
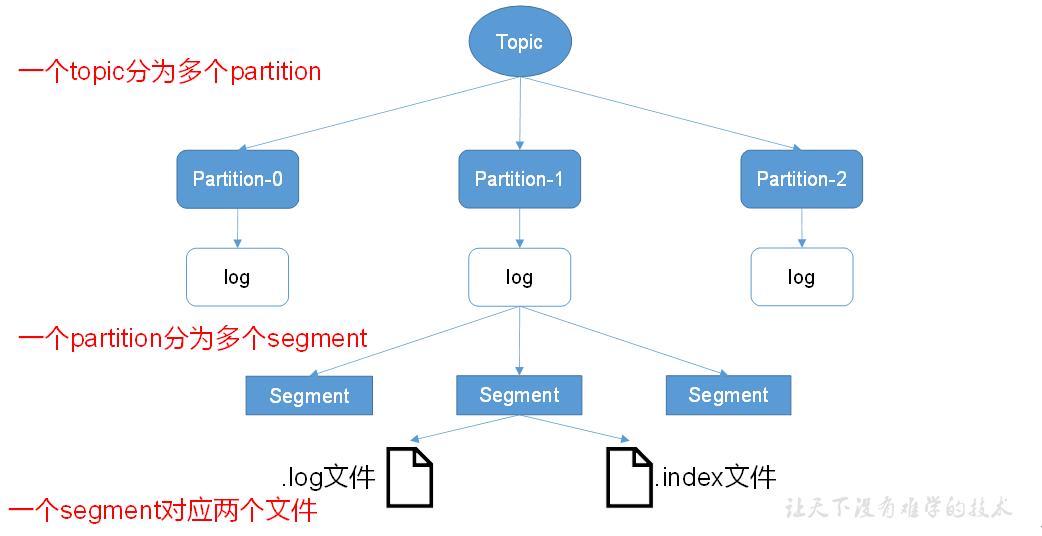
kafka中的消息是以topic进行分类,生产者生产消息和消费者消费消息都是面向topic的。
topic 是逻辑上的概念,partition 是物理上的概念,每个partition对应于一个log文件,生产者生产的消息被追加到改log文件末端,每条消息都有自己的offset ;由于生产者会不断顺序追加到log文件末端,为了防止文件过大,导致数据定位效率低下,kafka采用了分片和索引的机制,每个partition 又被分为多个segment,每个segment中有2个文件,一个.inex文件,一个.log文件,这些文件在一个文件夹下,文件夹命名:topic名-分区号,如first这个topic有三个分区,则其对应的文件夹为first-0,first-1,first-2。
问题:消费者如何根据offset找到需要消费的数据?
答:1.通过log文件命名规则使用二分查找,快速定位到数据在哪个.log文件中。
2.然后通过对应得index文件,该文件为对应得.log文件构建了稀疏索引,并不是为每一条数据都构建索引,避免了空间的浪费,后期通过索引文件快速定位到要找到数据在.log文件的区间,然后扫描获取数据。
3.3 生产者
3.3.1 分区策略
分区原因
(1)分布式存储,方便扩展。(2)提高并发读写。
分区规则
producer发送的数据会被封装成一个ProducerRecord对象
(1)如果指定了partition,就直接发往指定分区。
(2)如果没有指定partition,指定了key,就是key的hashcode值对分区数进行取模。
(3)如果没有指定partition,也没有指定key,那么第一次发消息会生成一个随机数,对分区数取模,得到分区号,第二次会将第一次的随机数加1,然后再对分区取模,得到分区号,后面以此类推获取分区号
3.3.2 数据可靠性
为了保证producer发送的数据,可靠地发往指定的topic的partition,每个partition的leader收到消息后都要向producer发送ack,如果producer收到ack,就会进行下一轮的发送,否则再重新发送一次数据。
ack应答分为3个级别:
ack=0:producer将消息发给leader后,leader马上返回ack。问题:数据丢失。
ack=1:producer将消息发给leader,等到leader将数据落盘后返回ack。 问题:数据丢失。
ack= -1:producer将消息发送给leader后,等到leader将数据落盘,ISR中的follower都同步完数据后再返回ack。问题:数据重复
ISR:副本同步队列。在isr中的follower同步leader数据,当超过一定的时间还是未同步leader数据就被踢出ISR,这个时间的设置是replica.lag.time.max.ms这个参数设置的,当leader发生故障会从ISR中选举出新leader。
ISR+OR=AR
LEO:每个follower中最后的offset。
HW:所有follower中最小的LEO。HW之前的数据对消费者可见。
3.3.3 Exactly Once
幂等性+At Least Once= Exactly Once
在producer中开启幂等性,将参数enable.idempotence设置为true。开启幂等性后,producer初始化生成一个PID,还有Partition和Sequence number(PID+Partition+SequnceNumber),维护了一个唯一主键,进行去重。
问题:如果producer重启,会重新生成producerid,导致主键不一样。数据重复
通过producer事务+幂等性+ack=-1可以保证数据exactly once
一个全局唯一的Transaction ID和PID绑定,这样即使重启producer也能保证主键唯一。
3.4消费者
3.4.1消费方式
consumer从kafka中拉取数据,能够自己控制消费的速率。拉取的缺点是kafka中如果没有数据,消费中会陷入循环,不断返回空数据,kafka的处理是设置一个时间timeout,如果没有数据消费,就等一段时间再进行拉取。
3.4.2分区分配策略
Kafka有两种分配策略,一是RoundRobin,一是Range
3.4.2offset的维护
0.9版本之前,offset保存在Zookeeper;
0.9版本后,offset保证在kafka的内置topic中,该topic是_consumer_offsets
3.5 leader、follower故障
follower
follower挂掉会被踢出ISR,当follower恢复后,会从磁盘读取上次记录的HW,并将log文件高于HW的部分截掉掉,再从HW开始同步leader,等到该follower追上leader后会被重新加入ISR。
leader
leader挂掉之后会从follower中选出新leader,其余follower先将各自高于HW的部分截掉,然后从新leader同步数据
3.6 高效读写
(1)分区,提高并发读写。
(2)顺序写,producer生产的数据是以追加的形式顺序写到log文件末端。随机写需要大量的寻址时间,所以顺序写的效率远高于随机写。
(3)页缓存,是在内存开辟的空间,
好处:
1.批量写 提高性能
2.在页缓存内部排序,写的时候减少磁盘寻址时间
3.如果网络好的情况下,读写速率相同,此时可以直接从页缓存获取数据
(4)零拷贝,数据先拷贝到page cache中将数据从pagecache拷贝到网卡
3.7 zookeeper在kafka中的作用
1.选controller
broker启动的时候会选出kafka controller,controller负责管理broker的上下线,leader选举,
分区副本分配。
2.leader选举过程
1)broker启动会先选出controller。
2)broker会在zookeeper上在/kafka/brokers/ids/节点注册节点信息,controller会监控这些节点信息。
3)broker中的每个partition的leader和follower会在zookeeper上注册分区信息,包括[leader,follower,isr]
4)leader挂了,controller知道,controller去zookeeper获取注册的信息,如[leader,follower,isr],然后进行leader选举,更新zookeeper上的注册信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号