Flume对接Kafka
一.简单实现
需求:根据 flume 监控 exec 文件的追加数据,写入 kafka 的 test-demo 分区,然后启用 kafka-consumer 消费 test-demo 分区数据。
需求分析
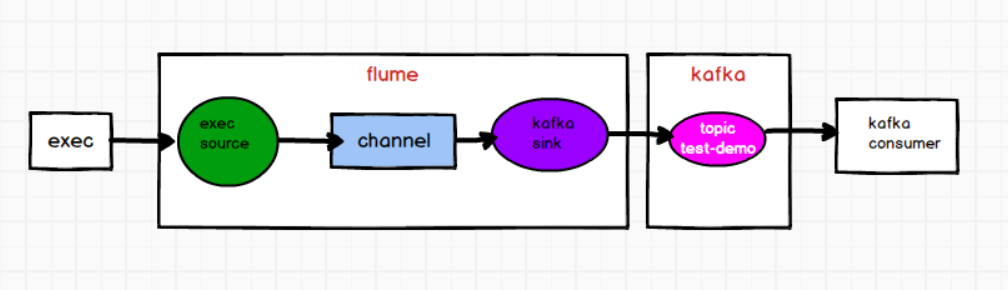
1)flume的配置文件
在hadoop102上创建flume的配置文件
# define
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/testdata/3.txt
# sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#kafka的broker主机和端口
a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
#kafka sink发送数据的topic
a1.sinks.k1.kafka.topic = test-demo
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2)启动 zk、kafka集群
3)创建 test-demo 主题
bin/kafka-topics.sh --create --bootstrap-server hadoop102:9092 --topic test-demo --partitions 2 --replication-factor 2
4)启动 kafka consumer 去消费 test-demo 主题
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic test-demo
aaa
5)启动 flume,并且往 3.txt 中追加数据
bin/flume-ng agent -c conf/ -f job/flume-kafka/flume-exec-kafka.conf -n a1
echo hello >> /opt/module/testdata/3.txt
6)观察 kafka consumer 的消费情况
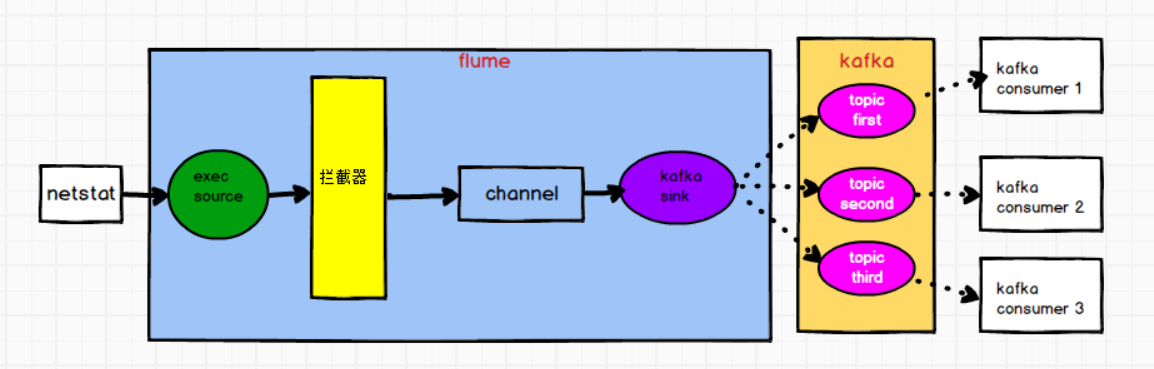
二.自定义interceptor(使用kafka sink)
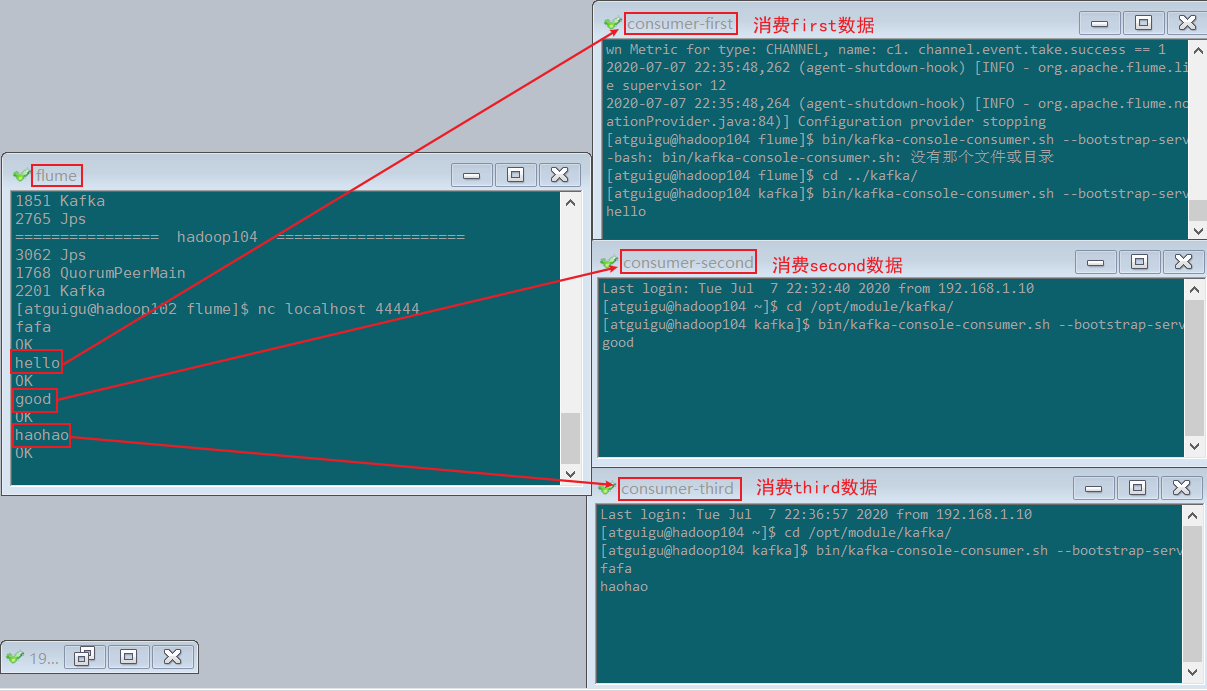
需求:flume监控 exec 文件的追加数据,将flume采集的数据按照不同的类型输入到不同的topic中
将日志数据中带有的 hello 的,输入到kafka的 first 主题中,
将日志数据中带有 good 的,输入到kafka的 second 主题中,
其他的数据输入到kafka的 third 主题中
需求分析
通过自定义 flume 的拦截器,往 header 增加 topic 信息 ,配置文件中 kafka sink 增加 topic 配置,实现将数据按照指定 topic 发送。
1)自定义 flume 拦截器
创建工程,pom依赖
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
自定义拦截器类,并打包上传至/opt/module/flume/lib包下
package com.bigdata.intercepter;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* @description: TODO 自定义flume拦截器
* @author: HaoWu
* @create: 2020/7/7 20:32
*/
public class FlumeKafkaInterceptorDemo implements Interceptor {
private List<Event> events;
//初始化
@Override
public void initialize() {
events = new ArrayList<>();
}
@Override
public Event intercept(Event event) {
// 获取event的header
Map<String, String> header = event.getHeaders();
// 获取event的boby
String body = new String(event.getBody());
// 根据body中的数据设置header
if (body.contains("hello")) {
header.put("topic", "first");
} else if (body.contains("good")) {
header.put("topic", "second");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
// 对每次批数据进来清空events
events.clear();
// 循环处理单个event
for (Event event : events) {
events.add(intercept(event));
}
return events;
}
@Override
public void close() {
}
// 静态内部类创建自定义拦截器对象
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new FlumeKafkaInterceptorDemo();
}
@Override
public void configure(Context context) {
}
}
}
2)编写 flume 的配置文件
flume-netstat-kafka.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
#Interceptor
a1.sources.r1.interceptors = i1
#自定义拦截器全类名+$Builder
a1.sources.r1.interceptors.i1.type = com.bigdata.intercepter.FlumeKafkaInterceptorDemo$Builder
# Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#默认发往的topic
a1.sinks.k1.kafka.topic = third
a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3)创建topic
在kafka中创建 first , second , third 这3个topic
[hadoop@hadoop102 kafka]$ bin/kafka-topics.sh --list --bootstrap-server hadoop102:9092
__consumer_offsets
first
second
test-demo
third
4)启动各组件
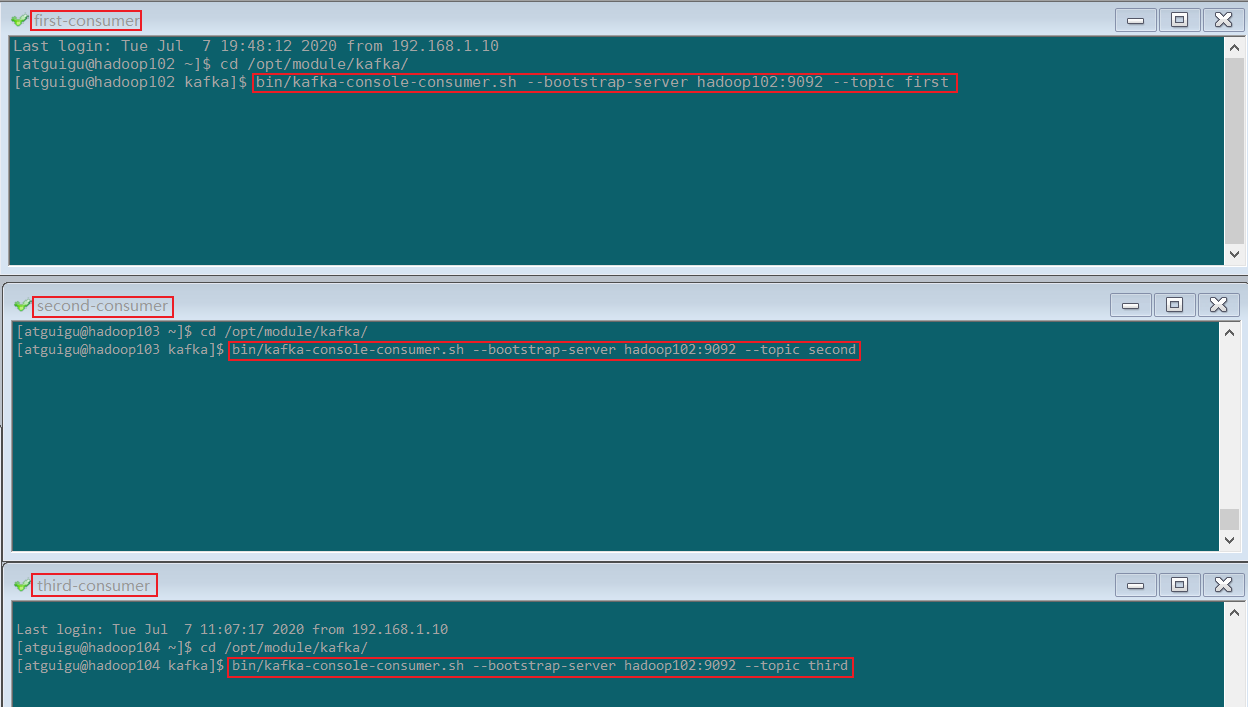
启动3个 kafka consumer 分别消费 first , second , third 中的数据
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic second
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic third
5)启动 flume,通过netstat发送数据到flume
bin/flume-ng agent -c conf/ -f job/flume-kafka/flume-netstat-kafka.conf -n a1
nc localhost 44444
6)观察消费者的消费情况
三.自定义interceptor(使用kafka channel)
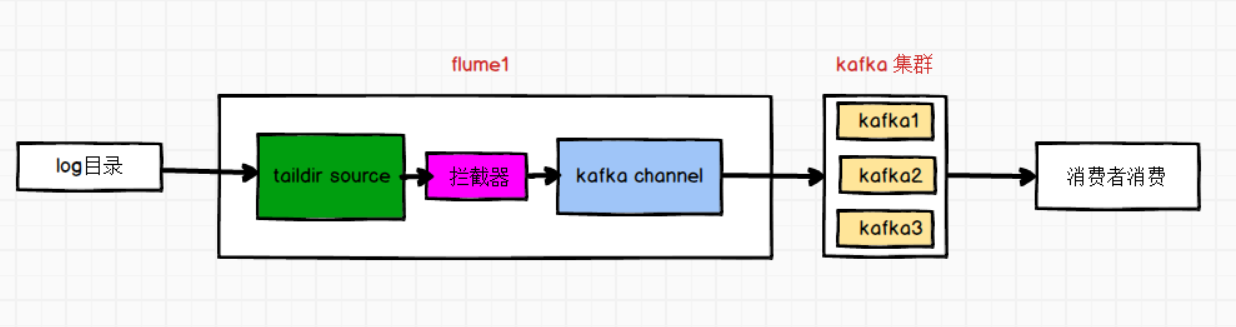
需求:使用taildir source监控/opt/module/applog/log文件夹下的文件,使用拦截器过滤非json的数据,使用kafka channel对接 kafka,将数据发往指定topic。
需求分析
使用kafka channel不需要sink
1)自定义拦截器
创建maven工程
pom文件
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
编写拦截器类:ETLInterceptor.java
package com.bigdata;
import com.alibaba.fastjson.JSON;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.Iterator;
import java.util.List;
/**
* @description: TODO 自定义拦截器,简单的ETL清洗
* @author: HaoWu
* @create: 2020/7/10 18:14
*/
public class ETLInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
String s = new String(event.getBody());
try {
JSON.toJSON(s);
return event;
} catch (Exception e) {
return null;
}
}
@Override
public List<Event> intercept(List<Event> events) {
Iterator<Event> iterator = events.iterator();
while (iterator.hasNext()){
Event e = iterator.next();
if(e==null){
iterator.remove();
}
}
return events;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new ETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
打包,将有依赖的包上传到%Flume_HOME%/lib目录下
2)flume配置
bigdata-applog-kafka.conf
#描述agent
a1.sources = r1
a1.channels = c1
#描述source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
#拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.bigdata.ETLInterceptor$Builder
#描述channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.channels.c1.kafka.topic = applog
a1.channels.c1.parseAsFlumeEvent = false
#关联source->channel->sink
a1.sources.r1.channels = c1
3)启动各组件
启动zookeeper、kafka-->启动消费者消费applog主题-->启动flume-->观察消费者
#消费者消费applog
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic applog --from-beginning
#启动flume
bin/flume-ng agent -n a1 -c conf/ -f job/bigdata-applog-kafka.conf
consumer消费到数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号