


ThreadPoolExecutor以及计数器CountDownLatch的使用
一:ThreadPoolExecutor的使用
项目中用到夜间跑批的问题,考虑使用多线程同时跑批,每次拿出100批数据,创建定长线程池,长度
为10,然后将这100批数据分成10份,10个线程各自处理自己的那一部分,每当有一个线程处理完成后就会
进入等待,计数器减1,直到计数器为0时,说明每个线程都完成了自己的工作,然后进入主线程执行。
1:创建定长线程池
1 public static final int THREAD_NUM = 10; 2 public ExecutorService threadPool = Executors.newFixedThreadPool(THREAD_NUM);// 创建10个线程放入线程池内
2:创建线程任务
1 public class myRun implements Runnable{ 2 3 private List<Map<String,Object>> tmpList; 4 private int threadCount; 5 private CountDownLatch countdown; 6 private int oneThreadCount; 7 8 public myRun(List<Map<String, Object>> tmpList, int threadCount, 9 CountDownLatch countdown,int oneThreadCount) { 10 super(); 11 this.tmpList = tmpList; 12 this.threadCount = threadCount; 13 this.countdown = countdown; 14 this.oneThreadCount = oneThreadCount; 15 } 16 17 @Override 18 public void run() { 19 for (int i = threadCount * oneThreadCount; i < (threadCount + 1) * oneThreadCount 20 && i < tmpList.size(); i++) { 21 System.out.println(Thread.currentThread().getName()+ "#" + i); 22 System.out.println(tmpList.get(i)); 23 } 24 countdown.countDown();// 每个子线程结束后进行线程减1 25 System.out.println(Thread.currentThread().getName() 26 + "##线程结束------------------------"); 27 System.out.println("----------------剩余的线程个数:" 28 + countdown.getCount()); 29 } 30 31 }
3:主线程执行任务
public void doHandler() { try { List<Map<String, Object>> list = getList(); final CountDownLatch countdown = new CountDownLatch(THREAD_NUM);// 子线程数 int oneThreadCount = list.size()/THREAD_NUM + 1; for (int num = 0; num < THREAD_NUM; num++) {// 开启线程个数 System.out.println("----------------共有的线程个数:" + countdown.getCount()); threadPool.execute(new myRun(list,num,countdown,oneThreadCount)); } countdown.await();// 这里进行同步等待,等所有子线程结束后,执行 countdown.await()后面的代码 System.out.println("##结束等待------------------------"); } catch (InterruptedException e) { e.printStackTrace(); } finally { threadPool.shutdown(); } } public static List<Map<String, Object>> getList() { List<Map<String, Object>> resultList = new ArrayList<Map<String, Object>>(); for (int i = 0; i < 99; i++) { Map<String, Object> tmpMap = new HashMap<String, Object>(); tmpMap.put("id", 1); tmpMap.put("name", "rose"); tmpMap.put("salary", 10000); resultList.add(tmpMap); } return resultList; }
4:整个代码如下
1 package com.hlcui.threadpool; 2 3 import java.util.ArrayList; 4 import java.util.HashMap; 5 import java.util.List; 6 import java.util.Map; 7 import java.util.concurrent.CountDownLatch; 8 import java.util.concurrent.ExecutorService; 9 import java.util.concurrent.Executors; 10 11 public class ThreadCountDemo { 12 public static final int THREAD_NUM = 10; 13 public ExecutorService threadPool = Executors.newFixedThreadPool(THREAD_NUM);// 创建10个线程放入线程池内 14 15 public void doHandler() { 16 try { 17 List<Map<String, Object>> list = getList(); 18 final CountDownLatch countdown = new CountDownLatch(THREAD_NUM);// 子线程数 19 int oneThreadCount = list.size()/THREAD_NUM + 1; 20 for (int num = 0; num < THREAD_NUM; num++) {// 开启线程个数 21 System.out.println("----------------共有的线程个数:" + countdown.getCount()); 22 threadPool.execute(new myRun(list,num,countdown,oneThreadCount)); 23 } 24 countdown.await();// 这里进行同步等待,等所有子线程结束后,执行 countdown.await()后面的代码 25 System.out.println("##结束等待------------------------"); 26 } catch (InterruptedException e) { 27 e.printStackTrace(); 28 } finally { 29 threadPool.shutdown(); 30 } 31 } 32 33 public static List<Map<String, Object>> getList() { 34 List<Map<String, Object>> resultList = new ArrayList<Map<String, Object>>(); 35 for (int i = 0; i < 99; i++) { 36 Map<String, Object> tmpMap = new HashMap<String, Object>(); 37 tmpMap.put("id", 1); 38 tmpMap.put("name", "rose"); 39 tmpMap.put("salary", 10000); 40 resultList.add(tmpMap); 41 } 42 return resultList; 43 } 44 45 public class myRun implements Runnable{ 46 47 private List<Map<String,Object>> tmpList; 48 private int threadCount; 49 private CountDownLatch countdown; 50 private int oneThreadCount; 51 52 public myRun(List<Map<String, Object>> tmpList, int threadCount, 53 CountDownLatch countdown,int oneThreadCount) { 54 super(); 55 this.tmpList = tmpList; 56 this.threadCount = threadCount; 57 this.countdown = countdown; 58 this.oneThreadCount = oneThreadCount; 59 } 60 61 @Override 62 public void run() { 63 for (int i = threadCount * oneThreadCount; i < (threadCount + 1) * oneThreadCount 64 && i < tmpList.size(); i++) { 65 System.out.println(Thread.currentThread().getName()+ "#" + i); 66 System.out.println(tmpList.get(i)); 67 } 68 countdown.countDown();// 每个子线程结束后进行线程减1 69 System.out.println(Thread.currentThread().getName() 70 + "##线程结束------------------------"); 71 System.out.println("----------------剩余的线程个数:" 72 + countdown.getCount()); 73 } 74 75 } 76 }
代码均已经验证。
二:ThreadPoolExecutor代码的分析
Executors类提供了很多静态方法:
1:维护单线程的线程池

2:固定线程数线程池

3:还有来一个任务就创建一个线程的缓存线程池

4:还有这种延迟对列的线程

这里面有一个很重要的方法,所以的线程池的创建几乎都依赖它,
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
先看一下它的参数:
corePoolSize:核心线程数 就是线程池在没有任务时,一般需要维持的线程数,当然,线程池创建后是0,当来第一个任务的时候就创建一个,依次类推
maximumPoolSize:最大线程数,当核心线程处理不了大量的请求时,就会把请求任务放入对列中,如果对列的容量达到上限,就会启用最大线程,继续创建线程处理请求
keepAliveTime:保持存活时间,如果当前线程池中维护的线程数大于核心线程数,且线程处于空闲状态,那么这个参数就是线程能够存活的时间
unit:时间单位,和上一个参数绑定使用
workQueue:对列,当核心线程数,处理不了当前请求任务时,就会把请求放入对列中
threadFactory:线程工厂,就是线程池创建线程的工具
rejectExecutionHandler:拒绝执行策略,当最大线程也处理不了请求任务时,如果这时候还有很多请求过来,那么就会启用拒绝策略
看一下单线程池:
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
当第一个请求来时,会启动一个线程处理,第一个请求没有处理完,再来一个请求时,就会放入对列。
看一下这个对列:
是LinkedBlockQueue,容量为Integer的最大值,可以认为是无界的


后续来的请求会一直向这个对列放,然后线程处理完上一个请求后,会从对列中取下一个请求来处理。
使用单线程池可以保证任务执行的有序
再看一下固定线程数线程:
和单线程池差不多,区别就是核心线程数和最大线程数,使用的对列也是无界LinedBlockingQueue对列
但是这个线程池可以并发处理请求任务,如果请求任务过多,也会入队列,等核心线程处理完当前任务,再从
对列中取

看一下CachedThreadPool这个线程,和其他的线程池不一样,这个线程池维护的线程核心数为0,最大数为Integer最大值
她使用的对列是同步对列,其实不存储请求任务,它的工作原理是,来一个请求任务,我就创建一个线程处理,处理完之后
在线程池存活60s,如果再来请求任务,直接使用空闲线程处理。如果没有空闲线程就创建,可以创建很多线程。
这个线程池比较适合任务处理时间短,并发比较大的请求。

阿里的开发手册建议开发者不要直接使用Executors类中的静态方法,最好是自己使用ThreadPoolExecutor这个构造函数创建,根据
自己实际的业务需求定制线程池。
三:读源码
下面来看看ThreadPoolExecutors类中的方法
1 :execute: 核心代码

a:检查核心线程数
检查线程池中维护的worker的数量是否小于核心线程数
if (workerCountOf(c) < corePoolSize) {
如果小于,则创建新的线程处理请求任务
if (addWorker(command, true))
b:放入对列
如果不小于,则程序继续向下走:
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
判断线程池处于运行状态,则把请求放入对列,放入成功后,再次判断线程池状态,如果状态不是运行,
则将任务从对列删除,然后使用线程池拒绝策略处理请求任务,如果这时工作线程的数量为0(有可能线程抛异常挂掉了),
则创建线程处理任务
c:继续启动线程
如果放入对列失败,则程序继续向下走

如果创建线程失败,则使用线程池的拒绝策略处理
这里面比较重要的一个方法是:addWorker
下面我们来看一下这个方法:
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
前面是一个死循环的判断:
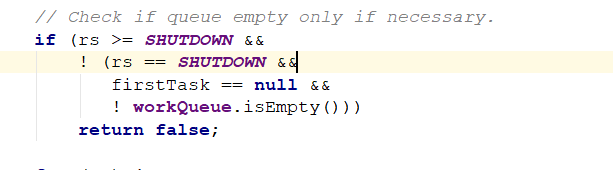
如果线程池的状态是shutdow、stop或者terminated等状态,
如果请求任务不为空,则退出,shutdown状态后只会把对列内的线程处理完毕,不会再创建新的线程
或者对列为空,则退出,对列为空说明任务已经处理完毕,不需要再创建新的线程

如果创建的线程是核心线程,则和核心线程数进行比较,如果大于等于核心线程数,则退出,不创建新的线程
如果创建的线程是最大线程时,则和最大线程数进行比较,如果大于最大线程数,则退出,不创建新的线程
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
所有创建的线程都会放到workers集合中,放置成功后,就会
调用 start方法,然后该线程就处于就绪状态,等待cpu分配时间片

来看一下创建worker的过程:

传进来的这个firstTask是我们要执行的任务,请求。
然后赋值给Worker对象中的一个变量引用,使用我们创建线程池传进来的线程工厂创建线程,如果不传会使用默认线程工厂,
我们看一下源码:

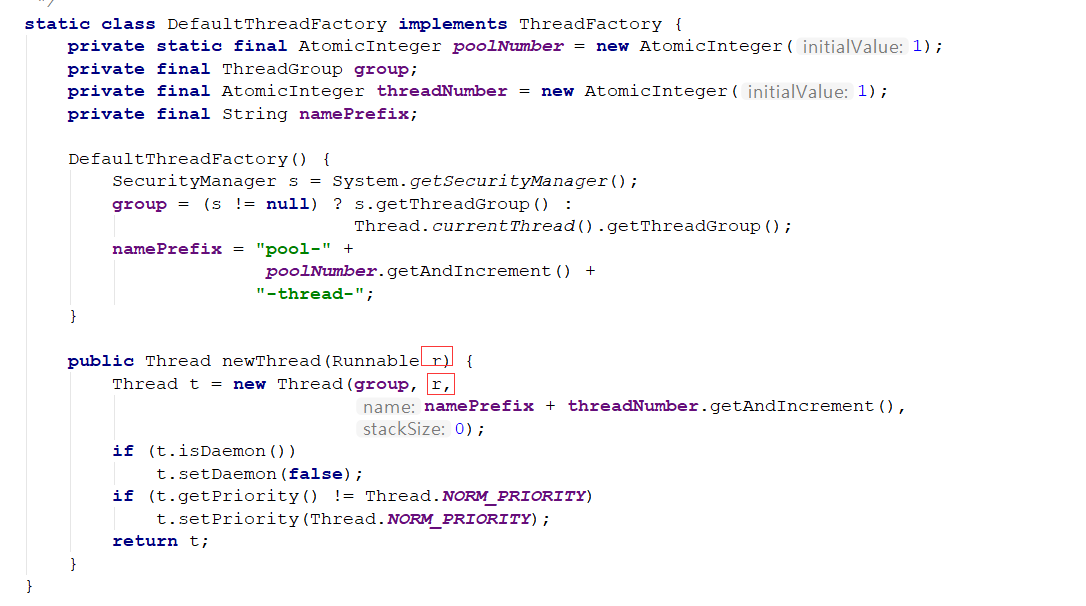
worker对象作为Runnable对象维护到了线程中,
Worker对象持有这个Thread对象的引用,这个Thread对象也持有worker对象的引用
那么当Thread start后,cpu调用Thread run的时候,其实调用的是worker的run方法



一路跟下来,我们知道这个worker就是run方法中的target,那么我们回过头来看看worker类,
worker的run方法:

runWorker方法:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
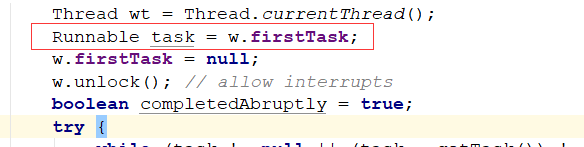
这个firstTask才是我们执行execute传进来的Runnable对象,
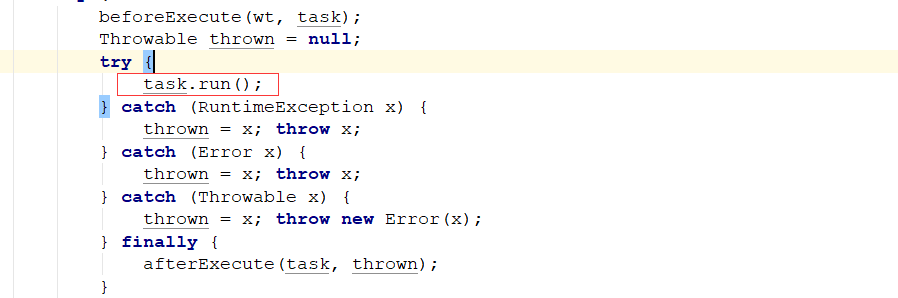
这里才能执行我们实现Runnable的真正逻辑,如果失败,则把异常抛出去。
最后这个异常会抛给虚拟机。
下面来看一下这个方法,红框标注的
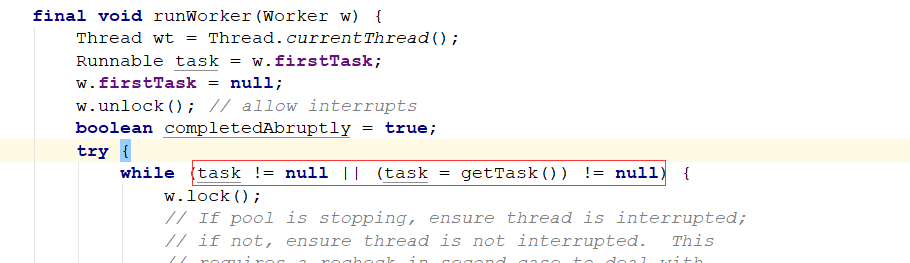
如果这个task!=null 则为执行任务,这个task就是第一次给这个worker分配的任务,如果这个任务已经执行完毕就被置位null,任务被gc了。
那么这个线程下一次分配到cpu的时间片时,就是执行 task=getTask()这个方法。
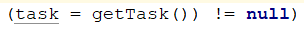
这个方法就是从对列中取出任务执行,
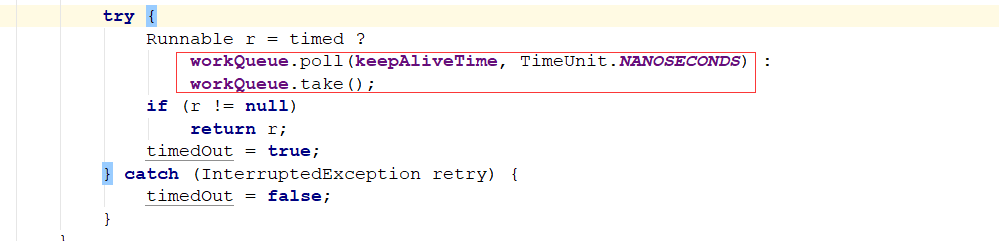
从工作对列中取出Runnable来执行。
2: submit 方法
一般任务execute是执行没有返回值的任务,实现Runnable,submit提交的
任务一般是需要返回值的,实现Callable,
submit重载了3个方法,既支持callable,又支持Runnable

线程池的submit实现在ThreadPoolExecutors的父类 AbstractExecuteService中,我们来看一下
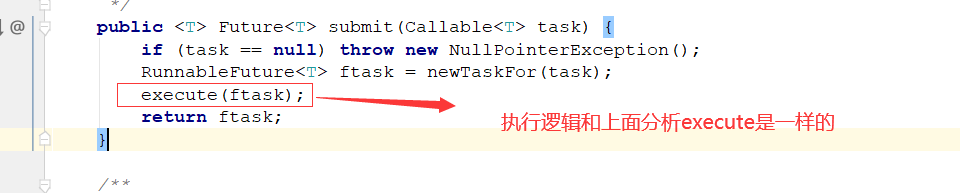
这里的execute的执行逻辑和上面的execute是一样的,区别就是这里的入参是RunnableFuture对象,当然这个类也实现了Runnable,而execute的入参是Runnable对象,



一路跟着源码下来,可以看到,把我们传进来的入参封装到了FutureTask里面,FutureTask类又实现了RunnableFuture类

那么根据执行execute的经验,
当cpu执行Thread的run方法的时候,会执行Worker的run ,runWorker方法,然后 task.run
这个task就是FutureTask对象,而不是execute时候我们自己实现Runnable的对象了。

我们来看一下FutureTask类的run方法:
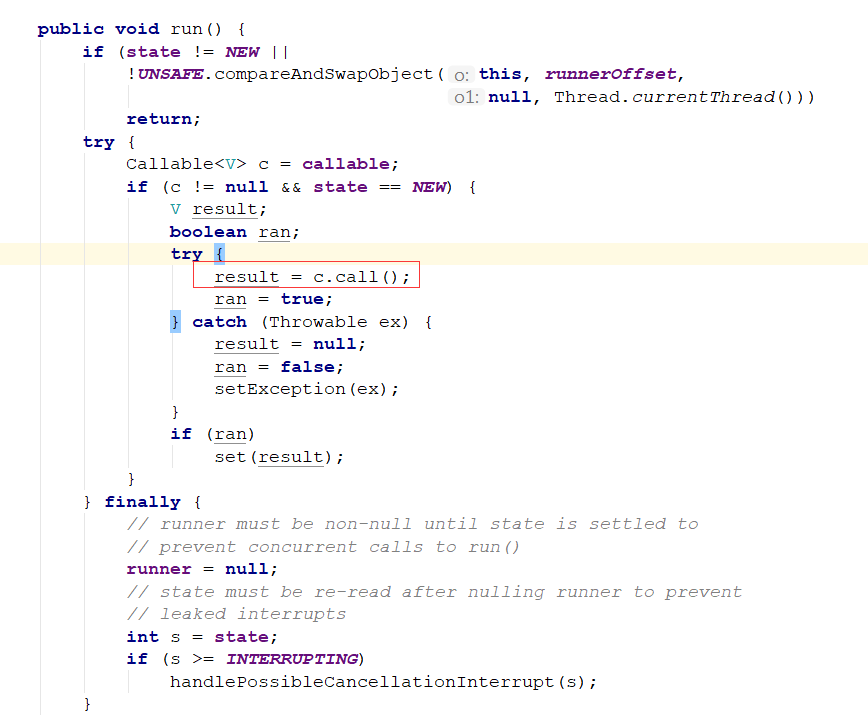
它的run方法里面的callable变量才是我们自己实现Callable接口创建的对象,
处理成功,则把执行结果set到report输出变量上,处理失败则把Throwable对象set到report输出变量上。
到这里 submit的调用链也结束了,再来看一下取结果。
get方法:
先来看一下FutureTask维护的几个状态:

New 创建一个FutureTask对象
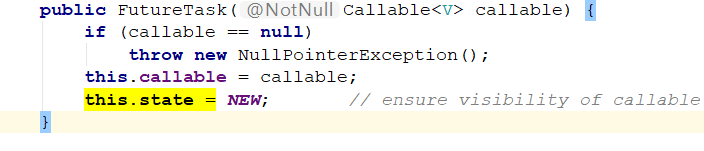
Completing:任务执行刚完成

Normal:任务执行完成,马上会被设置成Normal
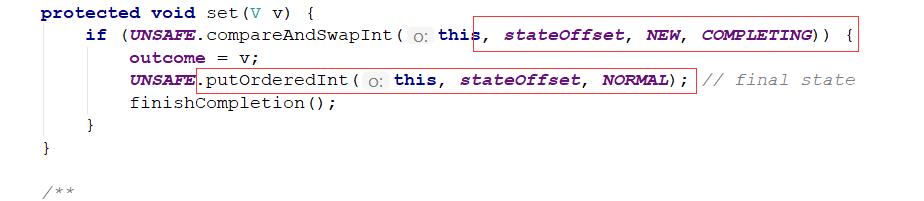
当我们收集完FutureTask后,可以通过get方法获取异步的执行结果

如果futureTask的状态是new或者刚刚完成时,
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
WaitNode q = null;
boolean queued = false;
for (;;) {
if (Thread.interrupted()) {
removeWaiter(q);
throw new InterruptedException();
}
int s = state;
if (s > COMPLETING) {
if (q != null)
q.thread = null;
return s;
}
else if (s == COMPLETING) // cannot time out yet
Thread.yield();
else if (q == null)
q = new WaitNode();
else if (!queued)
queued = UNSAFE.compareAndSwapObject(this, waitersOffset,
q.next = waiters, q);
else if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
removeWaiter(q);
return state;
}
LockSupport.parkNanos(this, nanos);
}
else
LockSupport.park(this);
}
}
get的时候会一直在死循环里面执行,知道s的state为normal,也就是结果已经设置到outcome中
如果当前线程中断了,直接抛异常


今天的学习就到这里!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号