Tracking without bells and whistles
Tracking without bells and whistles
2019-08-07 20:46:12
Paper: https://arxiv.org/pdf/1903.05625
Code: https://github.com/phil-bergmann/tracking_wo_bnw
1. Background and Motivation:
本文提出一种很霸道的观点:A detector is all you need for Multi-Object Tracking。我们知道 MOT 的常规思路都是要先检测,在做数据连接(data association)。但是,作者发现,最近两年,虽然有很多方法被提出,但是悲剧的是,在几个公共的 MOT 数据集上,并没有很明显的提升(两年才提升了2点多:multiple object tracking accuracy has only improved 2.4% in the last two years on the MOT16 MOTChallenge benchmark)。作者发现通过仅仅利用物体检测算法,如 Faster rcnn,就可以达到 state of the art 的效果。这也引出了一个很有意思的问题:如果一个检测器就可以很好地完成 MOT 的任务,那么,tracking algorithm 有什么用呢?这还是必要的吗?我们先来看看作者提出的算法框架到底是怎么样的。
2. A detector is all you need:
有一些物体检测算法中包含通过 regression 的方式进行 bounding box refinement 的模块。作者提出使用这种 regressor 来进行 MOT。这种方式有如下两种优势:
1). 不需要任何关于 tracking 的训练;
2). 在测试阶段不进行任何复杂的优化,因为该算法是 online 的。
此外,本文的方法也可以达到 SOTA 的效果。
2.1 Object detector:
这个貌似没啥说的,就是用基于 Resnet-101 和 Feature Pyramid Networks 的方法在 MOT17Det pedestrian detection dataset 上进行预训练。得到这种物体检测器之后呢?一起来看 2.2 小节。
2.2 Trackor:
MOT 的挑战在于:提取给定的视频帧中的多个物体的时间和空间上位置信息,即:轨迹。这种轨迹信息被定义为:一系列有序的物体包围盒的集合。
在时刻 t=0,作者的 tracker 用第一组检测的结果进行初始化,即:$D_0 = {d^1_0, d^2_0, ... } = B_0$。在图 1 中,我们展示了两个随后的步骤:the bounding box regression and track initialization。
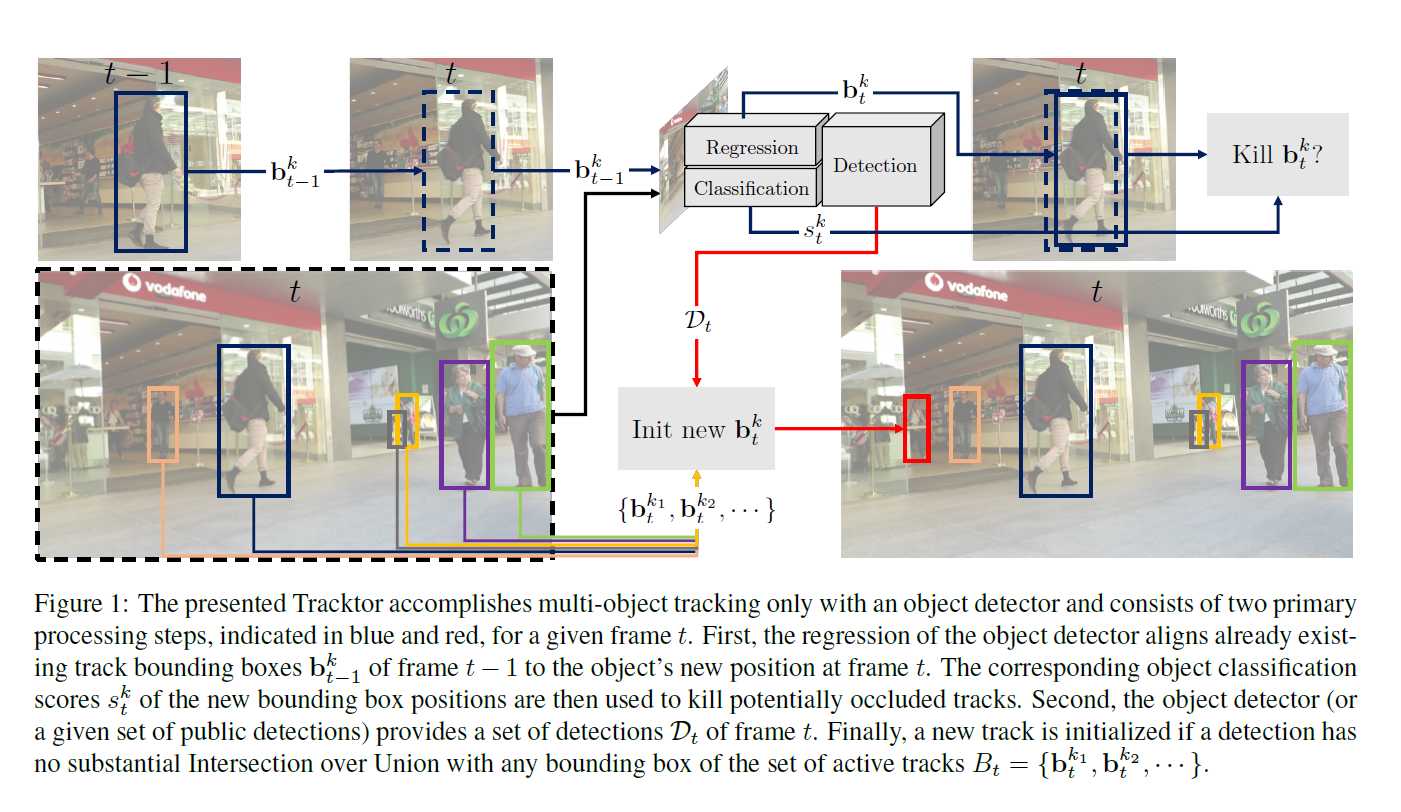
Bounding box regression.
第一步就是,如上图蓝色箭头所示,探索 bounding box regression 来拓展激活的轨迹。通过将 t-1 帧的 bounding box $b^k_{t-1}$ 进行回归,得到第 t 帧 新的位置 $b^k_t$。在 Faster RCNN 中,这就对应了在当前帧的 feature map 上进行 RoI Pooling 操作,但是用的是前一帧的 BBox。作者提出这种做法的一个假设就是:两帧之间的运动不是很明显,特别是在 high frame rates 的视频上。这个 identify 就自动的从之前的结果上迁移过来了,从而有效的得到了新的轨迹。这种操作可以对所有的视频帧进行重复处理。
在 BBox 回归以后,作者的跟踪器考虑两种情况来 kill 一个轨迹:
1). 一个物体在视频帧中消失了,或者被其他物体被遮挡了,即:如果新的 classification score 小于某一阈值;
2). 不同物体之间的遮挡,可以通过采用 NMS 来处理。
Bounding Box Initialization.
为了处理新出现的物体,物体检测器也提供了整个视频帧的检测结果 Dt。第二步,即图中红色箭头部分,类似于第一帧的初始化。但是,从 Dt 开始的检测,当且仅当 IoU 与任何已有的 active trajectories $b_t^k$ 小于某一阈值。即,我们考虑一个物体为新的 id,如果我们无法用任何已有的 trajectory 来描述该物体。
2.3 Tracking extensions.
作者将该模型进行了拓展,即:结合了 motion model 和 re-identification model。
Motion model. 作者之前的假设:两帧之间的变化不是很大,在有些情况下并不成立:large camera motion and low video frame rates. 在极端的情况下,BBox 从 frame t-1 在第 t 帧中可能根本不包含目标物体了。所以,作者设计了两种 motion model 来改善 BBox 的定位。对于运动相机,作者采用 相机运动补偿(camera motion compensation, CMC)的方式进行缓解。作者采用了 image registration 的方式来对齐视频帧,用的是 Enhanced Correlation Coefficient (ECC) maximization。对于低帧率的视频,作者采用 a constant velocity assumption (CVA)。这个也是别人提出的,不太了解,不知道有啥好处么?
Re-identification. 为了让 tracker 能够保持 online,作者提出利用 short-term re-ID 的方式(借助 Siamese Network 来进行 appearance feature 的匹配)来改善效果。为了达到这个目标,作者将杀死的目标,存储固定帧数的样本。然后将这些样本和新检测的目标在 embedding space 进行重识别。
3. Experiment:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号