Spatial-Temporal Relation Networks for Multi-Object Tracking
Spatial-Temporal Relation Networks for Multi-Object Tracking
2019-05-21 11:07:49
Paper: https://arxiv.org/pdf/1904.11489.pdf
1. Background and Motivation:
多目标跟踪的目标是:定位物体并且在视频中仍然可以保持他们的身份。该任务已经应用于多种场景,如视频监控,体育游戏分析,自动驾驶等等。大部分的方法都依赖于 “tracking-by-detection” 的流程,即:首先在每一帧进行物体检测,然后在后续的视频中将其连接起来。这种分解的流程,极大地降低了总体的复杂度,然后将主要问题变成了更加纯粹的问题:object association。这种思路主要受益于物体检测领域的快速发展,并且在多个 MOT 的 benchmark 上取得了顶尖的检测效果。
总体来说,这种通过联系物体(Object Association)的方法很大程度上依赖于鲁棒的相似性得分。这种相似性得分在大部分现有的方法中,都仅依赖于抠出来物体的表观特征(appearance feature)。这种相似性度量方法的结果是非常受限的:1). 所要跟踪的物体,在跟踪场景中,通常仅仅是一类,即:“Human”,通常非常难以区分;2). 跨越不同帧的物体,通常也受到遮挡,图像质量,姿态变化的影响,从而进一步增加了其鲁棒得分的难度。
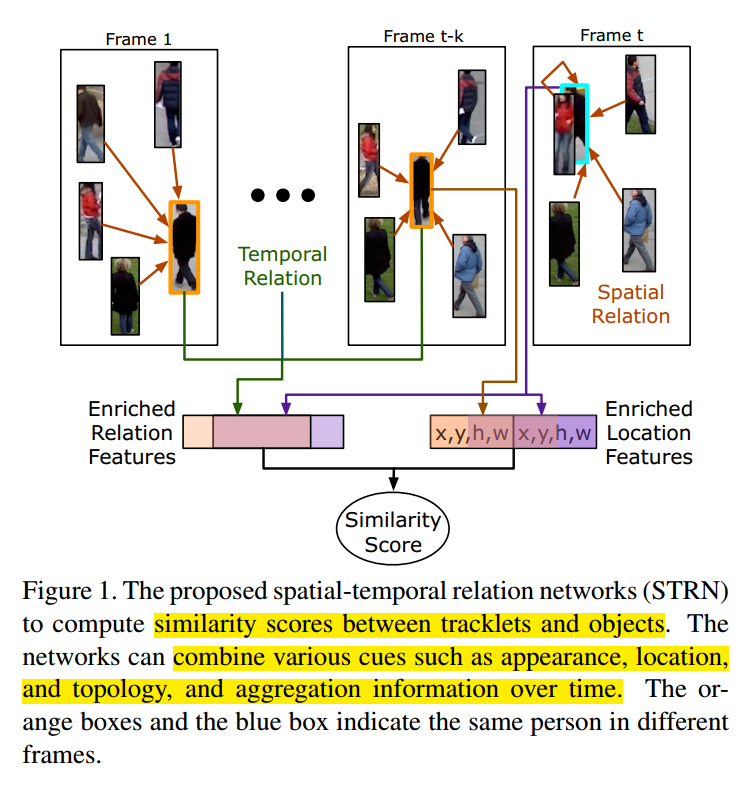
探索不同信息的前人工作也都在尝试如何有效的构建相似性得分。CNN 被很好的研究并且用于编码外观信息,手工设计的位置信息也被结合到 appearance cue。Bound Box 之间的拓扑结构对于判断是否给定的 BBox 对表示同一个物体,特别对于遮挡的场景来说。如图 1 所示,第一帧 和 第 t-k 帧中的橘色 BBox 和 第 t 帧的蓝色 BBox 表示同一个行人。虽然 第 t 帧的行人被另一个行人遮挡了,并且其外观仍然对于前面的视频帧来说,有较大的不同,但是其拓扑结构仍然是一致的,使得观测到的行人身份仍然是可识别的。此外,跨帧的信息融合,也被证明对于衡量相似度来说是有用的。
但是这些信息都是异构的表达,如何将这些信息进行整合,融合到一个框架中,现有的工作要么依赖于 cue-specific mechanism,要么需要顶尖的学习方法。本文的工作则是受到 natural language 和 CV 中关系网络成功应用的启发。在关系网络中,每一个元素通过一个 content-aware aggregation weight 从其他元素来进行特征聚合,可以自动根据任务的目标实现自动学习,而不需要显示的监督信息。由于不需要过多关于数据格式的假设,关系网络被广泛的应用于建模 distant, non-grid 或者 differently distributed data 之间的关系,例如 word-word, pixel-pixel and object-object 之间的关系。这些数据格式的很难用常规的卷积和循环网络建模。
该文章中,我们提出了一个联合的框架,通过将多种线索以一种端到端的方式进行相似性度量,从空间领域到时空领域拓展 object-object relation。有了这种关系网络的拓展,我们可以很好的编码 objects 和 tracklets 的外观和拓扑结构。同时也可以适应基于 location 的位置信息。
时空关系网络受限被应用到每一帧来加强空间上物体的外观表达。然后,在其参考的 tracklet 上的增强特征随着时间,通过采用我们的关系网络进行聚合。最终,在 tracklet 上聚合的特征,增强的目标特征被组合起来,以丰富 tracklet-object pair 的表达,并从而产生一个相似性得分。作者发现,tracklet-object pair 合适的特征表达也是相似性度量的关键所在。本文的算法被称为:spatial-temporal relation networks (STRN), 可以进行端到端的训练,并且在多个 MOT benchmark 上取得了顶尖的效果。
2. The Proposed Method:
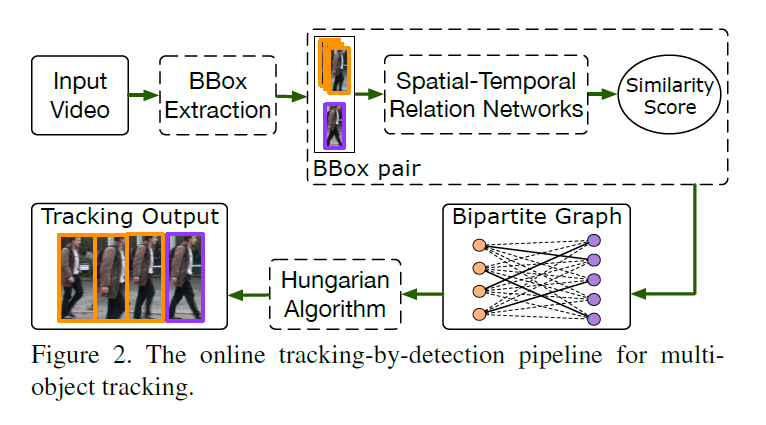
MOT 问题的定义:本文的算法示意图如图 2 所示。输入是 video,然后进行物体检测,得到行人的检测结果,即:BBox。然后在每一帧中,都进行前面一些帧得到的 tracklets 和 当前帧的检测结果 proposal 的匹配。那么,很自然的一个问题就是:如何很好的衡量这些 tracklets 和 proposals 之间的相似度度量问题?如果可以很好的度量其相似度,就可以很好的将其串起来,形成每一个目标物体的轨迹,从而完成多目标跟踪。将第 t-1 帧之前的第 i 个之前的 tracklet 记为:$T^{t-1}_i = \{b_i^1, b_i^2, ... , b_i^{t-1}\}$,当前帧 t 中检测到的物体记为:$D_t = \{b_j^t\}_{j=1}^{N_t}$。每一个 pair $(T^{t-1}_i, b_j^t)$ 被赋予一个相似性得分 $s_{ij}^t$。
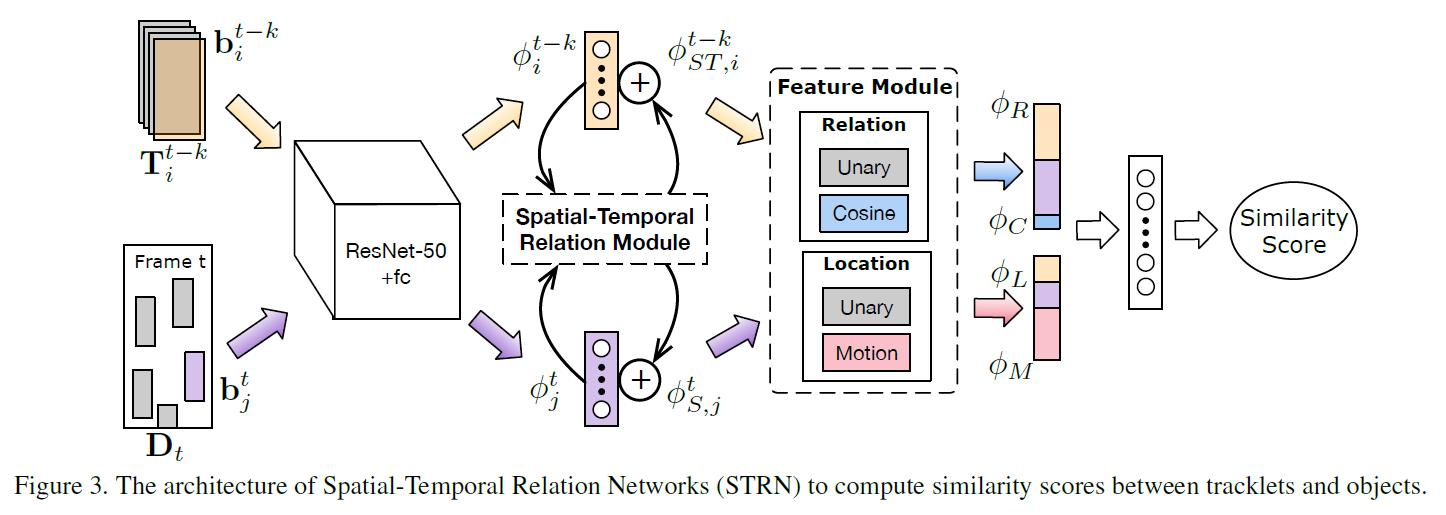
本文算法总览:这篇文章就是通过时空关系网络,将上述提到的 appearance,location,topology cues,and aggregating informaton over time 都用于计算相似性得分。图 3 展示了相似性计算的整个过程。首先,首先用基础的深度网络,ResNet-50 来提取 appearance feature;然后,跨越时空的表观特征通过 Spatial-temproal relation module (STRM) 来进行推理,得到了空间增强的表达和时间增强的表达。虽然这两个增强后的特征,我们进一步的得到两种特征,通过将其进行组合,然后分别计算其余弦相似度。最终,我们组合 the relation feature 和 unary location feature, motion feature 作为tracklet-object pair 的表达。对应的,该相似性得分是由两层网络和sigmoid 函数得到的。
紧接着,作者对该流程中的主要模块进行详细的介绍,主要包括:Spatial-temporal relation module (STRM), the design of the feature presentation for a tacklet-object pair。
2.1 The Spatial-Temporal Relation Module:
作者首先对基础的静态物体关系模型,由 MSRA组提出的 Relation network for object detection,用于编码 context information 来进行物体检测的。
Object relation module (ORM) :
基础物体关系模型的目标是:通过在一张静态图像上的其他物体进行信息的聚合,来增强输入的表观特征。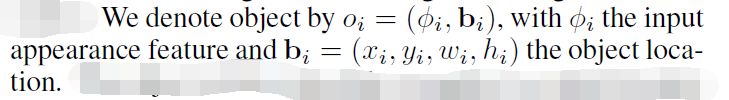
物体关系模块可以计算一个优化的物体特征,通过从一个物体集合O 中进行信息聚合:
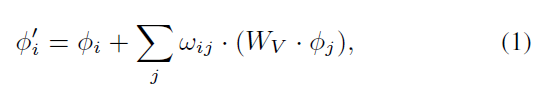
其中,$w_{ij}$ 是从物体 $o_j$ 到 $o_i$ 计算得到的 attention weight;$W_v$ 是输入特征的转换矩阵。而 Attention weight $w_{ij}$ 可以在考虑到投影后的表观相似性 $w_{ij}^A$,以及几何关系模型 $w_{ij}^G$之后得到:

其中,$w_{ij}^A$ 表示 the scaled dot product of projected appearance feature, 公式化表达为:
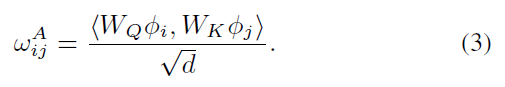
$w_{ij}^G$ 是通过相对位置 ![]() ,用一个小网络得到的。原始的物体关系模型仅仅在空间领域进行推理。为了更好发挥其在 MOT 中的优势,我们将该模型拓展到 temporal domain。
,用一个小网络得到的。原始的物体关系模型仅仅在空间领域进行推理。为了更好发挥其在 MOT 中的优势,我们将该模型拓展到 temporal domain。
Extension to the Sptial-Temporal Domain:
该物体关系模型可以直观的进行拓展,即:将上一帧的物体信息也考虑到 object set O 中。这种方法很明显是 sub-optimal:
1). 由于有更多的物体涉及到推理过程中,复杂度明显变大了;
2). 时间和空间的关系被无差别的进行处理了。
但是,作者认为时间和空间关系对信息的编码,应该是有不同贡献的。The spatial relation 可以从建模不同物体之间的拓扑关系得到优势;The temporal relation 适合用于从多帧上聚合特征,从而可以避免低质量的 BBox 带来的干扰。
考虑到时空关系的不同效果,我们提出一种新的时空关系模型,如图1所示。首先在每一帧进行 spatial domain 的推理,该空间推理过程,利用自动学习的拓扑信息,加强了输入的表观特征。然后通过空间关系推理,将增强后的特征在多帧上进行信息聚合。
这两种关系服从不同的形式。空间关系推理过程严格的服从 Eq. 1, 来编码拓扑信息,结果输出特征记为:![]() 。图 4 展示了不同帧之间空间注意力权重的学习过程。总的来说,在不同帧上的注意力权重是稳定的,说明捕获了拓扑表达。
。图 4 展示了不同帧之间空间注意力权重的学习过程。总的来说,在不同帧上的注意力权重是稳定的,说明捕获了拓扑表达。

时间关系的推理过程是在空间关系推理之后进行的。由于硬件设备的限制,作者考虑了过去 T1 帧的信息聚合(默认设置为 10):
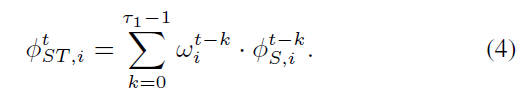
在每个输入特征上定义的 attention weight,记为:
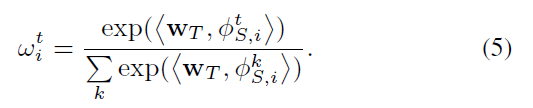
公式 4 其实是最近视频帧的物体特征的加权平均。学习到的时间注意力权重如图 5 所示。可以发现,模糊的,错误或者部分遮挡的物体被赋予较小的权重,表明可以自动学习到特征的质量,所以,可以很好的降低这些低质量的检测结果对 tracklet 的表达。

2.2 Design of Feature Representation :
在上面讲完关系模型的构建之后,作者接下来开始着重讲解如何学习很好的特征表达。因为特征表达直接和最终性能相挂钩。作者采用两层网络,来实现 tracklet 和 objects 之间相似性的度量:
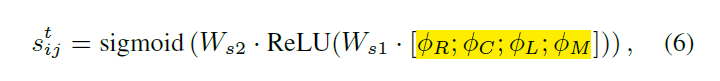
其中,黄色区域的几个元素分别代表:relation feature, consine similarity, location features and motion features。
2.2.1 Relation Features.
作者对输入的关系特征进行 linear transform,作为 base feature type:
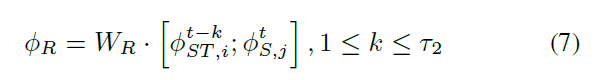
其中,$W_R$ 是用于 feature fusion 的线性转换。
直接利用组合后的关系特征可以计算不同 modes 的相似性。但是,the freedom in representation is double-edged 也增加了学习各自特征的复杂度。为了解决该问题,作者提出显示的计算两个关系特征的余弦距离:
![]()
其中,$W_C$ 是一个 linear layer 将原始的关系特征,投影到低维度的表达,即128-D。具体的各种特征计算方法,如下图 6 所示:

2.2.2 Location Features :
位置/运动特征 (Location/motion feature) 是另一种广泛应用于计算相似性得分的线索。我们将位置/运动特征从 tracklet 的最后一帧,来表示整个的,因为远距离帧的位置/运动模型可能导致当前帧的漂移。位置特征可以结合到作者提出的 pipeline 中。将 bare location features 首先进行 embedding,投射到高维度的空间,然后将其与 relation feature 进行组合,来产生最终的相似性得分。进行映射和投影的方法如下:

其中,* 是 {L, M} 之一。第一种是包围盒归一化后的绝对位置 (the normalized absolute location of bounding box):
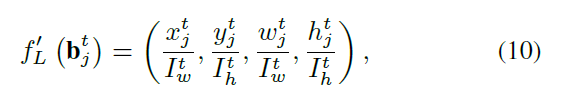
The other location feature depit the motion information of an object in consecutive frames:
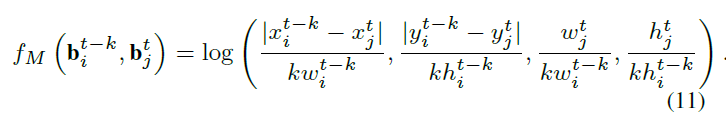
3. Experiments:
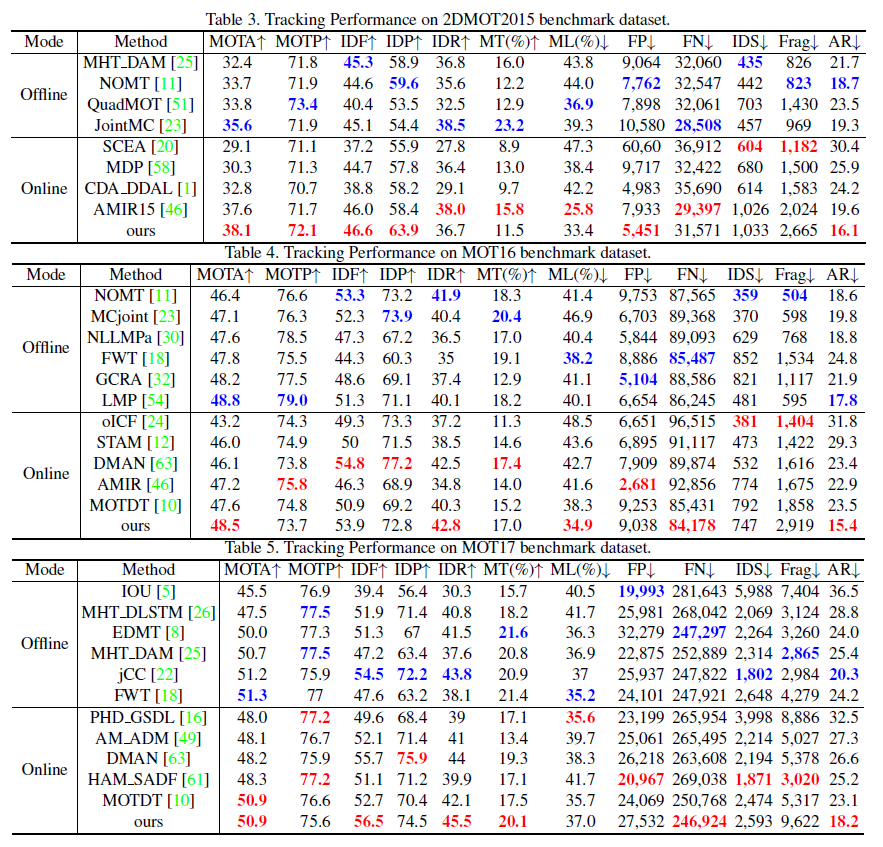
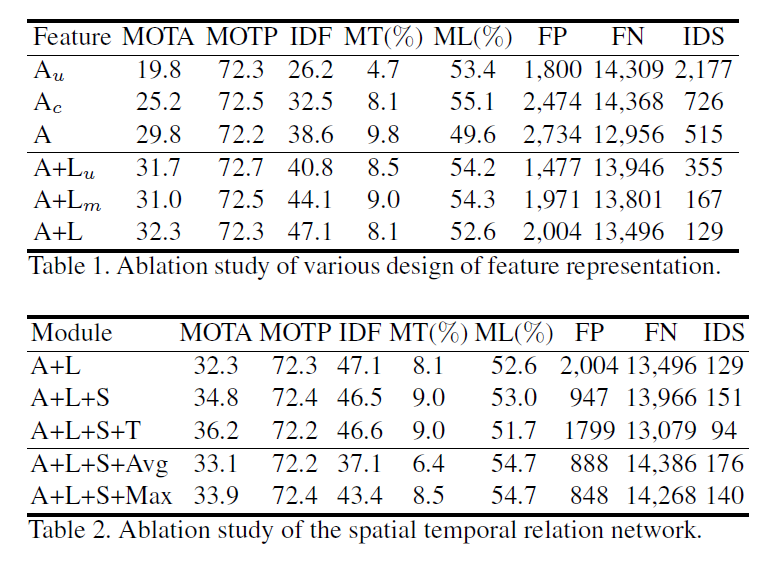
作者在多个 MOT 的 benchmark 上进行了实验,结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号