数据分析师的“水晶球”:时间序列分析
很多刚入行的小伙伴问我:“我想预测下个月公司的销售额,或者预测一下明天的股价,该学什么?”
我的回答通常只有六个字:时间序列分析。
如果在数据分析的世界里有一种魔法能让你“预知未来”,那一定就是它。
1. 什么是时间序列?
别被名词吓到了。简单来说,时间序列(Time Series)就是按时间顺序排列的一组数据。
比如:
- 你手机里每天的步数记录;
- 某只股票每天的收盘价;
- 或者是你家楼下便利店每个月的营业额。
这些数据都有一个共同点:有一个时间轴,且数据随着时间变化。
我们做时间序列分析的核心目的,就是要从过去的“历史数据”中找出规律,然后把这个规律延长到“未来”,这就是预测。
2. 像剥洋葱一样拆解数据:时间序列的四大成分
初学者最容易犯的错误是直接把数据丢进模型里跑。
作为一名老手,我要告诉你:看到数据,先拆解。
通常,任何一个随时间变化的数据(比如一家奶茶店的日销量),都可以被拆分为四个部分。
2.1. 长期趋势--“大势所趋”
这是数据在长时间内的主要运动方向。
- 例子:这家奶茶店开了三年,随着品牌知名度提升,整体销量每年都在涨。这就是趋势。
- 地位:它是总变动的老大,决定了长期的方向。
2.2. 季节变动--“春夏秋冬的轮回”
数据受季节、节假日等固定周期影响而出现的波动。
- 例子:夏天天气热,冰饮卖得疯快;冬天冷,销量自然下滑;每到周末销量就比周一高。这种随着时间固定重复的波动,就是季节性。
- 地位:它是总变动的老二,非常规律,预测起来最准。
2.3. 循环变动--“难以捉摸的周期”
这是一些周期较长、不固定的波动,通常和宏观经济有关。
- 例子:由于经济危机,大家钱包紧了,奶茶喝得少了。等经济复苏,又喝多了。
- 注意:这部分原因复杂,周期不固定,我们在基础预测中通常不做重点考虑。
2.4. 不规则变动--“老天爷的心情”
这是随机的、不可控的波动。
- 例子:某天突然下暴雨,没人出门,销量暴跌;或者某天网红来打卡,销量暴涨。
- 注意:这是“噪音”,在预测中我们很难捕捉它,通常假设它为0或忽略。
(重点):
在实际的时间序列预测中,我们主要抓 “长期趋势” 和 “季节变动”。抓住了这两条大鱼,预测的准确度通常能达到80%以上。
至于循环变动和不规则变动,因为占比小且太复杂,我们往往选择战略性忽略。
3. 手把手教你:用Python拆解时间序列
光说不练假把式。下面我们用Python代码模拟一组奶茶店的销售数据,并演示如何把这四个成分“拆”出来。
首先,构造“虚假”的奶茶店数据。
# === 第一步:构造数据 ===
# 假设我们有过去3年(36个月)的月度销售数据
dates = pd.date_range(start='2021-01-01', periods=36, freq='ME')
# 1. 制造【长期趋势】:每个月销量基础增加 10 杯
trend = np.linspace(100, 460, 36)
# 2. 制造【季节变动】:模拟每年夏天高、冬天低 (用正弦波模拟)
# 这里的逻辑是制造一个周期性的波浪
seasonality = 50 * np.sin(np.linspace(0, 3 * 2 * np.pi, 36))
# 3. 制造【不规则变动/噪音】:随机波动
noise = np.random.normal(0, 20, 36)
# 4. 合成总销量
total_sales = trend + seasonality + noise
# 创建 DataFrame
df = pd.DataFrame({'Date': dates, 'Sales': total_sales})
df.set_index('Date', inplace=True)
然后,使用 statsmodels 库进行分解,它能帮我们一键拆解数据。
from statsmodels.tsa.seasonal import seasonal_decompose
# === 第二步:数据分解 ===
# model='additive' 表示加法模型(销量 = 趋势 + 季节 + 噪音)
# 如果波动幅度随着趋势变大而变大,通常用乘法模型 (multiplicative)
decomposition = seasonal_decompose(df['Sales'], model='additive')
# === 第三步:绘图展示 ===
fig = decomposition.plot()
fig.set_size_inches(12, 10) # 设置画布大小
plt.show()
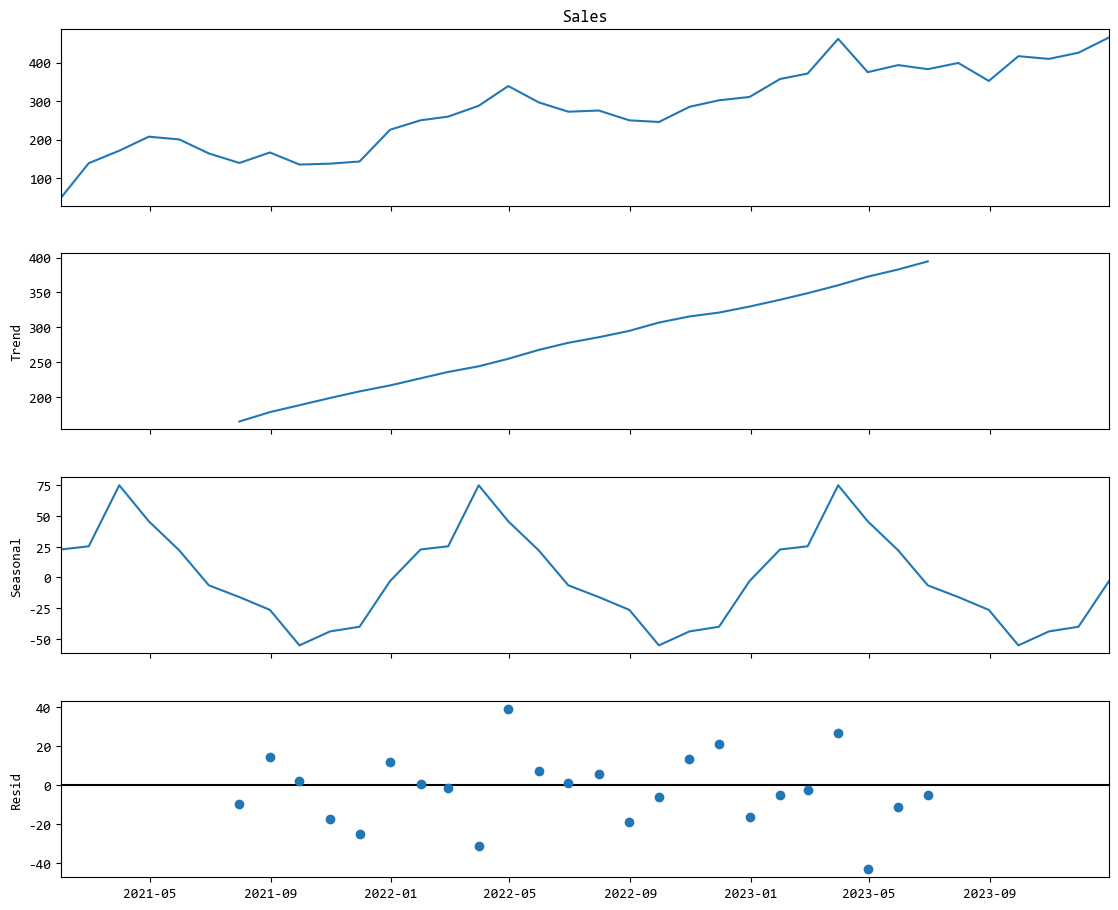
从上面四个子图可以看出:
- Observed (原始数据):你看到的真实销量曲线,上蹿下跳。
- Trend (趋势):一条稳步向上的直线。这告诉老板:放心,虽然每个月有波动,但咱们店整体是越做越好的!
- Seasonal (季节性):非常有规律的波浪线。这告诉店长:每年6-8月要多备货,12-1月可以安排员工轮休。
- Resid (残差/不规则项):围绕0上下跳动的杂乱点。这是我们无法预测的随机事件。
4. 分析师的内功:不仅仅是代码
学会了上面的代码,你已经入门了。但作为过来人,我想告诉你,工具和算法虽然层出不穷,但分析思路才是万变不离其宗的。
首先,关注数据的平稳性,这是时间序列分析的门槛。
简单说,大部分复杂的统计模型(如ARIMA)都假设数据的性质(均值、方差)不随时间变化。
然而现实数据(如股价、销量)往往是不平稳的(有上涨趋势),因此如果你发现数据一直在涨,可以试着做差分(用今天的数减去昨天的数)。
差分后的数据往往就平稳了,更容易放入模型去训练。
其次,结合业务场景,不要死记硬背模型,还要看场景。
比如:
- 场景A:电商大促预测(双11)
- 特点:有极强的季节性(每年11月暴涨)。
- 策略:重点分析季节变动。如果只看趋势,你会被双11的数据吓死,或者在双11备货不足。
- 热点关联:就像分析“淄博烧烤”或“哈尔滨旅游”,必须考虑节假日这个强季节因子。
- 场景B:股票价格预测
- 特点:不规则变动(噪音)极大,甚至噪音掩盖了趋势。
- 策略:这种时候,简单的分解模型往往失效。需要引入更多外部变量(新闻、政策),或者使用更高级的深度学习模型。
- 场景C:服务器流量监控
- 特点:白天高、深夜低,周末低、工作日高。
- 策略:这是最标准的周期性数据,非常适合用来做异常检测(比如某天深夜流量突然暴涨,肯定是有黑客攻击或系统Bug,因为这违背了季节性规律)。
5. 总结与建议
时间序列分析并没有想象中那么神秘。它的本质就是:承认历史会重演,但也接纳未来的不确定性。
对于刚入行的朋友,我的建议是:
- 理解四大成分(趋势、季节、循环、噪音)是基础中的基础。
- 抓住主要矛盾:在做预测时,优先搞定趋势和季节性。
- 多动手尝试:比如把上面的
Python代码跑一遍,尝试修改一下数据,看看结果有什么变化。
未来的分析方法虽然会越来越多,AI也会越来越强,但这种 “透过现象(原始数据)看本质(趋势与规律)” 的分析思维,将是我们职业生涯中永恒不变的宝贵财富。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号