【pandas基础】--数据读取
数据读取是第一步,只有成功加载数据之后,后续的操作才有可能。
pandas可以读取和导入各种数据格式的数据,如CSV,Excel,JSON,SQL,HTML等,不需要手动编写复杂的读取代码。
1. 各类数据源
pandas提供了导入各类常用文件格式数据的接口,这里介绍3种最常用的加载数据的接口。
1.1 从 CSV 文件读取数据
读取csv文件的接口:read_csv()
import pandas as pd
# 此csv中包含一些中国人口的统计信息
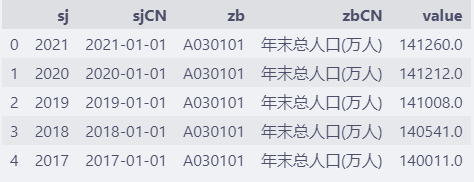
df = pd.read_csv("/path/to/china-population.csv")
df.head() # 显示前5条数据
1.2 从 excel 文件读取数据
读取excel文件的接口:read_excel ()
读取excel文件时,默认读取第一个sheet中的数据。
import pandas as pd
# 此excel中的数据与上面csv文件中的一样
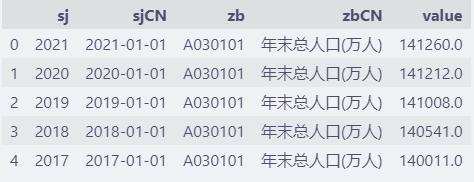
df = pd.read_excel("/path/to/china-population.xlsx")
df.head() # 显示前5条数据
1.3 从网络中读取数据
除了从本地文件中读取数据之外,read_csv和 read_excel也可以直接从URL读取数据。
比如,上面的csv文件和excel文件可以从下面的地址下载。
http://databook.top:8888/pandas/china-population.csv
http://databook.top:8888/pandas/china-population.xlsx
可以直接将URL传给 read_csv和 read_excel,不用下载保存本地。
import pandas as pd
df = pd.read_csv("http://databook.top:8888/pandas/china-population.csv")
df_excel = pd.read_excel("http://databook.top:8888/pandas/china-population.xlsx")
2. 不同分隔符
csv 文件中默认用逗号,分隔不同的字段,不过,也有很多csv文件不用逗号分隔,用其他生僻的符号来分隔。
import pandas as pd
df = pd.read_csv("http://databook.top:8888/pandas/china-population-sep.csv")
df.head()

文件china-population-sep.csv用 |来分隔不同的字段,直接读取的话,变成只有一个字段。
这时,要明确设置分隔符。
import pandas as pd
df = pd.read_csv("http://databook.top:8888/pandas/china-population-sep.csv", sep="|")
df.head()
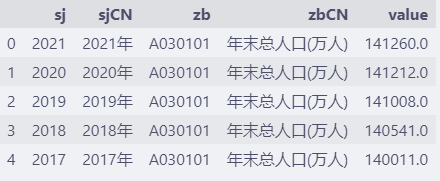
这样就得到了正确的数据结构。
3. 设置列名称
除了可以设置分隔符之外,读取数据时,也可以设置列的名称。
上面的例子中,列的名称都是字母的缩写,读取文件时可以替换成中文名称。
import pandas as pd
df = pd.read_csv(
"http://databook.top:8888/pandas/china-population-sep.csv",
sep="|",
names=["年份数字", "年份", "指标编码", "指标名称", "人口数"],
)
df.head()
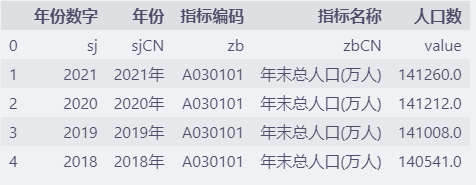
通过names参数设置列的名称,names参数是个列表,其中元素的个数一般与列的数目保持一致。
如果names中元素个数少于列的数目,那么多出来的列会作为索引(关于索引index,后续会详细介绍)。
import pandas as pd
df = pd.read_csv(
"http://databook.top:8888/pandas/china-population-sep.csv",
sep="|",
names=["指标编码", "指标名称", "人口数"],
)
df.head()
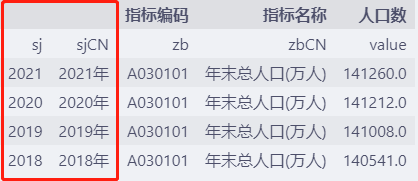
如果 names中元素个数多于列的数目,多出来的元素作为新增的空白列。
import pandas as pd
df = pd.read_csv(
"http://databook.top:8888/pandas/china-population-sep.csv",
sep="|",
names=["年份数字", "年份", "指标编码", "指标名称", "人口数", "列名称", "列名称2"],
)
df.head()
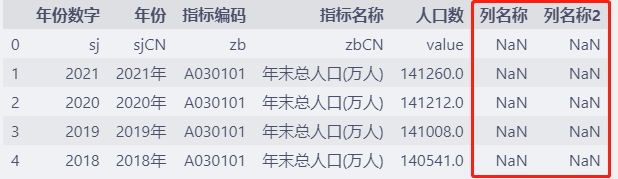
上面的例子中,我们应该发现了一个问题,设置 names作为新的列名称之后,原有的列名称被当成了实际的数据。
也就是:

设置新的列名称时,如果数据中包含列名称的话,需要忽略掉这个名称。
设置 header=0,忽略作为标题的第一行。
如果文件本来就没有标题的话,设置 header=None。
import pandas as pd
df = pd.read_csv(
"http://databook.top:8888/pandas/china-population-sep.csv",
sep="|",
header=0,
names=["年份数字", "年份", "指标编码", "指标名称", "人口数"],
)
df.head()
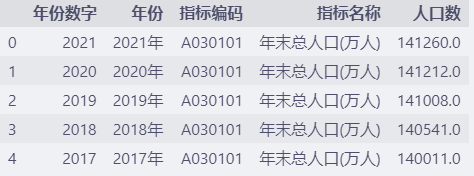
4. 随机生成数据
pandas支持从很多数据源读取数据,不过,有时候我们只想尝试尝试 pandas中的一些方法,并不想创建数据源。
这时,可以通过 numpy包创建一个随机的二维矩阵,直接将这个二维矩阵的数据导入 pandas即可。
下面的例子创建了一个10行3列的数据集。
import pandas as pd
import numpy as np
data = np.random.rand(10,3)
df = pd.DataFrame(data, columns=["data1", "data2", "data3"])
df.head()
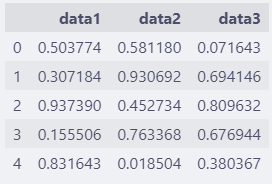
通过临时创建的随机数据,可以尝试 pandas提供的各类接口。
5. 总结回顾
本篇了主要介绍了数据的读取方法,重点介绍的是 csv 文件的读取方式,因为这是最常用的数据源。
其他数据源的读取方式也大同小异,各种数据源的差异会体现在不同接口的参数上。
本文所用到的数据:
- http://databook.top:8888/pandas/china-population.csv
- http://databook.top:8888/pandas/china-population-sep.csv
- http://databook.top:8888/pandas/china-population.xlsx
本文关联的微信视频号短视频:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号