
Spark程序开发
前言
本文基于JDK8,使用Java版本的SDK,相关代码示例所使用的spark相关jar包版本如下:
pom.xml
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<spark.version>3.3.4</spark.version>
<scala.version>2.13</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>0.98.12-hadoop2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>0.98.12-hadoop2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-protocol</artifactId>
<version>1.2.6</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-shaded-client</artifactId>
<version>1.2.6</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.5</version>
</dependency>
</dependencies>
SparkContext、SparkSession
SparkContext 是 Apache Spark 的核心组件之一,它是与 Spark 集群进行交互的入口点。
初始化:SparkContext 负责初始化 Spark 应用程序,加载 Spark 的配置,并创建与集群的连接。
提供访问 Spark 功能的接口,例如创建 RDD(弹性分布式数据集)。
管理资源,如集群中的工作节点和任务。
支持数据的读取与写入,能够从多种数据源(如 HDFS、S3、数据库等)读取数据。
生命周期:SparkContext 的生命周期通常与应用程序的生命周期相同。创建后,它将保持活动状态,直到应用程序结束或手动停止。
单一实例:在一个 Spark 应用程序中,通常只会有一个 SparkContext 实例,且在应用程序运行期间不能被多次创建。
写Spark程序时首先需要初始化SparkContext对象
SparkConf conf = new SparkConf()
.setAppName("Spark Example")
.setMaster("local[*]");
SparkContext context = new SparkContext(conf);
Spark的Java SDK提供了一个专门的SparkContext叫JavaSparkContext,两者无继承关系
SparkContext context = new SparkContext(conf);
// 将JavaSparkContext转换为SparkContext
JavaSparkContext javaSparkContext = JavaSparkContext.fromSparkContext(context);
SparkContext sparkContext = JavaSparkContext.toSparkContext(javaSparkContext);
SparkSession
SparkSession 是 Spark 2.0 中引入的一个新API,它是对 SparkContext、SQLContext 和 HiveContext 的综合替代方案。
SparkSession sparkSession =SparkSession.builder()
.master("yarn")
.appName("Spark Session Example")
.config("spark.yarn.master", "yarn://<yarn_address>:<port>") // 指定yarn集群master的地址
.getOrCreate();
指定master
| Master URL | 含义 |
|---|---|
| `local | 单线程本地执行 |
local[K] |
使用K个工作线程在本地运行Spark(理想情况下,将其设置为机器上的内核数量)。 |
local[K,F] |
Run Spark locally with K worker threads and F maxFailures (seespark.task.maxFailures for an explanation of this variable). |
local[*] |
使用机器核数个工作线程在本地运行Spark. |
local[*,F] |
Run Spark locally with as many worker threads as logical cores on your machine and F maxFailures. |
local-cluster[N,C,M] |
Local-cluster mode is only for unit tests. It emulates a distributed cluster in a single JVM with N number of workers, C cores per worker and M MiB of memory per worker. |
spark://HOST:PORT |
Connect to the givenSpark standalone cluster master. The port must be whichever one your master is configured to use, which is 7077 by default. |
spark://HOST1:PORT1,HOST2:PORT2 |
Connect to the givenSpark standalone cluster with standby masters with Zookeeper. The list must have all the master hosts in the high availability cluster set up with Zookeeper. The port must be whichever each master is configured to use, which is 7077 by default. |
yarn |
Connect to aYARN cluster in client or cluster mode depending on the value of --deploy-mode. The cluster location will be found based on the HADOOP_CONF_DIR or YARN_CONF_DIR variable. |
k8s://HOST:PORT |
Connect to aKubernetes cluster in client or cluster mode depending on the value of --deploy-mode. The HOST and PORT refer to the Kubernetes API Server. It connects using TLS by default. In order to force it to use an unsecured connection, you can use k8s://http://HOST:PORT. |
配置SparkContext
$SPARK_HOME/conf/spark-defaults.conf
spark.master会覆盖--master指定的值,并且会覆盖spark-defaults.conf的配置
本地启动
通过IDE直接启动不能指定master为yarn,需要通过spark-submit来提交
RDD
https://spark.apache.org/docs/latest/rdd-programming-guide.html
RDD全称resilient distributed dataset,弹性分布式数据集。RDD是一个可以并行操作的容错元素集合。创建RDD有两种方法:在驱动程序中并行化现有集合,或引用外部存储系统中的数据集,如共享文件系统、HDFS、HBase或任何提供Hadoop InputFormat的数据源。
集合并行化
SparkConf conf = new SparkConf()
.setAppName("Spark Example")
.setMaster("local[*]");
// 这里使用的Java SDK,要使用JavaSparkContext,Java版本的SparkContext没有parallelize方法
JavaSparkContext sc = new JavaSparkContext(conf);
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> rdd = sc.parallelize(data);
使用外部数据集
Spark可以从Hadoop支持的任何存储源创建分布式数据集,包括本地文件系统、HDFS、Cassandra、HBase、Amazon S3等。Spark支持文本文件、SequenceFiles和任何其他Hadoop输入格式。
https://hadoop.apache.org/docs/stable/api/org/apache/hadoop/mapred/InputFormat.html
文件输入
JavaRDD<String> distFile = sc.textFile("data.txt");
path:本地文件路径或 hdfs:// , s3a:// 等Hadoop支持的文件系统URI
minPartitions:可选参数,指定数据的最小分区
默认情况下,Spark为文件的每个块创建一个分区(HDFS中一个块默认为128MB),可以通过 minPartitions 参数来设置更多分区。请注意,分区数不能少于块数。
读取多个文件
如果要读取的多个指定文件,使用逗号分隔文件名传入 textFile() 即可
读取路径下所有文件
path 可传入文件路径来读取路径下所有文件
使用通配符读取多个文件
文件路径中可以使用通配符来读取多个文件。
从HDFS读取文件
从HDFS中读取文件和读取本地文件一样,只是要在URI中表明是HDFS。上面的所有读取方式也都适用于HDFS。
从数据库输入
TODO
分区
对于并行集合来说,一个重要参数是要分割数据集的分区数量,就是将数据拆分成多少份。
Spark将为集群的每个分区运行一个任务。通常集群中的每个CPU需要2-4个分区。Spark会尝试根据集群自动设置分区数量。也可以通过将其作为第二个参数传递给并行化来手动设置它。
// 指定分区数为10
sc.parallelize(data,10))
操作RDD
RDD 支持两种类型的操作:
- 转换(transformations),用于从现有数据集创建新数据集;例如 map 是一种转换,它将每个数据集元素传递给一个函数,并返回一个表示结果的新 RDD。
- 操作(action),用于在数据集上运行计算后将值返回给驱动程序。例如 reduce 是一种操作,它使用某个函数聚合 RDD 的所有元素,并将最终结果返回给驱动程序(尽管也有一个并行的 reduceByKey 操作,用于返回分布式数据集)。
Spark 中的所有转换都是惰性的,因为它们不会立即计算结果。相反,它们只是记住应用于某些基础数据集(例如文件)的转换。只有当操作需要将结果返回给驱动程序时,才会计算转换。这种设计使 Spark 能够更高效地运行。例如,我们可以意识到通过 map 创建的数据集将在 Reduce 中使用,并且只将 Reduce 的结果返回给驱动程序,而不是更大的映射数据集。
默认情况下,每次对转换后的 RDD 执行操作时,都可能需要重新计算。不过也可以使用 persist(或 cache)方法将 RDD 持久化到内存中,这样 Spark 会将元素保留在集群中,以便下次查询时更快地访问。Spark 还支持将 RDD 持久化到磁盘上,或将其复制到多个节点上。
JavaRDD<String> lines = sc.textFile("data.txt");
JavaRDD<Integer> lineLengths = lines.map(s -> s.length());
int totalLength = lineLengths.reduce((a, b) -> a + b);
第一行定义了一个来自外部文件的基础 RDD。此数据集不会加载到内存中,也不会进行其他操作:lines 仅仅是指向该文件的指针。第二行将 lineLengths 定义为 map 转换的结果。同样,由于惰性计算,lineLengths 不会立即计算出来。最后,我们运行 reduce,这是一个 action。此时,Spark 将计算分解为在独立机器上运行的任务,每台机器都运行其 map 部分和本地 Reduce 部分,并仅将其结果返回给驱动程序。
如果稍后还想再次使用 lineLengths,可以在reduce之前添加下面这行
// 将导致 lineLengths 在第一次计算后保存在内存中。
lineLengths.persist(StorageLevel.MEMORY_ONLY());
传递函数
Spark 的 API 很大程度上依赖于在驱动程序中传递函数来在集群上运行。在 Java 中,函数由实现 org.apache.spark.api.java.function 包1中接口的类表示。创建此类函数有两种方法:
- 在类中实现 Function 接口(可以是匿名内部类或命名类),并将其实例传递给 Spark。
- 使用 lambda 表达式来简洁地定义实现。
JavaRDD<String> lines = sc.textFile("data.txt");
JavaRDD<Integer> lineLengths = lines.map(new Function<String, Integer>() {
public Integer call(String s) { return s.length(); }
});
int totalLength = lineLengths.reduce(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer a, Integer b) { return a + b; }
});
或者
class GetLength implements Function<String, Integer> {
public Integer call(String s) { return s.length(); }
}
class Sum implements Function2<Integer, Integer, Integer> {
public Integer call(Integer a, Integer b) { return a + b; }
}
JavaRDD<String> lines = sc.textFile("data.txt");
JavaRDD<Integer> lineLengths = lines.map(new GetLength());
int totalLength = lineLengths.reduce(new Sum());
请注意,Java 中的匿名内部类也可以访问封闭作用域内的变量,只要它们被标记为 final。Spark 会像其他语言一样,将这些变量的副本发送到每个工作节点。
理解闭包
https://spark.apache.org/docs/latest/rdd-programming-guide.html#understanding-closures
Spark 的难点之一是理解跨集群执行代码时变量和方法的作用域和生命周期。修改作用域之外变量的 RDD 操作经常会引发混淆。在下面的示例中,我们将查看使用 foreach() 来增加计数器的代码,但其他操作也会出现类似的问题。
考虑下面这个简单的 RDD 元素求和函数,其行为可能会根据执行是否在同一个 JVM 中而有所不同。一个常见的例子是在本地模式下运行 Spark(--master = "local[n]")与将 Spark 应用程序部署到集群(例如通过 spark-submit 到 YARN)时:
int counter = 0;
JavaRDD<Integer> rdd = sc.parallelize(data);
// Wrong: Don't do this!!
rdd.foreach(x -> counter += x);
println("Counter value: " + counter);
上述代码的行为尚未定义,可能无法按预期工作。为了执行作业,Spark 将 RDD 操作的处理分解为多个任务,每个任务由一个执行器 (executor) 执行。在执行之前,Spark 会计算任务的闭包。闭包是指执行器在 RDD 上执行计算(在本例中为 foreach())时必须可见的变量和方法。闭包会被序列化并发送给每个执行器。
发送给每个执行器的闭包中的变量现在都是副本,因此,当计数器在 foreach 函数中被引用时,它不再是驱动程序节点上的计数器。驱动程序节点的内存中仍然有一个计数器,但它对执行器不再可见!执行器只能看到序列化闭包中的副本。因此,计数器的最终值仍然为零,因为所有对计数器的操作都引用了序列化闭包中的值。
在本地模式下,在某些情况下,foreach 函数实际上会与驱动程序在同一个 JVM 中执行,并引用相同的原始计数器,并且可能会对其进行更新。
为了确保在这些情况下行为定义明确,应该使用累加器。Spark 中的累加器专门用于提供一种机制,当执行在集群中的工作节点之间分散时,可以安全地更新变量。一般来说,闭包(例如循环或本地定义的方法)不应用于修改某些全局状态。Spark 不定义或保证对闭包外部引用的对象进行修改的行为。某些执行此操作的代码可能在本地模式下有效,但这只是偶然,此类代码在分布式模式下不会按预期运行。如果需要进行某些全局聚合,应该使用累加器 (Accumulator)。详情见:https://spark.apache.org/docs/latest/rdd-programming-guide.html#accumulators
打印RDD
使用 rdd.foreach(println) 或 rdd.map(println) 打印 RDD 的元素。
在单机模式下,这将生成预期的输出并打印所有 RDD 元素。然而,在集群模式下,执行器调用的 stdout 输出现在写入执行器的标准输出,而不是驱动程序的标准输出,因此驱动程序的标准输出不会显示这些!要打印驱动程序上的所有元素,可以使用 collect() 方法首先将 RDD 带到驱动程序节点,如下所示:rdd.collect().foreach(println)。但这可能会导致驱动程序内存耗尽,因为 collect() 会将整个 RDD 提取到单机;如果您只需要打印 RDD 的几个元素,更安全的方法是使用 take():rdd.take(100).foreach(println)。
转换操作
https://spark.apache.org/docs/latest/rdd-programming-guide.html#transformations
Actions
https://spark.apache.org/docs/latest/rdd-programming-guide.html#actions
Shuffle操作
Spark 中的某些操作会触发称为 shuffle 的事件。shuffle 是 Spark 的一种机制,用于重新分配数据,使其在各个分区之间按不同的方式分组。这通常涉及在执行器和机器之间复制数据,这使得 shuffle 操作复杂且成本高昂。
参考:https://www.cnblogs.com/vonlinee/p/19016167
持久化RDD
https://spark.apache.org/docs/latest/rdd-programming-guide.html#rdd-persistence
Spark 中最重要的功能之一是跨操作将数据集持久化(或缓存)在内存中。持久化 RDD 时,每个节点都会将其计算的所有分区存储在内存中,并在针对该数据集(或由其派生的数据集)的其他操作中重用它们。这使得未来的操作速度更快(通常可提高 10 倍以上)。缓存是迭代算法和快速交互使用的关键工具。
您可以使用 persist() 或 cache() 方法将 RDD 标记为要持久化。在操作中首次计算时,它将保存在节点的内存中。Spark 的缓存具有容错功能——如果 RDD 的任何分区丢失,它将自动使用最初创建它的转换重新计算。
此外,每个持久化的 RDD 都可以使用不同的存储级别进行存储,例如,您可以将数据集持久化在磁盘上、以序列化 Java 对象的形式持久化在内存中(以节省空间)以及跨节点复制。这些级别可以通过将 StorageLevel 对象(Python、Scala、Java)传递给 persist() 来设置。cache() 方法是使用默认存储级别的简写,默认存储级别为 StorageLevel.MEMORY_ONLY(将反序列化的对象存储在内存中)。完整的存储级别如下:
共享变量
记录应用日志
在很多情况下,我们需要查看driver和executors在运行Spark应用程序时候产生的日志,这些日志对于我们调试和查找问题是很重要的。
Spark日志确切的存放路径和部署模式相关:
- 如果是Spark Standalone模式,我们可以直接在Master UI界面查看应用程序的日志,在默认情况下这些日志是存储在worker节点的work目录下,这个目录可以通过SPARK_WORKER_DIR参数进行配置。
- 如果是Mesos模式,我们同样可以通过Mesos的Master UI界面上看到相关应用程序的日志,这些日志是存储在Mesos slave的work目录下。
- 如果是YARN模式,最简单地收集日志的方式是使用YARN的日志收集工具(yarn logs -applicationId),这个工具可以收集你应用程序相关的运行日志,但是这个工具是有限制的:应用程序必须运行完,因为YARN必须首先聚合这些日志;而且你必须开启日志聚合功能(yarn.log-aggregation-enable,在默认情况下,这个参数是false)。
如果开启了日志聚合,日志会存放至hdfs,本地的日志会删除。
如果运行在YARN模式,可以在ResourceManager节点的WEB UI页面选择相关的应用程序,在页面点击表格中Tracking UI列的ApplicationMaster,这时候你可以进入到Spark作业监控的WEB UI界面,这个页面就是你Spark应用程序的proxy界面,当然你也可以通过访问Driver所在节点开启的4040端口,同样可以看到这个界面。
到这个界面之后,可以点击Executors菜单,这时候你可以进入到Spark程序的Executors界面,里面列出所有Executor信息,以表格的形式展示,在表格中有Logs这列,里面就是你Spark应用程序运行的日志。
如果在程序中使用了println()输出语句,这些信息会在stdout文件里面显示;其余的Spark运行日志会在stderr文件里面显示。
默认情况下Spark应用程序的日志级别是INFO的,可以自定义Spark应用程序的日志输出级别,在$SPARK_HOME/conf/log4j.properties文件里面进行修改,如下所示:
log4j.rootLogger=INFO,rolling
# Setting properties to have logger logs in local file system
log4j.appender.rolling=org.apache.log4j.RollingFileAppender
log4j.appender.rolling.encoding=UTF-8
log4j.appender.rolling.layout=org.apache.log4j.PatternLayout
log4j.appender.rolling.layout.conversionPattern=[%d] %p %m (%c)%n
log4j.appender.rolling.maxBackupIndex=5
log4j.appender.rolling.maxFileSize=50MB
# Setting properties to have logger logs in console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.encoding=UTF-8
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.conversionPattern=[%d] (%t) %p -%l %m (%c)%n
log4j.appender.console.target=System.err
log4j.logger.org.apache.spark=OFF
log4j.logger.org.spark-project=OFF
log4j.logger.org.apache.hadoop=OFF
log4j.logger.io.netty=OFF
log4j.logger.org.apache.zookeeper=OFF
log4j.appender.rolling.file=/tmp/logs/application.log
这样Spark应用程序在运行的时候会打出WARN级别的日志,然后在提交Spark应用程序的时候使用–files参数指定上面的log4j.properties文件路径即可使用这个配置打印应用程序的日志
Spark应用打包
maven-shade-plugin
此插件的使用参考:https://www.cnblogs.com/vonlinee/p/19373726
maven-shade-plugin 不支持 scala 源文件
https://stackoverflow.com/questions/55309684/does-maven-shade-plugin-work-with-scala-classes
Idea Spark插件
直接在Idea插件市场下载即可。插件似乎只支持SparkSession的getOrCreate这个API,在getOrCreate这一行会出现一个Spark的图标
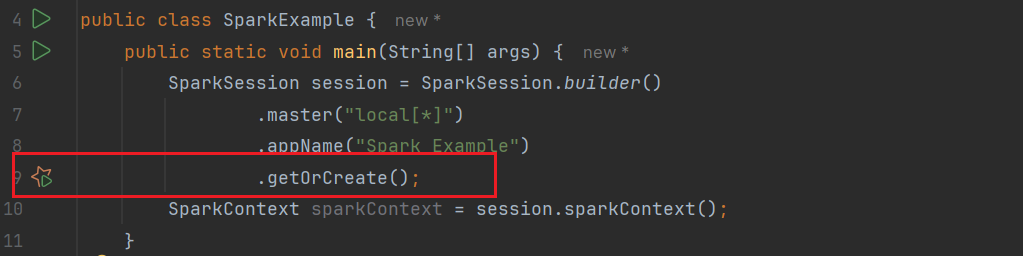
这里我使用虚拟机搭建一个伪集群演示一下这个插件的用法:
首先,点击星星图标,会提示创建一个运行配置
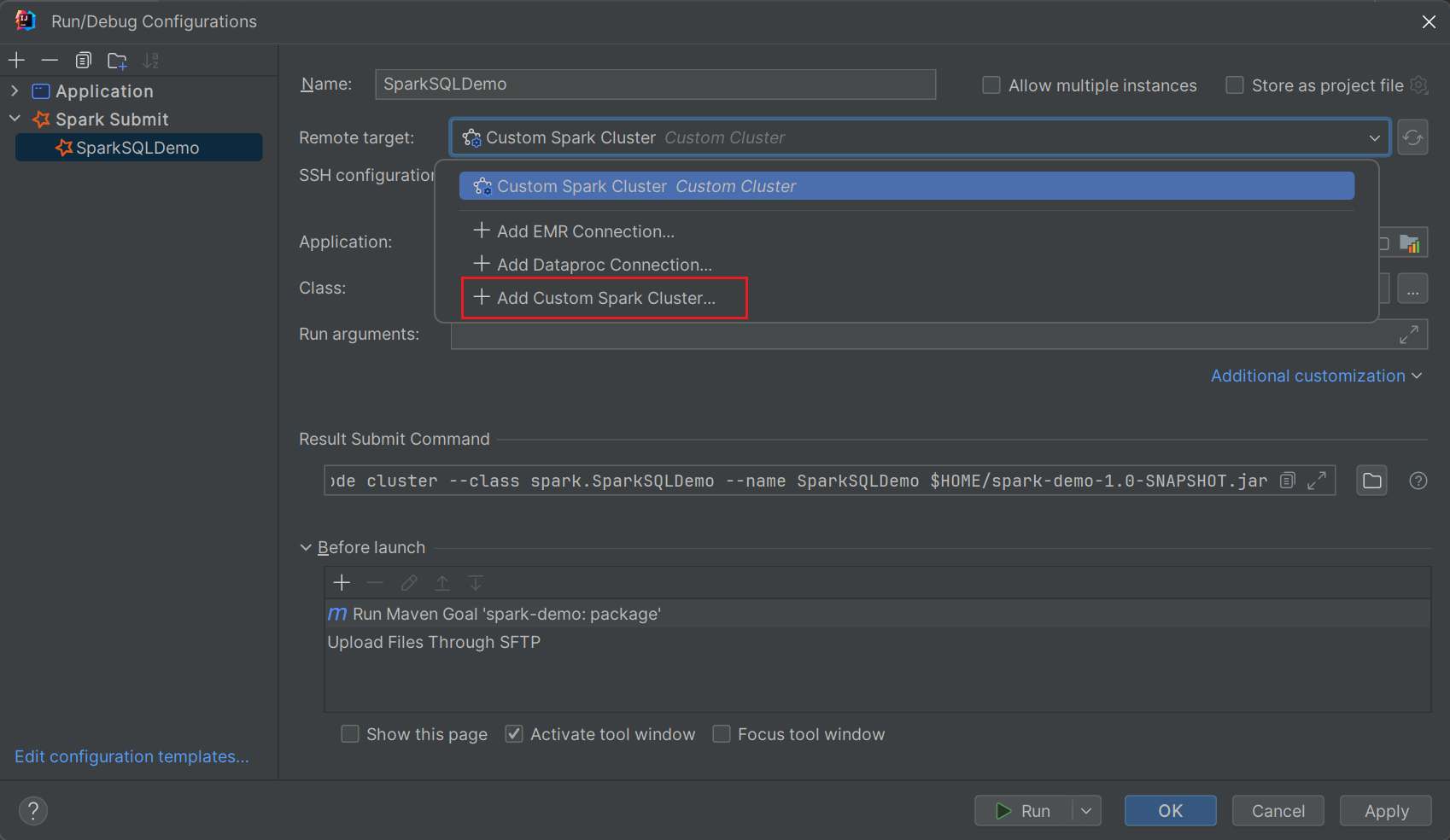
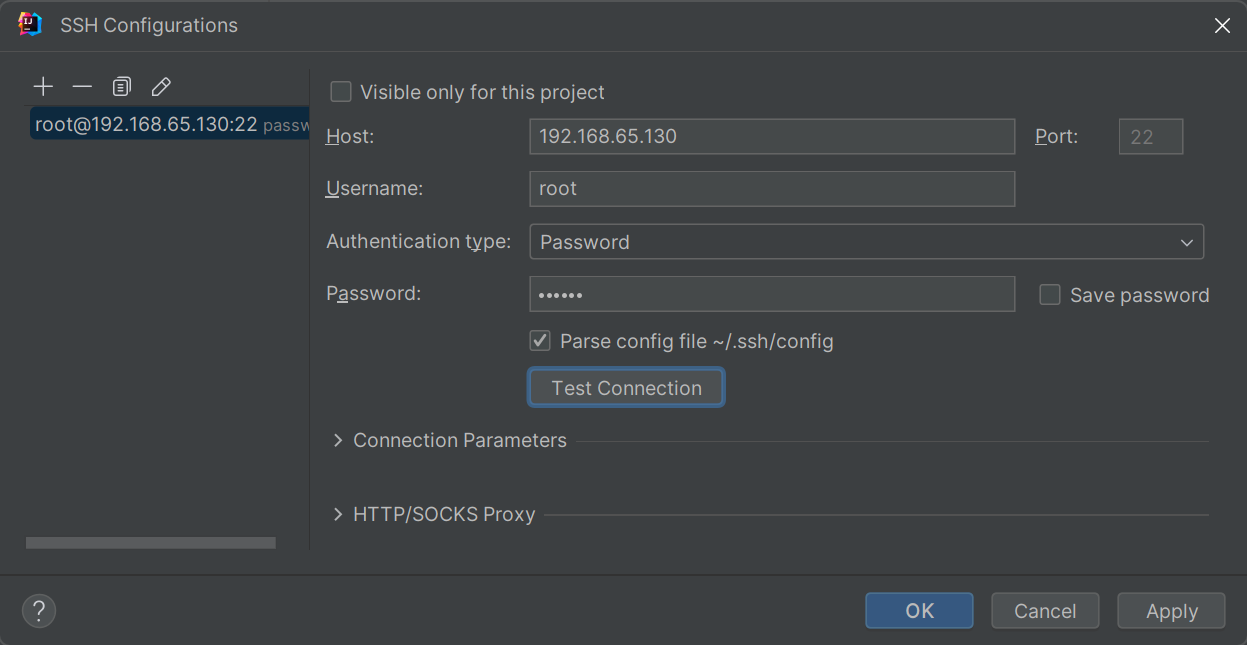
Remote target选择自定义集群配置,如果未配置SSH,会提示创建SSH配置,如下图所示
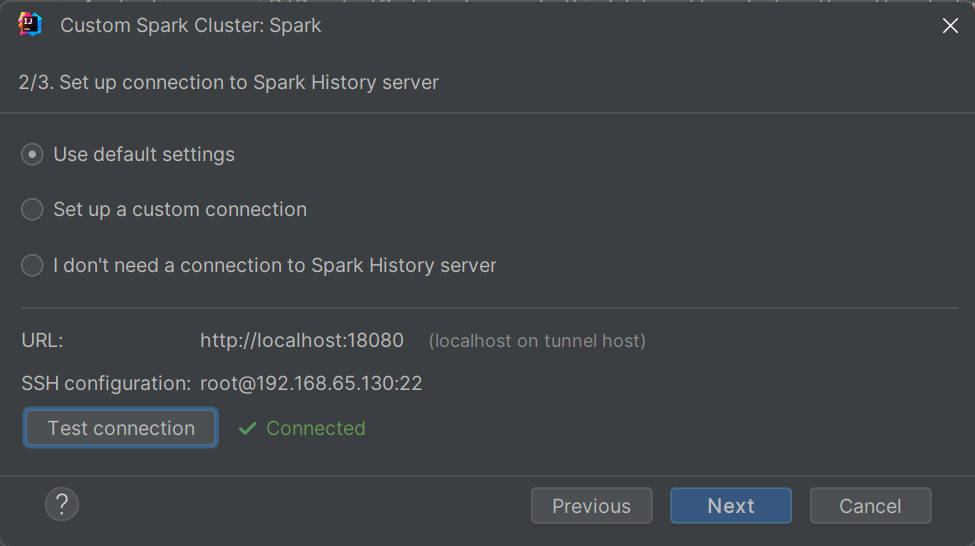
然后下一步:配置History Server连接
下一步:初始化SFTP设置
配置好后就可以直接通过IDE运行当前Spark程序,不需要繁琐的打包,上传,再通过spark-submit提交任务这个过程了。点击右上角的运行按钮就会进行打包,上传包,执行spark-submit这一过程
单文件打包运行
注意目录和包名需要对应
# 编译
$JAVA8_HOME/bin/javac -cp $env:SPARK_HOME/jars/* -encoding UTF-8 .demo/TestApp.java
# 打jar包
$JAVA8_HOME/bin/jar cf spark.jar ./demo/*
# 然后通过spark-submit提交即可
常见问题
- A master URL must be set in your configuration
本地运行,需要设置master地址,如果通过spark-submit提交方式来执行,master需要通过spark-submit来传递
- Exception in thread "main" org.apache.spark.SparkException: Task not serializable
Java SDK中函数需要实现java.io.Seriable接口

 浙公网安备 33010602011771号
浙公网安备 33010602011771号