
Spark Shuffle原理
数据分区
例如,当从本地文件系统加载一个文本文件到Spark时,文件的内容会被拆分成多个分区,这些分区会被均匀地分配给集群中的节点。可能有多个分区最终落在同一个节点上。所有这些分区的总和构成了你的RDD,这也是弹性分布式数据集中分布式一词的由来。图4.1展示了将文本文件的行加载到五节点集群中的RDD的分布情况。原始文件有15行文本,因此每个RDD分区包含3行文本。每个RDD都维护一个分区列表和一个可选的首选位置列表,用于计算这些分区。
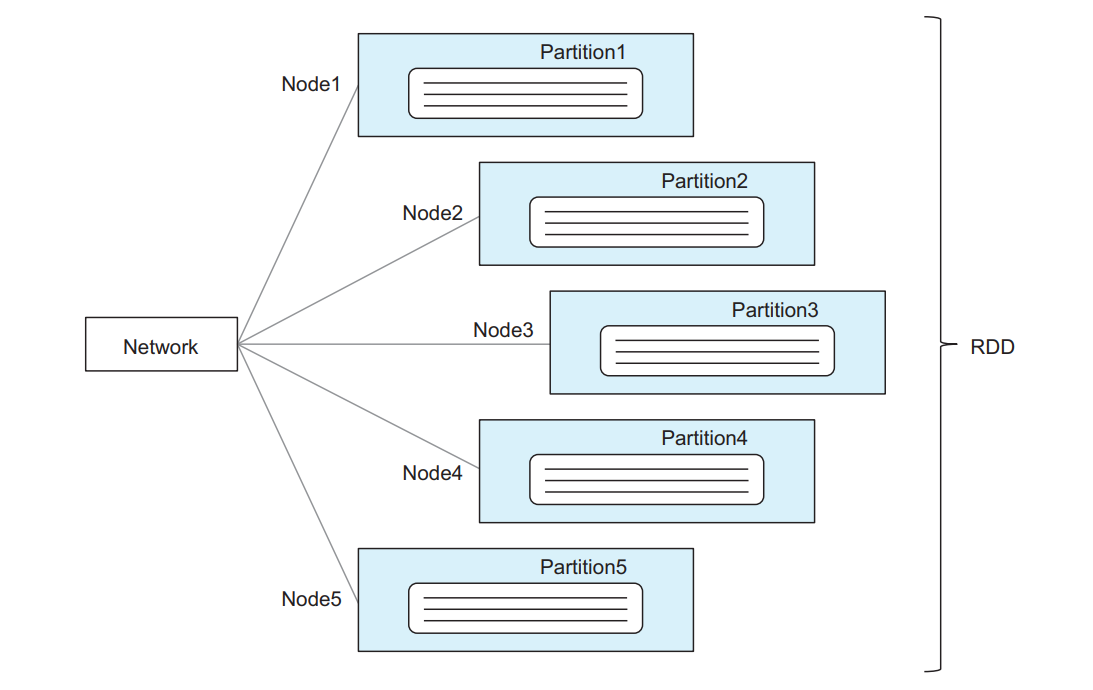
五节点集群中RDD分区的简化示意图。该RDD是通过使用SparkContext的textFile方法加载文本文件来创建。加载的
文本文件中有15行文本,因此每个分区由3行文本组成。
RDD分区的数量很重要,因为它除了影响数据之外分布在整个集群中,它还直接决定了任务的数量这将运行RDD转换。如果这个数字太小,集群将未充分利用。此外,还可能引发内存问题,因为工作集可能会变得太大,无法放入执行器的内存中。我们建议使用三个
分区数量是集群中核心数量的四倍。适度更大的值这应该不成问题,所以你可以放心尝试。但别太疯狂,因为管理大量任务可能会造成瓶颈。
分区器
HashPartitioner
HashPartitioner是Spark中的默认分区器。它基于元素的JVM平台上的hashcode或者pair RDD中key的hashcode计算分区索引,根据下面这个简单的公式:
partitionIndex = hashCode % numberOfPartitions
partitionIndex是准随机确定的,因此最有可能的情况下是,分区大小不会完全相同。在具有相对较少部分的大型数据集中,该算法可能会在它们之间均匀分布数据。
使用HashPartitioner需要指定分区数量
HashPartitioner hashPartitioner = new HashPartitioner(10);
配置spark.default.parallelism指定HashPartitioner的默认分区数量,如果用户没有指定该参数,则默认分区数量为集群中的核心数量。
RangePartitioner
RangePartitioner 用于对 RDD 的数据进行有序分区。它根据给定的范围将数据分配到不同的分区中,以确保同一分区中的数据在某种顺序上是有序的。RangePartitioner 通常用于需要对数据进行排序或需要确保相同键的数据在同一分区中的场景。
RangePartitioner 主要用于 PairRDD,因为它需要基于key进行分区。
JavaSparkContext sc = new JavaSparkContext("local", "Range Partitioner Example");
// 创建一个键值对 RDD
JavaPairRDD<Integer, String> rdd = sc.parallelizePairs(Arrays.asList(
new Tuple2<>(1, "a"),
new Tuple2<>(2, "b"),
new Tuple2<>(3, "c"),
new Tuple2<>(4, "d"),
new Tuple2<>(5, "e")
));
// 使用 RangePartitioner 进行分区
int numPartitions = 3;
RangePartitioner<Integer, String> partitioner = new RangePartitioner<>(numPartitions, rdd.rdd());
JavaPairRDD<Integer, String> partitionedRDD = rdd.partitionBy(partitioner);
// 查看每个分区的数据
partitionedRDD.mapPartitionsWithIndex((index, iter) -> {
List<String> list = new ArrayList<>();
iter.forEachRemaining(pair -> list.add(index + ": " + pair));
return list.iterator();
}, true).collect().forEach(System.out::println);
sc.close();
自定义分区器
只有pair RDD可以使用自定义分区器。绝大多数变换操作除了指定变换所需的函数外,还有几个重载方法,添加了额外2个参数,一个是int类型的分区数量,另一个是Partitioner类型,指定分区器。不包含分区器的方法默认会使用HashPartitioner。例如下面2行实际上是等效的
rdd.foldByKey(afunction, 100)
rdd.foldByKey(afunction, new HashPartitioner(100))
理解Shuffle
分区之间的数据移动称为Shuflle,当数据需要组合多个分区,以便为新的分区构建分区RDD。
当按key对元素进行分组时,Spark需要检查RDD所有的分区,找到具有相同key的元素,然后对它们进行物理分组,
从而形成新的分区。
环境准备
https://github.com/spark-in-action/first-edition/tree/master/ch04
书中代码基于Spark 1.x版本,这里做了一些改动,使用Spark3.3.1版本的API
- 在HDFS准备好使用到的测试数据文件
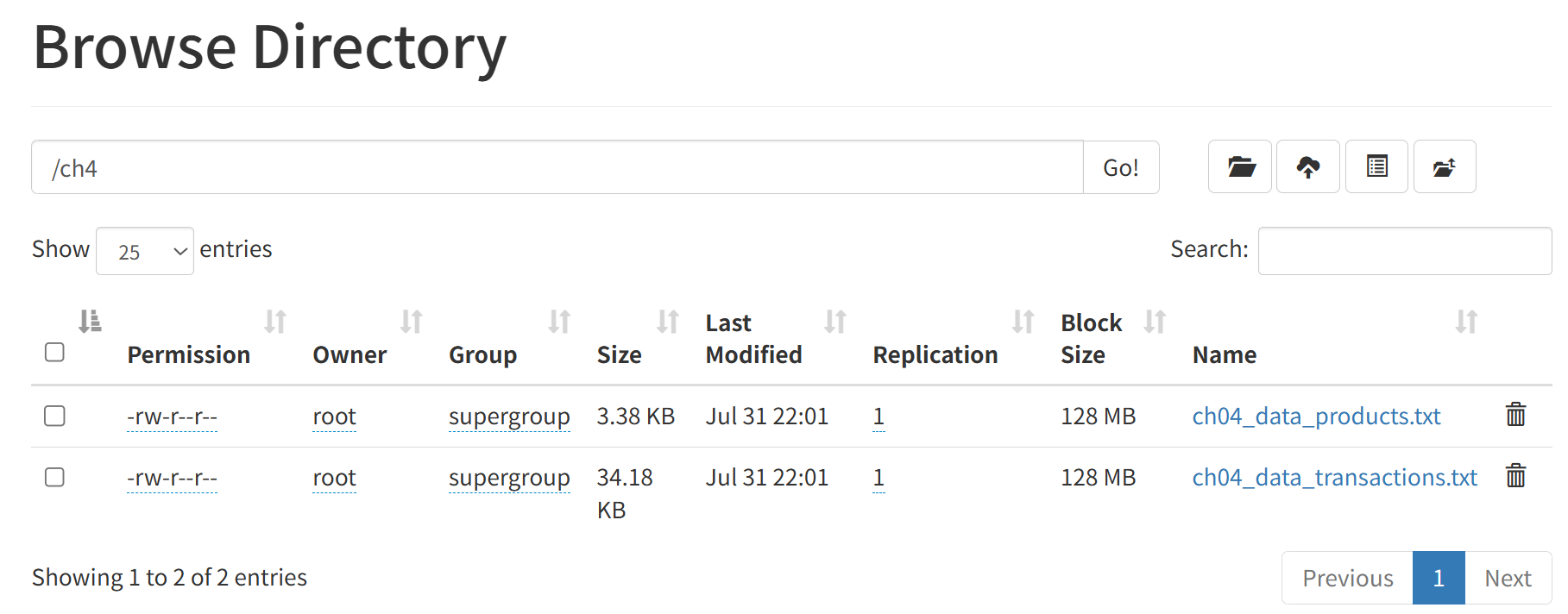
这两个测试文件可以在下面的地址下载:
https://github.com/spark-in-action/first-edition/blob/master/ch04/ch04_data_products.txt
https://github.com/spark-in-action/first-edition/blob/master/ch04/ch04_data_transactions.txt
其中 ch04_data_transactions.txt 文件包含1000行交易信息,每一行包含交易日期、时间、客户ID、产品ID、数量和产品价格,用#符号分隔。例如:
交易日期#时间#客户ID#产品ID#数量#产品价格
2015-03-30#6:55 AM#51#68#1#9506.21
- 配置好History Server
Shuffle示例
使用到的pom.xml文件
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>3.3.1</spark.version>
<scala.version>2.13</scala.version>
</properties>ss
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.2</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<finalName>SparkShuffleDemo</finalName>
<archive>
<manifest>
<mainClass>spark.SparkShuffleDemo</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<configuration>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
Spark程序示例:
package spark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class SparkShuffleDemo {
public static void main(String[] args) throws IOException {
final String hdfs = "hdfs://192.168.65.130:9000";
SparkConf conf = new SparkConf();
// conf.setMaster("local[*]");
conf.setAppName("SparkShuffleDemo");
conf.set("spark.eventLog.enabled", "true");
conf.set("spark.eventLog.dir", hdfs + "/spark-logs");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> tranFile = sc.textFile(hdfs + "/ch4/ch04_data_transactions.txt");
JavaRDD<String[]> tranData = tranFile.map((String line) -> line.split("#"));
// 按客户ID分组
JavaPairRDD<Integer, String[]> transByCust = tranData.mapToPair((String[] tran) -> new Tuple2<>(Integer.valueOf(tran[2]), tran));
JavaPairRDD<Integer, List<String>> prods = transByCust.aggregateByKey(new ArrayList<>(), (List<String> prods2, String[] tran) -> {
prods2.add(tran[3]);
return prods2;
}, (List<String> prods1, List<String> prods2) -> {
prods1.addAll(prods2);
return prods1;
});
System.out.println("Products per customer: " + prods.collect());
sc.close();
}
}
打包并提交任务
mvn clean package
# 使用spark-submit提交任务
spark-submit --class spark.SparkShuffleDemo --master yarn ./SparkShuffleDemo.jar

27行的JavaPairRDD<Integer, String[]> transByCust = tranData.mapToPair((String[] tran) -> new Tuple2<>(Integer.valueOf(tran[2]), tran));进行了Shuffle Read操作,36行的prods.collect()执行了Shuffle Write操作

整个过程如下图所示:
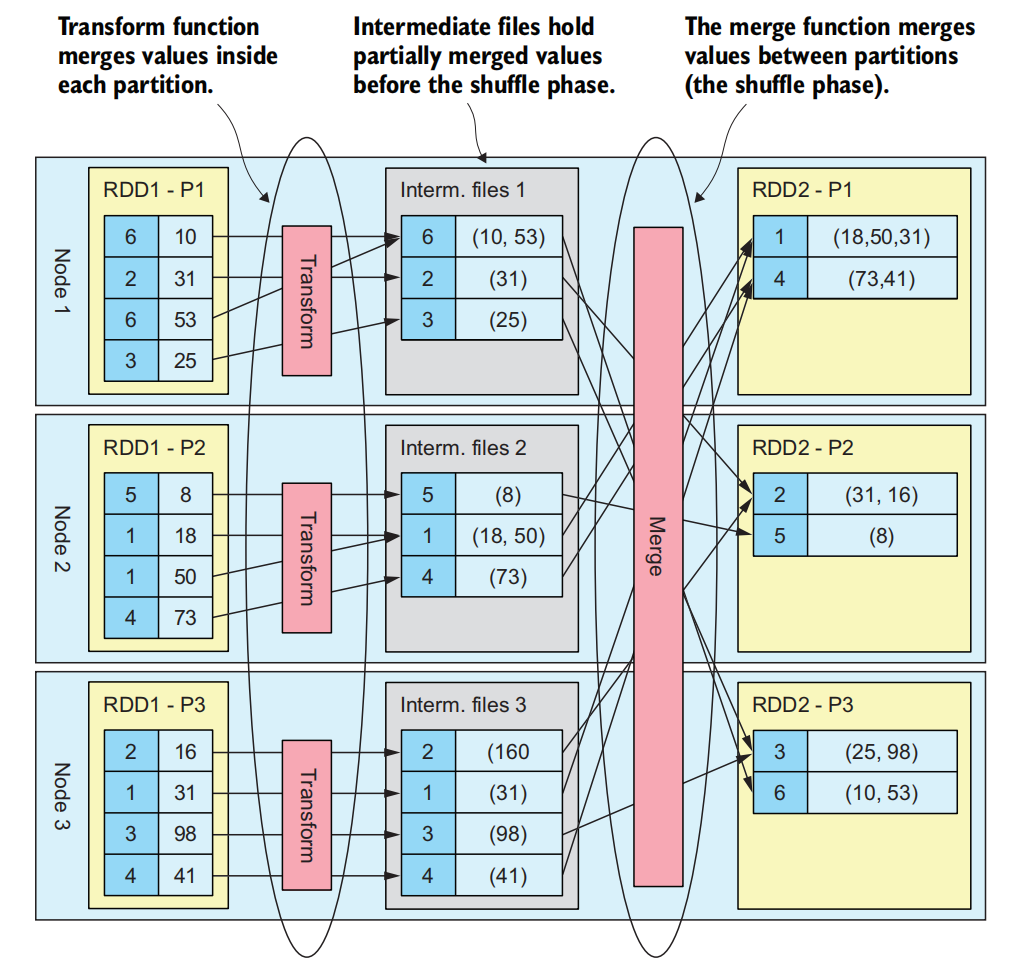
引起Shuffle的代码如下:
JavaPairRDD<Integer, List<String>> prods = transByCust.aggregateByKey(new ArrayList<>(),
(List<String> prods2, String[] tran) -> {
prods2.add(tran[3]);
return prods2;
}, (List<String> prods1, List<String> prods2) -> {
prods1.addAll(prods2);
return prods1;
});
在shuffle之前的任务称为map,之后的任务称为reduce任务,map任务的结果被写入中间文件(通常写入操作系统的文件系统缓存)和通过reduce任务读取。除了写到磁盘,数据是通过网络发送的,因此在Spark作业期间尽量减少Shuffle次数非常重要。
什么场景会Shuffle
虽然大多数RDD变换操作不需要Shuffle,但对于其中一些变换操作,Shuffle仅在特定条件下发生。因此,为了尽量减少shuffle出现的次数,需要了解这些条件。
显式改变分区
当使用与之前不同的HashPartitioner时,也会发生数据重排。
两个HashPartitioner若具有相同的分区数量则被视为相同(因为只要分区数量相同,它们对同一对象总会选择相同的分区)。因此,如果在转换过程中使用了分区数量与之前不同的哈希分区器,同样会触发Shuffle。
移除分区
有时尽管使用的是默认的分区器,变换操作也会导致Shuffle。map和flatMap变换会删除RDD的分区器,但不会引起Shuffle,但如果操作得到的RDD,即使使用默认的分区器,也会出现shuffle。
scala> val rdd:RDD[Int] = sc.parallelize(1 to 10000)
scala> rdd.map(x => (x, x*x)).map(_.swap).count() // no shuffle
scala> rdd.map(x => (x, x*x)).reduceByKey((v1, v2)=>v1+v2).count() // shuffle
对应的Java API版本:
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> rdd = sc.parallelize(IntStream.range(1, 10000).boxed().collect(Collectors.toList()));
// 第一部分:map 和 swap 操作
long count1 = rdd
.mapToPair((PairFunction<Integer, Integer, Integer>) x -> new Tuple2<>(x, x * x))
.mapToPair(Tuple2::swap) // 交换元组
.count(); // 计算数量
System.out.println("Count after swap: " + count1);
// 第二部分:reduceByKey 操作
long count2 = rdd
.mapToPair((PairFunction<Integer, Integer, Integer>) x -> new Tuple2<>(x, x * x))
.reduceByKey((Function2<Integer, Integer, Integer>) Integer::sum)
.count();
System.out.println("Count after reduceByKey: " + count2);
sc.close();
在map和flatMap操作之后会引起Shuffle的操作还有:
- 对pair RDD的变换操作,比如:aggregateByKey, foldByKey, reduceByKey, groupByKey, join, leftOuterJoin, rightOuterJoin, fullOuterJoin 以及 subtractByKey,这些操作都会改变RDD的分区器
- 普通RDD的变换操作:subtract, intersection以及groupWith
- 排序操作任务情况下都会引起Shuffle:比如sortByKey变换操作
- 指定了shuffle为true的partitionBy和coalesce操作
使用外部Shuffle服务
在Shuffle过程中,Executor需要相互读取文件(Shuffle是基于拉取的)。如果一些Executor挂了,其他Executor将无法再获得shuffle数据流中断。
外部shuffle服务旨在通过以下方式优化shuffle数据的交换
提供了一个Executor可以读取中间Shuffle文件的单一点。如果启用外部shuffle服务(通过将spark.shuffle.service.enabled设置为true),每个工作节点启动一个外部shuffle服务器。
重新分区
某些情况下需要显式地对RDD进行重新分区,以便更有效地分配工作负载或避免内存问题。例如,一些Spark操作默认分区数量较少,这会导致具有太多元素(占用太多内存)并且没有提供足够的分区并行度。
RDD的重新分区可以通过partitionBy,coalesce、repartition和repartitionAndSortWithinPartition这些转换操作来实现
partitionBy
partitionBy只能在pair RDD上使用,接收一个Partitioner作为参数
JavaPairRDD<K, V> partitionBy(Partitioner partitioner)
如果传入的Partitioner和之前使用的是同一个,则分区会保留
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> rdd = sc.parallelize(IntStream.range(1, 10000).boxed().collect(Collectors.toList()));
JavaPairRDD<Integer, Integer> pairRDD = rdd.mapToPair(
(PairFunction<Integer, Integer, Integer>) x -> new Tuple2<>(x, x * x));
Partitioner partitioner = rdd.partitioner().get();
pairRDD = pairRDD.partitionBy(partitioner);
如果使用新的,会导致Shuffle操作
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> rdd = sc.parallelize(IntStream.range(1, 10000).boxed().collect(Collectors.toList()));
JavaPairRDD<Integer, Integer> pairRDD = rdd.mapToPair(
(PairFunction<Integer, Integer, Integer>) x -> new Tuple2<>(x, x * x));
pairRDD = pairRDD.partitionBy(new HashPartitioner(5));
coalesce/repartition
coalesce意为合并,用于减少或增加分区数量。完整的方法签名是
coalesce(numPartitions:Int,shuffle:Boole=false)
第二个(可选)参数指定是否应执行Shuffle,默认为false。如果想增加分区的数量,有必要将shuffle参数设置为true。repartition这个方法可以理解为将shuffle设置为true的的coalesce方法。
重新分区算法平衡新分区,因此它们基于相同数量的已有的分区,尽可能多地使用本地机器上的数据(尽量减少数据移动),同时也要尝试在整个系统中平衡分区之间的数据。
如果变换操作本身不会导致shuffle,是否指定shuffle参数有一点区别
- 在未指定Shuffle参数的情况下(默认为false),所有变换操作将使用新指定的这些Executor运行
JavaSparkContext sc = new JavaSparkContext(conf);
// 假设executor数量为5
JavaRDD<Integer> rdd = sc.parallelize(IntStream.range(1, 10000).boxed().collect(Collectors.toList()));
JavaPairRDD<Integer, Integer> pairRDD = rdd.mapToPair(
(PairFunction<Integer, Integer, Integer>) x -> new Tuple2<>(x, x * x));
JavaRDD<Tuple2<Integer, Integer>> rdd1 = pairRDD.map(
(Function<Tuple2<Integer, Integer>, Tuple2<Integer, Integer>>) v ->
new Tuple2<>(v._1 + v._2, v._1 * v._2));
// 指定10个分区
rdd1.coalesce(10);
rdd1.map((Function<Tuple2<Integer, Integer>, Tuple2<Integer, Integer>>)
v -> new Tuple2<>(v._1 + v._2, v._1 * v._2));
// 以上所有变换操作都是在这10个分区上运行
- 在指定Shuffle参数的情况下,coalesce操作之前的变换操作会在之前的Executor上执行,而coalesce操作之后的变换操作会在新的分区上执行
JavaSparkContext sc = new JavaSparkContext(conf);
// 假设executor数量为5
JavaRDD<Integer> rdd = sc.parallelize(IntStream.range(1, 10000).boxed().collect(Collectors.toList()));
JavaPairRDD<Integer, Integer> pairRDD = rdd.mapToPair(
(PairFunction<Integer, Integer, Integer>) x -> new Tuple2<>(x, x * x));
JavaRDD<Tuple2<Integer, Integer>> rdd1 = pairRDD.map(
(Function<Tuple2<Integer, Integer>, Tuple2<Integer, Integer>>) v ->
new Tuple2<>(v._1 + v._2, v._1 * v._2));
// 指定10个分区
rdd1.coalesce(10, true);
// 后面的操作在新加的5个分区上运行
rdd1.map((Function<Tuple2<Integer, Integer>, Tuple2<Integer, Integer>>)
v -> new Tuple2<>(v._1 + v._2, v._1 * v._2));
repartitionAndSortWithinPartitions
repartitionAndSortWithinPartitions只能用在可排序的RDD上,即调用了sortByKey的pair RDD。repartitionAndSortWithinPartitions操作必定会执行Shuffle。
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> rdd = sc.parallelize(IntStream.range(1, 10000).boxed().collect(Collectors.toList()));
JavaPairRDD<Integer, Integer> pairRDD = rdd.mapToPair(
(PairFunction<Integer, Integer, Integer>) x -> new Tuple2<>(x, x * x));
JavaPairRDD<Integer, Integer> sortByKeyRDD = pairRDD.sortByKey();
sortByKeyRDD.repartitionAndSortWithinPartitions(new HashPartitioner(10));
理论上来说repartitionAndSortWithinPartitions比coalesce的性能好些,因为在Shuffle过程中就可以进行部分排序操作
分区间Map操作
Spark提供了一种方法,可以将函数应用于RDD的每个部分,而不是整个RDD
这种机制也是避免Shuffle的一种方式
mapPartitions、mapPartitionsWithIndex
和map的区别就是map变换中每次变换的对象是RDD中的一个元素,而mapPartitions和mapPartitionsWithIndex每次变换的对象是RDD中一个分区中的所有元素
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> rdd = sc.parallelize(IntStream.range(0, 10000).boxed().collect(Collectors.toList()), 10);
System.out.println("count of partitions = " + rdd.partitions().size());
JavaRDD<Integer> rdd1 = rdd.mapPartitions(new FlatMapFunction<Iterator<Integer>, Integer>() {
@Override
public Iterator<Integer> call(Iterator<Integer> it) throws Exception {
List<Integer> list = new ArrayList<>();
while (it.hasNext()) {
list.add(it.next());
}
System.out.println(list.size()); // 1000
return it; // 用于创建新的RDD
}
});
System.out.println(rdd1.count()); // 0
preservePartitioning参数
mapPartitions和mapPartitionsWithIndex都提供了一个参数preservePartitioning,区别在于mapPartitions这个参数非必填,默认是false,而mapPartitionsWithIndex是必填的
如果为true,新的RDD会保留旧的RDD的分区,如果为false,则旧的RDD分区会被移除。
glom
glom() 是一个 RDD 转换操作,用于将每个分区中的元素转换为一个数组。这个操作会将 RDD 的每个分区的元素封装成一个数组,从而返回一个新的 RDD,其中每个元素代表一个分区的所有元素。
JavaSparkContext sc = new JavaSparkContext(conf);
List<Integer> list = IntStream.range(0, 10000).boxed().collect(Collectors.toList());
JavaRDD<Integer> rdd = sc.parallelize(list, 10);
JavaRDD<List<Integer>> rdd1 = rdd.glom();
rdd1.foreach(new VoidFunction<List<Integer>>() {
@Override
public void call(List<Integer> integers) throws Exception {
System.out.println("partition size = " + integers.size()); // 1000
}
});
Shuffle相关参数
spark.shuffle.manager:指定Shuffle实现,Spark有两种Shuffle实现:基于排序和基于哈希,可选值有:hash或者sort
spark.shuffle.consolidateFiles:是否合并Shuffle过程中创建的中间文件,默认值为false
spark.shuffle.spill:是否限制Shuffle任务使用的内存,对于超过限制的部分数据,将会溢出到磁盘,默认为
spark.shuffle.memoryFraction:指定内存大小限制,默认0.2,值不应过高,否则内存溢出
spark.shuffle.spill.compress:是否压缩溢出的数据,默认为true
spark.shuffle.compress:是否压缩中间文件,默认为true
spark.shuffle.spill.batchSize:指定溢出到磁盘时序列化或者反序列化的对象大小,默认值为10,000
spark.shuffle.service.port:指定使用外部Shuffle服务时,服务器监听的端口
参考资料
- 《Spark In Action》:https://www.amazon.com/Spark-Action-Jean-Georges-Perrin/dp/1617295523

 浙公网安备 33010602011771号
浙公网安备 33010602011771号