
Spark环境搭建
https://spark.apache.org/docs/latest/index.html
前置环境
-
JDK:确保安装的JDK版本与Spark兼容(通常建议使用Java 8或Java 11)
-
winutils:如果打算在Windows上运行Spark,尤其是使用Hadoop相关功能,建议下载WinUtils。
将winutils.exe放入%HADOOP_HOME%\bin目录下 -
安装Scala
https://www.scala-lang.org/download/all.html
直接下载对应的离线包进行安装即可
# centos
rpm -ivh ./scala-2.13.2.rpm
下载安装 Spark
兼容性
scala版本和spark版本的对应关系
Spark 2.x 系列支持Scala 2.11 和Scala 2.12。
Spark 3.x 系列支持Scala 2.12 和Scala 2.13。 因此,如果您要使用Spark 3.2.1,则需要使用Scala 2.12 或Scala 2.13。
Spark2.3对应的Scala版本是Scala2.11
[ERROR] Terminal initialization failed; falling back to unsupported
java.lang.NoClassDefFoundError: Could not initialize class scala.tools.fusesource_embedded.jansi.internal.Kernel32
可能是Spark版本和Scala版本不兼容,因为我Scala版本是2.13,而安装的Spark版本是2.3
参考:
https://issues.apache.org/jira/browse/SPARK-13710?page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel&focusedCommentId=15208529
安装spark-without-hadoop,执行spark-shell报错:
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.NoClassDefFoundError: org/slf4j/Logger
https://stackoverflow.com/questions/42307471/spark-without-hadoop-failed-to-launch
https://spark.apache.org/docs/latest/hadoop-provided.html
下载Spark:https://spark.apache.org/downloads.html
我们选择历史版本Spark3.3.1:https://archive.apache.org/dist/spark/ 下载.tgz结尾的安装包(注.tgz格式和.tar.gz格式是一样的),然后解压缩到本地某个目录
一些镜像地址:
https://spark.apache.org/docs/latest/api/R/reference/install.spark.html
添加SPARK_HOME环境变量:D:\Tools\spark-3.3.1
Path添加:%SPARK_HOME%\bin
测试是否安装成功:打开cmd命令行,输入spark-shell
如果执行spark-shell命令报错:Failed to find Spark jars directory.
You need to build Spark before running this program.
参考:https://stackoverflow.com/questions/27618843/why-does-spark-submit-and-spark-shell-fail-with-failed-to-find-spark-assembly-j
可能有以下几个原因:
- Windows上如果Spark安装在一个带有空格的目录,安装会失败,换个安装目录
- 刚才安装的Spark安装包没有包含编译后的代码,也就是二进制包,可能下载错了,应该下载二进制包,而不是源码包,因为我下载的是spark-2.3.0.tgz这个包进行安装的。这种情况下可以重新下载二进制包,或者在安装目录下执行:mvn -DskipTests clean package对源码进行编译(需要提前安装好maven),其实看刚才的解压目录下的根目录就有一个pom.xml文件
安装Hadoop
如果要搭建Spark On Yarn或者是需要去hdfs取数据的话,应该先装hadoop。关于spark和hadoop的关系,可以参考这篇博客:
https://blog.csdn.net/hongxingabc/article/details/81565174
如果安装Hadoop,根据前面安装的spark3.3.1,安装hadoop3.x版本,这里我安装3.3.0版本,安装过程移步:Hadoop安装与部署
Spark With Hadoop
执行spark-shell,出现下面的结果就是安装成功了
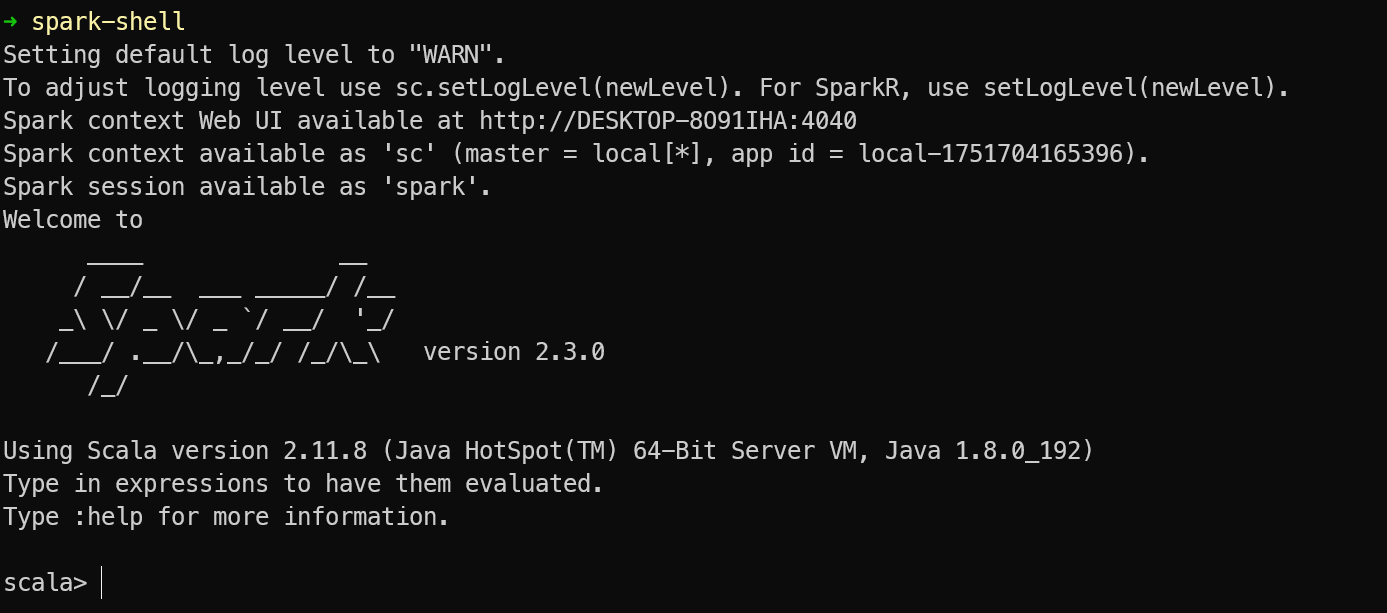
搭建本地开发环境
本地调试是使用本地编写的代码,通过引入的Spark的相关jar包来运行spark程序,将Spark程序提交到本地spark运行,本地并不需要安装Spark。下面是获取SparkContext的代码:
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(config)
也可以通过VM options上添加-Dspark.master=local -Dspark.app.name=test来进行设置
相关版本:Spark 3.3.1,Scala 2.13,Intellij IDEA 2025.2.1
Java + Maven
Spark 相关依赖的坐标:https://mvnrepository.com/artifact/org.apache.spark
创建Maven项目,pom.xml中添加如下配置
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>3.3.1</spark.version>
<scala.version>2.13</scala.version>
<scala.binary.version>2.13</scala.binary.version>
</properties>
<dependencies>
<!-- 如果使用spark-submit的话可以考虑指定作用范围为provided: <scope>provided</scope> -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.4.9</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.4.9</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-protocol</artifactId>
<version>2.4.9</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-shaded-client</artifactId>
<version>2.4.9</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
</dependency>
</dependencies>
如何知道Spark与Hadoop等其他组件的兼容版本
安装与Spark相关的其他组件的时候,例如JDK,Hadoop,Yarn,Hive,Kafka等,要考虑到这些组件和Spark的版本兼容关系。这个对应关系可以在Spark源代码的pom.xml文件中查看。在Github上的Spark仓库( https://github.com/apache/spark ) 。选择一个版本,例如选择3.3
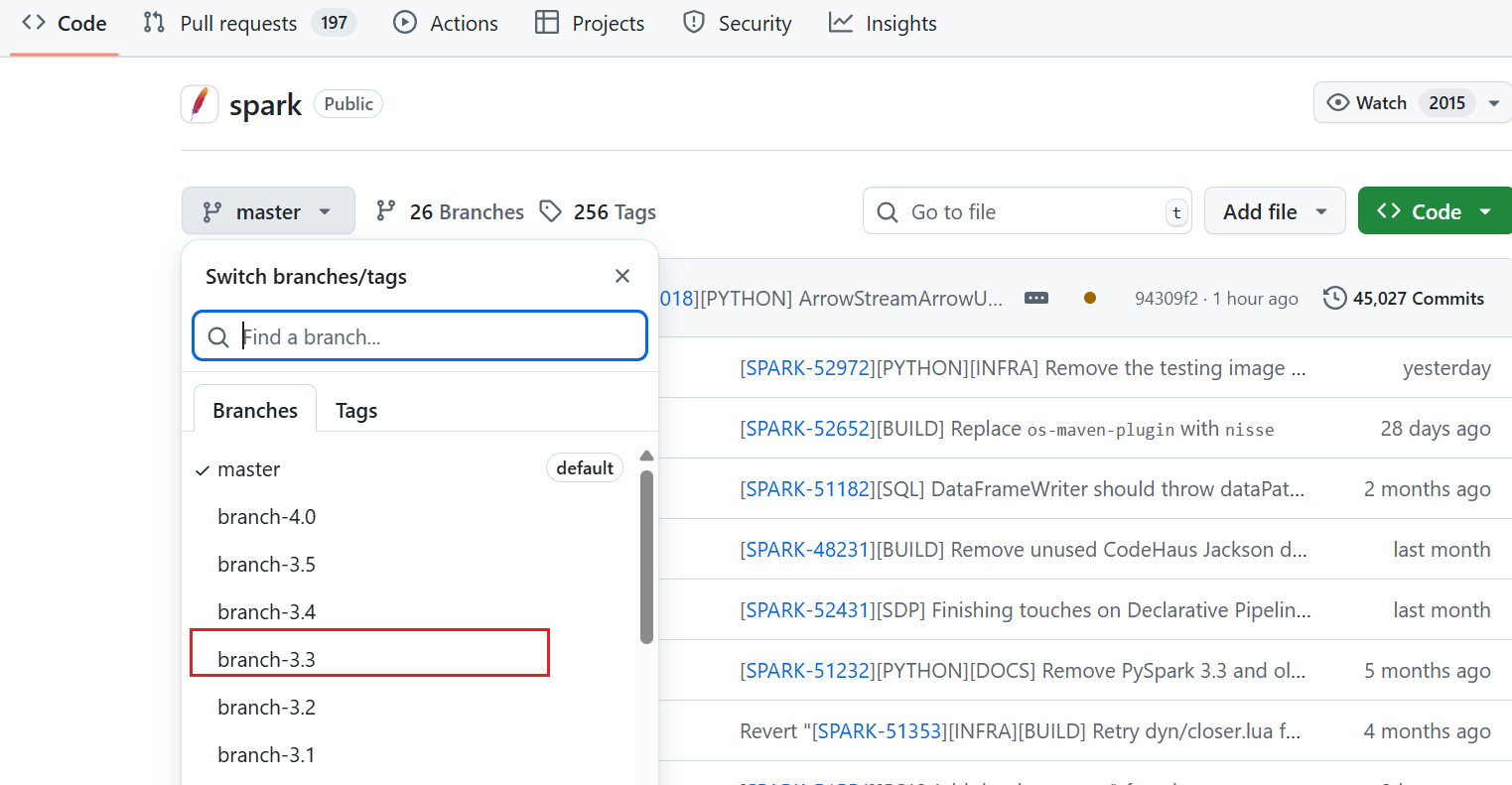
将下载的源代码压缩包解压后,打开里面的pom.xml文件,查看properties标签内各配置项,里面有列出其他组件的兼容版本信息
创建 SparkSession
我这里Yarn,HDFS,Spark WEB UI 都装在本地,所以相关地址都固定为 localhost 了,和我不一样的话自行修改
SparkSession spark = SparkSession.builder()
.appName("SparkApplication")
.master("local[*]") // 或者: yarn
.config("spark.eventLog.enabled", "true") // 开启事件日志
.config("spark.eventLog.dir", "hdfs://localhost:8020/user/spark/eventLogs") // 事件日志存放目录
.config("spark.history.fs.logDirectory", "hdfs://localhost:8020/user/spark/eventLogs")
.config("spark.yarn.historyServer.address", "http://localhost:18080") // 指定HistoryServer地址
.config("spark.sql.adaptive.enabled", "true")
.config("spark.sql.adaptive.coalescePartitions.enabled", "true")
.getOrCreate();
spark-submit
如果要用 spark-submit 的话,还要配置打包,使用 maven-shade-plugin
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.4.1</version>
<executions>
<execution>
<phase>package</phase>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<!-- 合并META-INF/services文件 -->
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
<!-- 合并Spring相关配置(如果有使用Spring) -->
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.handlers</resource>
</transformer>
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.schemas</resource>
</transformer>
<!-- 设置主类 -->
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.yourcompany.YourMainClass</mainClass>
</transformer>
</transformers>
<!-- 排除不需要的依赖 -->
<artifactSet>
<excludes>
<!-- 排除Spark相关依赖,因为它们已经在集群中提供了 -->
<exclude>org.apache.spark:spark-*</exclude>
<exclude>org.scala-lang:scala-*</exclude>
<exclude>org.apache.hadoop:hadoop-*</exclude>
<!-- 排除日志实现,使用集群提供的 -->
<exclude>org.slf4j:slf4j-*</exclude>
<exclude>log4j:log4j</exclude>
<exclude>org.apache.logging.log4j:log4j-*</exclude>
</excludes>
</artifactSet>
</configuration>
</execution>
</executions>
</plugin>
Scala
Idea 安装Scala插件
前置要求:Idea 安装Scala插件,有以下几种方式:
- 通过插件市场直接搜索Scala安装即可
- 下载离线安装包:https://plugins.jetbrains.com/plugin/1347-scala/versions/stable,
- Github地址,只有源码,需要自己构建:https://github.com/JetBrains/intellij-scala/tags
建议直接创建Maven项目,不然创建普通的scala项目极大可能会出现jar包依赖缺失的问题
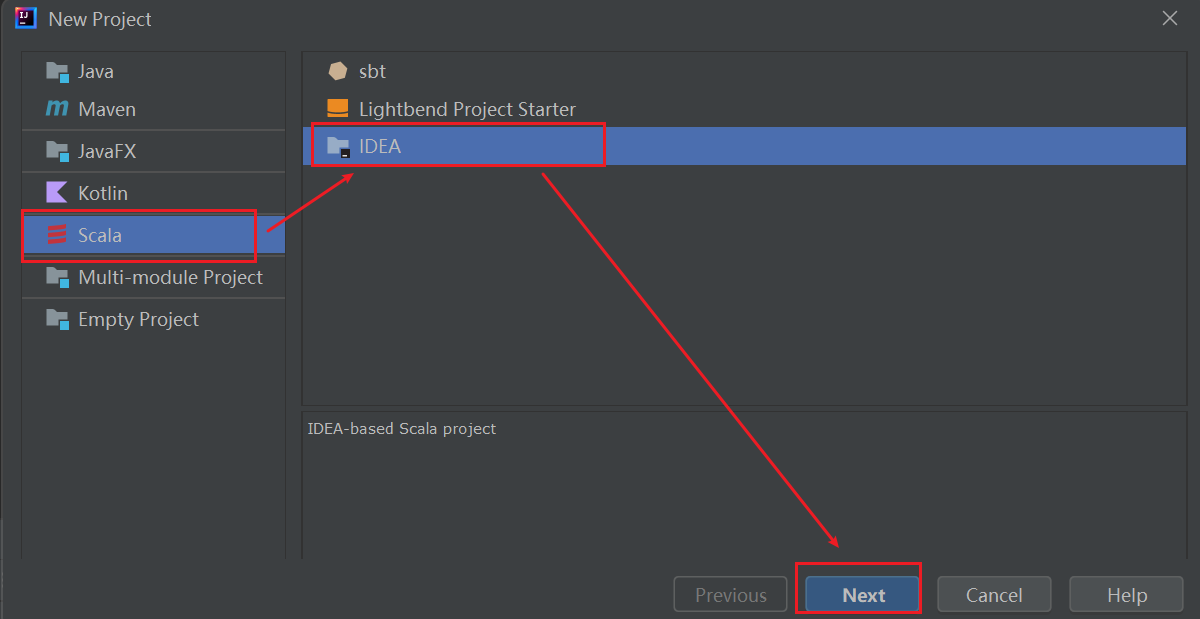
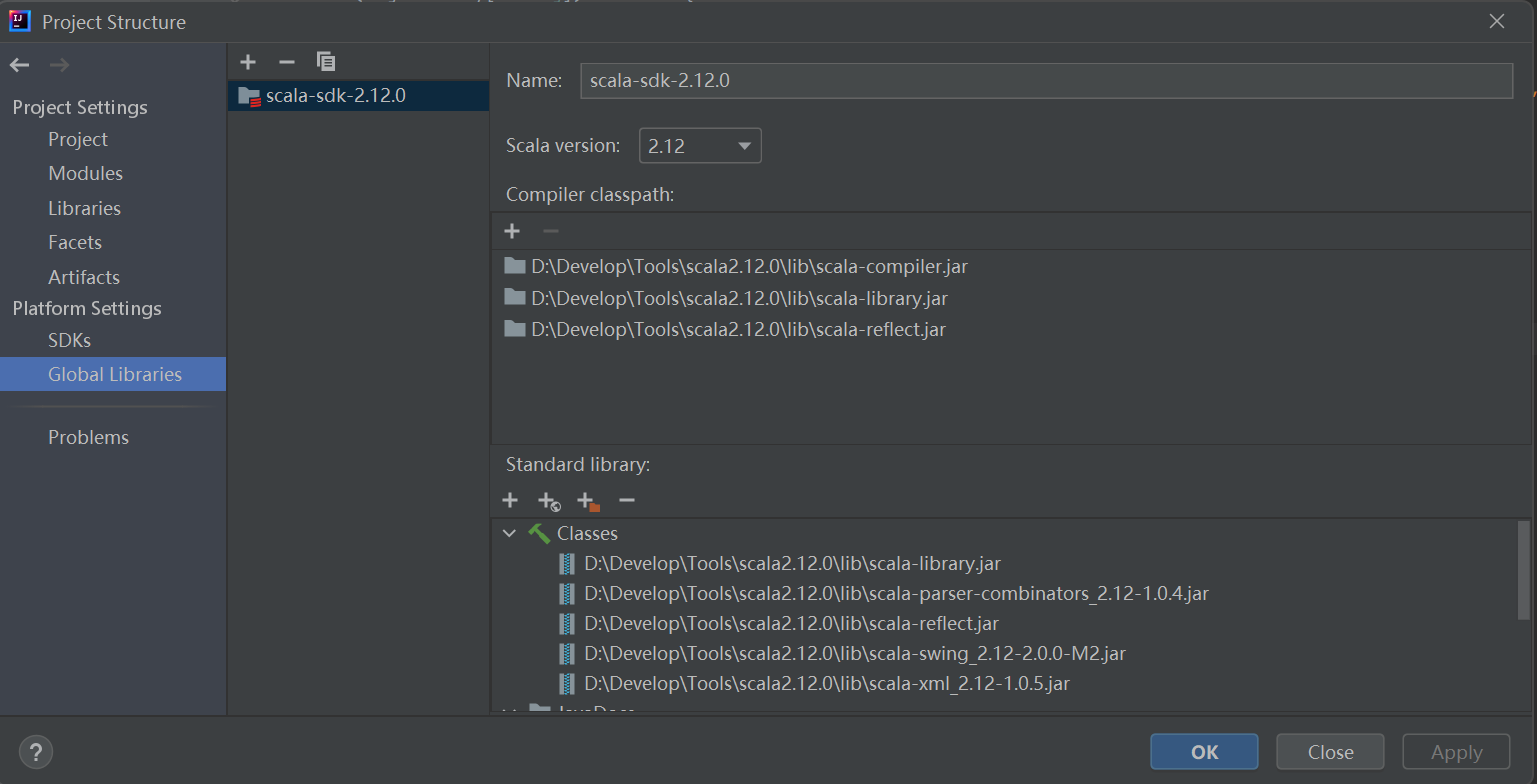
点击选择使用的scala版本
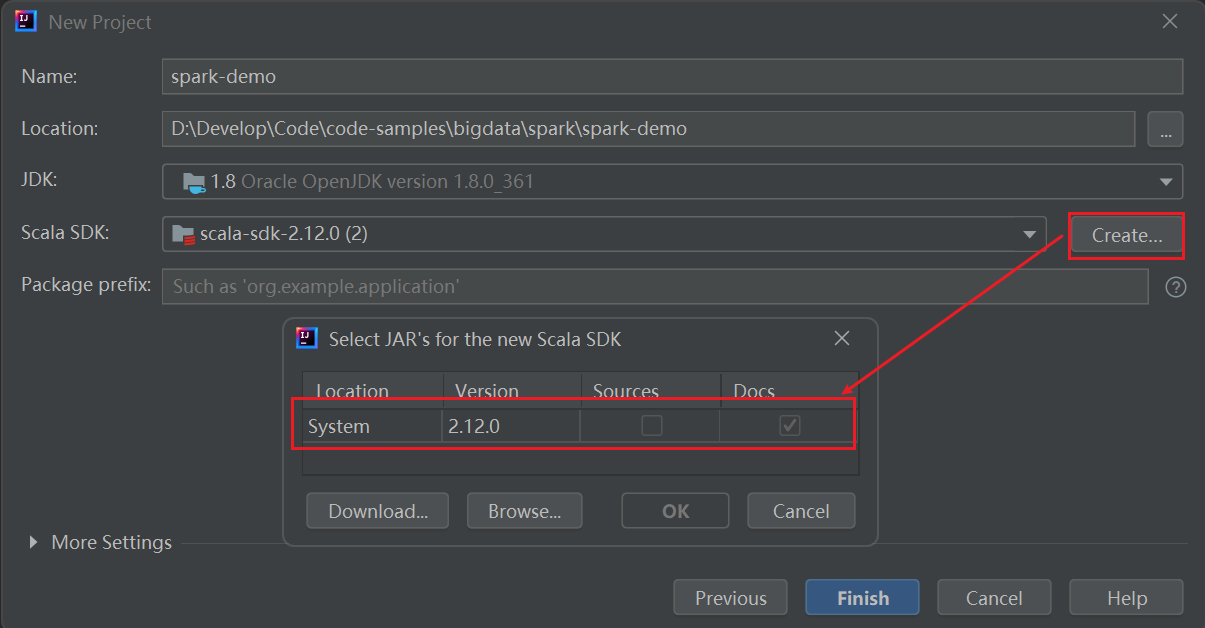
注意,这里创建项目里Location里填的最后一级目录就是项目名称,上面的Name输入框其实是没用的
在src目录上右键,选择New -> Scala Class,创建一个Scala Object,内容如下。
import org.apache.spark.{SparkContext, SparkConf}
object HelloWorld {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("GroupSort")
val sc = new SparkContext(conf)
val test = List(("key1", "123", 12, 2, 0.13), ("key1", "123", 12, 3, 0.18), ("key2", "234", 12, 1, 0.09), ("key1", "345", 12, 8, 0.75), ("key2", "456", 12, 5, 0.45))
val rdd = sc.parallelize(test)
val rdd1 = rdd.map(l => (l._1, (l._2, l._3, l._4, l._5))).groupByKey()
.flatMap(line => {
val topItem = line._2.toArray.sortBy(_._4)(Ordering[Double].reverse)
topItem.map(f => (line._1, f._1, f._4)).toList
})
rdd1.foreach(println)
sc.stop()
}
}
整个步骤和简单的java工程是一样的,
然后还需要引入Spark相关的依赖
Scala 版本的选择是根据你的Spark版本选择的,通过Spark官网下载页面可知相匹配的版本
Scala + SBT
直接基于 Idea 的Scala项目创建向导创建项目即可,构建系统选择 sbt
ThisBuild / version := "1.0.0"
ThisBuild / scalaVersion := "2.13.10"
ThisBuild / organization := "com.yourcompany"
lazy val root = (project in file("."))
.settings(
name := "spark-project"
)
// Java 版本设置
javacOptions ++= Seq("-source", "1.8", "-target", "1.8"),
scalacOptions += "-target:jvm-1.8",
val sparkVersion = "3.3.1"
val hadoopVersion = "3.3.4"
// Spark 核心依赖
libraryDependencies ++= Seq(
// Provided 作用域表示这些依赖在运行时由集群提供
"org.apache.spark" %% "spark-core" % sparkVersion % Provided,
"org.apache.spark" %% "spark-sql" % sparkVersion % Provided,
"org.apache.spark" %% "spark-mllib" % sparkVersion % Provided,
"org.apache.spark" %% "spark-streaming" % sparkVersion % Provided,
// Hadoop 相关依赖
"org.apache.hadoop" % "hadoop-common" % hadoopVersion % Provided,
"org.apache.hadoop" % "hadoop-client" % hadoopVersion % Provided,
"org.apache.hadoop" % "hadoop-hdfs" % hadoopVersion % Provided,
"org.apache.hadoop" % "hadoop-aws" % hadoopVersion,
// 其他常用依赖
"org.scala-lang" % "scala-library" % scalaVersion.value,
// 测试依赖
"org.apache.spark" %% "spark-core" % sparkVersion % Test classifier "tests",
"org.apache.spark" %% "spark-sql" % sparkVersion % Test classifier "tests",
"org.scalatest" %% "scalatest" % "3.2.15" % Test
),
// 仓库设置
resolvers ++= Seq(
"Apache Repository" at "https://repository.apache.org/content/repositories/releases/",
"Maven Central" at "https://repo1.maven.org/maven2/",
"Cloudera Repository" at "https://repository.cloudera.com/artifactory/cloudera-repos/"
)
如果需要 Assembly 插件来创建 fat JAR,在 project/plugins.sbt 中添加:
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "1.2.0")
然后再build.sbt中添加Assembly 插件配置
// 打包设置
assembly / assemblyJarName := s"${name.value}-${version.value}.jar",
assembly / assemblyMergeStrategy := {
case PathList("META-INF", xs @ _*) => MergeStrategy.discard
case x => MergeStrategy.first
},
// 并行执行设置
Test / parallelExecution := false,
// 内存设置
run / fork := true,
run / javaOptions ++= Seq(
"-Xms512M",
"-Xmx2G",
"-XX:MaxPermSize=512M"
)
打包命令
sbt assembly
# 跳过测试
sbt "set test in assembly := {}" assembly
下面是 Assembly 插件相关配置
// Assembly 配置
ThisBuild / assemblyMergeStrategy := {
case PathList("META-INF", "services", xs @ _*) => MergeStrategy.filterDistinctLines
case PathList("META-INF", xs @ _*) => MergeStrategy.discard
case "application.conf" => MergeStrategy.concat
case "reference.conf" => MergeStrategy.concat
case "module-info.class" => MergeStrategy.discard
case x => MergeStrategy.first
}
assembly / assemblyJarName := s"${name.value}-${version.value}-assembly.jar"
assembly / assemblyExcludedJars := {
val cp = (assembly / fullClasspath).value
cp filter {_.data.getName.contains("slf4j-api")}
}
// 可选:跳过测试
assembly / test := {}
如果遇到重复类错误,可以排除特定依赖:
libraryDependencies += "some.library" % "name" % "version" excludeAll(
ExclusionRule(organization = "org.slf4j"),
ExclusionRule(organization = "log4j")
)
Maven + Java + Scala 混编
在 Maven 项目中配置 Scala 编译和打包,需要在 pom.xml 文件中添加 Scala 插件(如 scala-maven-plugin)和 Scala 依赖,并创建相应的源码目录。通过这种方式,Maven 就能自动识别和编译 Scala 代码,并将其打包成可执行 JAR 文件。
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.13.0</version> <!-- 根据你的项目需求选择版本 -->
</dependency>
</dependencies>
配置maven的scala插件
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven.plugins</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.5.1</version> <!-- 根据你的项目需求选择版本 -->
<executions>
<execution>
<id>compile</id>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>test-compile</id>
<phase>test-compile</phase>
<goals>
<goal>test-compile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
创建 Scala 源码目录:在 src/main/scala 目录下创建 Scala 代码文件。如果该目录不存在,需要手动创建。
搭建Spark环境
https://spark.apache.org/docs/latest/cluster-overview.html
Standalone
Standalone模式是Spark自带的资源调动引擎,构建一个由Master + Slave构成的Spark集群,Spark运行在集群中。这个要和Hadoop中的Standalone区别开来。这里的Standalone是指只用Spark来搭建一个集群,不需要借助其他的框架。是相对于Yarn和Mesos来说的。
Master和Worker是Spark的守护进程,即Spark在特定模式下正常运行所必须的进程。Driver和Executor是临时程序,当有具体任务提交到Spark集群才会开启的程序。
Spark on Yarn
参考:https://spark.apache.org/docs/latest/running-on-yarn.html
需提前安装好hadoop,下载:https://archive.apache.org/dist/hadoop/common/
配置Yarn地址
关于yarn的一些配置信息都是在安装hadoop的时候自带,如果想利用yarn来启动spark,需要告知spark关于yarn的配置信息
打开%SPARK_HOME%/conf/目录,刚开始该目录下只有一些.template结尾的文件,这些文件是表示一些配置模板,可以在这些文件的基础上进行配置。
fairscheduler.xml.template
log4j2.properties.template
metrics.properties.template
spark-defaults.conf.template
spark-env.sh.template
workers.template
我们要修改的是spark-env.sh.template文件,事实上spark-env.sh.template文件全部都是注释。将spark-env.sh.template复制一份,改名为spark-env.sh。(注意:如果在Windows上操作,需要改为spark-env.cmd文件,同时要将该文件的语法改为cmd文件的语法,将行首的#!/usr/bin/env bash改为@echo off,以及将shell脚本中的注释语法#使用cmd中@rem进行替代)
添加一行,注意将HADOOP_HOME替换为实际的路径
YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
如果是Windows上
SET YARN_CONF_DIR=%HADOOP_HOME%/etc/hadoop
添加配置后,启动HDFS及YARN集群
下面提交一个示例程序
# 切换到SPARK_HOME目录下
# cd %SPARK_HOME%
# 具体执行的jar包名称以自己下载的spark版本为准
./bin/spark-submit.cmd --class org.apache.spark.examples.SparkPi --master yarn .\examples\jars\spark-examples_2.13-3.3.4.jar
正常情况下会如下图所示:
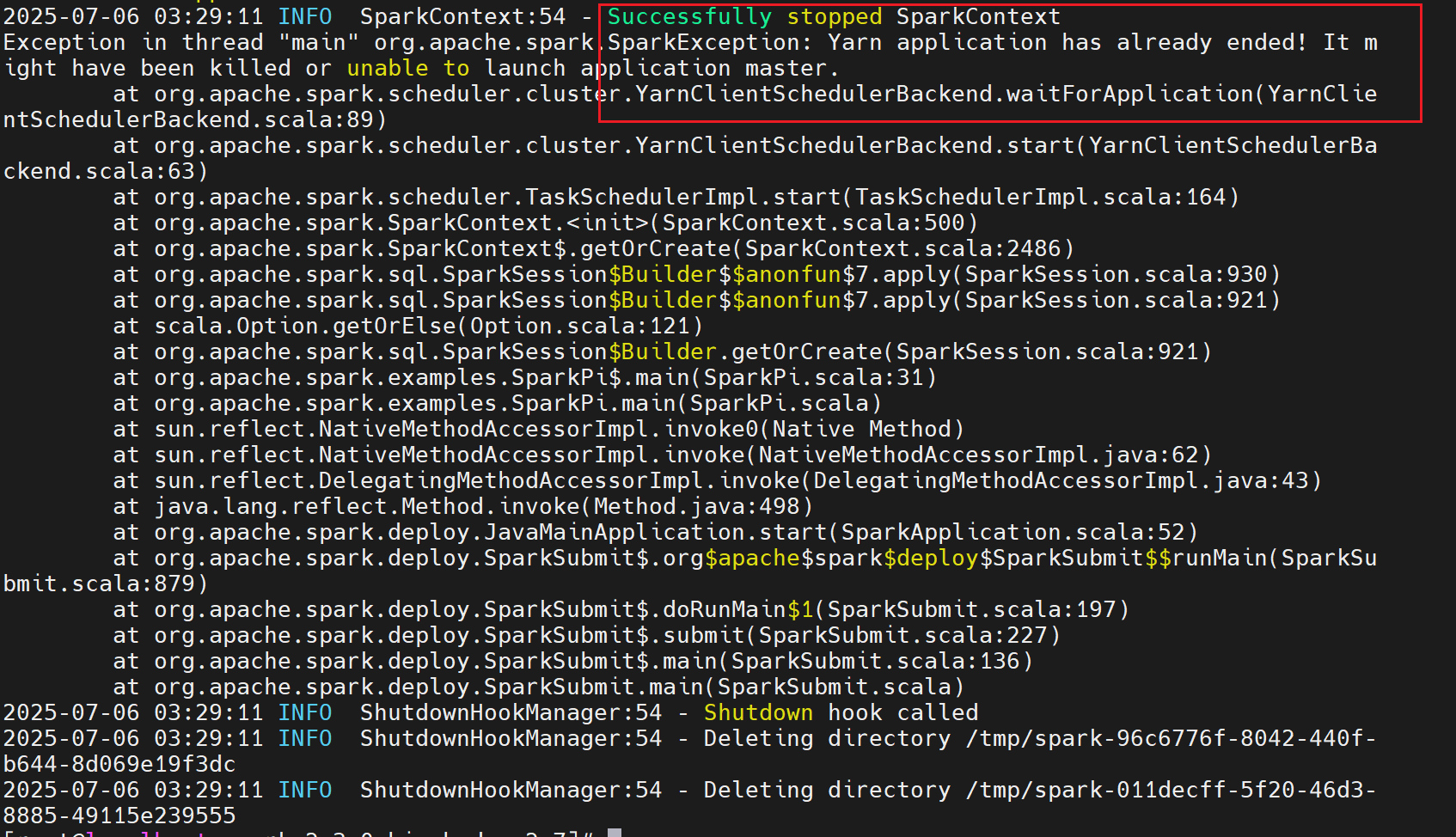
如果已经添加了set YARN_CONF_DIR=xxx还是报下面的错,可以直接将YARN_CONF_DIR配置在系统环境变量
➜ ./bin/spark-submit.cmd --class org.apache.spark.examples.SparkPi --master yarn .\examples\jars\spark-examples_2.13-3.3.4.jar
Exception in thread "main" java.lang.Exception: When running with master 'yarn' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.
at org.apache.spark.deploy.SparkSubmitArguments.validateSubmitArguments(SparkSubmitArguments.scala:286)
......
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Client/Cluster模式
添加--deploy-mode参数指定部署模式:有client和cluseter两种
# 不指定--deploy-mode参数时,默认就是client
./bin/spark-submit.cmd --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client .\examples\jars\spark-examples_2.13-3.3.4.jar
# cluster模式
./bin/spark-submit.cmd --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster .\examples\jars\spark-examples_2.13-3.3.4.jar
观察2种模式的JPS进程情况
Spark有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点
yarn-client: Driver程序运行在客户端,适用于交互,调试
Client模式
在 Client 模式下,Spark Driver 运行在提交任务的客户端节点上(即运行 spark-submit 命令的机器)。Driver 负责执行应用程序的调度和监控,而 Executor 则在集群的工作节点上启动和运行任务。
在 Client 模式中,机器的 CPU 负担主要集中在 Driver 进程上,因为 Driver 负责调度和监控整个应用程序的运行。Client 模式适用于开发、调试和交互式操作,对于小型数据集和快速迭代的任务有效,希望立即看到app的输出
Cluster模式
在 Cluster 模式下,Spark Driver 运行在集群中的某个由 ResourceManager 启动的 APPMaster节点上,并且与其他 Executor 并行运行。客户端只负责提交应用程序,并不参与应用程序的实际运行。
在 Cluster 模式中,机器的 CPU 负担在整个集群中分布,因为 Driver 和 Executor 都在各自的节点上运行。
Cluster 模式适用于生产环境,用于处理大规模数据集和长时间运行的任务。
总体而言,Client 模式下对机器的 CPU 影响较大,因为 Driver 运行在客户端节点上,而 Cluster 模式下对机器的 CPU 影响相对均匀,因为任务在整个集群中运行。在选择提交模式时,需考虑任务的规模、数据量和计算资源情况,以及是否需要实时监控和交互式操作等因素
Spark Web UI
https://spark.apache.org/docs/latest/web-ui.html
Spark UI是反映一个Spark作业执行情况的web页面,用户可以通过Spark UI观察Spark作业的执行状态,分析可能存在的问题
当一个Spark Application运行起来后,可以通过访问hostname:4040端口来访问UI界面。hostname是提交任务的Spark客户端ip地址,端口号由参数spark.ui.port(默认值4040,如果被占用则顺序往后探查)来确定。由于启动一个Application就会生成一个对应的UI界面,所以如果启动时默认的4040端口号被占用,则尝试4041端口,如果还是被占用则尝试4042,一直找到一个可用端口号为止。
如下图所示,启动过程中会打印出tracking URL,如果访问有问题可以将域名改为ip试试
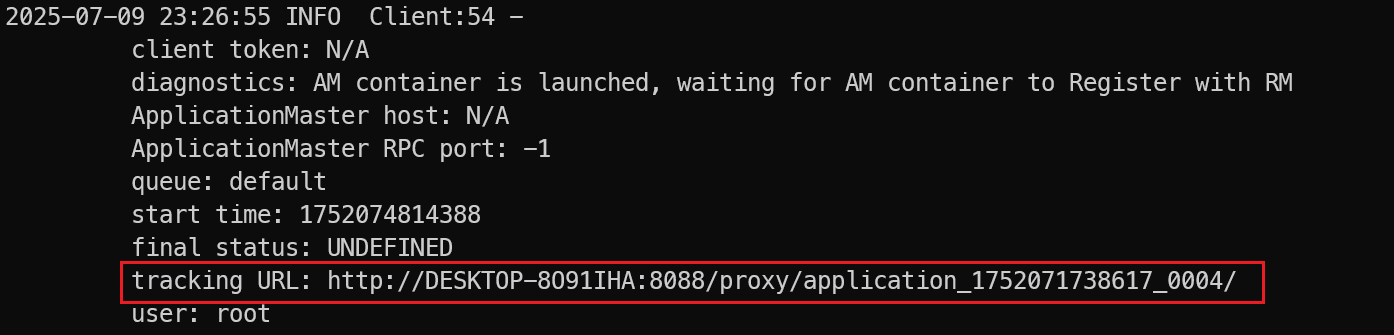
如果Spark Application运行完后,这个界面就不可访问了
配置历史服务
默认情况下,Spark程序运行完毕关闭窗口之后,就无法再查看运行记录的Web UI(4040)了,但通过 HistoryServer 可以提供一个服务, 通过读取日志文件, 使得我们可以在程序运行结束后, 依然能够查看运行过程。有助于理解应用程序的执行流程、识别性能瓶颈并解决问题。
参考:https://spark.apache.org/docs/latest/monitoring.html#viewing-after-the-fact
事件日志配置
每个 Spark 应用的 Job 在运行过程中如果开启了事件日志记录功能,会将日志保存到文件,这个文件可以选择保存到本地文件系统或者HDFS上。Spark Web UI 支持读取这些日志文件,并通过 UI 界面进行展示
- 修改Spark的配置文件
mv spark-defaults.conf.template spark-defaults.conf
vi spark-defaults.conf
cd %SPARK_HOME%/conf
添加下面2行配置
# 开启记录事件日志
spark.eventLog.enabled true
# 指定事件日志存放的位置,这里需要替换实际的IP端口: 例如hdfs://localhost:9870/spark-logs
# 默认: file:///tmp/spark-events
spark.eventLog.dir hdfs://${namenode}/spark-logs
# 是否压缩事件日志
spark.eventLog.compress true
# 详细配置参考:https://spark.apache.org/docs/latest/configuration.html#spark-ui
其中spark.eventLog.dir可以不配置,默认是存放在本地文件系统/tmp/spark-events目录下
如果配置为HDFS路径,则需要提前先在Hadoop上创建用于存放Spark日志的存储路径
hadoop fs -mkdir /spark-logs
如果运行在yarn模式下,还需要在spark-defaults.conf添加yarn相关的配置
spark.yarn.historyServer.address=192.168.58.130:18080
spark.history.ui.port=18080
spark.history.fs.logDirectory=hdfs://192.168.58.130:8020/spark-logs
spark.eventLog.dir和spark.history.fs.logDirectory的区别:
spark.eventLog.dir是指定应用日志写入保存的位置,而spark.history.fs.logDirectory是指定Spark Web UI从哪里读取日志
修改 spark-env.sh 文件, 添加日志配置
在配置文件中配置了历史服务器的参数,在此处可以不配置
# spark.history.ui.port: WEB UI 访问的端口号为 18080
# spark.history.fs.logDirectory: 指定历史服务器日志存储路径
# spark.history.retainedApplications: 指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序
# 信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://192.168.58.130:8020/spark_logs
-Dspark.history.retainedApplications=30"
启动历史服务
如果在Linux上使用,只需要执行Spark安装目录下../sbin/start-history-server.sh这个脚本即可
如果在Windows上使用Spark,因为Spark安装包中sbin目录下只有sh脚本,没有对应的cmd脚本,可以通过以下方式启动
cd $SPARK_HOME
java -cp ./jars/* org.apache.spark.deploy.history.HistoryServer
# 或者通过spark-class.cmd这个脚本来执行,这个脚本是Spark自带的
bin\spark-class.cmd org.apache.spark.deploy.history.HistoryServer
读取日志文件的路径可以通过spark-defaults.conf中配置,或者通过命令行参数传入
# 也可以指定HDFS路径
spark.history.fs.logDirectory file:///c:/logs/dir/path
现在提交一个应用来测试是否可以看到历史日志
spark-submit \
--master yarn \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
$SPARK_HOME/examples/jars/spark-examples_2.13-3.3.1.jar \
1000
查看历史服务:http://localhost:18080/
问题记录
- 运行示例代码时报错java.lang.NoSuchMethodError: scala.Predef$.refArrayOps
可能是使用的Scala版本不对,使用的Spark是2.3.0,使用的Scala版本应该是2.11.x版本
-
????????????? org.apache.spark.deploy.yarn.ExecutorLauncher
Spark-submit错误信息乱码,导致这个错误信息看不出来什么原因,也不方便搜索
每个Container都会有自己的日志,根据Container的ID找到存在本地磁盘上的日志文件stderr,用文本编辑器打开调整下编码就可以看到不乱码的错误信息了
从文件中可以看到错误信息是: 找不到或无法加载主类org.apache.spark.deploy.yarn.ExecutorLauncher,这个可以推断出是由于jar包缺失导致报错
最常见的原因是 spark-defaults.conf 中 spark.yarn.jars 配置不对,或者必要的 Spark JAR 文件没有上传到 HDFS,导致执行器启动时 classpath 缺失. 解决办法是 确保 Spark 核心 JAR 和其他依赖 JAR 存在于 HDFS 上的指定位置,并在 spark-defaults.conf 中正确配置 spark.yarn.jars 指向这些 JAR 的路径,例如 hdfs://
解决办法如下:
(1)上传本地 Spark 安装目录下的 jars 文件夹(例如 /usr/local/spark/jars/)的这些 JAR 文件上传到 HDFS 上一个指定的目录(例如 hdfs://master:9000/user/hadoop/jars/).
hadoop fs -mkdir -p /spark/jars
hdfs dfs -put /usr/local/spark/jars/*.jar /spark/jars/
然后编辑 Spark 配置文件 conf/spark-defaults.conf。添加或修改 spark.yarn.jars 属性,指向你在 HDFS 上的 JAR 目录.配置内容:spark.yarn.jars hdfs://
- Container exited with a non-zero exit code 13. Error file: prelaunch.err.
- 查看yarn日志:yarn logs -applicationId application_1753803383891_0002
https://blog.csdn.net/appleyuchi/article/details/105846962
报错可能是因为spark-submit中指定的集群模式和工程文件中的设定master的语句冲突,修改如下:
SparkSessionspark = SparkSession.builder.appName("AppName").getOrCreate();
- 启动历史服务时报错:RPC response exceeds maximum data length
25/09/30 22:16:53 INFO HistoryServer: Bound HistoryServer to 0.0.0.0, and started at http://DESKTOP-8O91IHA:18080
Exception in thread "main" org.apache.hadoop.ipc.RpcException: RPC response exceeds maximum data length
at org.apache.hadoop.ipc.Client$IpcStreams.readResponse(Client.java:1936)
at org.apache.hadoop.ipc.Client$Connection.receiveRpcResponse(Client.java:1238)
at org.apache.hadoop.ipc.Client$Connection.run(Client.java:1134)
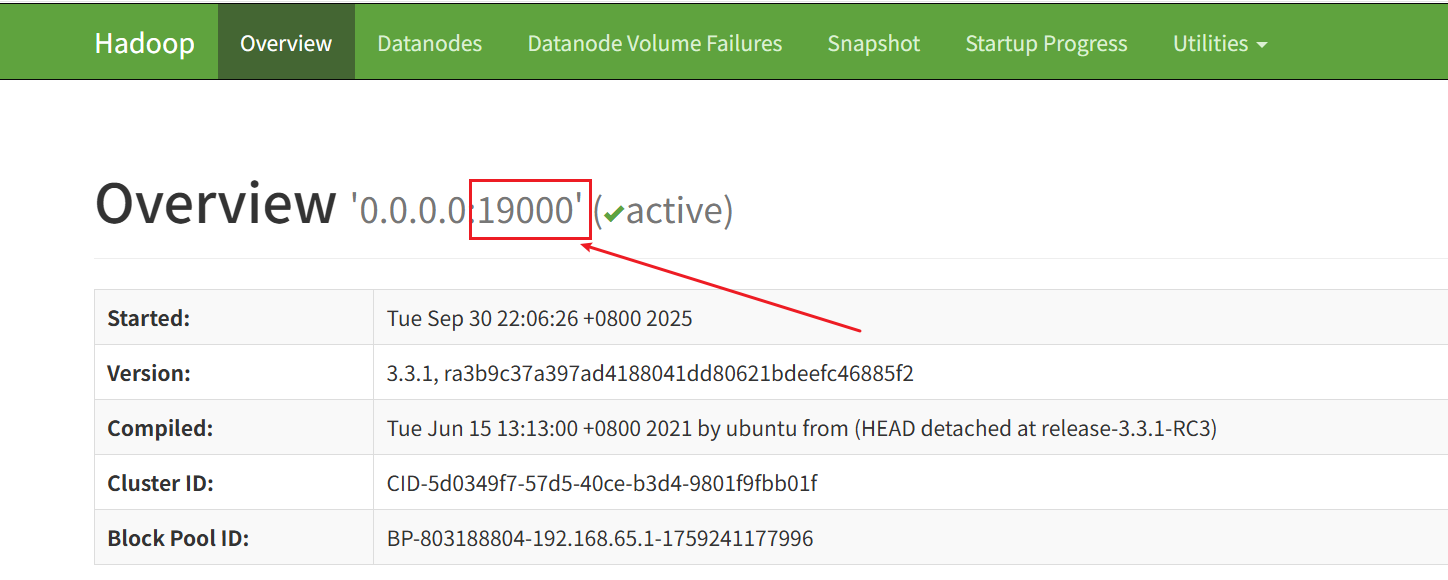
可能是spark.eventLog.dir和spark.history.fs.logDirectory端口配置错误
访问http://localhost:9870/dfshealth.html#tab-overview,下图的这里显示的端口进行配置即可
spark.eventLog.dir hdfs://localhost:19000/spark-logs
spark.history.fs.logDirectory=hdfs://localhost:19000/spark-logs
- 使用无法连接上 RM
26/01/08 00:47:05 INFO DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /0.0.0.0:8032
26/01/08 00:51:00 INFO Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 8 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
26/01/08 00:51:01 INFO Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 9 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
26/01/08 00:51:01 INFO RetryInvocationHandler: java.net.ConnectException: Your endpoint configuration is wrong; For more details see: http://wiki.apache.org/hadoop/UnsetHostnameOrPort, while invoking ApplicationClientProtocolPBClientImpl.getNewApplication over null after 6 failover attempts. Trying to failover after sleeping for 33643ms.
参考:https://cwiki.apache.org/confluence/display/HADOOP2/UnsetHostnameOrPort
- Cluster deploy mode is not compatible with master "local"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号