Hadoop安装与部署
本文记录在Windows下搭建Hadoop 3.3.1环境
下载安装Hadoop
所有版本的下载地址:https://archive.apache.org/dist/hadoop/common/ ,本文使用 hadoop 3.3.1版本
安装Hadoop native IO binary
Linux版本的Hadoop中Native IO支持是可选的,但是Windows版本是必须的,没有的话,Windows Native IO库并未包含在Apache
Hadoop发行版中。因此,我们需要构建并安装它。
下面的Github仓库包含了构建好的 Hadoop Windows Native 库文件:
https://github.com/ruslanmv/How-to-install-Hadoop-on-Windows/tree/master/winutils/hadoop-3.3.1/bin
注意:这些库没有签名,不能保证它是100%安全的,仅适合将其用于测试和学习目的
下载以下位置的所有文件,并将其保存到Hadoop文件夹下的bin文件夹中。
git clone https://github.com/ruslanmv/How-to-install-Hadoop-on-Windows.git
然后复制bin目录下的所有文件到%HADOOP_HOME%/bin目录下,如果有同名文件,可以直接覆盖,但是要确保使用的是正确的版本
cd How-to-install-Hadoop-on-Windows\winutils\hadoop-3.3.1\bin
copy *.* C:\Hadoop\hadoop-3.3.1\bin
配置及启动Hadoop
涉及Hadoop核心配置、YARN、MapReduce、HDFS 配置。
%HADOOP_HOME%\etc\hadoop\core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:19000</value>
</property>
</configuration>
创建目录
mkdir %HADOOP_HOME%\data\datanode
mkdir %HADOOP_HOME%\data\namenode
编辑%HADOOP_HOME%\etc\hadoop\hdfs-site.xml,注意需要替换%HADOOP_HOME%为你的实际路径
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>%HADOOP_HOME%/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>%HADOOP_HOME%/data/datanode</value>
</property>
</configuration>
配置MapReduce
编辑:%HADOOP_HOME%\etc\hadoop\mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>%HADOOP_HOME%/share/hadoop/mapreduce/*,%HADOOP_HOME%/share/hadoop/mapreduce/lib/*,%HADOOP_HOME%/share/hadoop/common/*,%HADOOP_HOME%/share/hadoop/common/lib/*,%HADOOP_HOME%/share/hadoop/yarn/*,%HADOOP_HOME%/share/hadoop/yarn/lib/*,%HADOOP_HOME%/share/hadoop/hdfs/*,%HADOOP_HOME%/share/hadoop/hdfs/lib/*</value>
</property>
</configuration>
编辑%HADOOP_HOME%\etc\hadoop\yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
注意
Hadoop会使用默认的JDK的JAVA_HOME变量指向的JDK,如果你装了其他版本的JDK,可以在每个控制台会话临时修改 JAVA_HOME 环境变量,或者在
%HADOOP_HOME%/etc/hadoop/hadoop-env.cmd文件中临时设置 JAVA_HOME 环境变量
启动 HDFS
执行命令hdfs namenode -format初始化HDFS
启动HDFS: %HADOOP_HOME%\sbin\start-dfs.cmd,访问:http://localhost:9870/dfshealth.html#tab-overview.
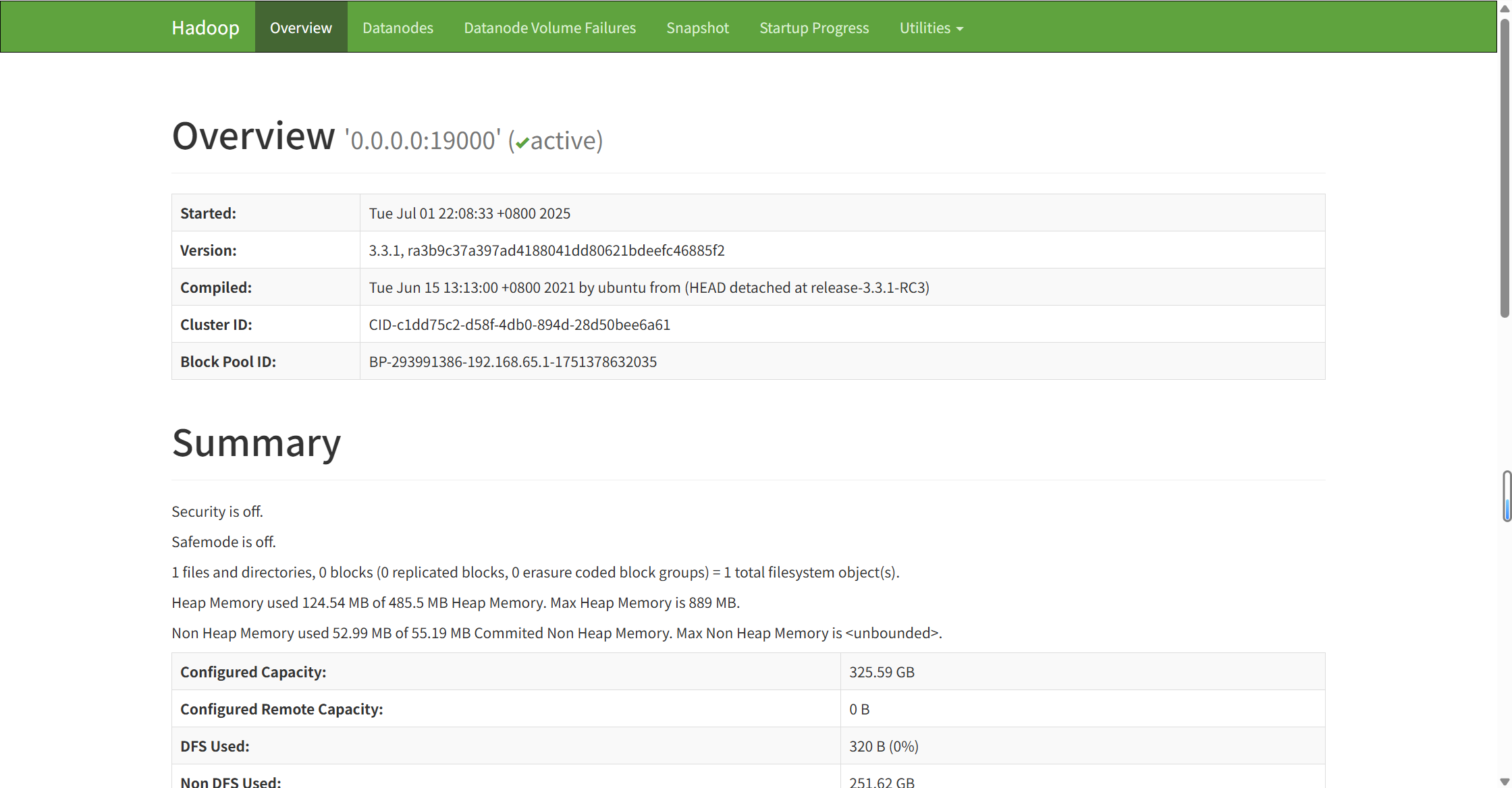
启动 Yarn
启动Yarn:%HADOOP_HOME%\sbin\start-yarn.cmd
yarn和前端的yarn工具命名冲突,如果你安装了前端的yarn,则需要修改%HADOOP_HOME%\sbin\start-yarn.cmd文件,使用绝对路径来执行 yarn 相关命令:
@rem start resourceManager
start "Apache Hadoop Distribution" %HADOOP_HOME%/bin/yarn.cmd resourcemanager
@rem start nodeManager
start "Apache Hadoop Distribution" %HADOOP_HOME%/bin/yarn.cmd nodemanager
@rem start proxyserver
@rem start "Apache Hadoop Distribution" yarn proxyserver
验证启动结果
一次性启动HDFS NameNode, DataNode和Yarn(ResourceManager 和 NodeManager):%HADOOP_HOME%/sbin/start-all.cmd。
此时通过jps可以看到这些进程
➜ jps
21008 NameNode
3168 DataNode
25740 NodeManager
29436 ResourceManager
# 查找指定PID监听的TCP端口
> netstat -ano | findstr "21008" | findstr "LISTENING"
TCP 0.0.0.0:9870 0.0.0.0:0 LISTENING 21008
TCP 127.0.0.1:19000 0.0.0.0:0 LISTENING 21008
Hadoop端口配置
常用端口号和配置文件
Hadoop 3.X
- HDFS NameNode 内部通信端口:8020/9000/9820
- HDFS NameNode HTTP UI:9870
- HDFS DataNode HTTP UI:9864
- Yarn 查看任务执行端口:8088
- 历史服务器通信端口:19888
Hadoop 2.X
HDFS NameNode 内部通信端口:8020/9000
HDFS NameNode HTTP UI:50070
HDFS DataNode HTTP UI:50075
Yarn 查看任务执行端口:8088
历史服务器通信端口:19888
| Hadoop2.x | Hadoop3.x | |
|---|---|---|
| HDFS NameNode内部通信端口 | 8020/9000 | 8002/9000/9820 |
| HDFS NameNode Http UI | 50070 | 9870 |
| HDFS DataNode Http UI | 50075 | 9864 |
| MapReduce查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
配置文件
-
Hadoop 3.X
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
workers -
Hadoop 2.X
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
常见配置
fs.default.name / fs.defaultFS
https://www.cnblogs.com/lishiqi-blog/p/12410373.html
设置默认的文件系统实现和其URI,fs.default.name 不是一个端口号,而是Hadoop文件系统中用于指定HDFS(Hadoop分布式文件系统)NameNode的地址的配置参数,通常格式为hdfs://<name_node_host>:<name_node_port>,例如hdfs://namenode_host:8020或hdfs://namenode_host:9000。这个参数用于告知Hadoop客户端,文件系统(FS)的默认命名服务在哪里,从而使客户端能够连接到NameNode并访问HDFS中的数据和元数据。
在core-site.xml 里配置:
<property>
<name>fs.default.name</name>
<value>hdfs://host:port</value>
</property>
NameNode端口可能是8020或9000,是NameNode监听客户端请求的实际端口,客户端通过这个端口与NameNode进行通信,以读取或写入数据。
fs.default.name已被废弃,由fs.defaultFS替代
参考:https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/DeprecatedProperties.html
https://www.cnblogs.com/lishiqi-blog/p/12410373.html
问题记录
ssh: Could not resolve hostname java_home: Name or service not known
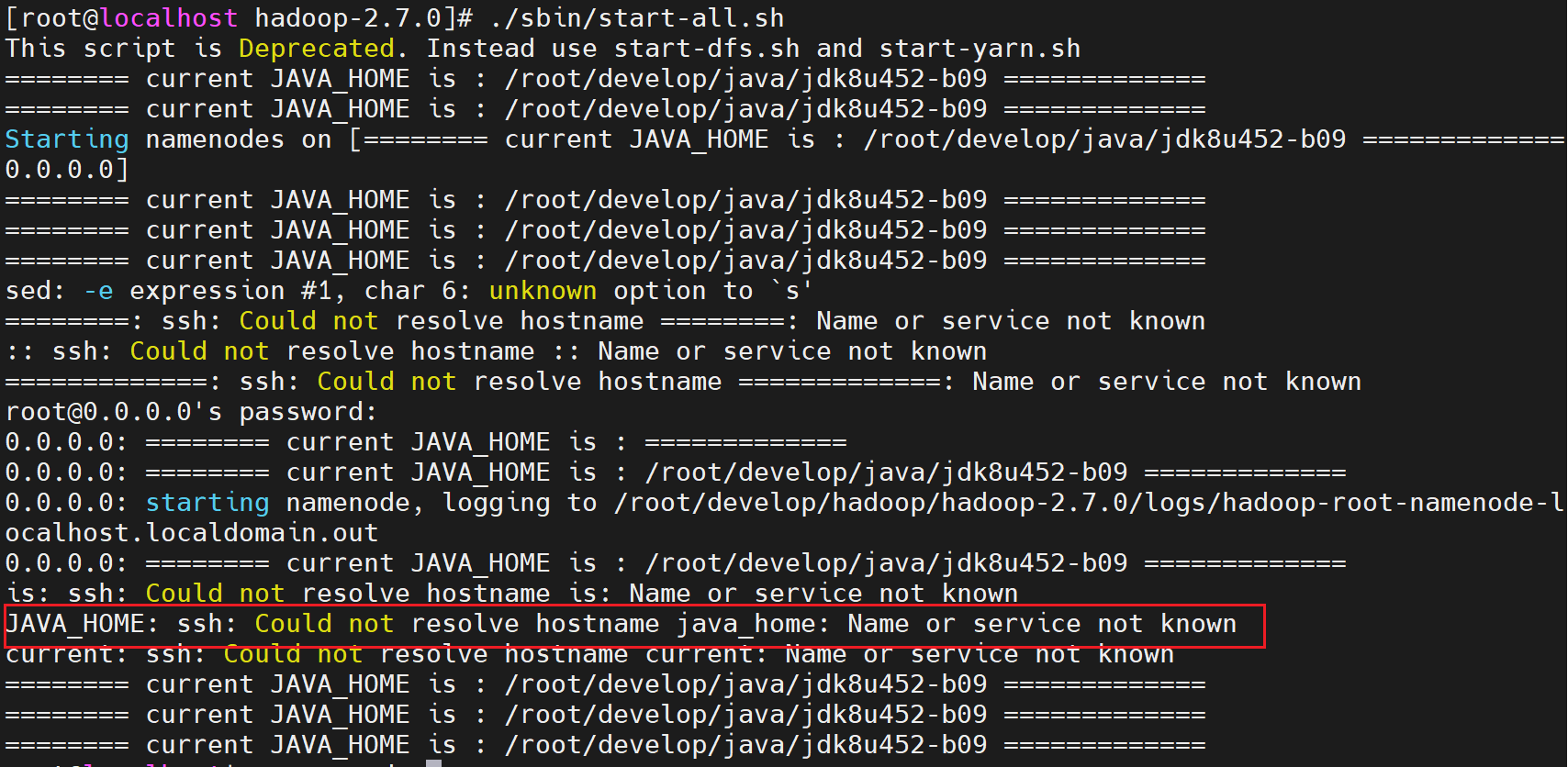
https://github.com/judasn/Linux-Tutorial/blob/master/markdown-file/Hadoop-Install-And-Settings.md
systemctl stop firewalld.service
hadoop-env.sh 脚本中如果在开始添加echo命令,可能会执行start-all.sh时报错,windows版本不会这样,linux上使用了sed命令来截取hostname
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
修改$HADOOP_HOME/etc/hadoop/hadoop-env.sh文件,添加
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
ERROR: JAVA_HOME is not set and could not be found.
执行$HADOOP_HOME/sbin/start-all.sh时报错
[root@localhost hadoop-3.3.0]# sudo ./sbin/start-all.sh
ERROR: JAVA_HOME is not set and could not be found.
修改hadoop-env.sh,设置JAVA_HOME环境变量
Address already in use: bind;
java.net.BindException: Problem binding to [0.0.0.0:9864] java.net.BindException: Address already in use: bind; For more details see: http://wiki.apache.org/hadoop/BindException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
参考:https://stackoverflow.com/questions/19082735/hadoop-java-net-bindexception-address-already-in-use
解决方案:
- 可能是关闭Hadoop时有进程没有关闭,通过命令进行关闭:
.\sbin\stop-all.cmd - 查找具体的端口占用情况
# 查找使用特定端口的连接(例如8080)
netstat -an | findstr ":9864"
# 查找特定端口并显示进程名
netstat -ano | findstr ":9864"
# 查找多个端口
netstat -an | findstr ":80 :443 :9864"
Encountered exception loading fsimage java.io.IOException: NameNode is not formatted.
WARN namenode.FSNamesystem: Encountered exception loading fsimage
java.io.IOException: NameNode is not formatted.
hadoop集群创建完成之后 namenode没有进行初始化
- 先关闭hadoop集群:/sbin/stop-all.sh,或者直接关闭进程
- 初始化namenode:/bin/hdfs namenode -format
Permission denied
Linux下执行./sbin/start-all.sh脚本时报错没有权限
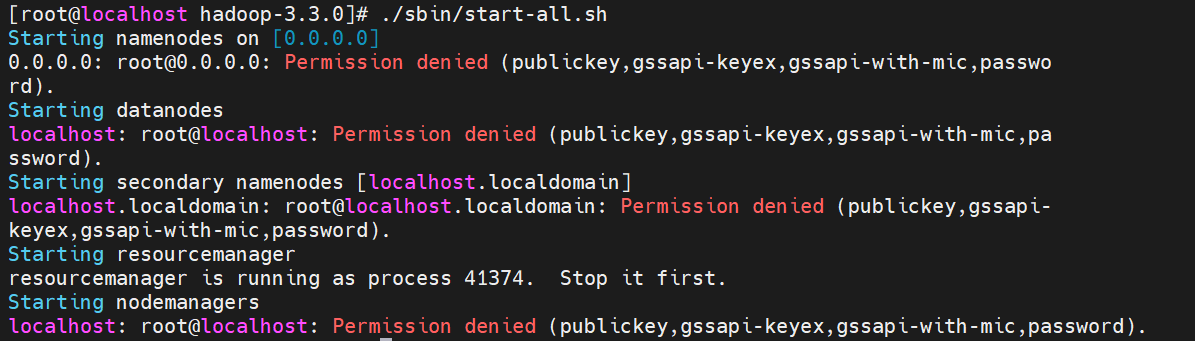
通常是因为SSH 密钥认证问题或文件权限不足。解决此问题,需要确保SSH 密钥对已正确配置,并且Hadoop 相关的目录和文件具有正确的权限。
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
#
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
添加后启动正常:

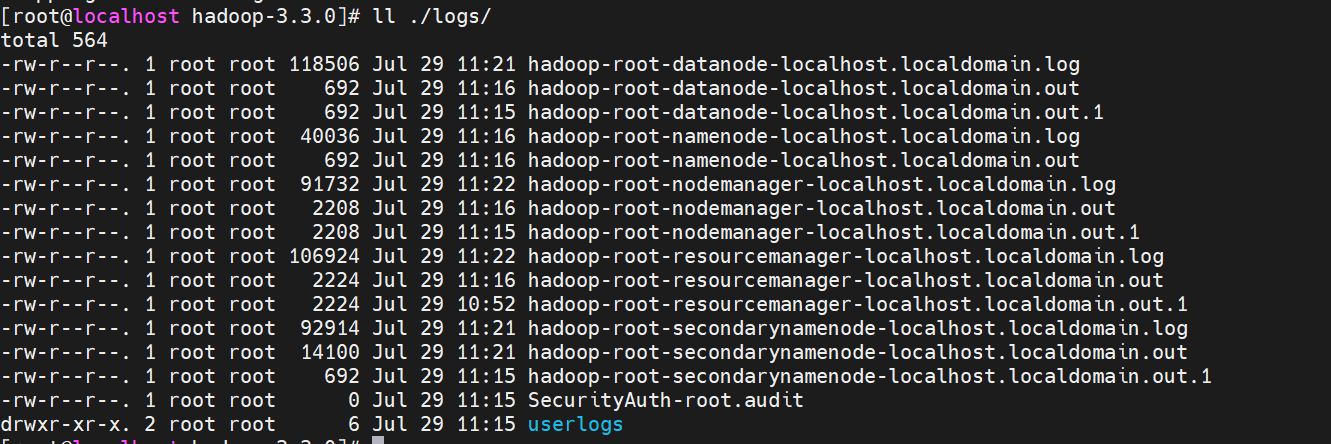
启动失败查看日志
查看启动日志,在$HADOOP_HOME/logs目录下存放了命令执行的日志
启动失败:WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: 0.0.0.0/0.0.0.0:19000
https://lists.apache.org/thread/287tccj3kjp4cp9ybpkf03f9876xxr0b
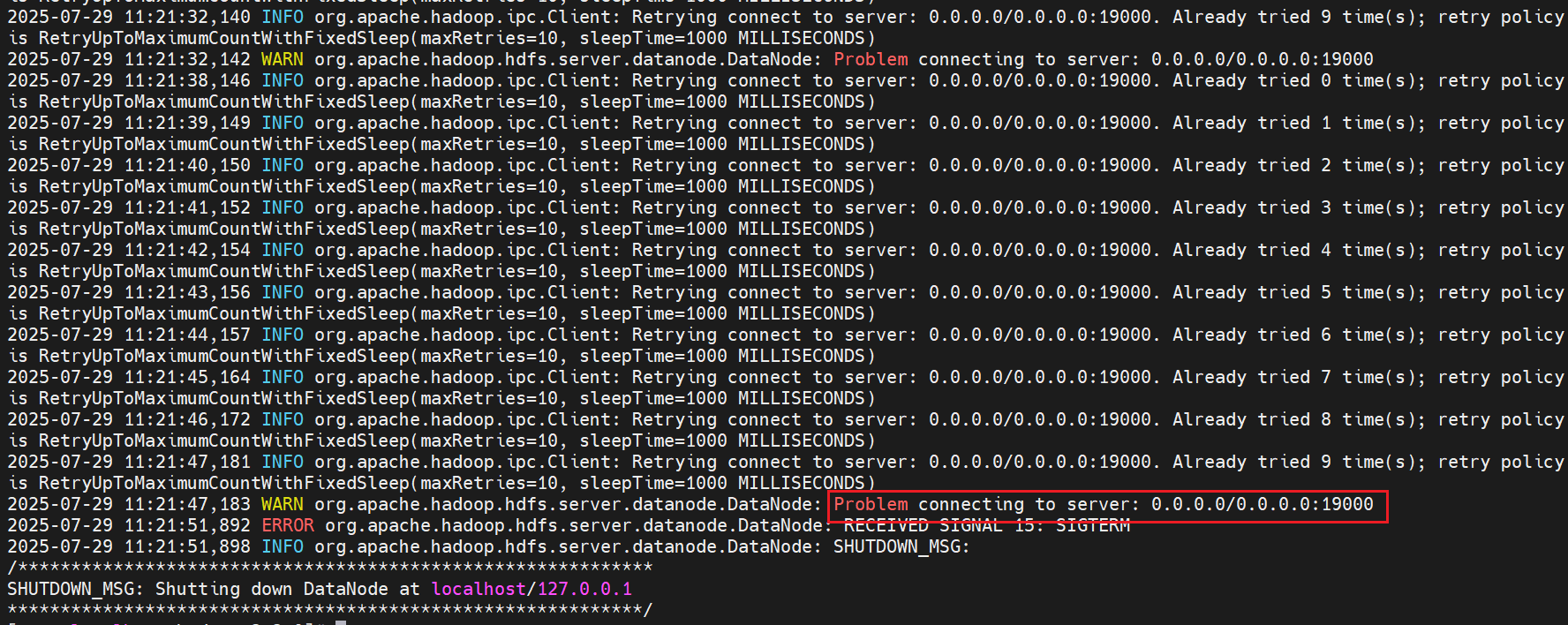
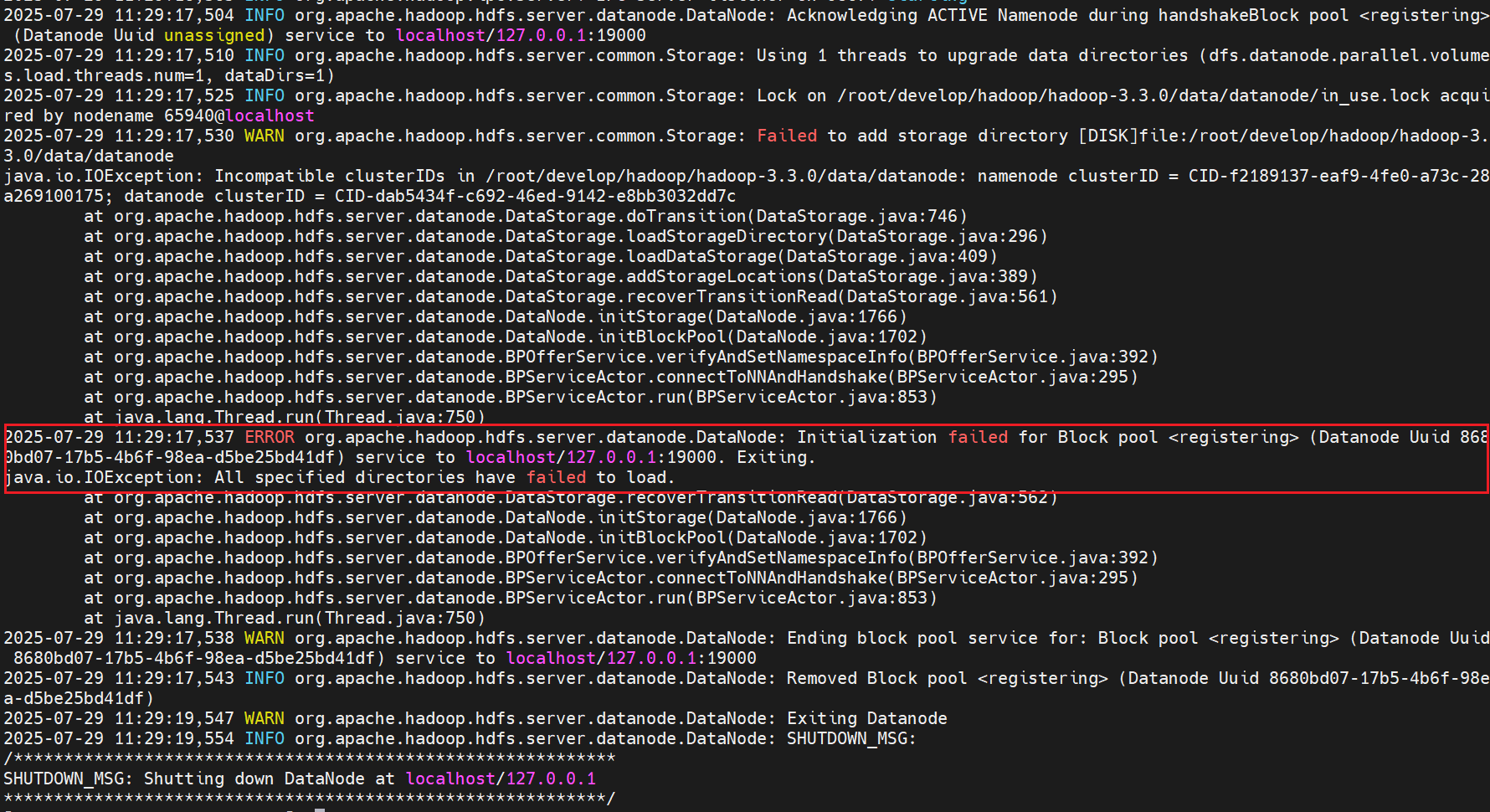
启动失败:Failed to add storage directory [DISK]file
在NameNode重新格式化之前,需要删除DataNode上的数据和log日志。不然会造成NameNode和DataNode的clusterID不一致的问题。会有以下报错信息:
本地浏览器无法访问虚拟机中Hadoop相关UI地址
https://blog.csdn.net/qq_45638264/article/details/111027363
关掉防火墙 :systemctl stop firewalld
去掉跟随系统启动:systemctl disable firewalld
HDFS上传文件时:Permission denied: user=dr.who, access=WRITE, inode="/":root:supergroup:drwxr-xr-x
https://hadoop.apache.org/docs/r1.0.4/cn/hdfs_permissions_guide.html
dr.who其实是hadoop中http访问的静态用户名,并没有啥特殊含义,可以在core-default.xml中看到其配置,hadoop.http.staticuser.user=dr.who
我们可以通过修改core-site.xml,配置为当前用户,
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
另外,通过查看hdfs的默认配置hdfs-default.xml发现hdfs默认是开启权限检查的。
dfs.permissions.enabled=true #是否在HDFS中开启权限检查,默认为true
由于当前用户权限不足,所以无法操作/目录。
解决方案有两种,一是直接修改/tmp目录的权限设置,操作如下:/bin/hdfs dfs -chmod -R 755 /,然后就可以正常访问/tmp目录下的文件了。
另一种是直接hdfs的权限配置,
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
第二种方案可以在测试环境下使用,生产环境不建议这样设置。
关闭安全模式:hadoop dfsadmin -safemode leave
RPC response exceeds maximum data length
出现 rpc response exceeds maximum data length 错误,通常是因为 RPC 响应的数据大小超过了系统配置的最大限制。
- 可能是最大数据长度限制设置的小了,可以适当增大此值
首先,通过namenode的日志查看具体是多少超出了最大长度
然后修改配置文件core-site.xml,增加 ipc.maximum.data.length 的值。例如,将默认的 64MB 增加到 256MB:
<property>
<!-- 允许的最大RPC消息长度(字节)。 -->
<name>ipc.maximum.data.length</name>
<value>268435456</value> <!-- 设置为256MB -->
</property>
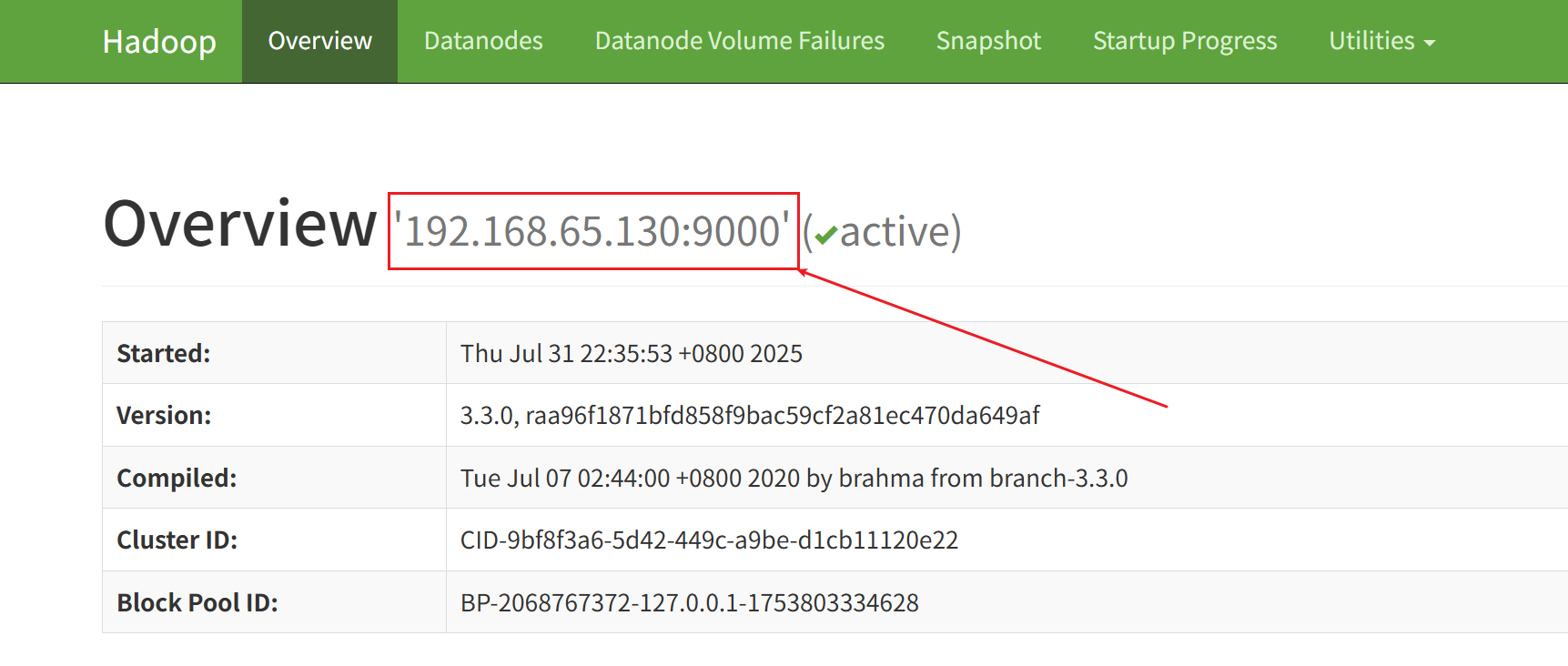
- HDFS文件地址可能写错了
地址可以直接根据下图方式确定:hdfs://192.168.65.130:9000/a/1.txt
![img]()
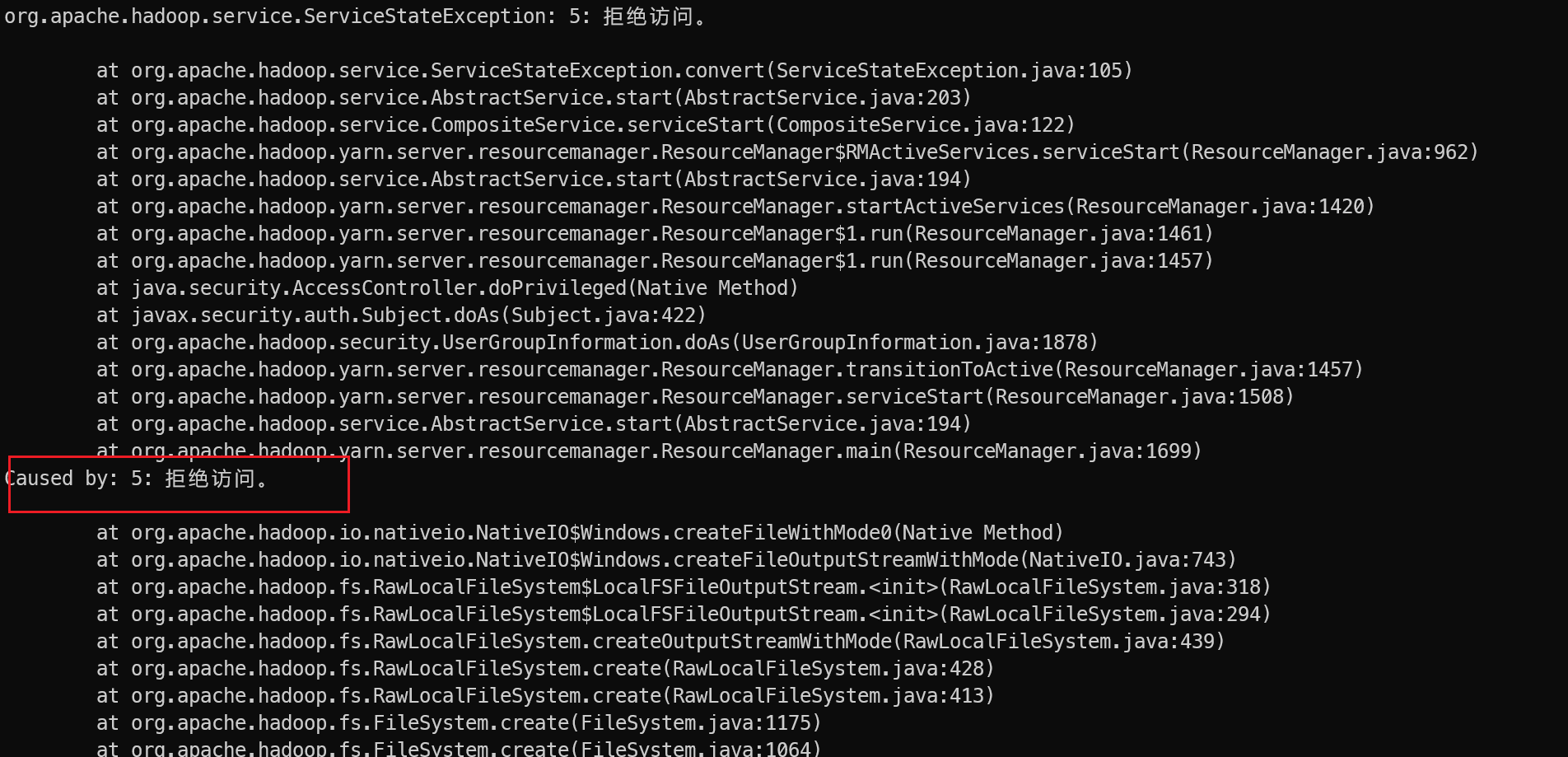
Error starting ResourceManager: 拒绝访问。
Windows上通过执行命令 ./sbin/start-all.cmd 启动Yarn和HDFS时,报错:Error starting ResourceManager
org.apache.hadoop.service.ServiceStateException: 5: 拒绝访问。
报错日志如下:
2025-09-30 21:24:09,100 INFO store.AbstractFSNodeStore: Created store directory :file:/tmp/hadoop-yarn-root/node-attribute
2025-09-30 21:24:09,128 INFO service.AbstractService: Service NodeAttributesManagerImpl failed in state STARTED
5: 拒绝访问。
at org.apache.hadoop.io.nativeio.NativeIO$Windows.createFileWithMode0(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$Windows.createFileOutputStreamWithMode(NativeIO.java:743)
at org.apache.hadoop.fs.RawLocalFileSystem$LocalFSFileOutputStream.<init>(RawLocalFileSystem.java:318)
at org.apache.hadoop.fs.RawLocalFileSystem$LocalFSFileOutputStream.<init>(RawLocalFileSystem.java:294)
at org.apache.hadoop.fs.RawLocalFileSystem.createOutputStreamWithMode(RawLocalFileSystem.java:439)
at org.apache.hadoop.fs.RawLocalFileSystem.create(RawLocalFileSystem.java:428)
at org.apache.hadoop.fs.RawLocalFileSystem.create(RawLocalFileSystem.java:413)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:1175)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:1064)
......
2025-09-30 21:24:09,132 INFO service.AbstractService: Service RMActiveServices failed in state STARTED
org.apache.hadoop.service.ServiceStateException: 5: 拒绝访问。
at org.apache.hadoop.service.ServiceStateException.convert(ServiceStateException.java:105)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:203)
at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:122)
......
Caused by: 5: 拒绝访问。
如下图所示:
执行jps查看进程,缺少了 ResourceManager
解决方案:可能是由于没有以管理员权限执行该命令,Windows上以管理员权限运行终端然后执行该命令即可
执行hdfs namenode -format时报错:java.lang.IllegalArgumentException: No class configured for D
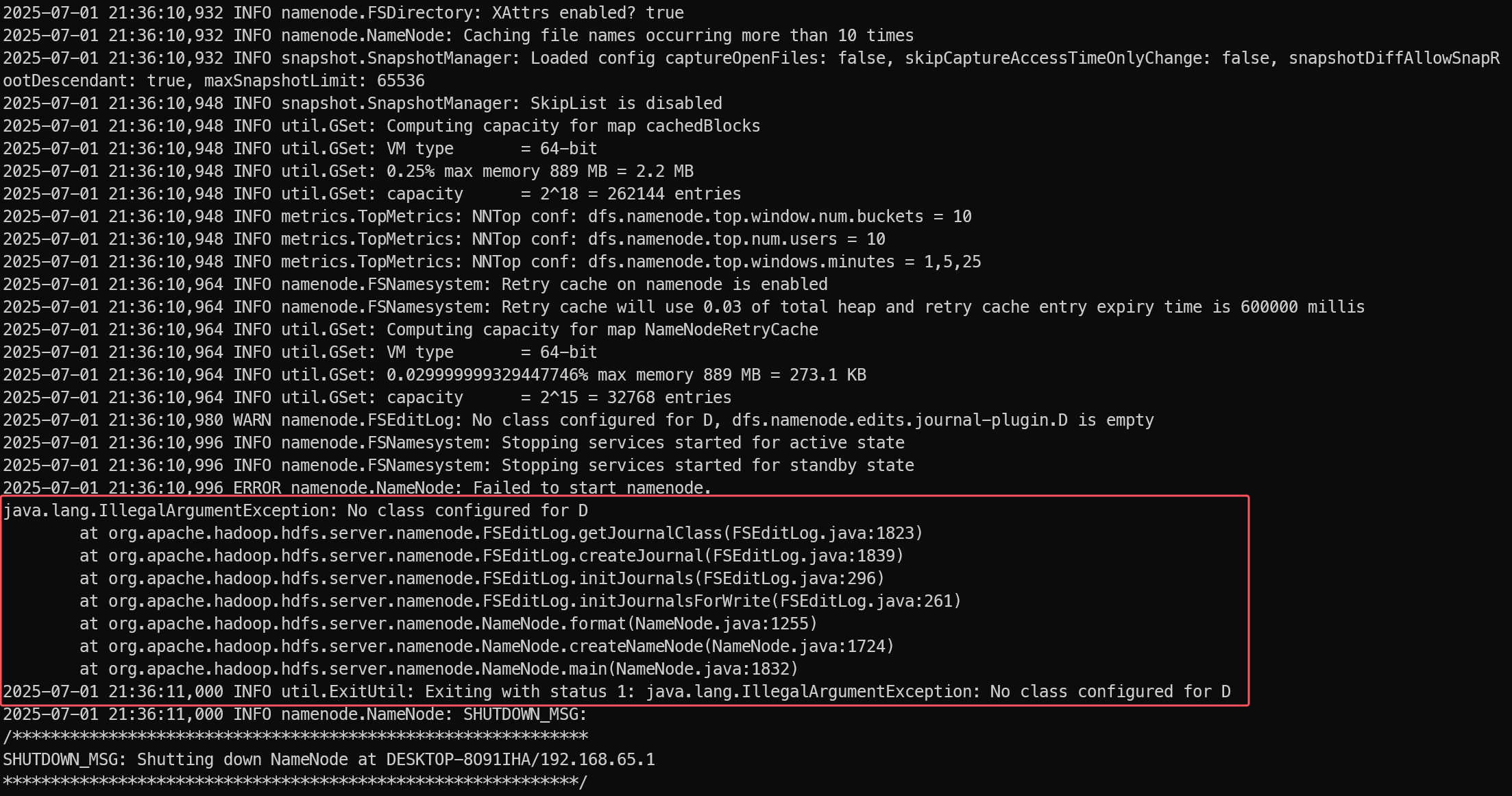
原因是配置 hdfs-site.xml 时路径包含了盘符,将盘符去掉即可
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<!-- 正确配置:<value>/xxx/xxx/xxx/hadoop-3.3.1/data/namenode</value> -->
<value>D:/xxx/xxx/xxx/hadoop-3.3.1/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>D:/xxx/xxx/xxx/hadoop-3.3.1/data/datanode</value>
</property>
</configuration>
重新格式化namenode后,出现java.io.IOException Incompatible clusterIDs
2025-09-30 22:02:06,217 INFO common.Storage: Lock on Hadoop安装目录\data\datanode\in_use.lock acquired by nodename 13732@DESKTOP-8O91IHA
2025-09-30 22:02:06,220 WARN common.Storage: Failed to add storage directory [DISK]file:/D:/Develop/Tools/BigData/hadoop-3.3.1/data/datanode
java.io.IOException: Incompatible clusterIDs in D:\Develop\Tools\BigData\hadoop-3.3.1\data\datanode: namenode clusterID = CID-29b714f5-8b6e-4a80-b26c-840d65bf3a25; datanode clusterID = CID-2713f9fc-7b36-42ad-b4b8-2e785463ffb5
at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:746)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadStorageDirectory(DataStorage.java:296)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadDataStorage(DataStorage.java:409)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:389)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:561)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1753)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1689)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:394)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:295)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:854)
at java.lang.Thread.run(Thread.java:750)
2025-09-30 22:02:06,223 ERROR datanode.DataNode: Initialization failed for Block pool
java.io.IOException: All specified directories have failed to load.
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:562)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1753)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1689)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:394)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:295)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:854)
at java.lang.Thread.run(Thread.java:750)
2025-09-30 22:02:06,225 WARN datanode.DataNode: Ending block pool service for: Block pool
2025-09-30 22:02:06,231 INFO datanode.DataNode: Removed Block pool
2025-09-30 22:02:08,233 WARN datanode.DataNode: Exiting Datanode
每次namenode format会重新创建一个namenodeId,而data目录包含了上次format时的id,namenode format清空了namenode下的数据,但是没有清空datanode下的数据,导致启动时失败,所要做的就是每次fotmat前,清空data下的所有目录.
解决办法:
方法1:停掉集群,删除问题节点的data目录下的所有内容。即hdfs-site.xml文件中配置的dfs.data.dir目录。重新格式化namenode。
方法2:先停掉集群,然后将datanode节点目录/dfs/data/current/VERSION中的修改为与namenode一致即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号