MagicWorld 实现长时交互视频世界建模
作者: vivo BlueImage Lab
MagicWorld 针对当前视频世界模型在长时间交互中易出现运动不合理与场景崩坏的问题,提出了一种面向长时稳定性的交互式建模框架。该方法通过引入基于光流的运动约束提升动态真实性,利用历史检索机制增强跨时间一致性,并通过多步聚合的训练策略优化整体交互序列质量,从而有效缓解误差累积问题。整体上,MagicWorld 实现了在长时间交互下更加稳定、一致的世界生成能力。
论文主页:MagicWorld: Towards Long-Horizon Stability for Interactive Video World Exploration
一、研究背景:解决视频世界模型的“长时漂移”问题
近年来,视频世界模型(Video World Model)逐渐成为生成式 AI 的一个重要方向。它的目标不再只是“生成一段视频”,而是学习视觉世界在用户动作条件下如何持续演化,从而支持交互式探索、场景预测和长期规划。
这类能力在自动驾驶、具身智能和虚拟世界构建等任务中都具有很高价值。但现有交互式视频世界模型虽然已经能够根据用户输入进行连续生成,仍然面临两个非常关键的问题。
第一个问题是 运动漂移(motion drift):在复杂动态场景中,行人、车辆等本应持续运动的目标,往往会出现静止、运动异常甚至逐渐退化的现象,导致生成结果缺乏真实感。
第二个问题是 长时不稳定(long-horizon instability):由于大多数方法采用自回归方式逐步生成,前一步的小误差会不断累积,最终造成场景结构扭曲、语义偏移以及长序列一致性崩坏。
针对这些问题,来自浙江大学和vivo蓝图实验室等机构的研究团队联合提出了 MagicWorld。其核心目标非常明确:既要让动态目标“动得真实”,又要让整个世界在长时间交互下保持稳定一致。为此,作者围绕运动建模、历史记忆和训练机制,设计了一套面向长时稳定性的交互式视频世界模型框架。

二、核心技术:MagicWorld 框架
MagicWorld 的整体思路可以概括为三部分:基于光流的运动保持约束、基于 latent 相似度的历史缓存检索,以及多步聚合的增强式交互训练策略。它们分别对应“让运动更真实”“让模型记住过去”“让训练优化整段交互而不是单步结果”。
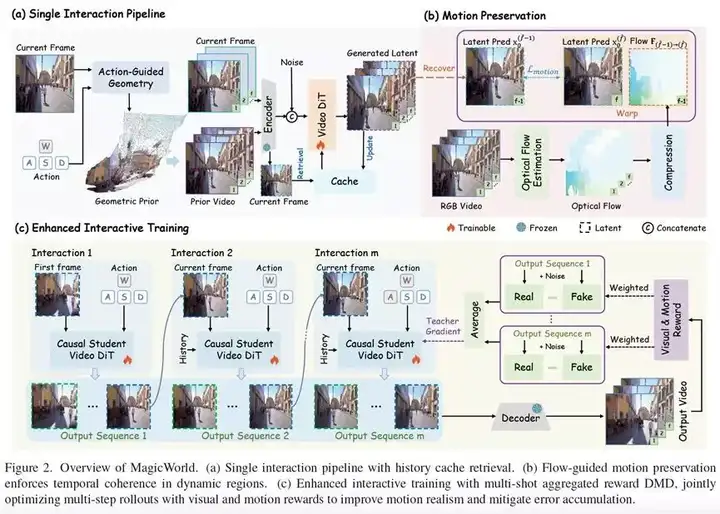
2.1 基于光流的运动保持:抑制动态目标运动漂移
为了缓解动态主体在生成过程中出现的运动退化问题,MagicWorld 引入了 flow-guided motion preservation。
这个模块的核心思想是:既然动态区域的真实变化可以由光流反映出来,那么就应该在训练时利用光流信息,对这些区域施加更强的时间一致性约束。具体来说,作者并没有直接在 RGB 空间做光流监督,而是将监督放到 latent 空间中进行,以减少显存开销。
模型首先基于 flow-matching 形式预测去噪后的 latent 表示,再利用相邻帧之间的光流进行 warping,对齐连续 latent 帧,并对高运动区域赋予更大的约束权重。这样一来,模型会更关注那些真正发生运动的区域,而不会对静态背景施加过强限制。
最终效果是,动态主体的运动更加连贯,运动漂移现象得到明显缓解。从直观上看,这一步相当于告诉模型:哪些地方应该动,以及这些区域在时间维度上必须保持合理演化。这也是 MagicWorld 提升运动真实性的关键基础。
2.2 历史缓存检索:让模型“记住过去”
长时交互中的另一个核心问题,是模型会随着时间推移逐渐偏离最初的世界状态。为了解决这个问题,MagicWorld 设计了 history cache retrieval,本质上是给模型增加了一套可检索的历史记忆机制。
其做法分为三步。
- 首先,在每个自回归步骤中,模型会把生成得到的 latent 特征写入一个历史缓存池中;
- 其次,在下一步推理时,将当前输入帧的 latent 与缓存中的历史 latent 做相似度匹配;
- 最后,选取得分最高的几个历史状态作为辅助条件,再注入当前生成过程。
这里最有意思的一点在于,MagicWorld 的检索并不依赖时间邻近性,也不依赖显式相机几何,而是直接在 latent 空间中做语义和结构层面的相似性匹配。这意味着模型不只是“回看最近几帧”,而是能够主动找回那些在当前状态下最有参考价值的历史场景,从而维持视角切换前后的结构一致性,并减少长期漂移。可以把它理解成一种更灵活的“世界记忆”:模型不是机械地继承上一步结果,而是在生成过程中不断参考过去最相关的状态,避免场景越走越偏。
2.3 多步聚合训练:从优化单步转向优化整段交互
除了结构设计,MagicWorld 在训练策略上也做了非常关键的改进。作者指出,已有一些交互式蒸馏方法在每一步交互后都会立即更新模型参数,但这种做法容易让模型只顾当前一步的局部最优,而忽略整条生成轨迹的整体质量。为此,MagicWorld 提出了 multi-shot aggregated DMD。
训练时,模型不会在每一步结束就立刻反向传播,而是先完整模拟一段多步交互 rollout,将整段交互中的蒸馏损失聚合起来,再统一进行优化。这样,模型学习到的不再只是“这一步怎么生成得好”,而是“这一整段交互序列是否稳定、是否一致”。
在此基础上,作者进一步引入了 dual-reward weighting,同时用视觉质量和运动质量两个奖励信号来加权蒸馏目标。这意味着模型不仅要生成清晰画面,还要保证长时间交互中的动态表现合理。实验表明,这种“多步聚合 + 双奖励”的训练方式,相比逐步更新的方案,能更有效地减少误差累积,提升长时稳定性。
2.4 数据支撑:构建真实世界数据集 RealWM120K
为了更系统地支持真实动态场景下的视频世界建模,论文还构建了 RealWM120K 数据集。该数据集以全球多城市的 city-walk 视频为主体,覆盖不同城市、季节、时间和天气条件,并配套了文本描述、相机轨迹、点云、目标 mask 和深度图等多模态标注。
相比以往偏游戏环境或弱动态场景的数据,RealWM120K 更强调真实街景中的复杂动态主体与非平凡相机运动,因此更适合用来评估和训练长时交互式视频世界模型。
三、性能表现:在长时稳定性与运动真实性上全面提升
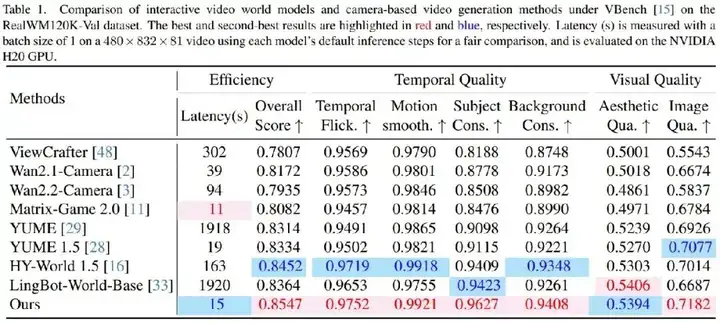
MagicWorld 在 RealWM120K-Val 上进行了系统评测,结果显示其在整体表现上优于现有主流方法。根据论文中的 VBench 结果,MagicWorld 的 Overall Score 达到 0.8547,为所有对比方法中最高;同时,其推理延迟为 15 秒,效率也具备很强竞争力,仅次于极少数更轻量的方法。
定性结果的比较:

MagicWorld在多个场景下的结果:

四、总结:从“能生成”走向“能长期稳定生成”
MagicWorld 解决的并不是一个表面上的画质问题,而是交互式视频世界模型走向实用化过程中最核心的瓶颈之一:如何在长时间交互中保持运动合理、场景稳定和语义一致。
它的思路很清晰:用光流约束解决动态主体“怎么动”的问题,用历史缓存解决“如何记住过去”的问题,再通过多步聚合和双奖励训练,让模型从优化单步结果转向优化整段交互轨迹。最终,这套方法在实验中同时提升了运动真实性、时间一致性和长时稳定性。
vivo BlueImage Lab
蓝图影像创新实验室,主要负责移动影像算法创新,包括图像/视频处理、图像/视频交互、图像/视频增强、多模态理解大模型等方面的技术前沿探索。
致力于不断提升vivo移动影像的算法能力,使用户能够拍摄出更加清晰、美观的照片和视频。同时积极探索增强现实、具身智能等新兴技术领域的应用,努力为用户提供更加丰富和便捷的影像体验。
欢迎持续关注 vivo 影像技术,获取前沿技术创新经验分享与热招岗位信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号