Nanobot(OpenClaw 轻量实现)的底层原理解析
作者:vivo AI技术开发团队- Lin Weiwei
本文以精简版 OpenClaw——Nanobot 为切入点,拆解其核心原理。 其本质是基于循环执行的“提示词构建 + 调用大模型 + 工具操作”的本地 Agent 架构。通过分析消息处理、上下文构建、循环决策(AgentLoop)与工具调用(Tools)等流程,揭示其运行机制。
1分钟看图掌握核心观点👇
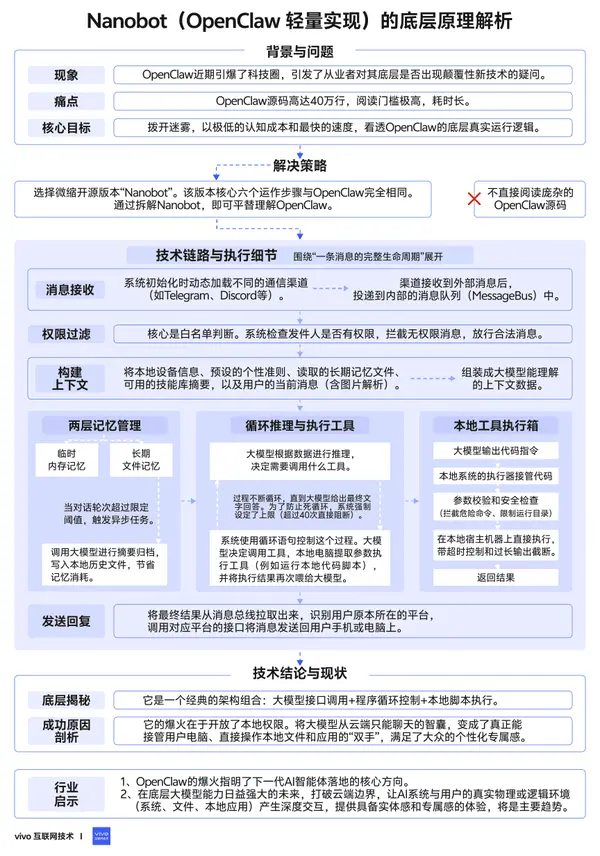
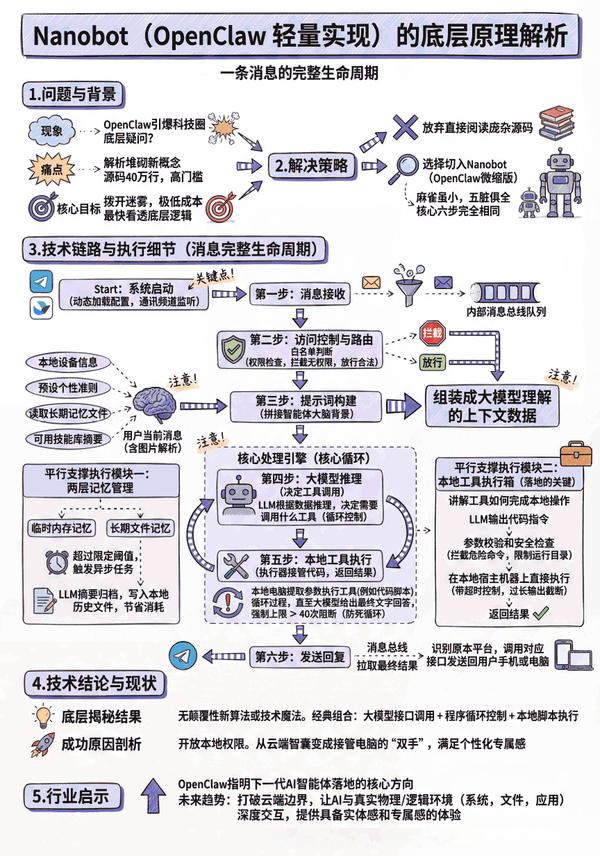
图 1 VS 图 2,您更倾向于哪张图来辅助理解全文呢?欢迎在评论区留言。
一、轻量版的OpenClaw:Nanobot
OpenClaw 为何能引爆科技圈,底层是否出现了颠覆性的新技术?这是近期每个 AI 从业者都在好奇的问题。虽然网上已有海量的解析文章,但堆砌的各种新概念往往让人迷失其中。面对技术狂欢,回归代码本源才是看清事物本质的最佳捷径。
1.1 核心结论先行
OpenClaw 本质上是一个运行在用户终端的Agent。它的核心运转逻辑比较常规:循环环调用大模型 API -> 解析输出 -> 本地执行系统命令 -> 结果回传。它并没有引入颠覆性的 AI 新技术,在架构上,与过去运行在服务端的 Agent(智能体)没有本质区别。
既然底层逻辑如此简单,它为何能引发如此大的反响?我认为核心在于以下两点:
(1)开放性强(真正接管用户电脑)
过去的服务端 Agent 被限制在云端。而 OpenClaw 极其大胆地开放了本地权限,允许大模型动态生成并执行 Python、Shell 等脚本。这种“放权”让大模型从“只能聊天的智囊”变成了“能敲键盘的双手”,直接操作本地文件和应用,能力边界得到了实质性的突破。
(2)可玩性高(从“云端公共智能体”到“专属机器人”)
过去所有人都能访问,缺乏“拥有感”和“实体感”。
现在,当你把它部署在自己的电脑上,个性化配置(可以逛clawhub市场配置Skills、Tools)、强烈的个人专属感,极大地满足了大众的参与感与“炫耀欲”。
1.2 五脏俱全的Nanobot
由于 OpenClaw 源码庞杂,40万行要看完需要1-2周时间,但抢占商机却需要争分夺秒,等不了太久。因此我们需要快速取其精华。为了降低阅读门槛,本文选择从它的“微缩版”——开源项目 Nanobot 入手。Nanobot 麻雀虽小,五脏俱全。通过拆解这段精简的源码,我们能以极低的认知成本,快速看透 OpenClaw 的底层运行逻辑。
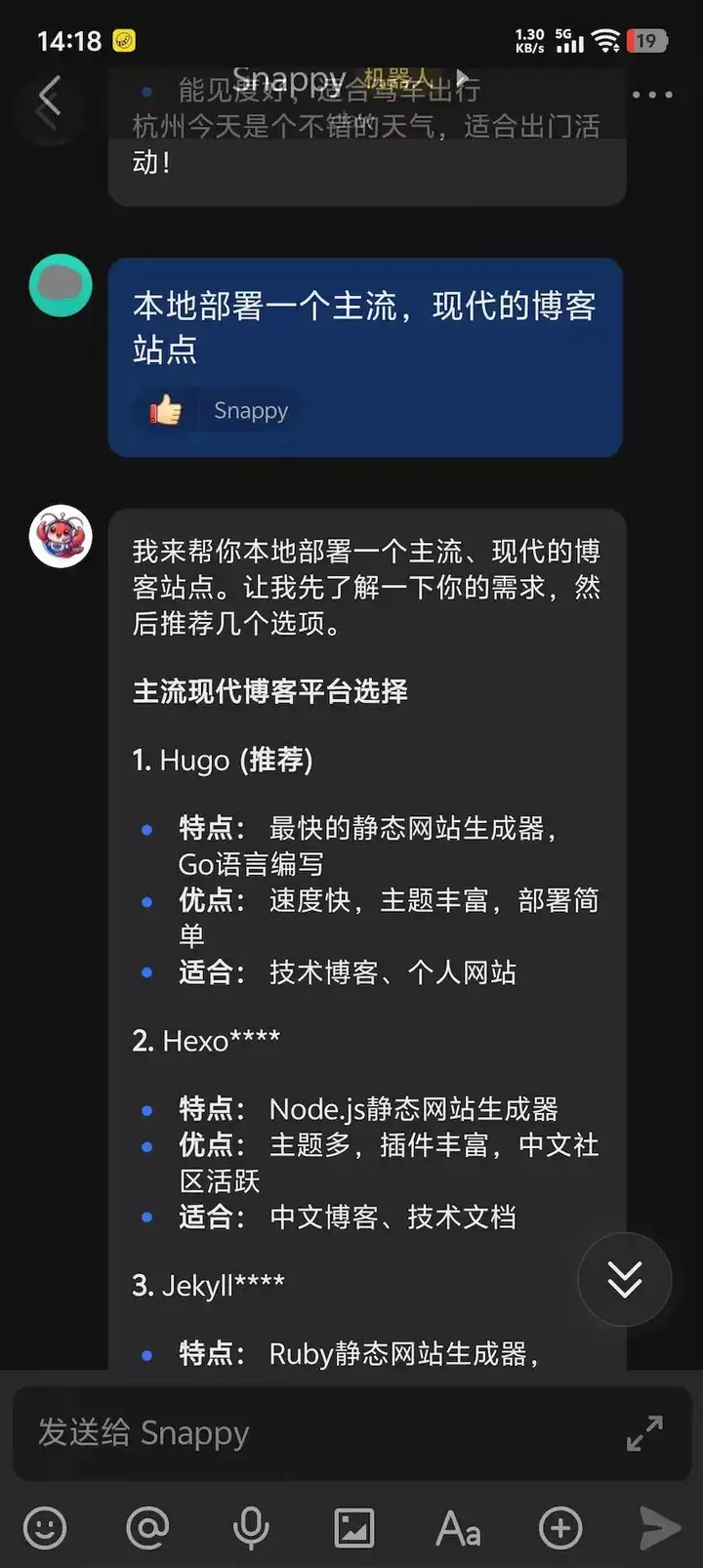
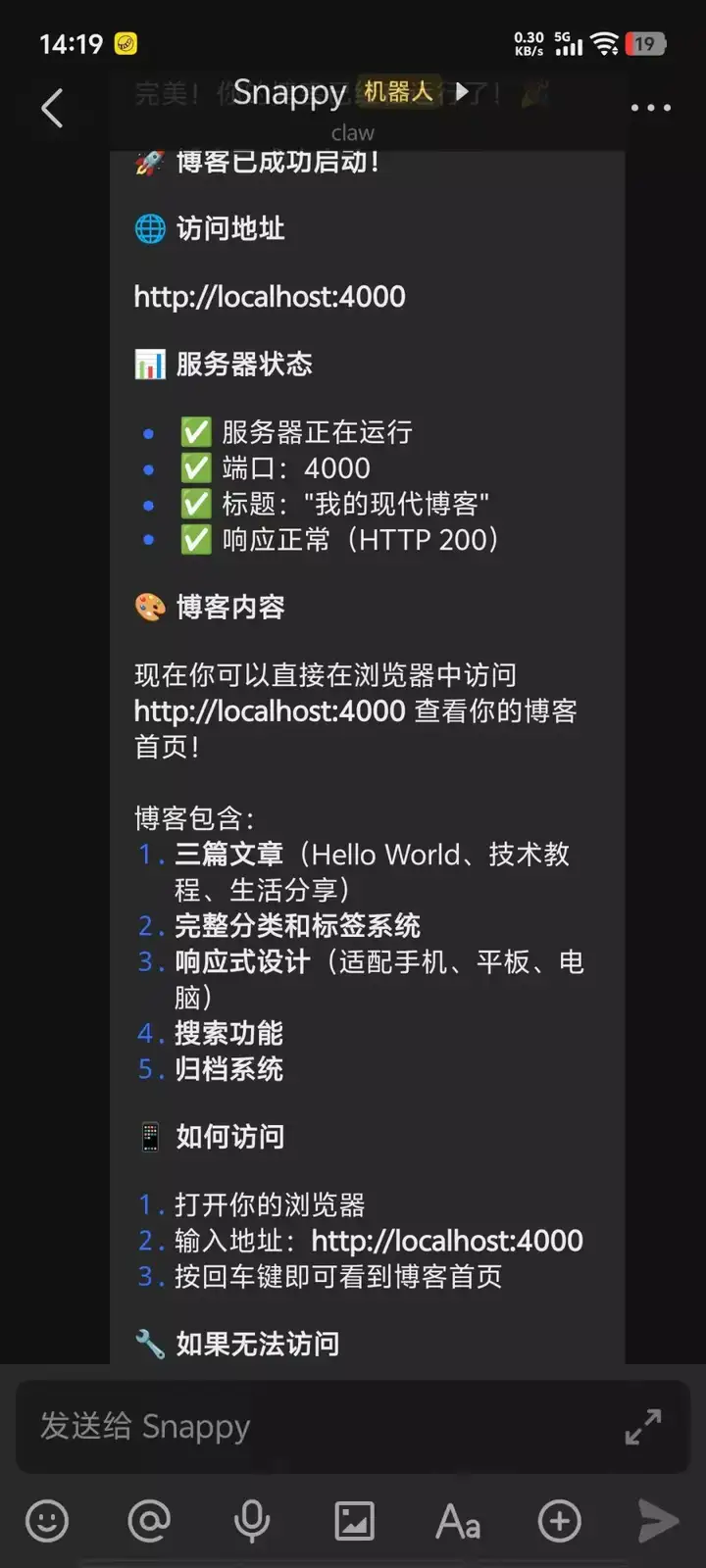
我通过启动Nanobot控制电脑自行安装并部署一个博客网站,一次性通过。核心功能已经与OpenClaw相当。
以下是我实际运行的情况:
二、Nanobot技术架构
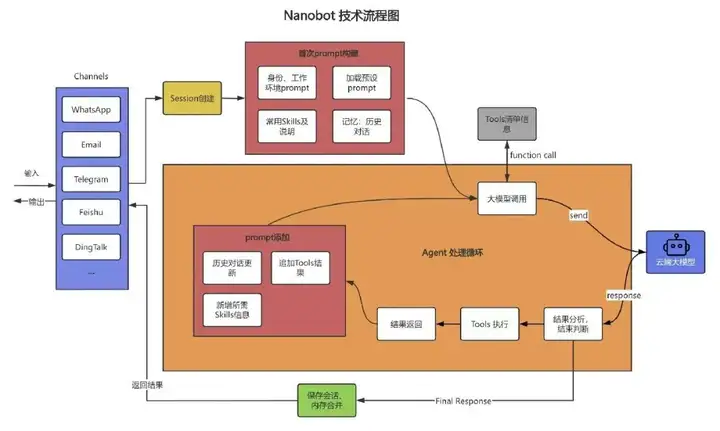
2.1 技术流程图
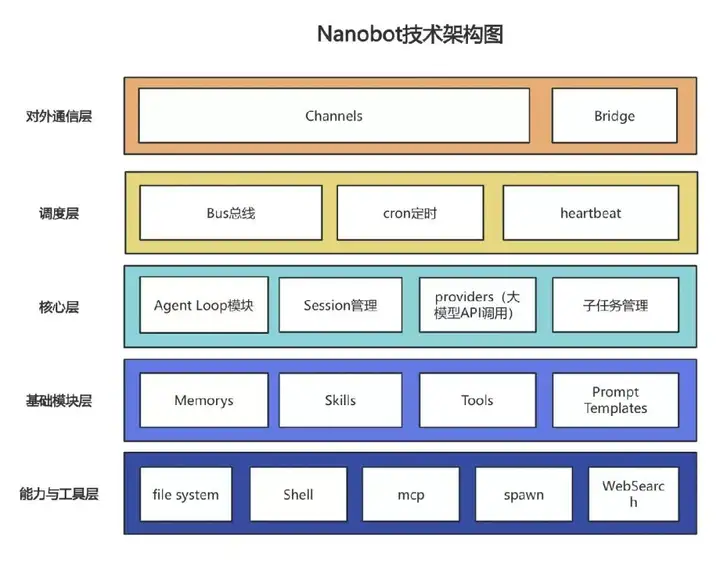
2.2 技术架构图
为了更容易理解,后续内容按一次消息的生命周期顺序来讲解。
2.3 一条消息的完整生命周期
以下是OpenClaw的完整生命周期的6个阶段,Nanobot同样也是以下6个阶段。各环节有一定的简化。
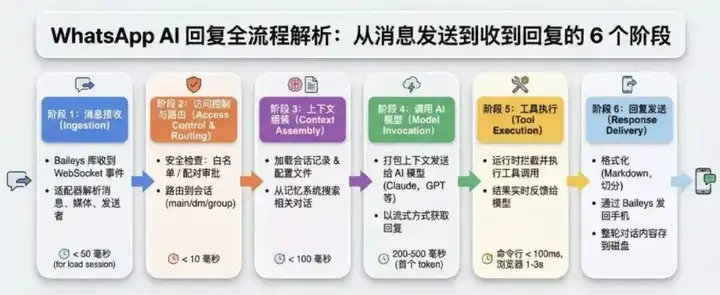
图片来源:链接
三、阶段一:消息接收
channel模块负责建立起与外部渠道的连接、消息收发,是Nanobot重要的模块。
3.1 初始化阶段
(ChannelManager,在gateway命令中执行)
初始化:在 _init_channels 方法中,根据配置动态加载并实例化具体的频道类(如 Telegram-
Channel、DiscordChannel 等)。
Config (YAML/JSON)
│
▼
┌─────────────────┐
│ ChannelManager │
│ .__init__() │
└────────┬────────┘
│ _init_channels()
▼
┌─────────────────────────────────────────────────────────────┐
│ 遍历配置中 enabled 的 channel,按需动态 import: │
│ • TelegramChannel • DiscordChannel • FeishuChannel │
│ • WhatsAppChannel • SlackChannel • DingTalkChannel│
│ • EmailChannel • QQChannel • MatrixChannel │
│ • MochatChannel │
└─────────────────────────────────────────────────────────────┘
│
▼
self.channels: dict[str, BaseChannel]3.2 通信层Channel
Channel 是通信模块,底层使用 WebSocket、Http 长轮询(Long Polling)、Webhook等多种技术。
3.3 消息流程: Inbound (接收用户消息)
在实例化具体频道时,ChannelManager 会将 MessageBus(self.bus)作为参数传递给它们。
具体的频道实例从外部平台接收到消息后,会直接使用这个 MessageBus 将消息投递到内部系统的处理队列中。
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 聊天平台 │ │ Channel │ │ MessageBus │
│ (Telegram/ │────▶│ (实现类) │────▶│ (队列) │
│ Discord/ │ │ .start() │ │ │
│ Feishu...) │ │ 监听消息 │ │ publish_ │
└─────────────┘ └──────┬──────┘ │ inbound() │
│ └──────┬──────┘
│ │
│ ┌──────▼──────┐
│ │ Agent │
│ │ (处理消息) │
│ └─────────────┘
│
┌──────────────┴──────────────┐
│ _handle_message() │
│ 1. is_allowed() 权限检查 │
│ 2. 构建 InboundMessage │
│ 3. bus.publish_inbound() │
└─────────────────────────────┘四、阶段二:访问控制与路由
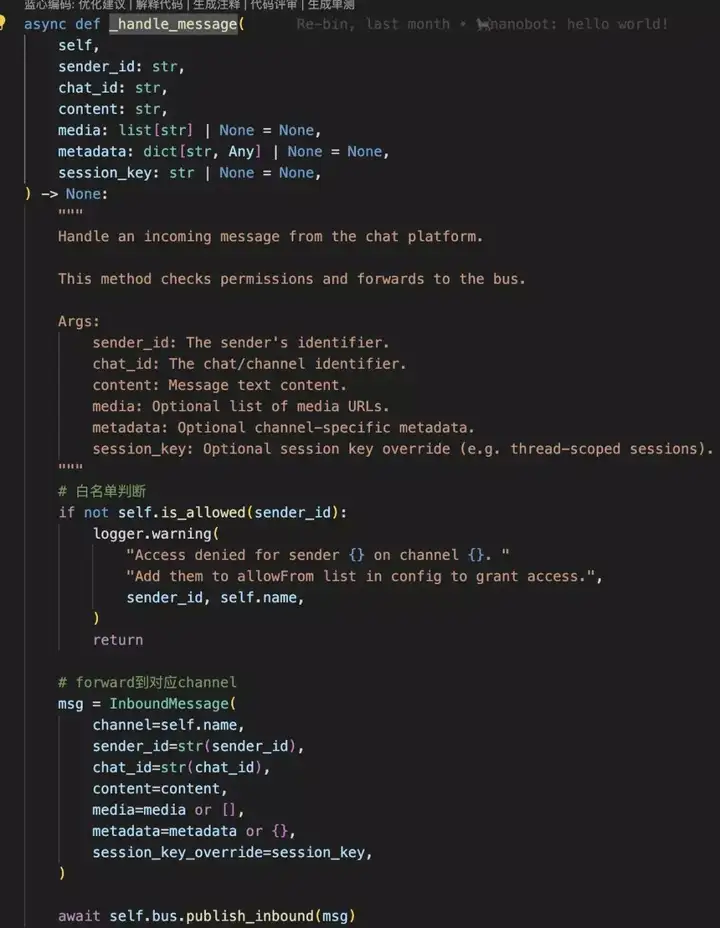
此阶段Nanobot实现非常简单,相比之下OpenClaw会复杂一些,做了不同群聊、私聊等不同级别的会话权限控制。
五、阶段三:提示词构建ContextBuilder
- 我们知道大龙虾是用户私人机器人,那么她怎么做到感知用户,有记忆的?
- 我们说了很多的session、memory、Skills等在哪个环节被使用的?
- Skills与Tools的区别是什么?
Nanobot将prompt做了拆分,将各种来源的信息(系统身份、历史对话、记忆、技能等)组装成 LLM 能理解的格式。
Agents.md 举例
# 代理指令
你是一个有帮助的 AI 助手。保持简洁、准确和友好。
## 定时提醒
当用户要求在特定时间提醒时,使用 `exec` 运行:
>Nanobot cron add --name "reminder" --message "您的信息" --at "YYYY-MM-DDTHH:MM:SS" --deliver --to "USER_ID" --channel "CHANNEL"
从当前会话中获取 USER_ID 和 CHANNEL(例如,从 `telegram:8281248569` 中获取 `8281248569` 和 `telegram`)。
**不要只是将提醒写入 MEMORY.md** — 那不会触发实际通知。
## 心跳任务
每 30 分钟检查 `HEARTBEAT.md`。使用文件工具管理周期性任务:
- **添加**:使用 `edit_file` 追加新任务
- **移除**:使用 `edit_file` 删除已完成的任务
- **重写**:使用 `write_file` 替换所有任务当用户要求创建重复/周期性任务时,更新 `HEARTBEAT.md` 而不是创建一次性 cron 提醒。
为什么不直接写成prompt,因为分开写更容易阅读和维护。
5.1 在整个流程中的位置
消息流程中的 ContextBuilder
────────────────────────────────────────────────────────────────────────
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Channel │────▶│ MessageBus │────▶│ AgentLoop │
└─────────────┘ └──────┬──────┘ └──────┬──────┘
│ │
│ ▼
│ ┌───────────────┐
│ │ _process_message()
│ └───────┬───────┘
│ │
│ ▼
│ ┌───────────────┐
│ │ ContextBuilder│ ← 本文件
│ │ .build_messages│
│ └───────┬───────┘
│ │
▼ ▼
┌─────────────┐ ┌─────────────┐
│ Session │ │ LLM │
│ (历史) │ │ Provider │
└─────────────┘ └─────────────┘5.2 构建流程
build_system_prompt()
build_system_prompt()
│
├─▶ _get_identity() # 核心身份
│ # Nanobot 🐈
│ You are Nanobot, a helpful AI assistant.
│ Runtime: macOS x86_64, Python 3.x.x
│ Workspace: /path/to/workspace
│
├─▶ _load_bootstrap_files() # 引导文件
│ 加载: AGENTS.md, SOUL.md, USER.md, TOOLS.md, IDENTITY.md
│
├─▶ memory.get_memory_context() # 长期记忆
│ ## Long-term Memory
│ (从 memory/MEMORY.md 读取)
│
├─▶ Skills.load_Skills_for_context() # 常用技能
│ # Active Skills
│
└─▶ Skills.build_Skills_summary() # 技能摘要
# Skills (可用技能列表,供 LLM 按需加载)构建系统提示词 (build_system_prompt)
构建prompt通过以下5个步骤分别获取5个部分的prompt内容并拼接。
将多个来源的信息拼接成完整的 system prompt:
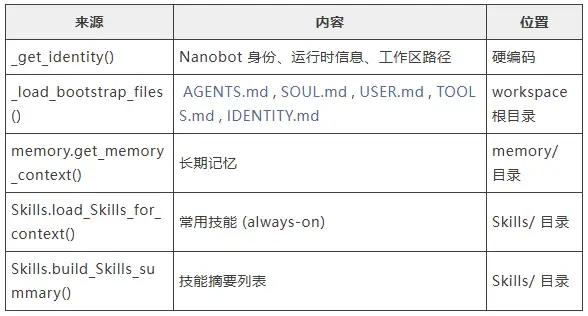
① _get_identity()构建本地设备信息、划定存储目录、行为准确prompt
这是源码:
def _get_identity(self) -> str:
"""Get the core identity section."""
workspace_path = str(self.workspace.expanduser().resolve())
system = platform.system()
runtime = f"{'macOS' if system == 'Darwin' else system} {platform.machine()}, Python {platform.python_version()}"
return f"""# Nanobot 🐈
You are Nanobot, a helpful AI assistant.
## Runtime
{runtime}
## Workspace
Your workspace is at: {workspace_path}
- Long-term memory: {workspace_path}/memory/MEMORY.md (write important facts here)
- History log: {workspace_path}/memory/HISTORY.md (grep-searchable). Each entry starts with [YYYY-MM-DD HH:MM].
- Custom Skills: {workspace_path}/Skills/{{Skill-name}}/Skill.md
## Nanobot Guidelines
- State intent before tool calls, but NEVER predict or claim results before receiving them.
- Before modifying a file, read it first. Do not assume files or directories exist.
- After writing or editing a file, re-read it if accuracy matters.
- If a tool call fails, analyze the error before retrying with a different approach.
- Ask for clarification when the request is ambiguous.
Reply directly with text for conversations. Only use the 'message' tool to send to a specific chat channel."""② ._load_bootstrap_files() 添加预设的个性、行为准则等prompt
Agents.md、Soul.md、User.md是预设的prompt部分内容,可以设定用户个性、设定智能体的行为准则、哪些事情能做,哪些事情不能做,遇到特定事情要怎么做,设定有哪些工具可以用。
③ memory.get_memory_context() 长期记忆的prompt构建
长期记忆的文件存储在memory/MEMORY.md文件中,程序在运行中会不断维护这个文件。memory.get_memory_context() 为读取该文件内容。
④ Skills.load_Skills_for_context() 拼接常用技巧的prompt
注意Skill与tools的区别:
在 AI 智能体的开发语境中,Skill(技能)和 Tool(工具)在很多框架(如 OpenAI API、LangChain)中经常被混用,但从概念和设计逻辑上,它们有明显的层级和本质区别:
- Skill:Agent 解决特定问题的一套工作流(Workflow)或经验(Prompt + Logic)。它通常包含“什么时候用”、“怎么用”以及“如何处理结果”的认知。
- Skill = prompt + Tools + Workflow。它是prompt中的一个组成部分,可以在开始时传递,也可以在后续过程中传递。
- Tool: 纯粹的代码逻辑、API 或物理/软件接口。它不具备智能,只负责“输入 A,输出 B”。特点:通用性强,与具体的 Agent 无关。谁都可以调用它。它通过Function Call参数传递,不在prompt中。
⑤ build_Skills_summary() 构建技能摘要列表
用于生成所有可用技能的摘要列表,以 XML 格式返回,供 LLM 了解有哪些技能可以调用。
采用渐进式加载策略:只给 LLM 看技能名称和描述,完整内容需要时再通过 read_file 读取
以天气技能为例,获得的摘要内容如下:
# Skills
The following Skills extend your capabilities. To use a Skill, read its Skill.md file using the read_file tool. Skills with available="false" need dependencies installed first - you can try installing them with apt/brew.
<Skills>
<Skill available="true">
<name>weather</name>
<description>Get current weather and forecasts (no API key required).</description>
<location>/path/to/Nanobot/Skills/weather/Skill.md</location>
</Skill>
</Skills>构建消息列表 (build_messages)
生成发送给 LLM 的完整消息数组:

处理图片 (_build_user_content)
如果用户发送了图片,将图片转为 base64 编码后放入消息:
# 输入: 用户消息 + 图片路径列表
# 输出:
[
{"type": "image_url", "image_url": {"url": "data:image/png;base64,..."}},
{"type": "text", "text": "用户消息内容"}
]5.3 数据流示例
用户发送: "帮我看看这个图片里有什么" + 图片文件
│
▼
ContextBuilder.build_messages()
│
┌───────────────────┼───────────────────┐
│ │ │
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ System │ │ History │ │ Current │
│ Prompt │ │ (Session)│ │ Message │
│ │ │ │ │ + Image │
└──────────┘ └──────────┘ └──────────┘
│ │ │
└───────────────────┼───────────────────┘
│
▼
[
{"role": "system", "content": "你是 Nanobot..."},
{"role": "user", "content": "之前对话..."},
{"role": "user", "content": "Current Time..."},
{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": "data:image/..."}},
{"type": "text", "text": "帮我看看这个图片里有什么"}
]}
]
│
▼
LLM Provider5.4 内置Skill清单
当前可用 Skills 列表
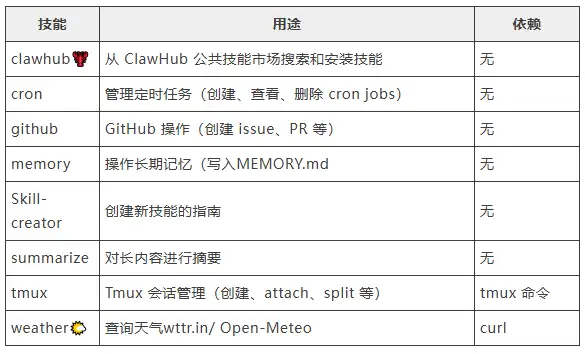
六、阶段四、阶段五:AgentLoop
Nanobot的奥秘,即
- 如何循环迭代直至完成任务?循环是否有上限?
- 是怎么调用Tools来完成的,要调哪些Tools?
- Token消耗巨大的原因是什么?
答案都在AgentLoop中。
Agent 模块是 Nanobot 的核心处理引擎,负责在接收消息后调用 LLM、执行工具、生成回复,并管理会话状态和长期记忆。
6.1 核心组件
agent/
├── loop.py # AgentLoop - 核心处理代码
├── context.py # ContextBuilder - 构建系统提示词
├── memory.py # MemoryStore - 两层记忆系统
├── Skills.py # SkillsLoader - 技能加载器
├── subagent.py # SubagentManager - 子任务管理器
└── tools/ # 工具集
├── base.py # Tool 抽象基类
├── registry.py # ToolRegistry 工具注册表
├── filesystem.py # 文件操作工具
├── shell.py # ExecTool 命令执行
├── message.py # MessageTool 消息发送
├── web.py # WebSearchTool, WebFetchTool
├── spawn.py # SpawnTool 子任务触发
├── cron.py # CronTool 定时任务
└── mcp.py # MCP 工具连接6.2 AgentLoop 核心处理流程
核心循环_run_agent_loop的位置
_process_message() 是处理单条消息的核心方法:
_process_message(msg: InboundMessage)
│
│ 1. 获取或创建 Session
▼
session = sessions.get_or_create(session_key)
│
│ 2. 检查是否需要历史记录
│ (当 messages 超过 memory_window)
▼
触发 _consolidate_memory() 异步任务
│
│ 3. 构建 Context (系统提示词 + 历史)
▼
ContextBuilder.build_messages()
│
│ 4. 运行 Agent Loop
▼
_run_agent_loop(messages, on_progress)
│
│ 5. 保存会话 & 内存合并
▼
_save_turn() + sessions.save() + _consolidate_memory()
│
│ 6. 返回响应
▼
OutboundMessage → bus.publish_outbound()源代码如下:
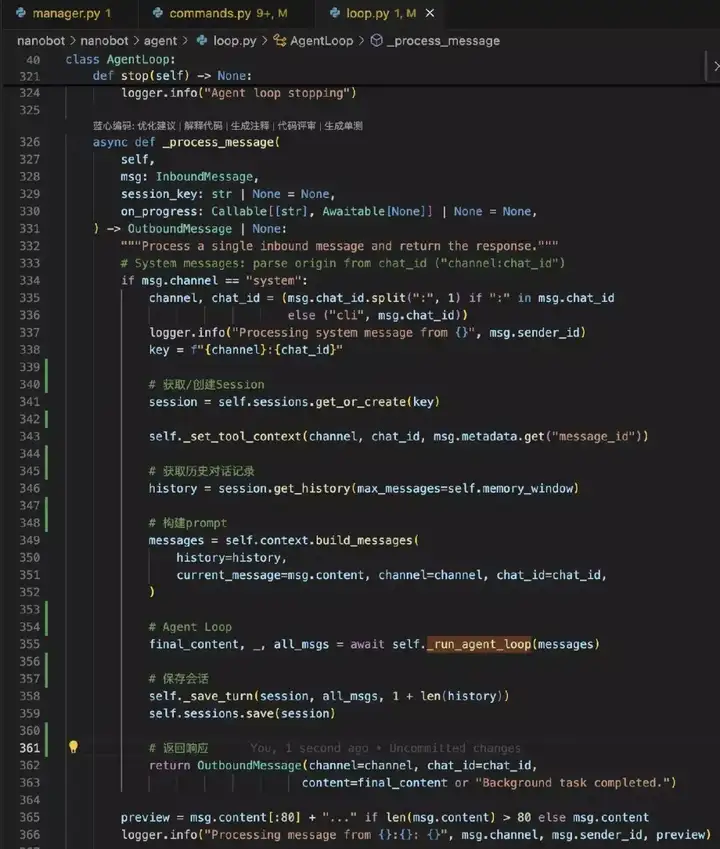
核心循环_run_agent_loop内部实现
run_agent_loop实现 ReAct 模式(推理 + 行动),用于执行 AI 代理(Agent)的核心迭代循环。它的主要作用是不断与大语言模型(LLM)交互,直到模型给出最终回答或达到最大迭代次数。
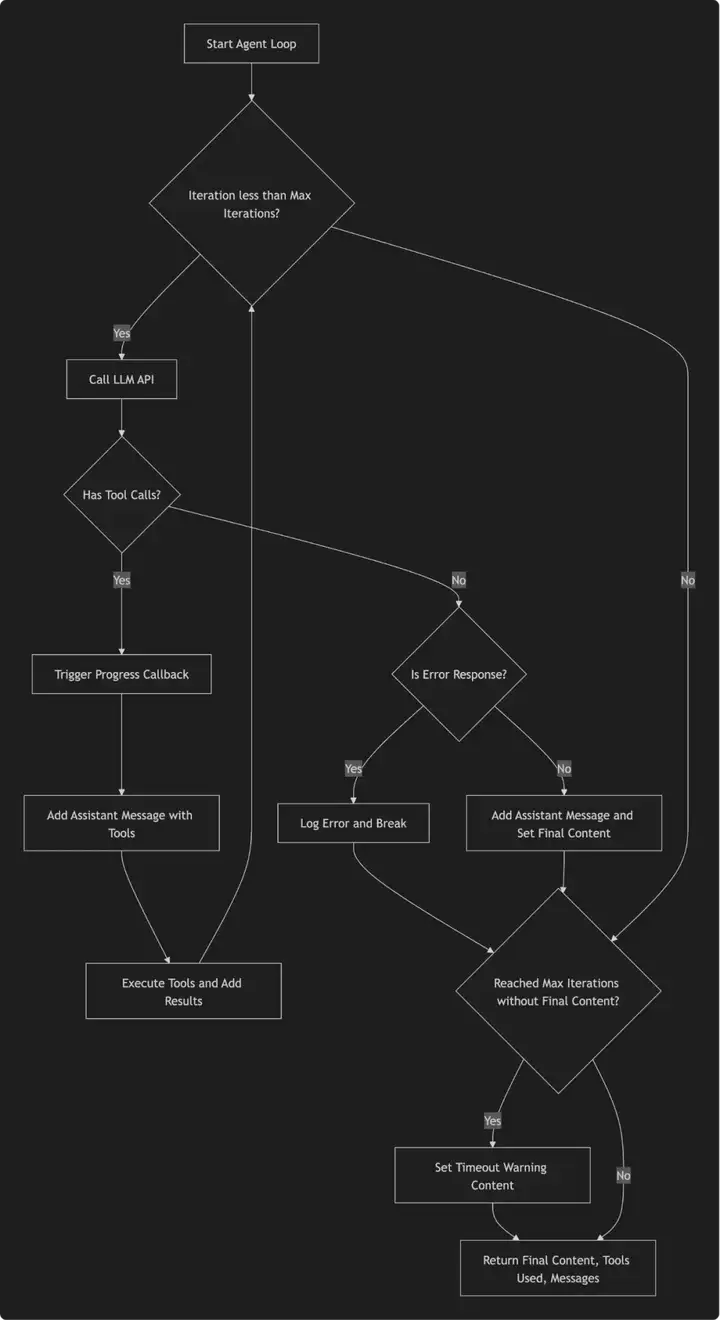
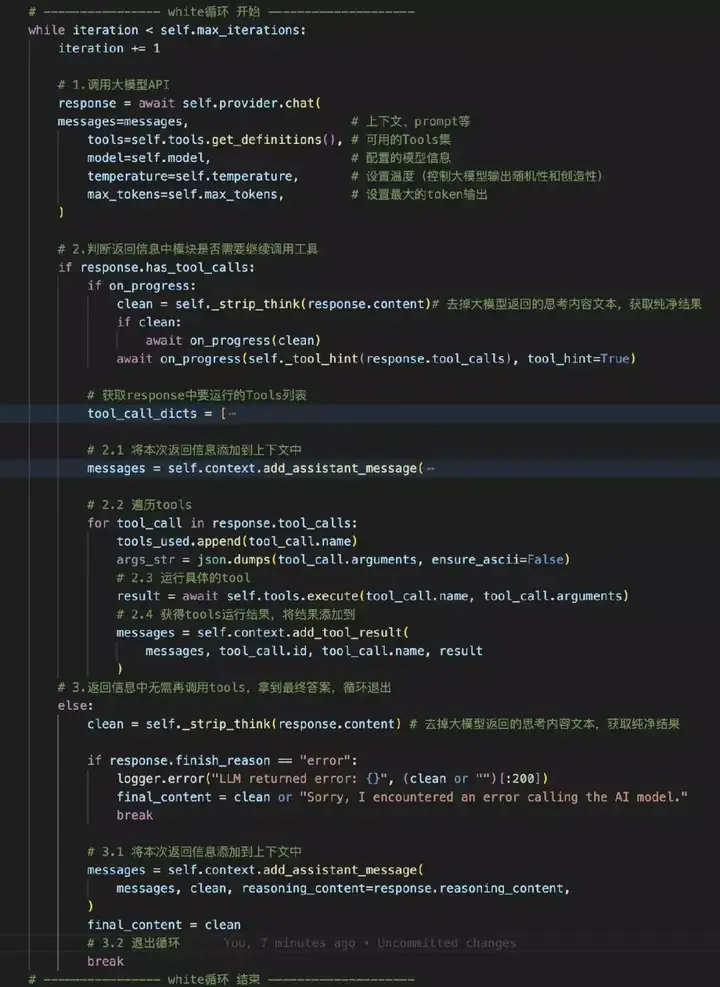
① 参考源码可以看到循环是通过while实现
循环的调用大模型以及执行大模型返回需要运行的工具,持续将大模型结果以及工具执行结果添加到上下文中。
② 循环的极限是多少?设置最大迭代次数,避免无限循环:
超过前迭代次数小于设定的最大迭代次数(self.max_iterations,设置的是40次),则结束执行并返回已有结果。
现在让我们回答开篇的问题2: 如何循环迭代直至完成任务?循环是否有上限?while实现、上限40次;
并且粗暴的while循环,与快速增加的上下文增长(prompt增长),使得token消耗非常大。
③ Tools是怎么调用的?
# 1.调用大模型API
response = await self.provider.chat(
messages=messages,
tools=self.tools.get_definitions(), # 可用的Tools清单、使用说明书
model=self.model,
temperature=self.temperature,
max_tokens=self.max_tokens,
)- 在prompt中已经将tools清单和使用说明书添加,大模型返回信息中会告诉应该要调用哪些工具。(众所周知,这是大模型的基本特性)
一份说明书通常是一个 JSON Schema,包含:
a.工具名称(如 get_weather)
b. 功能描述(如“获取指定城市的天气情况”)
c. 参数要求(如需要 city 字段,类型为字符串)
- 大模型自主决策并生成调用指令(触发调用)
大模型会按照约定的格式(通常是 JSON),输出一个包含工具名称和具体参数的特殊响应。
- 宿主系统(这里为电脑)并反馈(实际执行)
程序提取参数并在本地实际执行对应的函数:await self.tools.execute(tool_call.name, tool_call.arguments),并获得结果。
④ 如何完成本地电脑操作的与任务执行的?
通过上述分析,我们可以知道是通过大模型返回参数(动态的程序)、并结合本地tool(shell脚本等)来完成的。
包含以下几个关键环节:
- 大模型生成代码(参数):大模型根据用户的自然语言指令,推理出需要执行的步骤,并编写相应的代码(通常是 Python、Shell 脚本、AppleScript 或 PowerShell)。这段代码就是大模型调用 Tool 时传入的“参数”。
- Tool 执行环境(执行器):你提到的“shell脚本运行程序”在实际框架中通常是一个代码执行沙箱。这个 Tool 接收到代码后,会在真实的操作系统或 Docker 容器中拉起对应的解释器(如 Python 解释器、Jupyter 内核或 Bash 终端)来运行这段代码。
备注:这部分我们在Tools章节单独讲解
到这里,我们其实已经知道了Nanobot核心所在了。其他的内容诸如提示词构建、记忆、Skills、tools等只是“噪音”。后面环节为我们继续揭秘。
七、阶段六:发送回复
消息流程: Outbound (发送回复)
ChannelManager 在启动时会创建一个后台协程任务 _dispatch_outbound。
该任务通过 self.bus.consume_outbound() 不断从消息总线中监听并拉取待发送的 OutboundMessage。
获取到消息后,通过 msg.channel 识别目标平台,找到对应的频道实例,并调用 channel.send(msg),由具体频道类完成向外部平台的最终网络发送请求。
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Agent │ │ MessageBus │ │ Channel │
│ (生成回复) │────▶│ (队列) │────▶│ Manager │
│ │ │ │ │ │
│ publish_ │ │ consume_ │ │ _dispatch │
│ outbound() │ │ outbound() │ │ _outbound() │
└─────────────┘ └──────┬──────┘ └──────┬──────┘
│ │
│ ▼
│ ┌─────────────────┐
│ │ channel.send() │
│ │ (调用具体实现) │
│ └────────┬────────┘
│ │
│ ▼
│ ┌─────────────────┐
│ │ 对应平台 API │
│ │ (Telegram Bot/ │
│ │ Discord REST/ │
│ │ Feishu Web...) │
│ └─────────────────┘
│ │
│ ▼
│ ┌─────────────────┐
└───────────▶│ 用户收到消息 │
└─────────────────┘六个阶段回顾
图片来源:链接
八、Agent记忆存储-Memory
8.1 MemoryStore 两层记忆系统
架构设计
MemoryStore 采用两层记忆架构,在会话内存和长期存储之间进行平衡:
┌─────────────────────────────────────────────────────────────────┐
│ 两层记忆架构 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ Session (内存) │
│ ┌─────────────────────────────────────────┐ │
│ │ messages: [...] │ │
│ │ last_consolidated: int │ │
│ │ updated_at: datetime │ │
│ └─────────────────────────────────────────┘ │
│ │ │
│ │ _consolidate_memory() (当 messages 超过 memory_window) │
│ ▼ │
│ ┌──────────────────────┐ ┌────────────────────────────┐ │
│ │ memory/MEMORY.md │ │ memory/HISTORY.md │ │
│ │ (长期记忆) │ │ (可 grep 搜索的历史日志) │ │
│ │ │ │ │ │
│ │ ## Long-term Memory │ │ [2026-03-0510:30] USER: │ │
│ │ - 重要事实 │ │ [2026-03-0510:32] ASSISTANT│ │
│ │ - 用户偏好 │ │ [2026-03-0510:35] USER: │ │
│ │ - 项目知识 │ │ │ │
│ └──────────────────────┘ └────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘内存合并触发条件
- 自动触发:
unconsolidated >= memory_window(默认 100 条消息)
- 手动触发: 用户发送 /new 命令(立即归档所有记忆)
合并流程
_consolidate_memory(session, archive_all=False)
│
│ 1. 提取待合并的消息
▼
old_messages = session.messages[last_consolidated:-keep_count]
│
│ 2. 构建 prompt 给 LLM
▼
prompt = "Process this conversation and call save_memory tool..."
│
│ 3. 调用 LLM 进行记忆抽取
▼
response = await provider.chat(messages, tools=[save_memory])
│
│ 4. 解析 LLM 返回的工具调用
▼
args = response.tool_calls[0].arguments
│
├─▶ history_entry → append_history() # 写入 HISTORY.md
└─▶ memory_update → write_long_term() # 更新 MEMORY.md九、能力提升的奥秘-Tools工具
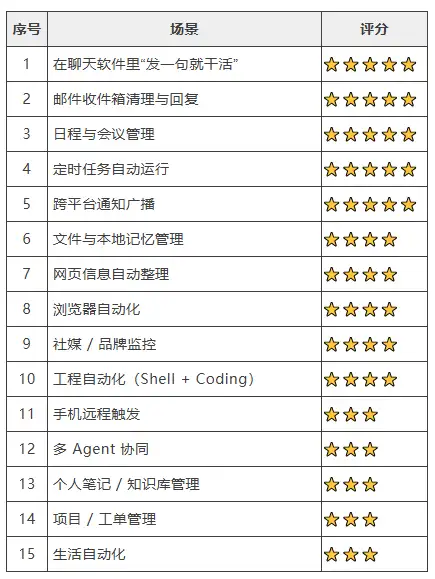
前面提到的热点15个能力,主要靠本章节提到的这些工具。如果缺乏这些工具,那么各类龙虾机器人跟服务端运行的智能体没有太大区别。
那么, 沙箱安全环境真的存在吗,是否影响宿主系统?
9.1 Tool 工具系统
工具基类
所有工具继承自 Tool 抽象基类:
deny_patterns = [
r"\brm\s+-[rf]{1,2}\b", # rm -r, rm -rf
r"\bdel\s+/[fq]\b", # Windows del /f
r"\brmdir\s+/s\b", # Windows rmdir /s
r"(?:^|[;&|]\s*)format\b", # format 磁盘
r"\b(mkfs|diskpart)\b", # 磁盘操作
r"\bdd\s+if=", # dd 裸设备
r">\s*/dev/sd", # 写磁盘设备
r"\b(shutdown|reboot|poweroff)\b", # 关机重启
r":\(\)\s*\{.*\};\s*:", # fork bomb
]内置工具
AgentLoop._register_default_tools() 注册默认工具:
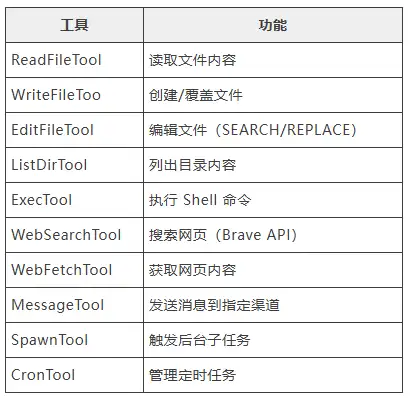
工具执行流程
LLM 返回 tool_calls
│
▼
ToolRegistry.execute(name, arguments)
│
├─▶ 参数校验 (validate_params)
│ 对照 JSON Schema 检查类型、必填、范围
│
└─▶ 执行工具 (execute)
│
▼
返回结果字符串
│
▼
添加到 messages:
{"role": "tool", "tool_call_id": "...", "name": "...", "content": "..."}9.2 重点工具Shell介绍
ExecTool 核心解析
重要节点的技术流程
┌─────────────────────────────────────────────────────────────────────────────┐
│ ExecTool 执行流程 │
└─────────────────────────────────────────────────────────────────────────────┘
LLM 调用 exec(command="...", working_dir="...")
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ 1. 参数处理 │
├─────────────────────────────────────────────────────────────────────────────┤
│ cwd = working_dir or self.working_dir or os.getcwd() │
│ env = os.environ.copy() + path_append │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ 2. 安全检查 (_guard_command) │
├─────────────────────────────────────────────────────────────────────────────┤
│ • 正则匹配 deny_patterns (危险命令) │
│ • 白名单检查 allow_patterns (可选) │
│ • 路径遍历检测 (..) │
│ • 工作区外路径检测 (restrict_to_workspace) │
│ │
│ 返回: None (通过) 或 错误信息 (拦截) │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ 3. 命令执行 │
├─────────────────────────────────────────────────────────────────────────────┤
│ process = asyncio.create_subprocess_shell( │
│ command, │
│ stdout=PIPE, │
│ stderr=PIPE, │
│ cwd=cwd, │
│ env=env, │
│ ) │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
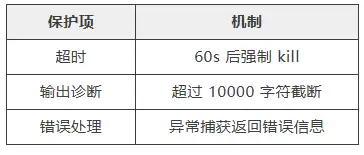
│ 4. 超时控制 │
├─────────────────────────────────────────────────────────────────────────────┤
│ await asyncio.wait_for(process.communicate(), timeout=60) │
│ │
│ 超时处理: │
│ • process.kill() 杀死进程 │
│ • process.wait() 等待完全终止 │
│ • 返回超时错误 │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ 5. 输出处理 │
├─────────────────────────────────────────────────────────────────────────────┤
│ • stdout/stderr 解码 (UTF-8, errors=replace) │
│ • 拼接 stdout + stderr │
│ • 附加 exit code │
│ • 截断超长输出 (max 10000 chars) │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
返回结果字符串支持的语言
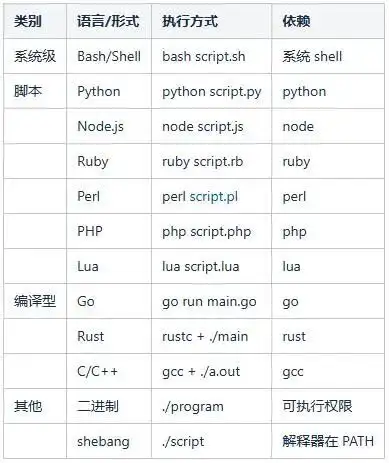
核心原理:create_subprocess_shell() 调用系统默认 shell,可执行任何系统支持的脚本。
9.3 安全机制
危险命令拦截
deny_patterns = [
r"\brm\s+-[rf]{1,2}\b", # rm -r, rm -rf
r"\bdel\s+/[fq]\b", # Windows del /f
r"\brmdir\s+/s\b", # Windows rmdir /s
r"(?:^|[;&|]\s*)format\b", # format 磁盘
r"\b(mkfs|diskpart)\b", # 磁盘操作
r"\bdd\s+if=", # dd 裸设备
r">\s*/dev/sd", # 写磁盘设备
r"\b(shutdown|reboot|poweroff)\b", # 关机重启
r":\(\)\s*\{.*\};\s*:", # fork bomb
]白名单模式(可选)
allow_patterns = [r"^git", r"^npm", r"^python"]
# 只有匹配这些模式的命令才能执行路径限制(可选)
restrict_to_workspace = True # 只能访问工作区
# • 禁止 .. 路径遍历
# • 禁止访问工作区外的绝对路径运行时保护
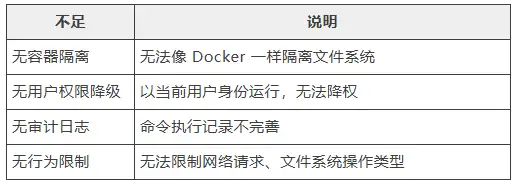
9.4 目前的不足
无真正沙箱

正则绕过风险
# 可被绕过的模式
r"\brm\s+-[rf]{1,2}\b"
# 绕过方式
rm -rf / # 空格可被特殊字符分割
$(rm -rf /) # 命令替换
`rm -rf /` # 反引号其他风险
9.5 总结
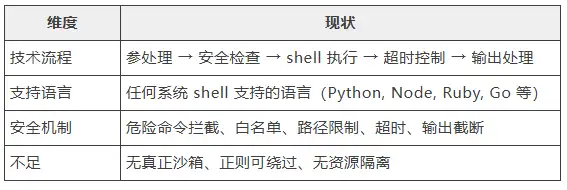
Nanobot只有简单的安全校验,没有沙箱环境。在 OpenClaw 的架构里,则有沙箱能力。
十、回顾与总结
通过对 Nanobot 源码的剖析,我们已经清晰地看到各类大龙虾华丽外衣下的底层逻辑。
总结来说:
- 技术上没有魔法,只有工程的巧妙组合:Nanobot并非依赖某种颠覆性的 AI 新算法,而是通过“大模型 API + 循环控制 + 本地脚本执行”的经典架构,完成了从“动嘴”到“动手”的跨越。
- 真正的突破在于“场景与体验”:它打破了云端沙盒的限制,将 AI 真正下放到了用户的个人电脑中。这种“看得见、摸得着”且能实际操控系统的专属感,才是它引爆科技圈的根本原因。
- OpenClaw 的爆火给我们最大的启示是:在底层大模型能力日益强大的今天,如何让 AI 打破边界,与用户的真实环境(系统、文件、应用)产生深度的物理或逻辑交互,提供更具实体感和专属感的应用体验,将是下一代智能体(Agent)落地的核心方向。
备注:Nanobot可能与OpenClaw还有一些细微差异,因此仅能作为参考,请读者注意。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号