vivo GPU容器与 AI 训练平台探索与实践
作者:互联网容器团队-Chen Han、AI 研发团队 - Liu Dong Yang
在大规模GPU容器集群与模型训练场景,面临稳定性和资源利用率等多重挑战。本文展示vivo GPU平台的总体架构,介绍容器平台在大规模GPU容器集群稳定性建设措施,以及探索多种GPU容器降本提效的解决方案。分享AI工程训练平台大规模训练稳定性建设,及GPU利用率提升实践经验。
本文为2025年 vivo 开发者大会互联网技术专场分享内容之一,在微信公众号“vivo互联网技术”对话框回复【2025VDC】获取 2025VDC 互联网技术会场议题相关资料。
1分钟看图掌握核心观点👇
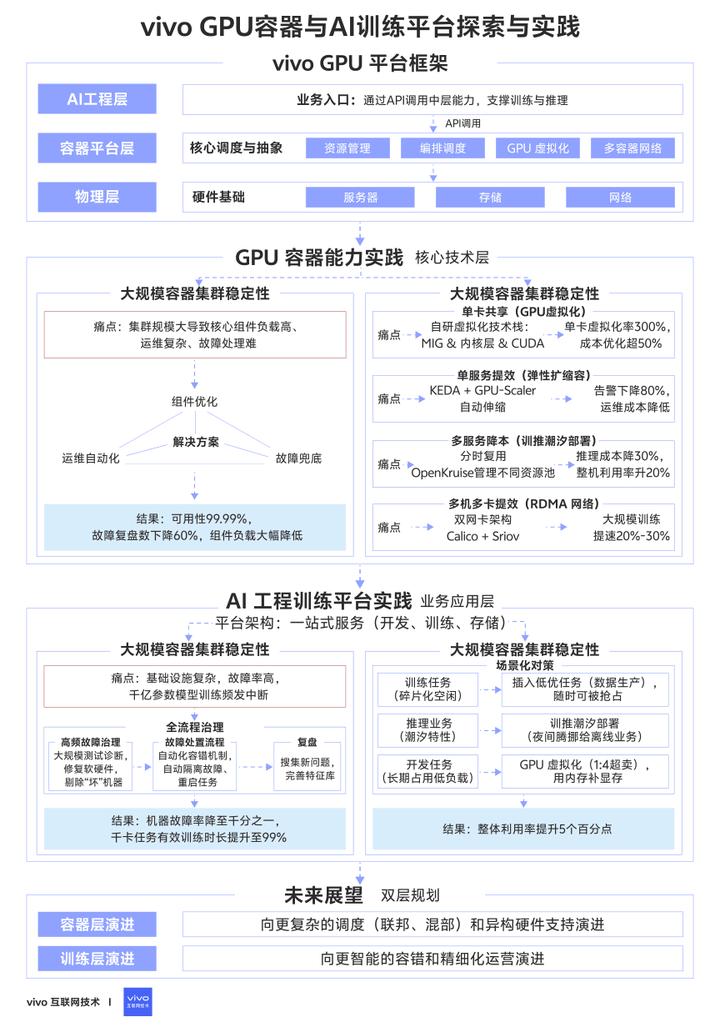
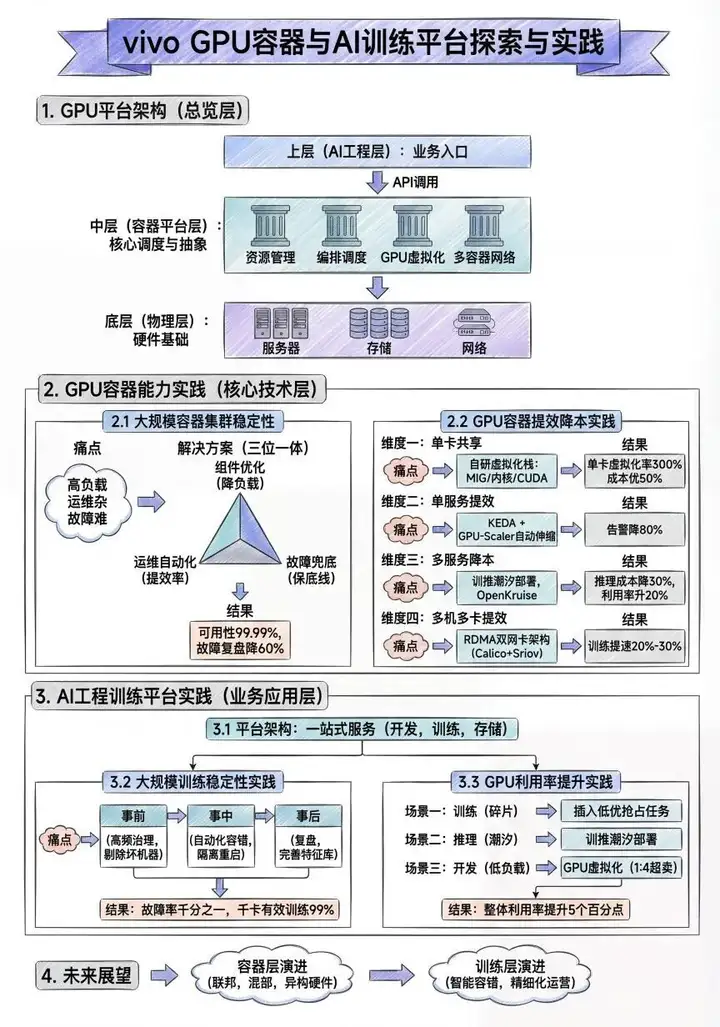
图1 VS 图2,您更倾向于哪张图来辅助理解全文呢?欢迎在评论区留言
一、GPU平台架构
vivo的GPU平台由物理层、容器平台层与AI工程层三方面构成。由多种GPU服务器和分布式存储以及高性能网络等基础设施,构成了可靠的物理层。容器平台层的GPU容器能力,主要包含了资源管理、编排调度、GPU虚拟化与多容器网络这四个方面。
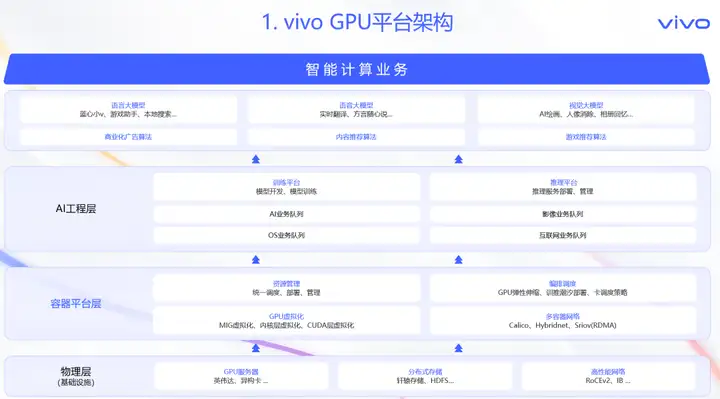
其中资源管理,表现为多种架构资源池的部署与管理能力。编排调度能力,由GPU弹性伸缩、训推潮汐部署以及多种卡调度策略组成。自研的GPU虚拟化囊括了业界主流的MIG虚拟化、内核层虚拟化以及CUDA层虚拟化三种技术。由传统的Underlay网络以及SRIOV的RDMA直通网络,组成了丰富的容器网络架构。容器平台提供了开放的API接口,为AI工程层的训练和推理平台,提供了坚实的算力底座。通过训练和推理平台,支撑公司内的智能计算业务。
二、GPU容器能力实践
GPU容器能力实践分为两个模块,首先是大规模容器集群稳定性建设,其次是GPU容器提效降本方案。先了解下容器平台在大规模容器集群场景,如何进行稳定性建设的。
2.1 大规模容器集群稳定性
集群稳定性是一切的基石。当集群规模大时,任务多,调度频繁,导致核心组件负载激增,极易发生集群崩溃。随着节点规模扩大,运维复杂度呈指数级增长,日常运维工作繁重,发现问题不及时。同时故障处理也面临严峻挑战,故障中涉及的复杂场景多,故障处理的难度大。稳定性建设需要解决上述问题。

为了解决高频调度导致的核心组件高负载问题,我们针对Apiserver、etcd、CoreDNS,这3个核心组件进行了架构和性能优化,具体的方案如图所示。通过这些优化手段提升了组件性能,并且降低了组件负载,有利于大规模集群的平稳运行。

为了减轻集群运维负担,我们重点建设了自动化节点管理方案。把重复性的运维事项自动化。同时我们还完善了监控告警体系,开发了自动化巡检功能,使运维人员能够及时发现集群问题,快速介入,处理潜在风险,保障集群能够长久稳定运行。

故障处理是集群稳定的兜底措施,我们针对多个核心组件都做了,各类故障处理预案。结合可能存在的故障特点,构造故障场景,进行故障恢复演练,确保故障发生时,能够第一时间找到合理的解决方案,准确的处理问题。

通过上述的措施,在集群稳定性方面取得了不错的效果,首先日常的集群可用性稳定保持在99.99%水平,其次平台的年度故障复盘数相较于上一年下降60%。核心组件方面的优化也达到了不错效果,其中Apiserver的CPU负载下降70%,etcd提交延迟,从秒级缩短到毫秒级,CoreDNS的毛刺现象消失了,并且负载量下降了90%左右。

2.2 GPU容器提效降本实践
容器平台的核心竞争力之一就是助力业务提效降本,我们从不同业务维度,对GPU容器提效降本方案进行了探索。
- 首先在单卡维度,通过自研GPU虚拟化方案,使多个容器,互不干扰的共享一张卡资源。
- 其次是在单服务维度,使业务能够自动应对,负载变化的GPU弹性扩缩容方案。
- 在多服务维度,能够让推理服务和训练服务,分时复用整机资源的,训推潮汐部署方案。
- 最后是在多机多卡的分布式场景中,让GPU容器搭配RDMA网络,来解决跨节点通信的瓶颈问题。

2.2.1 单卡共享-GPU虚拟化
如何让一张卡同时运行多个容器又不互相干扰,就涉及到GPU虚拟化技术。GPU虚拟化一直是AI云原生领域的热门话题之一,各大云厂商都有成熟的解决方案售卖。

vivo容器平台的自研GPU虚拟化方案,主要为了解决业务的三大痛点,
- 首先是部分推理业务负载偏低,无法有效用满整卡资源,需要通过共享部署方式,减少资源总量,降低业务成本,提升利用率。
- 其次是不同业务共享同一张卡时,对于安全性以及隔离性的要求各不相同,就需要使用不同的GPU虚拟化技术来满足不同业务诉求。
- 最后在Dev开发机场景,用户使用频率偏低,需要通过显存超售,来提升资源复用率,但显存超售后又需要避免某个用户将显存耗尽,导致OOM错误影响同卡的其他用户。
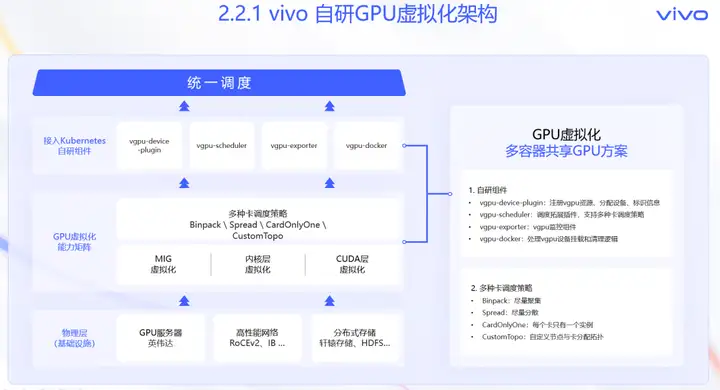
自研GPU虚拟化方案包含MIG虚拟化、内核层虚拟化、CUDA层虚拟化这三种技术。结合业务场景,提供了丰富的卡调度策略,例如尽量聚集的Binpack策略、尽量分散的Spread策略,每个卡只有一个实例的CardOnlyOne策略,以及自定义节点和卡分配关系的CustomTopo策略。通过自研模块与组件,接入Kubernetes体系,对外提供统一调度能力。
首先,MIG虚拟化技术,是基于Nvidia硬件提供的,切块组合能力,能够按规则把计算单元和显存单元进行组合,组成MIG实例挂载到容器内,提供完全独立的运行环境。MIG方案的优点是拥有Nvidia官方支持,可以集成到自研体系中。由于是在硬件层面实现的算力和显存限制,所以隔离性和安全性最好。缺点就是仅支持Ampere及以后架构的部分卡,而且限定了切分比例。主要应用场景是对算力隔离有强需求的线上业务。
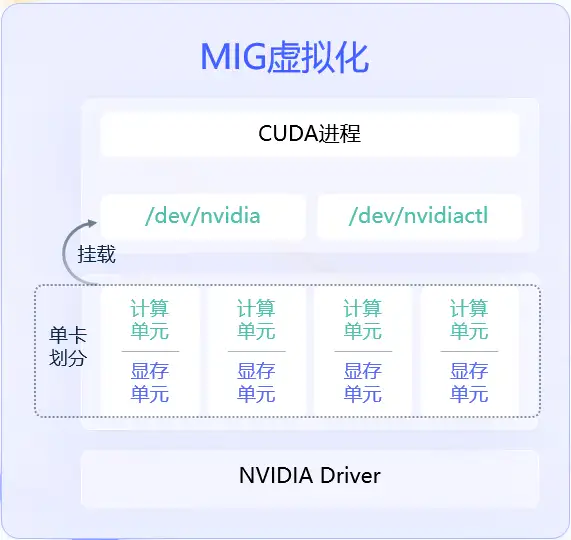
内核层虚拟化技术,是通过自研内核模块,创建虚拟字符设备替换原有的Nvidia字符设备,在内核态拦截IOCTL请求后,实现的算力和显存限制。优点是上层应用无感。并且内核态拥有良好的安全性。缺点是当前无开源方案,开发难度大,而且算力隔离的并不充分。主要应用场景是常规线上业务。

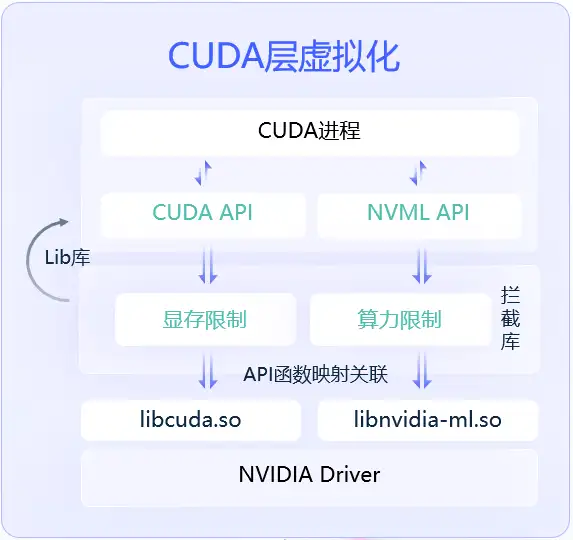
CUDA层虚拟化技术的原理:使用拦截库替换Nvidia Driver的原始库,建立拦截库与原始库的,API函数映射关系,从而拦截调用函数,实现算力和显存的限制。
优点是有开源方案,使用起来比较灵活。并且可以基于Nvidia提供的统一内存模型,开发显存超售能力。能够在显存不足时,使用内存替代,虽然处理速度下降,但是能够有效避免,显存OOM导致用户程序报错。
缺点是用户态导致安全性不足,并且算力隔离能力偏弱,主要应用场景是Dev开发机场景。
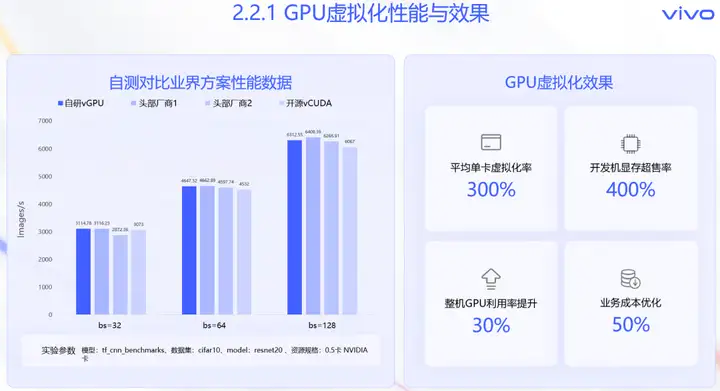
将自研的内核层虚拟化方案与业界方案,进行了自测性能对比,如图所示,可以看到自研方案在性能上,已经达到业界先进水平。业务使用该方案,与独占整卡部署相比较,平均单卡虚拟化率300%左右,就是把1张物理卡当3张卡使用,同时整机GPU利用率提升了30%+,成本优化超过50%。
2.2.2 服务提效-GPU弹性扩缩容
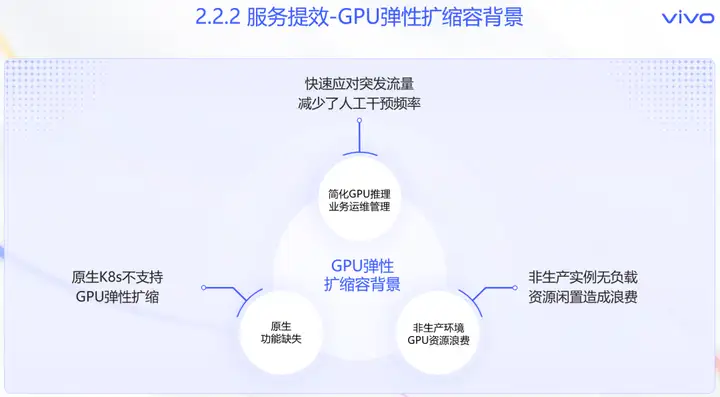
在单服务维度,如何帮助业务自动管理大量的GPU容器是提效的关键。我们引入了GPU弹性扩缩容方案。
- 首先弹性扩缩容能力,能够快速响应负载变化,自动调节实例数量,减少人工干预次数,有利于业务在突发场景的平稳运行。
- 其次是业务方在生产环境部署后,非生产环境的实例通常会闲置,这会浪费稀缺的GPU资源。
- 最后由于Kubernetes原生,并不支持GPU维度的弹性扩缩容,需要寻找合适的方案来满足业务诉求。
如图所示,我们是基于开源的KEDA框架,自研了GPU-Scaler组件,使用Prometheus中存储,来自DCGM-Exporter的GPU指标,汇聚为扩缩容事件,用于触发KEDA框架,调整实例个数,以此实现了GPU弹性扩缩容能力。
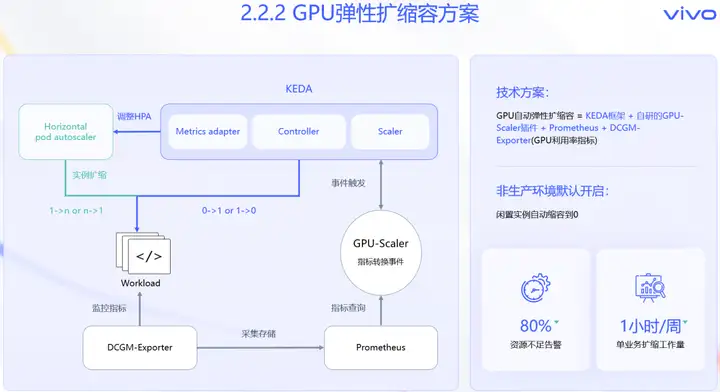
由于KEDA框架支持将Workload实例数缩容到0,所以在非生产环境部署的GPU业务,默认开启无负载时,自动缩容到零的功能,以此自动回收,长期闲置的GPU资源。
最终的使用效果,线上业务资源不足类告警,下降了80%,单业务平均减少约每周1小时的,扩缩容工作量,有效降低了GPU业务的运维成本。
2.2.3 多服务降本-训推潮汐部署
在多服务维度,训练服务的资源短缺问题,与推理服务,低峰时段资源空闲问题,相对突出。考虑让训练业务利用推理的空闲资源,即训推潮汐部署方案。
首先推理和训练业务都需要稳定的运行环境。而且推理业务潮汐特征明显,夜晚负载低,资源空闲多,导致平均利用率偏低。并且多机多卡训练任务,需要整机资源,且资源需求日益增长,采购新设备,难且慢,导致训练资源缺口明显。

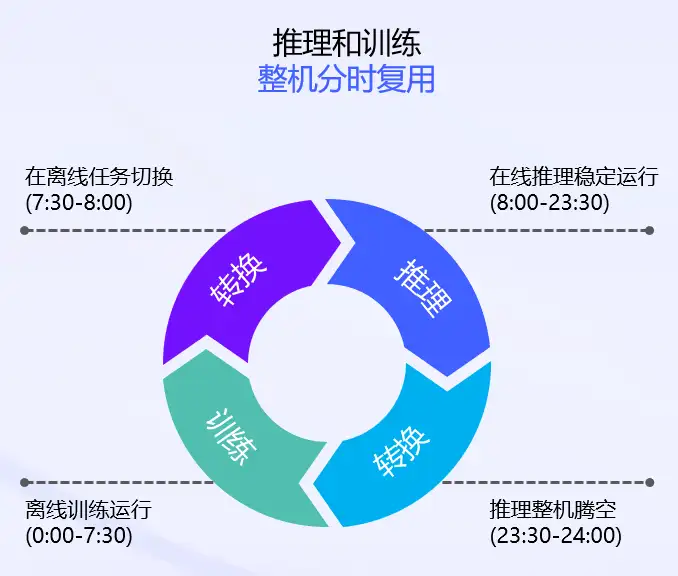
训推潮汐部署就是整机资源分时复用的逻辑,如图所示,推理业务在白天高负载时,稳定运行,在夜晚低峰时段,自动腾挪出空闲整机资源,借给训练业务使用。在清晨时段,训练业务结束,把整机资源还给推理业务,如此达到分时复用的效果。
如图所示。推理业务在部署前,需要评估保底负载容量。在部署时填入维持业务稳定的最少Pod数量。基于OpenKruise组件的,WorkloadSpread功能,管理不同的Subset,分别在稳定池和潮汐池中按需部署。同时配置CronHPA,定时缩容,自动调整副本数,到稳定Pod数量,优先删除潮汐池中的Pod。以此达到把潮汐池的节点整机腾空的效果。
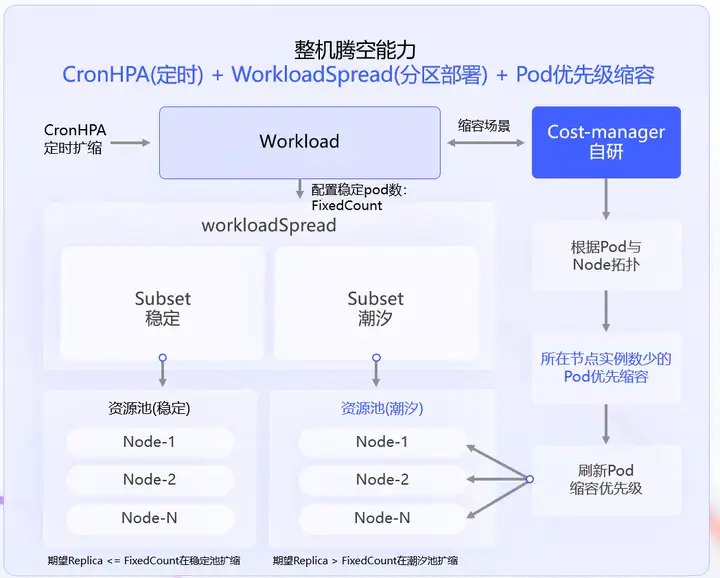
其中我们还针对Workload的缩容优先级进行了优化。当缩容发生时,结合Pod和节点的拓扑关系,把所在节点实例数少的Pod优先缩容,达到更快的腾空效果。
通过上述方案,训推潮汐部署的降本效果明显,使推理业务,成本下降30%,同时整机GPU利用率提升20%多,有效缓解了训练资源短缺问题。
2.2.4 多机多卡提效-容器RDMA高性能网络
当前分布式训练和推理业务,对算力和显存的需求巨大,单节点资源不足,需要使用多机多卡资源,那么网络通信容易成为性能瓶颈。RDMA技术允许GPU直接访问支持RDMA设备中的数据,无需经过主机CPU或内存,实现跨节点的零拷贝数据传输,有效减少了CPU开销和网络延迟。所以从多机多卡维度,使用RDMA技术是网络提效的有效措施。从容器平台角度,GPU容器更加需要结合RDMA技术,提供简单高效的解决方案,方便业务使用。

如图所示,RDMA容器有两个网卡,一个是使用Calico-CNI插件,通过veth创建的eth0网卡,对应的是Underlay网络。另一个是使用Sriov-CNI插件,通过VF创建的eth1网卡,对应的RoCE_v2或IB协议网络。我们引入了Multus-CNI组件,能够在单容器创建时,按需调用多种CNI插件。同时我们选择使用Spiderpool组件管理IP池,以及进行IP分配和路由策略配置。
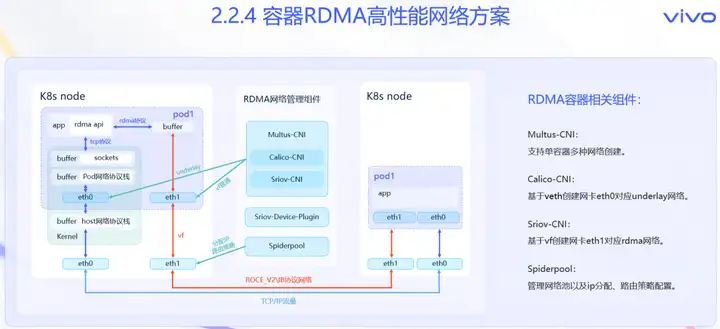
通过上述组件,在Kubernetes体系中实现了RDMA容器的全生命周期管理能力。基于容器RDMA能力,在大规模训练和推理场景,业务能够提速20%到30%之间,提升效果明显。
三、AI工程训练平台实践
3.1 训练平台整体架构
VTraining训练平台是由vivo AI计算平台团队打造的一站式大模型训练方案,它面向算法工程师,提供模型开发、模型训练和海量样本存储等能力。

VTraining底层是基于vivo容器平台、及高性能计算、网络、存储等基础设施之上构建,通过提供模型开发、模型训练、资产管理等能力,支撑公司的大模型训练业务。
像vivo手机的蓝心小V、相册等核心产品的大模型训练,都是在VTraining平台进行迭代的。
3.2 大规模训练稳定性实践
3.2.1 稳定性背景
稳定性问题是大规模训练的痛点。任务在大规模的同步训练过程中需要依赖计算、网络、存储、容器调度等复杂的基础设施环境,任何环节出问题都会导致任务中断,问题定位、恢复困难。
例如知名头部公司千亿参数大模型的大规模训练任务,平均每3小时触发一次意外中断。
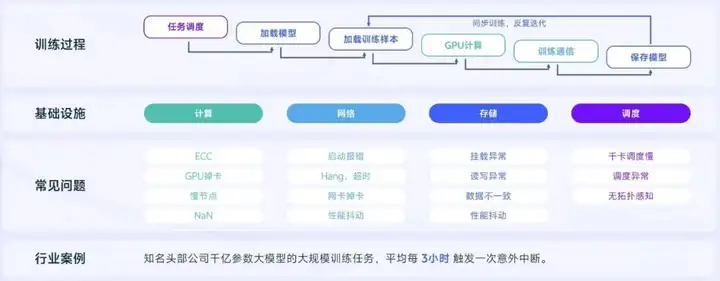
3.2.2 稳定性实践-高频故障专项治理
其中一个问题,是GPU集群投入使用初期机器故障率会很高,训练任务会经常被中断。为了降低机器故障率,我们进行了高频故障专项治理。首先对GPU集群进行了大规模测试诊断、然后进行高频故障统计和修复,把有问题的软硬件进行维修、替换、升级或修复。

3.2.3 稳定性实践-故障处置流程完善
另一个问题,是任务故障就是不可避免的,所以为了缩短任务中断时间,尽快恢复任务运行,我们对故障处置流程进行了重点建设完善。
- 训练前,我们会针对GPU机器、网络通信等环境进行大规模检测,剔除异常节点、慢节点等问题节点,降低故障风险。
- 训练中,会开启自动化容错机制,以便能及时发现基础设施或任务异常,快速进行故障定位和故障容错,自动隔离故障、自动重启恢复任务运行。
- 训练后,对新问题进行搜集分析,完善异常特征库,增强问题诊断能力,以便后续遇到类似的故障可以快速容错。

3.2.4 稳定性实践-效果与总结
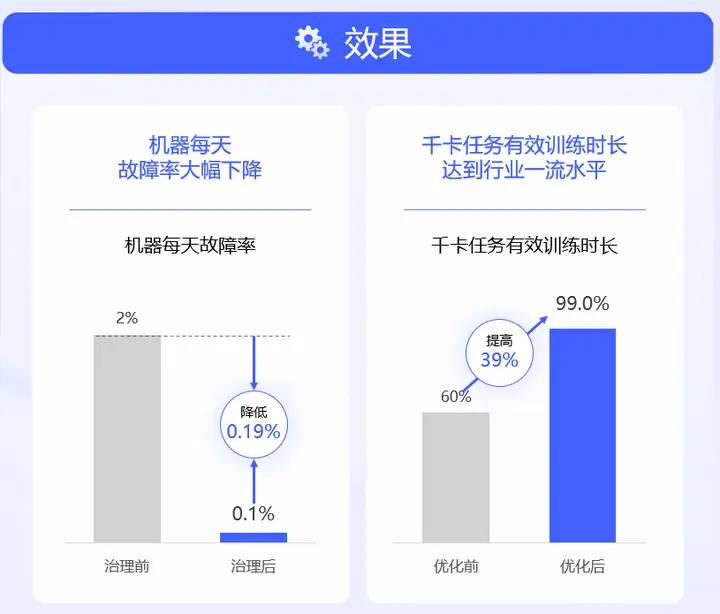
通过减少基础设施高频故障、完善任务故障处置流程两大措施,我们取得了良好效果:机器每天故障率由原来的百分之二下降到千分之一;千卡任务有效训练时长由原来的60%提升到99%,达到了行业一流水平。
同时我们也积累了相关的稳定性经验:
- GPU集群由不稳定到稳定,需要一个软硬件磨合过程。因为不同的软硬件环境会触发不同的稳定性问题。
- 大规模训练前,尽量剔除历史故障率高的机器。我们发现稳定的机器一般会一直很稳定,而故障率高的机器即使修复后出问题的概率也比较大。
- 提升任务有效训练时长,需结合基础设施、训练框架、平台容错机制综合优化。例如秒级监控告警能力、checkpoint持久化策略等等都需要进行持续深入的优化。
3.3 GPU利用率提升实践
3.3.1 GPU利用率提升-业务背景及问题
GPU是稀缺资源,但是差异化的业务场景下GPU难以高效利用,利用率提升困难。比如GPU场景常见业务形态:有训练任务、推理业务、数据生产、开发调试等等类型。他们各有特点:

- 训练任务虽然GPU利用率高,但是偶尔也会出现碎片化空闲资源,比如算法同学偶尔会将任务停下来排查问题,调下参数之类的操作,任务并不是一直不间断地在跑的。
- 推理业务有很明显的潮汐特性,白天流量高峰期GPU利用率高、到了夜间流量低峰期利用率会比较低。
- 数据生产任务属于离线任务,GPU利用率高、资源需求大、但难申请到资源;开发调试任务的话GPU利用率低并且要长期占用资源,导致GPU利用率长期低下。
所以不同的业务形态有不同的利用率特点,接下来介绍下我们的GPU利用率提升措施。
3.3.2 利用率提升措施一:低优任务
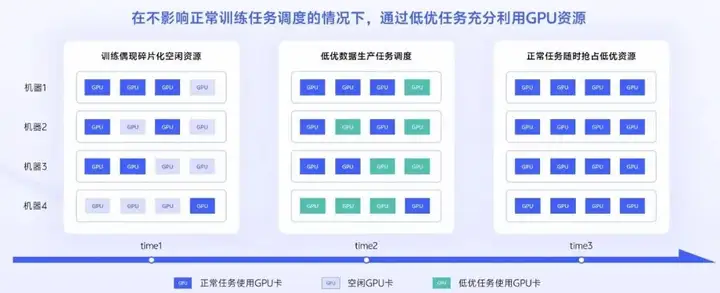
对于训练任务场景,偶现的碎片化空闲资源,我们 通过低优数据生产任务进行充分利用。如图所示,我们通过低优数据生产任务调度,复用训练场景偶现的碎片化资源,当正常任务需要资源时,可随时抢占低优资源,不会影响正常训练任务的调度。
3.3.3 利用率提升措施二:训推潮汐部署
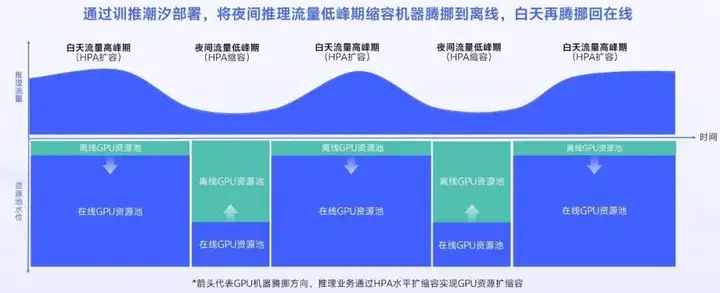
对于推理业务场景,在夜间流量低峰期可以释放大量GPU资源,我们通过训推潮汐部署给离线业务复用。如图所示,通过训推潮汐部署机制,我们将夜间推理流量低峰期缩容的机器腾挪到了离线GPU资源池,给离线业务使用,白天再腾挪回在线GPU资源池进行扩容,达到潮汐复用的目的。
3.3.4 利用率提升措施三:GPU虚拟化
对于开发任务场景,长期独占GPU资源且利用率低,我们通过vivo自研VGPU虚拟化技术,减少开发任务占用的物理GPU卡数,释放冗余算力。如图所示,我们可以将单机4卡GPU机器,通过开启VGPU虚拟出16卡VGPU,相当于一卡顶四卡。
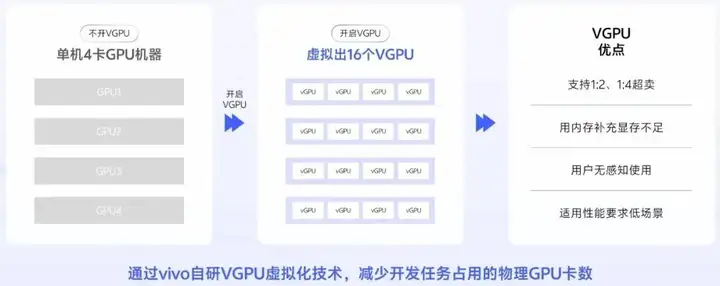
VGPU的优点是:可支持1:2、1:4超卖、还可以用内存补充显存不足,所以对用户是无感知使用的,很适用于开发任务这种对性能要求低的场景。
3.3.5 利用率提升总结与规划
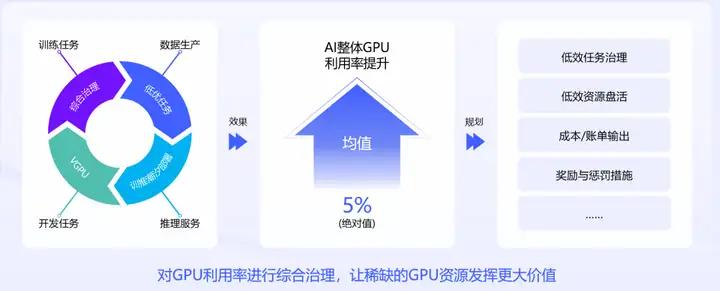
总之,训练平台通过低优任务、训推潮汐部署、GPU虚拟化等策略,深度适配差异化业务场景特性,实现了资源高效复用。AI整体GPU利用率均值绝对值提升了5个百分点,接近行业一流水平。
未来训练平台也会持续对GPU利用率进行综合治理。例如进行低效任务治理、低效资源盘活、成本账单统计、奖励与惩罚措施的实施等等,让稀缺的GPU资源发挥更大价值!
四、GPU平台未来展望
在容器平台层面,我们会从多集群联邦调度、在离线GPU混部、国产异构计算芯片支持、GPU资源池化等方面能力进行综合建设,支撑上层平台业务对GPU资源的高效利用。
训练平台层面,我们会增强故障预警、任务动态容错等能力,增强业务稳定性;同时完善对大模型训练全流程能力的支撑,以及对GPU资源进行更精细化的运营,从而让GPU业务更加稳定、资源利用更加高效!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号