CMU15-455 Lab2 - task4 Concurrency Index -并发B+树索引算法的实现
最近在做 CMU-15-445 Database System,lab2 是需要完成一个支持并发操作的B+树,最后一部分的 Task4 是完成并发的索引这里对这部分加锁的思路和完成做一个总结,关于 B+ 树本身的操作(插入、删除)之后再整理。
一些基础知识
索引的并发控制
并发控制协议是DBMS用来确保对共享对象进行并发操作的“正确”结果的方法。
协议的正确性标准可能会有所不同:
- 逻辑正确性:这意味着线程能够读取应允许其读取的值。
- 物理正确性:这意味着数据结构中没有指针,这将导致线程读取无效的内存位置。
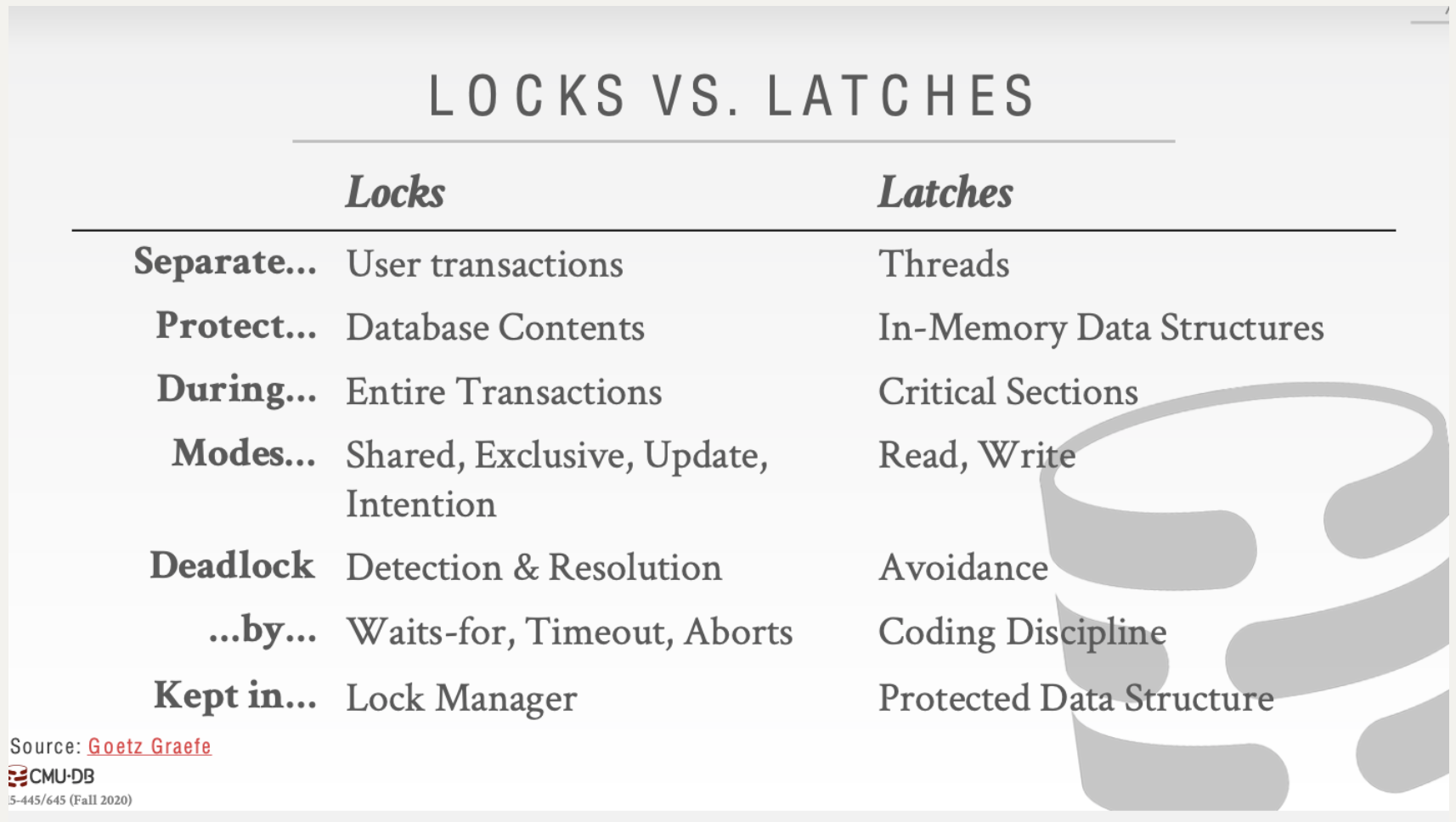
Lock 和 Latch
Lock
Lock 是一种较高级别的逻辑原语,可保护数据库的内容(例如,元组,表,数据库)免受其他事务的侵害。事务将在整个持续时间内保持锁定状态。数据库系统可以将查询运行时所持有的锁暴露给用户。锁需要能够回滚更改。
Latch
latch 是低级保护原语,用于保护来自其他线程的DBMS内部数据结构(例如,数据结构,内存区域)的关键部分。 latch 仅在执行操作期间保持。 latch 不需要能够回滚更改。 latch 有两种模式:
- READ:允许多个线程同时读取同一项目。一个线程可以获取读 latch ,即使另一个线程也已获取它。
- WRITE:仅允许一个线程访问该项目。如果另一个线程以任何模式保持该 latch ,则该线程将无法获取写 latch 。持有写 latch 的线程还可以防止其他线程获取读 latch
这部分 提供的 RWLatch 的实现真的写得好,放到末尾来参考
这里对他们的不同做一个比较:
Latch 的实现
用于实现 latch 的基础原语是通过现代CPU提供的原子比较和交换(CAS)指令实现的。这样,线程可以检查内存位置的内容以查看其是否具有特定值。如果是这样,则CPU将旧值交换为新值。否则,内存位置的值将保持不变。
有几种方法可以在DBMS中实现 latch 。每种方法在工程复杂性和运行时性能方面都有不同的权衡。这些测试和设置步骤是自动执行的(即,没有其他线程可以更新测试和设置步骤之间的值。
Blocking OS Mutex
latch(锁存器) 的一种可能的实现方式是OS内置的互斥锁基础结构。 Linux提供了mutex(fast user-space mutex ),它由(1) user space 中的自旋 latch 和(2)OS级别的 mutex 组成。
如果DBMS可以获取 user space latch ,则设置 latch 。即使它包含两个内部 latch ,它也显示为DBMS的单个 latch 。如果DBMS无法获取 user space latch ,则它将进入内核并尝试获取更昂贵的互斥锁。如果DBMS无法获取第二个互斥锁,则线程会通知OS锁已被阻塞,然后对其进行调度。
操作系统互斥锁通常是DBMS内部的一个不好的选择,因为它是由OS管理的,并且开销很大。
Test-and-Set Spin Latch (TAS)
自旋 latch 是OS互斥锁的更有效替代方法,因为它是由DBMS控制的。自旋 latch 本质上是线程在内存中尝试更新的位置(例如,将布尔值设置为true)。线程执行CAS以尝试更新内存位置。如果无法获取 latch ,则DBMS可以控制会发生什么。它可以选择重试(例如,使用while循环)或允许操作系统取消调度。因此,与OS互斥锁相比,此方法为DBMS提供了更多的控制权,而OS互斥锁无法获取 latch 而使OS得到了控制权。
Reader-Writer Latches
互斥锁和自旋 latch 不区分读/写(即,它们不支持不同的模式)。 DBMS需要一种允许并发读取的方法,因此,如果应用程序进行大量读取,它将具有更好的性能,因为读取器可以共享资源,而不必等待。
读写器 latch 允许将 latch 保持在读或写模式下。它跟踪在每种模式下有多少个线程保持 latch 并正在等待获取 latch 。读取器-写入器 latch 使用前两个 latch 实现中的一种作为原语,并具有其他逻辑来处理读取器-写入器队列,该队列是每种模式下对 latch 的队列请求。不同的DBMS对于如何处理队列可以具有不同的策略。
B+树加锁算法
为了能尽可能安全和更多的人使用B+树,需要使用一定的锁算法来讲 B+ 树的某部分锁住来进行操作。这里将使用 Lock crabbing / coupling 协议来允许多个线程同时访问/修改B+树,基本的思想如下:
- 获取 parent 的 latch
- 获取 child 的 lacth
- 如果 child 是 “安全的”,那么就可以释放 parent 的锁。“安全”指的是某个节点在子节点更新的时候不会 分裂 split 或者 合并 merge(在插入的时候不满,在删除的时候大于最小的大小)
当然,这里需要区分读锁和写锁,read latch 和 write latch
锁是在针对于每个 Page 页面上的,我们将对每个 内部页面或者根页面进行锁
推荐看 cmu-15-445 lecture 9 的例子,讲解的非常清楚,这里举几个例子:
例子
查找
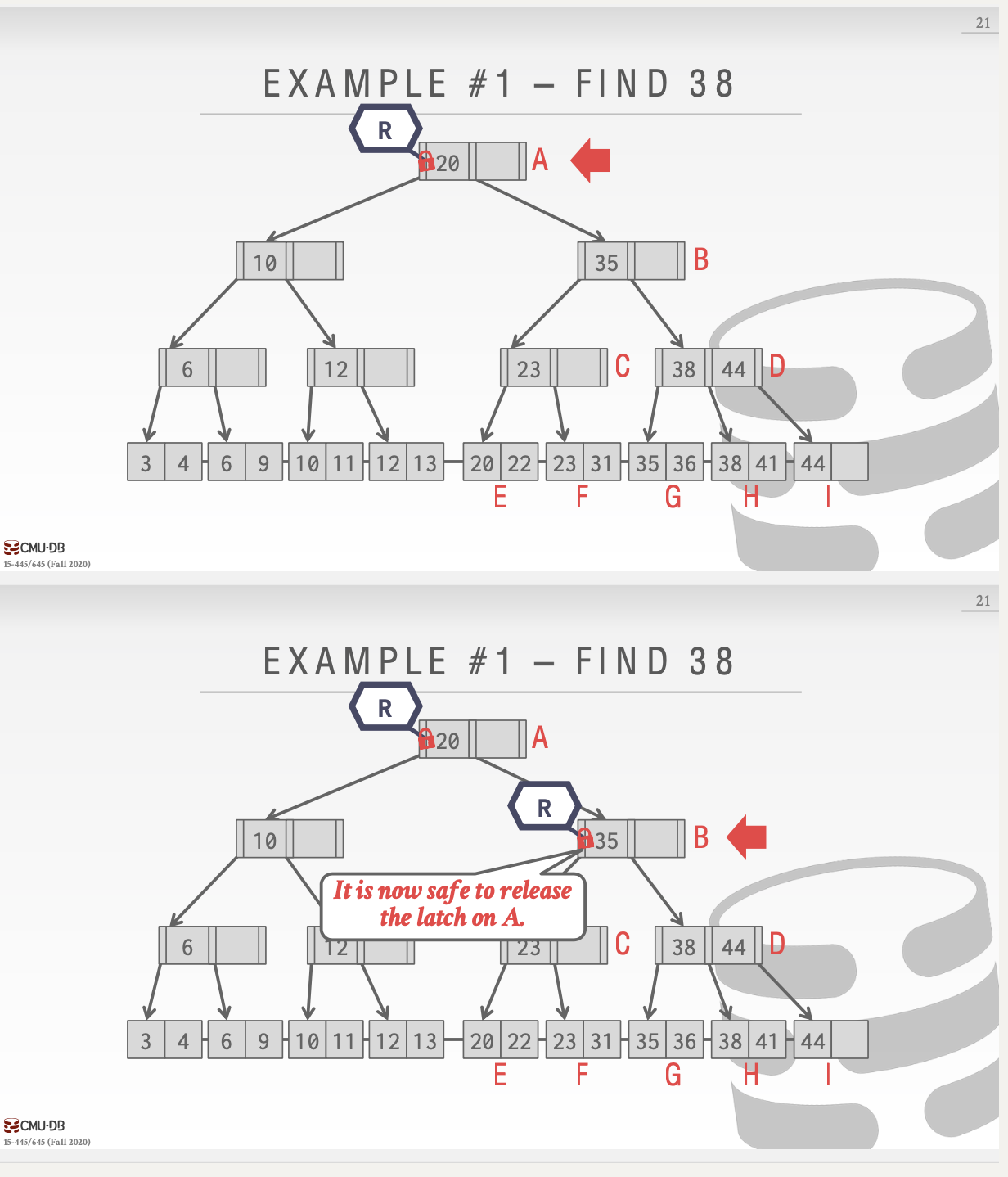
... 一步步向下加锁,如果获得了子页面,就将父亲的读锁直接释放
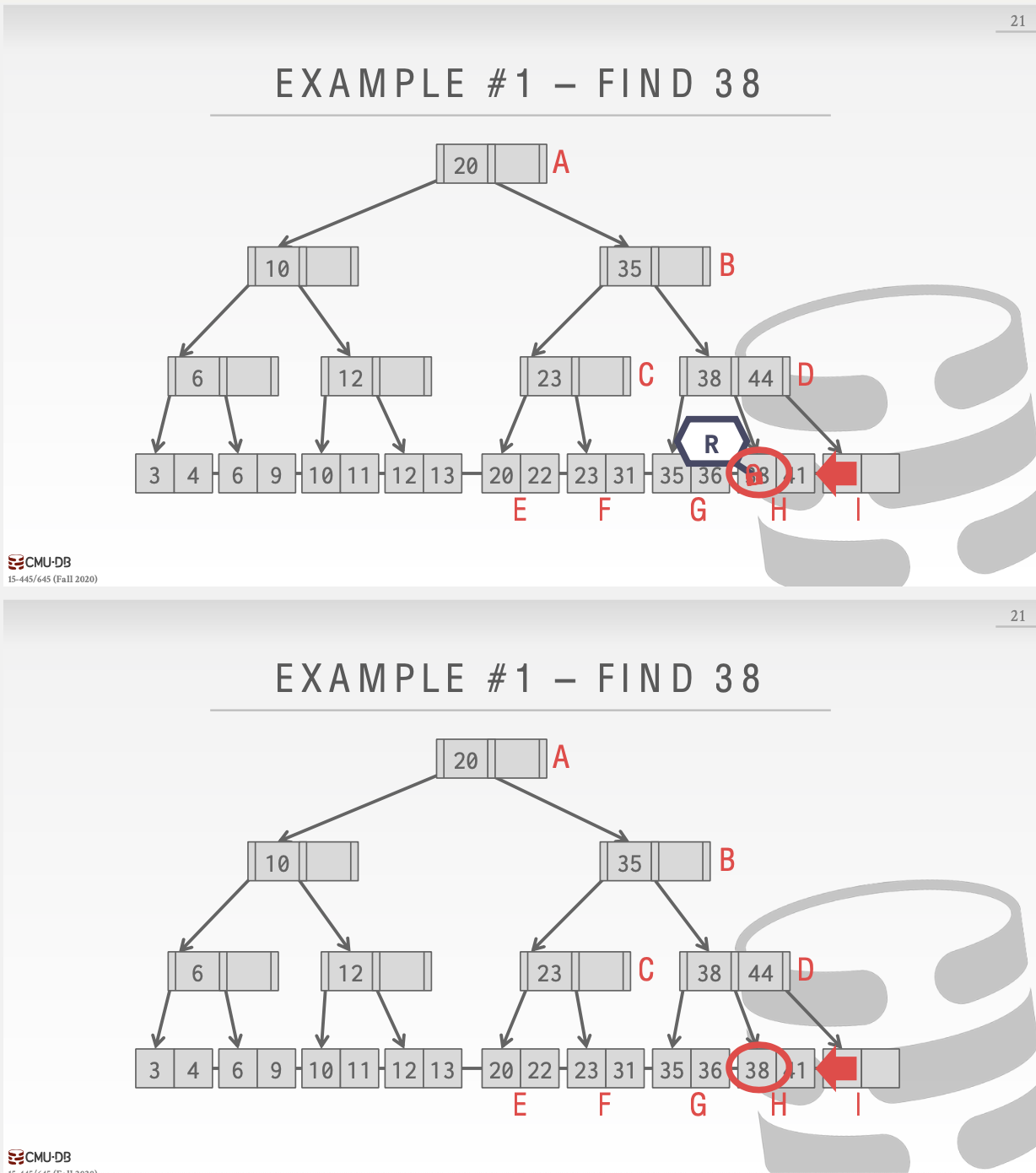
删除和插入
删除和插入其实都是写锁,区别不大,只是在具体的判断某个节点是否安全的地方进行不同的判断即可。这里举一个不安全插入的例子:
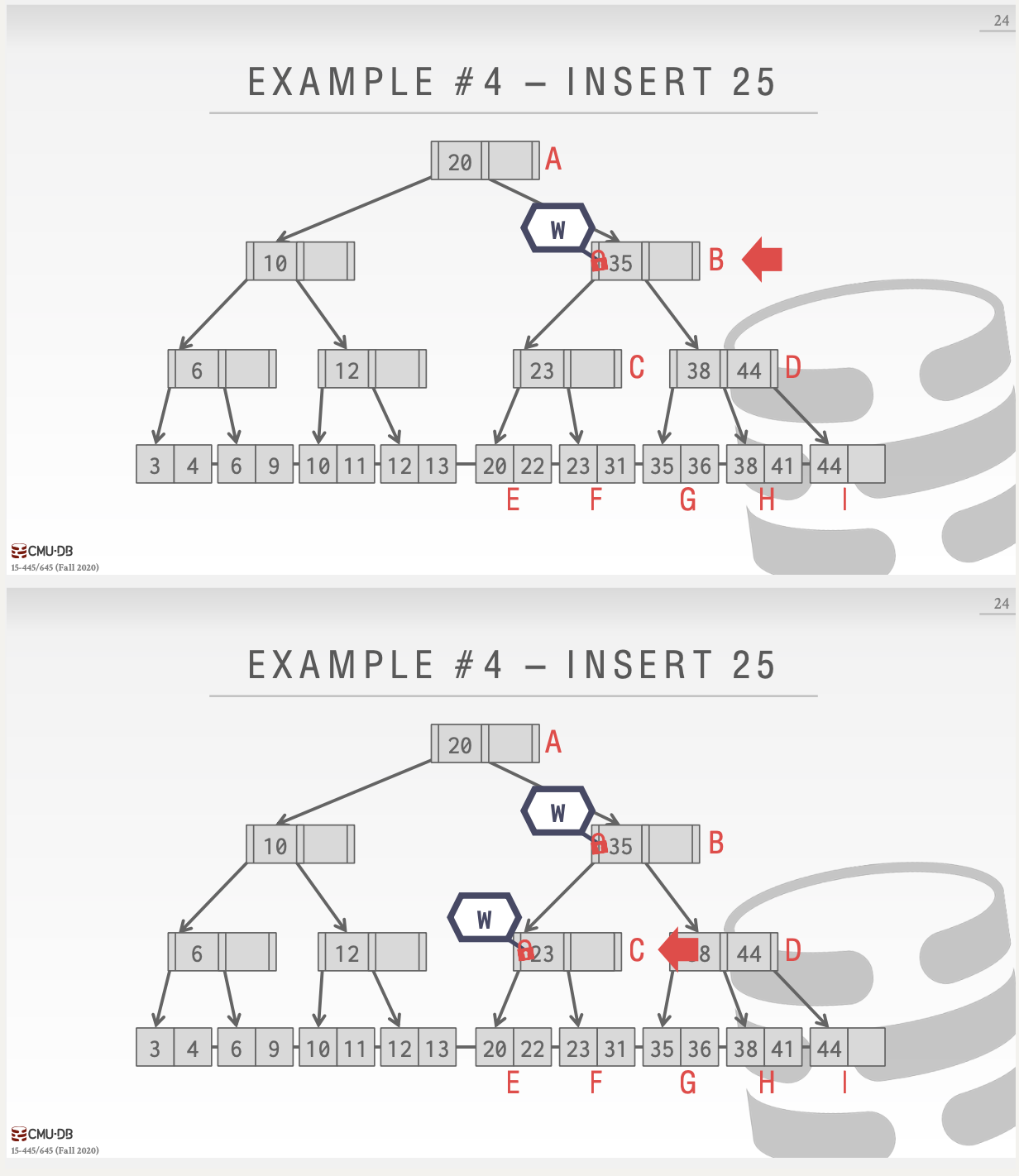


优化
我们上面聊到的其实是悲观锁的一种实现,也就是说如果处于不安全状态,我们就一定加锁(注意,不安全状态不一定),所以可能效率可能会稍微打一点折扣,这里介绍一下乐观锁的思路:
假定默认是查找多,大多数操作不会进行分裂 split 或者 合并 merge,不会修改到父亲页面,一直乐观地在树中采用读锁来遍历,直到真的发现会修改父亲页面之后,再次以悲观锁的方式执行一次写操作即可。
Leaf Scan
刚才提到的的线程以“自上而下”的方式获取 latch 。这意味着线程只能从其当前节点下方的节点获取 latch 。如果所需的 latch 不可用,则线程必须等待直到可用。鉴于此,永远不会出现死锁。
但是叶节点扫描很容易发生死锁,因为现在我们有线程试图同时在两个不同方向(即从左到右和从右到左)获取锁。索引 latch 不支持死锁检测或避免死锁。
所以解决这个问题的唯一方法是通过编码规则。叶子节点同级 latch 获取协议必须支持“无等待”模式。也就是说,B +树代码必须处理失败的 latch 获取。这意味着,如果线程尝试获取叶节点上的 latch ,但该 latch 不可用,则它将立即中止其操作(释放其持有的所有 latch ),然后重新开始操作。
我的想法是:可以来采用单方向的锁,或者是两个方向的叶子锁,假定一个方向的优先级问题,优先级高的可以抢占优先级较低方向的锁。
具体实现思路
transaction
每个线程针对数据库的操作都会新建一个事务,每个事务内都会执行不同的操作,在每次执行事务的时候对当前事务进行一个标记,用一个枚举类型表明本次事务是增删改查的哪一种:
/**
* 操作的类别
*/
enum class OpType { READ = 0, INSERT, DELETE, UPDATE };
自顶向下递归查找子页面
这是整个悲观锁算法的最基础的地方,也就是上方的例子中的内容,当我们递归去查找 Leaf Page 的时候就可以对“不安全的”页面加上锁,此后,就不需要再次加锁了,同时将所有锁住的 Page 利用 transaction 来保存,这样在最终修改结束之后统一释放不安全页面的读锁或者写锁即可。
这里对两个核心的函数进行说明:
递归查找子页面
递归查找子页面过程中需要加锁,将这个逻辑抽离出去,根据不同事务的操作来决定是否释放锁
/*
* Find leaf page containing particular key, if leftMost flag == true, find
* the left most leaf page
*/
INDEX_TEMPLATE_ARGUMENTS
Page *BPLUSTREE_TYPE::FindLeafPage(const KeyType &key, bool leftMost, Transaction *transaction) {
{
std::lock_guard<std::mutex> lock(root_latch_);
if (IsEmpty()) {
return nullptr;
}
}
// 从 buffer pool 中取出对应的页面
Page *page = buffer_pool_manager_->FetchPage(root_page_id_);
BPlusTreePage *node = reinterpret_cast<BPlusTreePage *>(page->GetData());
if (transaction->GetOpType() == OpType::READ) {
page->RLatch();
} else {
page->WLatch();
}
transaction->AddIntoPageSet(page);
while (!node->IsLeafPage()) { // 如果不是叶节点
InternalPage *internal_node = reinterpret_cast<InternalPage *>(node);
page_id_t child_page_id;
if (leftMost) {
child_page_id = internal_node->ValueAt(0);
} else {
child_page_id = internal_node->Lookup(key, comparator_);
}
Page *child_page = buffer_pool_manager_->FetchPage(child_page_id);
BPlusTreePage *new_node = reinterpret_cast<BPlusTreePage *>(child_page->GetData());
HandleRWSafeThings(page, child_page, new_node, transaction); // 处理这里的读写锁,父亲和孩子的都在这里加锁
page = child_page;
node = new_node;
}
return page; // 最后找到的叶子页面的包装类型
}
处理向下查找页面锁
/**
* 根据孩子页面是否安全判断是否能够释放锁
* 1. 读锁,给孩子加上锁之后给父亲解锁
* 2. 写锁,孩子先加写锁,然后判断孩子是否安全,安全的话释放所有父亲的写锁,然后将孩子加入到 PageSet 中
*/
INDEX_TEMPLATE_ARGUMENTS
void BPLUSTREE_TYPE::HandleRWSafeThings(Page *page, Page *child_page, BPlusTreePage *child_node,
Transaction *transaction) {
auto qu = transaction->GetPageSet();
if (transaction->GetOpType() == OpType::READ) {
child_page->RUnlatch(); // 给孩子加锁
ReleaseAllPages(transaction);
transaction->AddIntoPageSet(child_page); // 将孩子加入到 PageSet 中
} else if (transaction->GetOpType() == OpType::INSERT) {
child_page->WLatch(); // 给孩子加上读锁
if (child_node->IsInsertSafe()) { // 孩子插入安全,父亲的写锁都可以释放掉了
ReleaseAllPages(transaction);
}
transaction->AddIntoPageSet(child_page);
} else if (transaction->GetOpType() == OpType::DELETE) {
child_page->WLatch();
if (child_node->IsDeleteSafe()) {
ReleaseAllPages(transaction);
}
transaction->AddIntoPageSet(child_page);
}
}
统一释放与延迟删除页面
将所有加上锁的页面加入到 transaction 的pageset 中,最终根据读写事务的不同来统一释放锁以及Unpin操作。
/**
* 事务结束,释放掉所有的锁
*/
INDEX_TEMPLATE_ARGUMENTS
void BPLUSTREE_TYPE::ReleaseAllPages(Transaction *transaction) {
auto qu = transaction->GetPageSet();
if (transaction->GetOpType() == OpType::READ) {
for (Page *page : *qu) {
page->RUnlatch();
buffer_pool_manager_->UnpinPage(page->GetPageId(), false);
}
} else {
for (Page *page : *qu) {
page->WUnlatch();
buffer_pool_manager_->UnpinPage(page->GetPageId(), true);
}
}
(*qu).clear();
// 延迟删除到事务结束
auto delete_set = transaction->GetDeletedPageSet();
for (page_id_t page_id : *delete_set) {
buffer_pool_manager_->DeletePage(page_id);
}
delete_set->clear();
}
针对 root_page_id
由于在好几个地方会修改 root_page_id,所以在访问和修改 root_page_id 的时候,需要额外使用一个同步变量来是这些进程互斥。
std::mutex root_latch;
Unpin 操作的统一
多线程访问页面有一个很重要的点,那就是需要在不需要使用页面的时候 Unpin 掉,此时 buffer pool 才能正确的执行替换算法。在出现多线程之后,将所以需要加锁页面的释放 Unpin 操作统一到 transaction 的结束阶段即可。
其他特殊情况
处理并发确实是一个比较难的事情,需要考虑到各种情况,这里再说明几个容易出错的可能:
- 第一个事务,安全的删除某个叶子节点 A,同时第二个事务不安全的删除第一个事务叶子节点相邻节点 B,此时B 可能会找兄弟节点 A 借元素或者是合并,所以此时 B 需要获得 A 的写锁才能够继续进行
关于测试用例的一点吐槽
不得不吐槽一下 lab2b 的几个 Task 的测试用例是真的拉跨,绝大多数 bug 都检测不出来,只能自己构建大数据的测试用例,建议自己构造 1,000,000 长度的测试用例来测试B+树在大数据的压力下能够正确执行页面替换算法,能否正确的执行悲观锁算法,是否会出现死锁,只有经过这样的测试才能验证B+树的正确性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号