数据标注&&YOLO体验&&机器学习
数据标注真的费时间
275张照片用时一个半小时
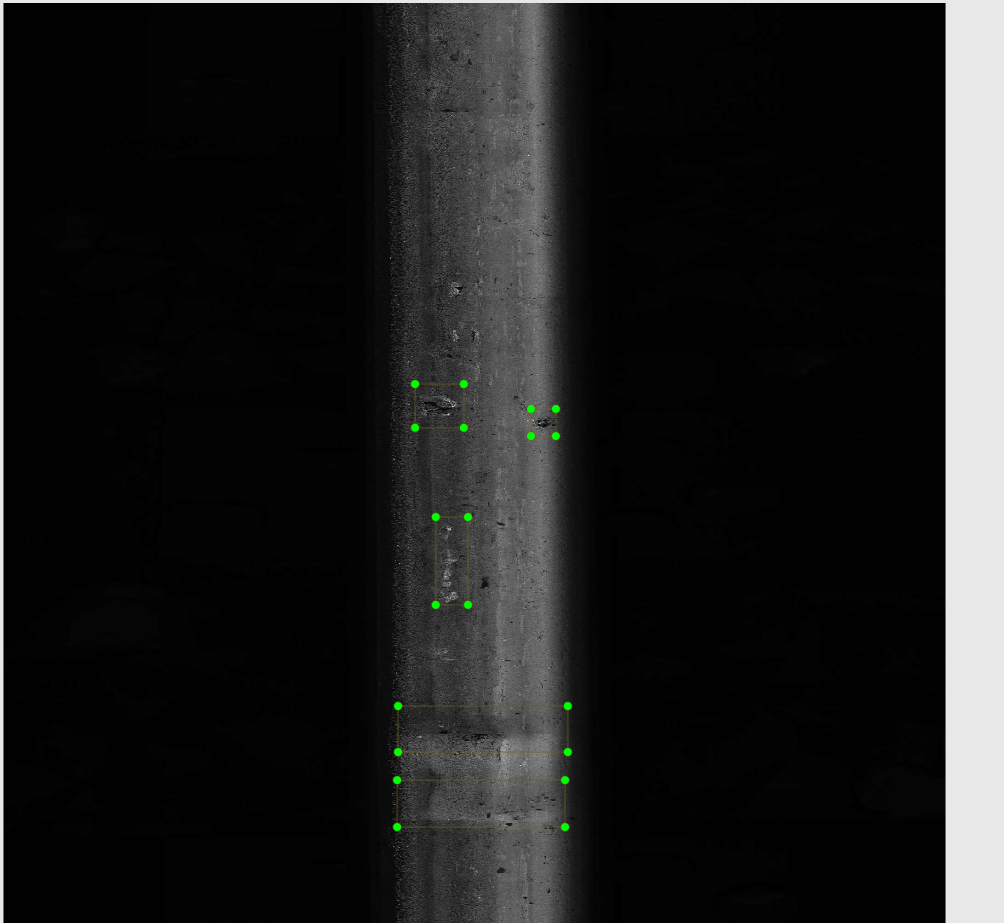
接触yolo

50轮

一开始验证集忘记标注了 所以 no labels found in detect set
标注好之后就可以了

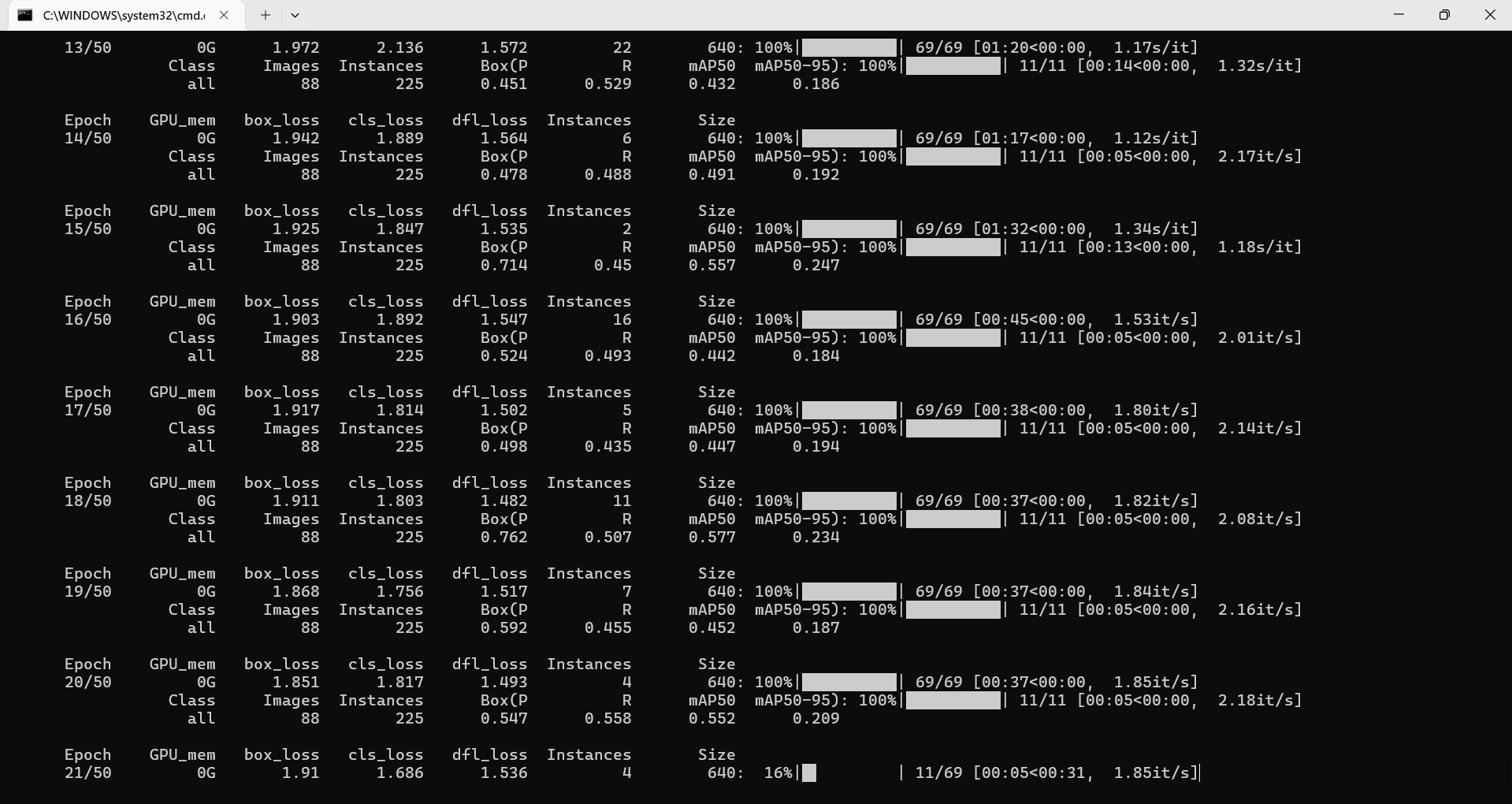
准确率逐步提升 泪目



这就是机器学习的一种 我丢
监督式目标检测的核心训练范式
其本质是通过标注数据构建强监督信号,驱动 YOLO 模型完成从图像特征空间到目标检测空间的映射学习,具体可拆解为以下环节:
标注的专业定位与规范
标注是为目标检测任务构建结构化监督数据集的过程,核心是将原始图像的未结构化像素信息转化为模型可学习的结构化标签
对于 YOLO 系列模型,标注需遵循严格格式:每张图像对应一个.txt标签文件,每行对应一个目标实例格式为class_id x_center y_center width height,其中x_center、y_center、width、height均为归一化到 [0,1] 区间的坐标值(以图像左上角为原点)。
这些标签构成了模型训练的ground truth(真实值),为后续损失计算提供了绝对参考标准。
YOLO 迭代训练的核心机制
YOLO 作为单阶段目标检测模型,其网络架构由Backbone(特征提取)+ Neck(特征融合)+ Head(检测输出)三部分组成,迭代训练的本质是基于梯度下降的端到端参数优化过程 核心流程如下:
初始化:对网络参数(卷积核权重、偏置等)进行随机初始化,此时模型处于 “无知识” 状态,检测输出完全随机。
前向传播:将标注图像输入模型,Backbone 通过堆叠卷积层提取多尺度视觉特征(如边缘、纹理、语义特征);Neck 通过 FPN/SPPF 等结构融合多尺度特征,提升对不同大小目标的检测能力;Head 基于融合特征直接输出检测张量,包含目标边界框坐标、置信度、类别概率三类预测值。
损失计算:通过 YOLO 专用损失函数(如 YOLOv5 的 CIoU Loss + BCEWithLogitsLoss),量化预测值与 ground truth 的偏差,损失函数数学上可表示为三类损失的加权和
反向传播与参数更新:基于链式法则,将损失值反向传递至网络各层,计算参数的梯度;通过优化器(如 SGD、AdamW)按照梯度方向更新参数,最小化损失值。
迭代收敛:重复 “前向传播 - 损失计算 - 反向传播” 流程,直至损失函数收敛(训练集与验证集损失均趋于稳定),此时模型完成了从 “特征 - 检测结果” 的映射学习,具备泛化能力
二、 拟合、过拟合的专业定义与辨析
这三个概念的核心是描述模型泛化能力与数据规律、模型复杂度的关系,泛化能力定义为模型在未见测试集上的预测精度。
拟合(Fitting,理想状态)
又称有效拟合或适度拟合,指模型复杂度与数据的真实分布规律完全匹配,能够准确捕捉数据的本质特征,而非噪声或局部特例。
量化表现为:训练集误差(经验风险)与测试集误差(泛化风险)均处于较低水平,且两者差值极小。
对于 YOLO 训练,拟合的表现是:训练集与验证集的 mAP(平均精度均值)同步上升,最终趋于稳定;模型对新图像中的目标,既能准确框定位置,又能正确分类。
过拟合(Overfitting,病态状态)
指模型复杂度远超数据真实规律,在学习过程中不仅捕捉了数据的本质特征,还过度拟合了训练集的噪声、异常值或局部特例,导致泛化能力急剧下降。
量化表现为:训练集误差极低,但测试集误差陡增,两者差值显著扩大
对于 YOLO 训练,过拟合的典型表现是:训练 loss 持续下降,而验证 loss 先降后升;训练集 mAP 接近 100%,但测试集 mAP 大幅回落(比如训练集 mAP=0.95,测试集 mAP=0.6)
常见诱因包括:训练数据集规模不足、模型结构过于复杂(如 Backbone 层数过多)、训练轮次过多(Epoch 过大)、未施加正则化约束等
补充:欠拟合(Underfitting,病态状态)
与过拟合相反,指模型复杂度低于数据真实规律,无法充分捕捉数据的本质特征,导致模型 “学不会” 核心规律。
量化表现为:训练集与测试集误差均处于较高水平。
对于 YOLO 训练,欠拟合的表现是:训练集与验证集的 loss 均居高不下,mAP 始终处于低位;模型甚至无法准确识别训练集中的目标
常见诱因包括:模型结构过于简单、训练轮次不足、特征提取能力薄弱等。
加油!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号