2023 级课堂测试试卷—数据分析
课程名称: 大型数据库应用技术 任课教师: 孙静 考试时间: 90 分钟
Result文件数据说明:
Ip:106.39.41.166,(城市)
Date:10/Nov/2016:00:01:02 +0800,(日期)
Day:10,(天数)
Traffic: 54 ,(流量)
Type: video,(类型:视频video或文章article)
Id: 8701(视频或者文章的id)
测试要求:
1、 数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中。
两阶段数据清洗:
(1)第一阶段:把需要的信息从原始日志中提取出来
ip: 199.30.25.88
time: 10/Nov/2016:00:01:03 +0800
traffic: 62
文章: article/11325
视频: video/3235
(2)第二阶段:根据提取出来的信息做精细化操作
ip--->城市 city(IP)
date--> time:2016-11-10 00:01:03
day: 10
traffic:62
type:article/video
id:11325
(3)hive数据库表结构:
create table data( ip string, time string , day string, traffic bigint,
type string, id string )
2、数据分析:在HIVE统计下列数据。
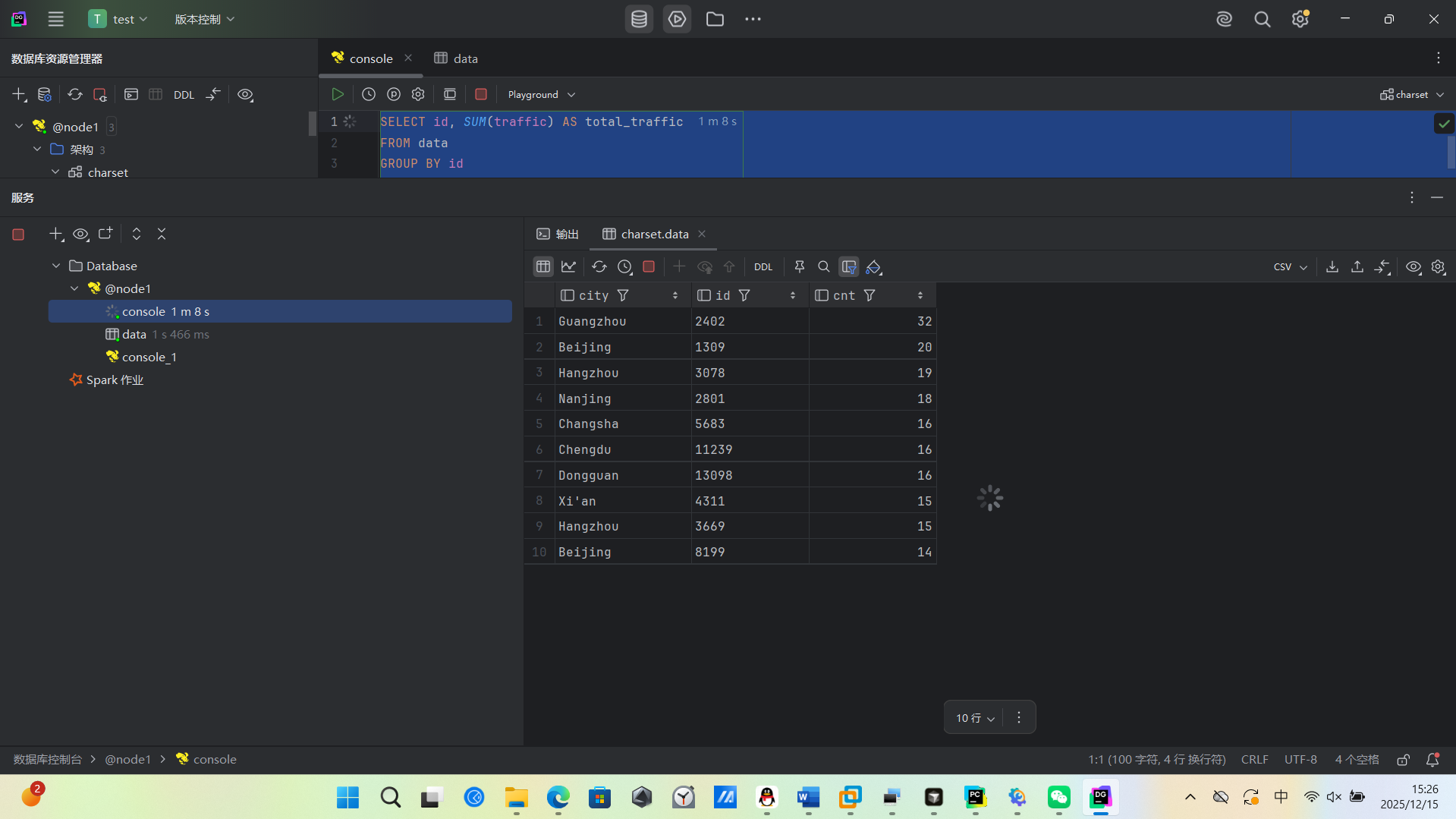
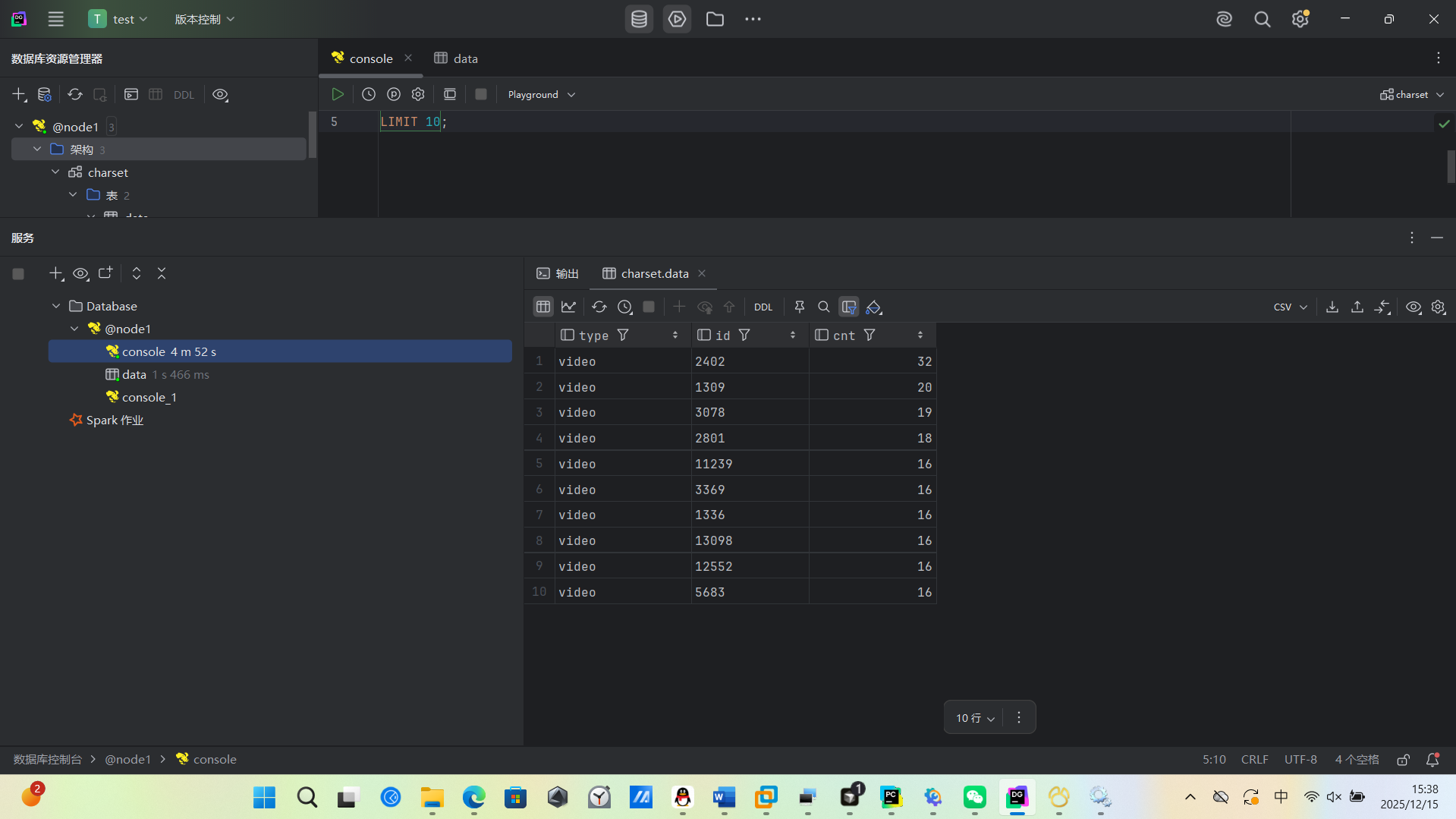
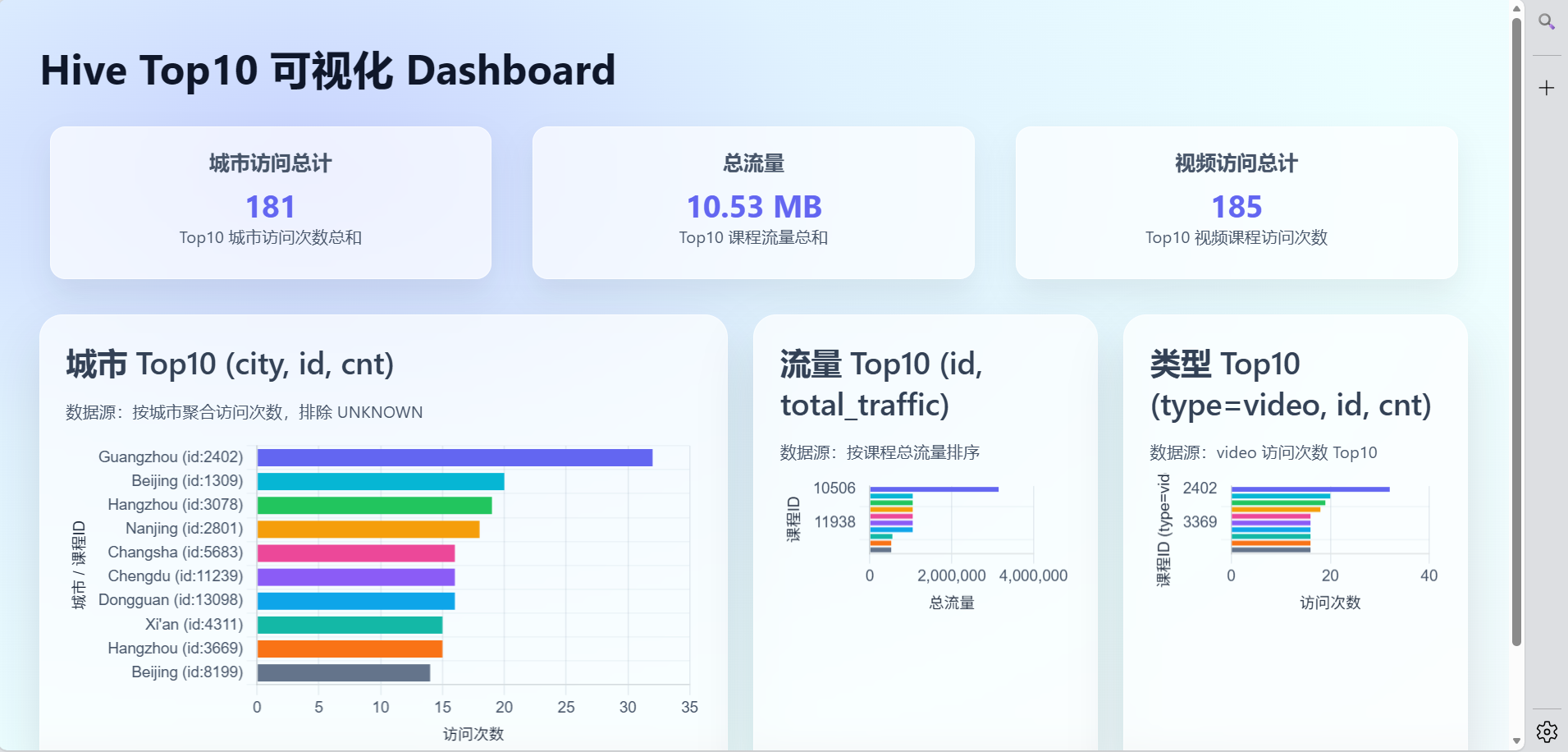
(1)统计最受欢迎的视频/文章的Top10访问次数 (video/article)
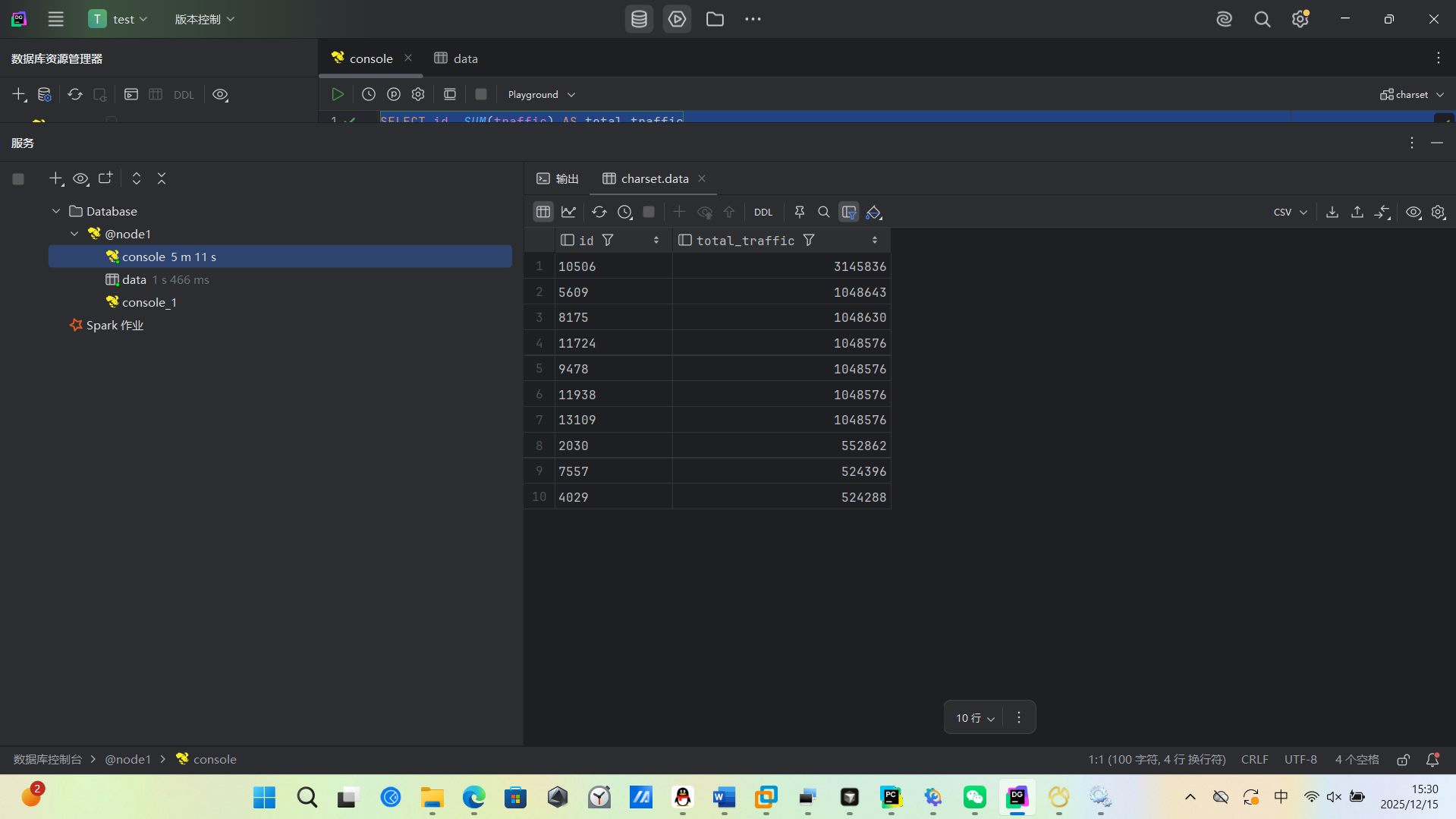
(2)按照地市统计最受欢迎的Top10课程 (ip)
(3)按照流量统计最受欢迎的Top10课程 (traffic)
3、数据可视化:
将统计结果倒入MySql数据库中,通过图形化展示的方式展现出来。
数据集已经给好了只需要简单清洗一下就可以
这是先把原数据中有用的信息提取出来,并以,隔开
import csv
from datetime import datetime
from pathlib import Path
RAW_FILE = Path("raw.csv")
OUT_FILE = Path("cleaned.csv")
def parse_time(raw_time: str) -> str:
# 原始格式: 10/Nov/2016:00:01:02 +0800
main = raw_time.split()[0]
dt = datetime.strptime(main, "%d/%b/%Y:%H:%M:%S")
return dt.strftime("%Y-%m-%d %H:%M:%S")
def clean(in_path: Path = RAW_FILE, out_path: Path = OUT_FILE) -> None:
with in_path.open("r", encoding="utf-8", newline="") as fin, \
out_path.open("w", encoding="utf-8", newline="") as fout:
reader = csv.reader(fin)
writer = csv.writer(fout)
for row in reader:
# 结构校验
if len(row) != 6:
continue
ip, raw_time, day, traffic, typ, _id = (c.strip() for c in row)
# 类型/id 过滤
if typ not in ("video", "article"):
continue
if not _id.isdigit():
continue
# 解析时间与流量
try:
time_fmt = parse_time(raw_time)
traffic_val = int(traffic.replace(" ", ""))
except Exception:
continue
writer.writerow([ip, time_fmt, day, traffic_val, typ, _id])
if __name__ == "__main__":
clean()
print(f"done: {OUT_FILE}")
需要下载
GeoLite2-City.mmdb才可以把坐标转换为城市的名字
下载地址
https://gitcode.com/open-source-toolkit/94ce3/tree/main
再清洗一遍,把地址转换为城市的名字
import csv
from pathlib import Path
import geoip2.database
CLEANED_FILE = Path("cleaned.csv")
ENRICHED_FILE = Path("enriched.csv")
GEOIP_DB = Path("GeoLite2-City.mmdb") # 请将库文件放在同目录或改为绝对路径
def ip_to_city(reader):
try:
return reader.city.name or "UNKNOWN"
except Exception:
return "UNKNOWN"
def enrich(cleaned=CLEANED_FILE, out=ENRICHED_FILE, geo_db=GEOIP_DB):
if not geo_db.exists():
raise FileNotFoundError(f"GeoIP DB not found: {geo_db}")
reader = geoip2.database.Reader(str(geo_db))
with cleaned.open("r", encoding="utf-8", newline="") as fin, \
out.open("w", encoding="utf-8", newline="") as fout:
r = csv.reader(fin)
w = csv.writer(fout)
for row in r:
if len(row) != 6:
continue
ip, ts, day, traffic, typ, _id = row
try:
city = reader.city(ip).city.name or "UNKNOWN"
except Exception:
city = "UNKNOWN"
w.writerow([ip, ts, day, traffic, typ, _id, city])
reader.close()
print(f"done -> {out}")
if __name__ == "__main__":
enrich()
需要提前配置好hive,用datagrip将清洗的数据上传到hive中
根据需求生成sql语句,交给hive执行mapreduce语句,我这个虚拟机分配的内存比较少,主4GB,从1GB,从1GB
用了5-6分钟才计算出来,我还以为没连接好,可以把内存分配的多一些,这样就不需要等太长时间了,我没有装sqoop所以是手动导入mysql的,生成sql语句到mysql数据库,最后使用html可视化,因为数据量还是不大,所有可以这么做,数据大就必须用sqoop来传输运算结果了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号