编程入门之字符编码与乱码
——“为什么服务器收到的请求或者打开的文本文件有时会乱码?”
——“因为编码不对。”
——“编码的本质是什么?为什么编码不对就会乱码?一段文本是如何在网络中传输后最终显示给用户的?Java String默认使用什么编码?”
——“……”
乱码问题相信很多同学都有幸遇到过的,也解决过,但根据个人面试的经验,对该问题知其然亦知其所以然的同学,是少之又少的。故在这里做一下分享,以备在其他的面试中被问到:-)。
因为计算机已经发明很久了,“不要重复发明轮子”也是一句大家耳熟能详的古训,我们已经习惯了编写Print("A"),就会在屏幕上显示一个字符A的便利,认为这一切自然而然。而过程中需要哪些支持,发生了什么,思考的人已经越来越少了。下面我们推理下在轮子还不那么齐全的年代,如何实现一个显示字符的“记事本”程序。
一、文本的存储
.txt文件非常常见,当我们在windows桌面右键新建一个“文本文档”,在其中输入A之后保存,就在桌面形成了一个保存着A的文本文档A。然后我们双击它打开,就会看到这个保存的A。
而学校里的课程告诉我们,计算机中存储的都是0和1这种2进制数据,无法存储“A”,那磁盘存储的究竟是什么?我们换另外一类工具来打开这个文本文档,这类工具叫做16进制编辑器,这里使用HxD编辑器。显示如下内容。

这里显示了实际的存储内容为一个字节0x41,对应的文本是A。 这时我们在41这个字节之后输入一个字节0x42,这时对应的文本显示了B

保存后用记事本打开这个存储了两个字节的文件,同样会显示AB,即我们通过输入0x42的方式,输入了字符B。

二、字符集
上面揭示了,我在记事本程序中输入字符A后保存,存储在磁盘文件的实际是数字0x41(对应二进制0100 0001),而如果我在16进制编辑器中直接追加一个0x42,则用记事本打开会显示B。所以记事本程序一定有一个转换功能,这个转换规则可能是输入一个字符A,则转换存储为0x41。反之读取时,如果是0x41则显示字符A,如果是0x42则显示B,其实可以理解为一个保存编码,显示解码过程。显然字母有26个,算上大小写可能有27个,再加上些加减乘除,爱心符号,所以我们需要全面的定义这种对应关系,对常用的字符定义完成后,可能会得到下面这样一张表,就是传说中的ascii字符集。
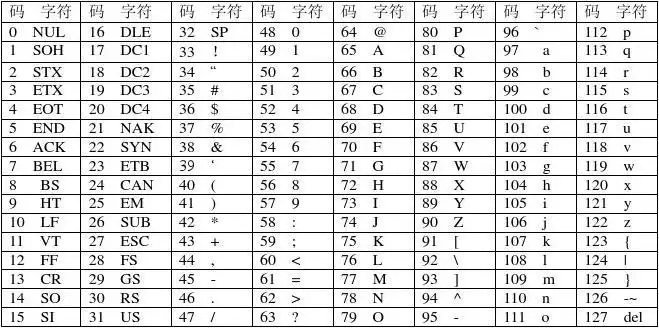
这张表定义了字符与计算机存储二进制数据间的对应关系,因此要实现记事本程序,本质上是实现了一个将二进制与可见字符转换的程序。当输入字符时保存为二进制,当读取二进制时,转换为字符显示。是不是看上去简单的记事本比想象中的略复杂了些。但字符集是抽象的。所谓抽象是指定义了字符的编码之后,仍然无法在屏幕上显示出一个字符A。接下来需要考虑,要把一个字符A显示在屏幕上,需要做哪些具体的工作。
三、字库(字体)
屏幕上显示的A实际上是一个图形,显示A的过程,本质上是需要在屏幕上画出一个形状为A的图形。并且A的写法有很多种,如下面都是A。因此我们需要具体定义出当我们要显示字符A的时候需要把A绘制成什么样子,当然还要同样定义B,C,D等。

这个定义我可以硬编码在我的“记事本程序”中,那这个定义就是一种私有的定义,保存的文件拿到其他的文本编辑器,就无法正确的显示出我保存的A的样子了。因为其他程序绘制A的方式也许不同。一个比较好的主意是把这个定义公开出来,定义一个标准格式,这样大家都可能解析,编制这个定义字符形状的文件,可以保证显示的通用一致性,这个就叫做字体文件。
实践中字符集定义和字体文件的定义都是标准公开的,这样系统内的程序都可以将相同的文件内容对应成相同的字符,如果愿意,也使用相同的字体来显示,保持风格的一致。
字符形状(字体)的定义无疑包含至少包含两个要素,这个字符的图形和这个字符的索引编码。程序需要绘制字符A的时候可以用编码0x41,去字体文件搜索对应的字体定义,然后调用其他的绘图API把A“画”出来,绘图API可以理解为一些比较底层的绘图方法,实现类似将第一排第一列的像素点显示为黑色这样的功能,驱动显示芯片在显示器上绘图。
像素字体是一种符合直觉的定义方式

按照定义将其绘制到对应屏幕像素点上,就形成了文字。当然问题是缩放可能会比较模糊,定义时可能会加入字号信息,为不同的字号,定义一系列不同的像素点阵,改善显示效果。高级的做法也容易想到,就是用数学描述的方式来定义字符形状,形成所谓矢量字体,优点可以无极缩放,缺点可能是需要绘制逻辑比较复杂,对资源占用高。
四、乱码的产生
有了以上的背景知识,推而广之就容易想到乱码是如何产生的了。乱码的产生本质是由于“记事本”之类的程序,对文件的二进制内容无法正确转换为字符进行绘制而产生。
如果全世界只存在ascii一种字符集则简单的多。但因为世界范围内的语言文字众多,除了英文字母外,还有中文,希腊文,日文……。这些文字符号也有被计算机存储显示的要求,如我国会有显示中文的需求,因此会存在众多的字符集,通常是以国家区域推行,自己的事情自己操心嘛。于是可能存在这样的定义。
如在某字符集编码中约定(GBK编码集)
两个字节 0xD6 0xD0 对应字符 “中”
我们使用了一个强大的支持中文编辑的“中文记事本”输入了一个“中"保存了起来。 实际存储内容为 0xD6 0xD0。 此时我们用上面那个“功能简单的记事本”读取显示该文件,假设它只支持ascii编码集, 那他会逐个字节对文件内容进行处理显示,读取第一个字节0xD6去ascii编码集中寻找对应的字符进行显示,之后读取0xD0进行显示,于是变成了下面这样的所谓“乱码”。由此可见,乱码的原因,可能是对应了错误的字符,或者对应不可见字符,或者根本就不存在的字符如何处理显示取决于程序自身的处理。

思考题:但为啥实际中的windows记事本是可以记录中文的,为何它打开0xD6 0xD0 会知道是以GBK编码保存的呢?:-)
当然很久很久之后,分久必合,自然而然产生了unicode编码,即统一码,可以以一套编码编码全世界所有的语言文字符号。避免了编码各自(各国各民族)为战的情况。
五、总结
- 计算机文件的存储及网络传输都是基于二进制数据流进行的。
- 乱码现象是由于输入存储(编码)的字符编码,与读取显示的编码(解码)不一致产生的。
- 需要用相同的字符编码集进行 字符->二进制->字符 的转换过程, 以避免乱码问题的产生。
思考题:Java中遍地的String, 是如何在内存中存储的呢?使用何种编码呢?
相关解释见这里 Java String编码:https://www.cnblogs.com/uncleguo/p/16076173.html
本文来自博客园,作者:锅叔
转载请注明原文链接:https://www.cnblogs.com/uncleguo/p/16008551.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号