数据分析之表示——NumPy数据存取与函数
>>>数据的CSV文件存取
【CSV,Comma-Separated Value,逗号分隔值】,CSV一种常见的文件格式,用于存取批量数据
CSV文件
np.savetxt (frame, arry, fmt = ' %.18e ' , delimiter = None)
frame : 文件、字符串或产生器,可以是 .gz或 .bz2的压缩文件
array :存入文件的数组
fmt : 写入文件的格式,例如:%d %.2f %.18e
delimiter : 分割字符串,默认是任何空格
>>>a = np.arange(100).reshape(5,20) >>> np.savetxt('a.csv',a,fmt = '%1f',delimiter = ',')

np.loadtxt(frame, dtype=np.float, delimiter=None, unpack=False )
frame : 文件、字符串或产生器,可以是 .gz或 .bz2的压缩文件
dtype : 数据类型,可选
delimiter : 分割字符串,默认是任何空格
unpack : 如果True,读入属性将分别写入不同变量
b = np.loadtxt('a.csv',delimiter=',')

b = np.loadtxt('a.csv',dtype=np.int,delimiter=',')

##CSV文件的局限性
CSV只能有效存储一维和二维数组,
np.savetxt ,np.loadtxt 只能有效存储一维和二维数组
>>>多维数据的存取
a.tofile(frame,sep=' ',foemat='%s')
frame : 文件、字符串
sep : 数据分割字符串,如果是空串,写入文件为二进制
format :写入数据的格式
a = np.arange(100).reshape(5,10,2) a.tofile("b.dat" , sep = ",", format='%d')

a = np.arange(100).reshape(5,10,2) a.tofile("b.dat" , format='%d')

np.fromfile(frame, dtype=float, count=-1, sep=' ')
frame : 文件、字符串
dtype :读取的数据类型
count :读入元素个数,-1 表示读入整个文件
sep : 数据分割字符串,如果是空串,写入文件为二进制

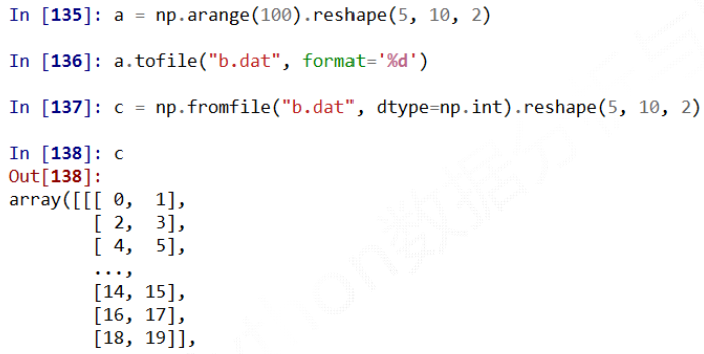
##需注意
该方法要读取时知道存入文件时数组的维度和元素类型,
a.tofile()和np.fromfile()需要配合使用
可以通过元数据文件来存储额外信息
##NumPy的便捷文件存取 【可以很好地解决存多维数组的问题】
np.save(fname , array) 或 np.savez(fname, array)
fname : 文件名,以.npy为扩展名,压缩扩展为.npz
array :数组变量
np .load( fname )
fname : 文件名,以.npy 为扩展名,压缩扩展名为 .npz
a = np.arange(100).reshape(5,10,2) np.save("a.npy", a) b = np.load("a.npy")
>>> NumPy的随机数函数
##NumPy的random子库 np.random.*
np.random.randn() np.random.rand() np.random.randint()
np.random的随机数函数(1)
>>> import numpy as np >>> a = np.random.rand(3,4,5) >>>b = np.random.randint(100,200,(3,4))
>>> b = np.random.randint(100,200,(3,4)) >>> b array([[128, 165, 185, 192], [145, 104, 120, 195], [120, 175, 172, 100]]) >>> np.random.seed(10) #只使用一次随机数种子 >>> np.random.randint(100,200,(3,4)) array([[109, 115, 164, 128], [189, 193, 129, 108], [173, 100, 140, 136]]) #产生的随机数不相同 >>> np.random.seed(10) #使用两次随机数种子 >>> np.random.randint(100,200,(3,4)) array([[109, 115, 164, 128], [189, 193, 129, 108], [173, 100, 140, 136]]) #产生相同的随机数
np.random.seed(n)函数用于生成指定随机数,n 可理解为第n份,n值相同,种子相同
seed()中的参数被设置了之后,np.random.seed()可以按顺序产生一组固定的数组,如果使用相同的seed()值,则每次生成的随机数都相同。如果不设置这个值,那么每次生成的随机数不同。但是,只在调用的时候seed()一下并不能使生成的随机数相同,需要每次调用都seed()一下,表示种子相同,从而生成的随机数相同。
np.random的随机数函数(2)

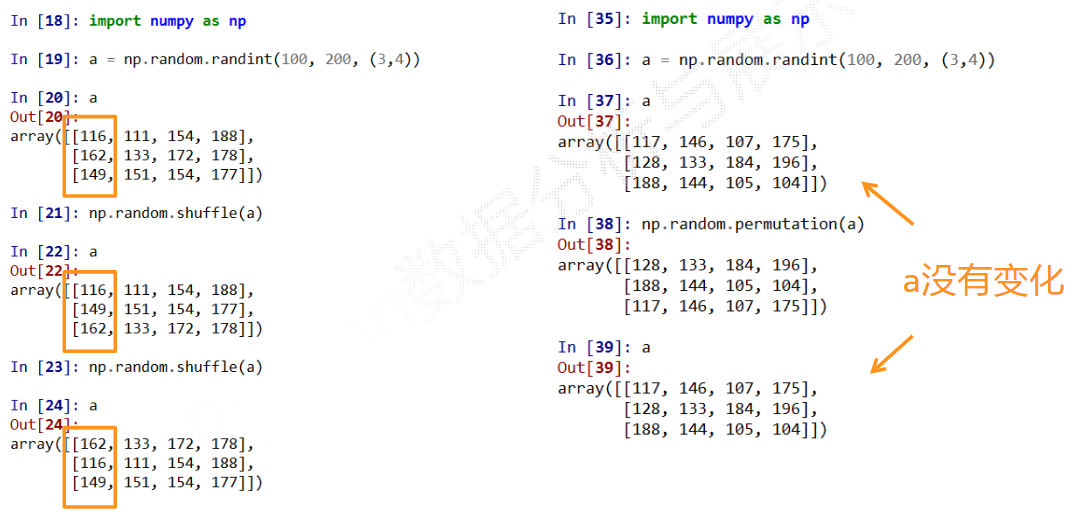
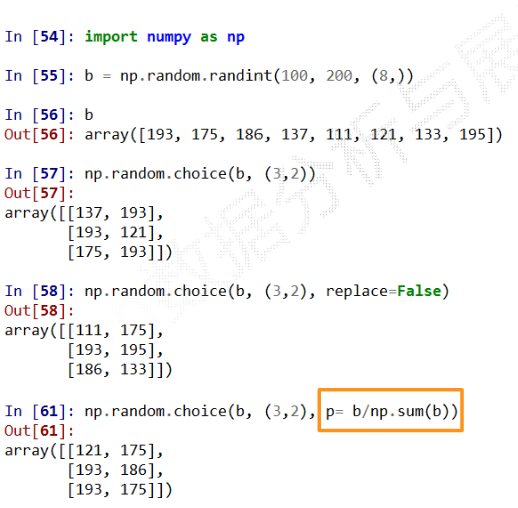
np.random的随机数函数(3)

>>> import numpy as np >>> u = np.random.uniform(0,10,(3,4)) >>> u array([[3.45560727, 3.96767474, 5.38816734, 4.19194514], [6.852195 , 2.0445225 , 8.78117436, 0.27387593], [6.7046751 , 4.17304802, 5.58689828, 1.40386939]]) >>> n = np.random.normal(10,5,(3,4)) >>> n array([[12.82172433, 7.16744885, 13.64987798, 11.86496895], [12.66905456, 9.5401335 , 19.56910194, 11.65398565], [15.7097126 , 4.3520242 , 5.74973811, 14.80410002]])
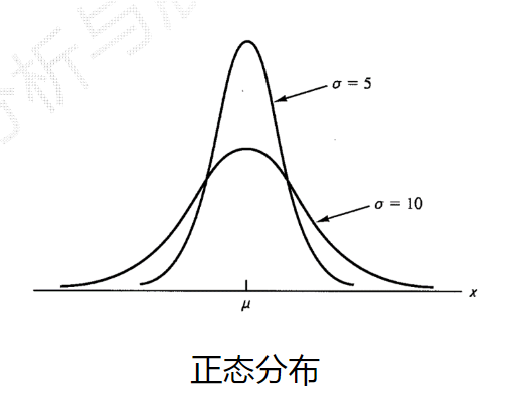
>>>NumPy的统计函数
NumPy直接提供的统计类函数 np.*
np.std() np.var() np.average()
>>> import numpy as np >>> a = np.arange(15).reshape(3,5) >>> a array([[ 0, 1, 2, 3, 4], [ 5, 6, 7, 8, 9], [10, 11, 12, 13, 14]]) >>> np.sum(a) 105 >>> np.mean(a,axis=1) array([ 2., 7., 12.]) >>> np.mean(a,axis=0) array([5., 6., 7., 8., 9.]) >>> np.average(a,axis=0,weights=[10,5,1]) array([2.1875, 3.1875, 4.1875, 5.1875, 6.1875]) # 加权平均4.1875=2*10+7*5+1*12/(10+5+1) >>> np.std(a) 4.320493798938574 >>> np.var(a) 18.666666666666668
>>> import numpy as np >>> b = np.arange(15,0,-1).reshape(3,5) >>> b array([[15, 14, 13, 12, 11], [10, 9, 8, 7, 6], [ 5, 4, 3, 2, 1]]) >>> np.argmax(b) 0 #扁平化后的下标 >>> np.unravel_index(np.argmax(b),b.shape) (0, 0) #重塑成多维下标
>>>NumPy的梯度函数

梯度:连续值之间的变化率,即斜率
>>> import numpy as np >>> a = np.random.randint(0,20,(5)) >>> a array([7, 8, 9, 3, 7]) >>> np.gradient(a) array([ 1. , 1. , -2.5, -1. , 4. ]) #-2.5 存在两侧值:(3-8)/2 #4. 只有一侧值:(7-3)/1
#二维数组 >>> import numpy as np >>> a = np.random.randint(0,20,(5)) >>> a array([7, 8, 9, 3, 7]) >>> np.gradient(a) array([ 1. , 1. , -2.5, -1. , 4. ]) >>> import numpy as np >>> c = np.random.randint(0,50,(3,5)) >>> c array([[23, 36, 27, 37, 19], [38, 8, 32, 34, 10], [23, 15, 47, 23, 25]]) >>> np.gradient(c) [array([[ 15. , -28. , 5. , -3. , -9. ], [ 0. , -10.5, 10. , -7. , 3. ], [-15. , 7. , 15. , -11. , 15. ]]), #最外层维度的梯度,即纵向梯度 array([[ 13. , 2. , 0.5, -4. , -18. ], [-30. , -3. , 13. , -11. , -24. ], [ -8. , 12. , 4. , -11. , 2. ]])] #第二层维度梯度,即横向梯度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号