
03、编写网络爬虫及过程分析💪💪💪
过程分析
一、什么是Network❓
①概念:记录当前页面上发生的请求。
二、如何使用Network❓
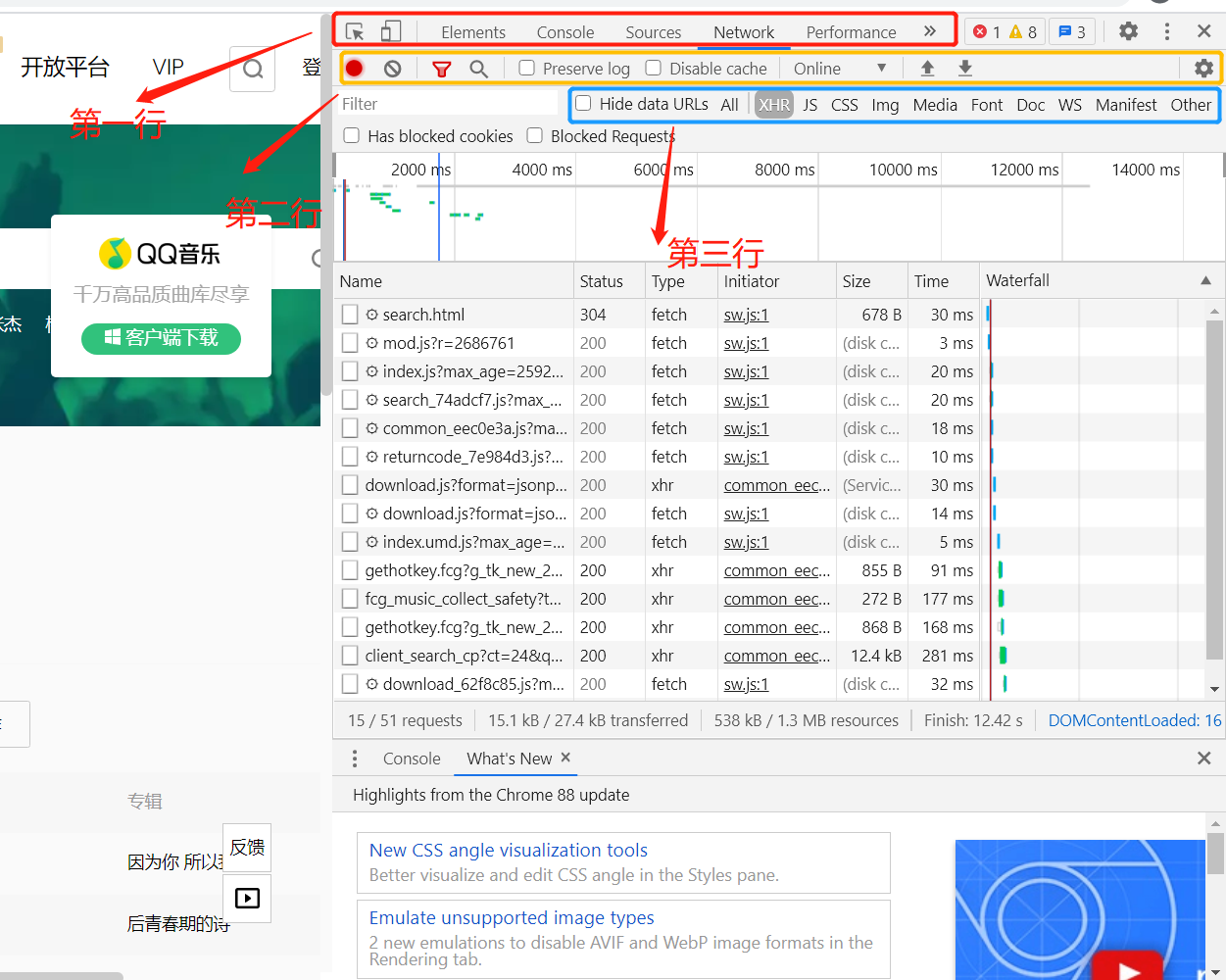
①第一行我们点击Network
②第二行,红色的原按钮是启用Network监控 -----  ----,灰色圆圈是清空面板-----
----,灰色圆圈是清空面板----- ------,右侧勾选框Preserve log保留请求日志-----
------,右侧勾选框Preserve log保留请求日志----- -----
-----
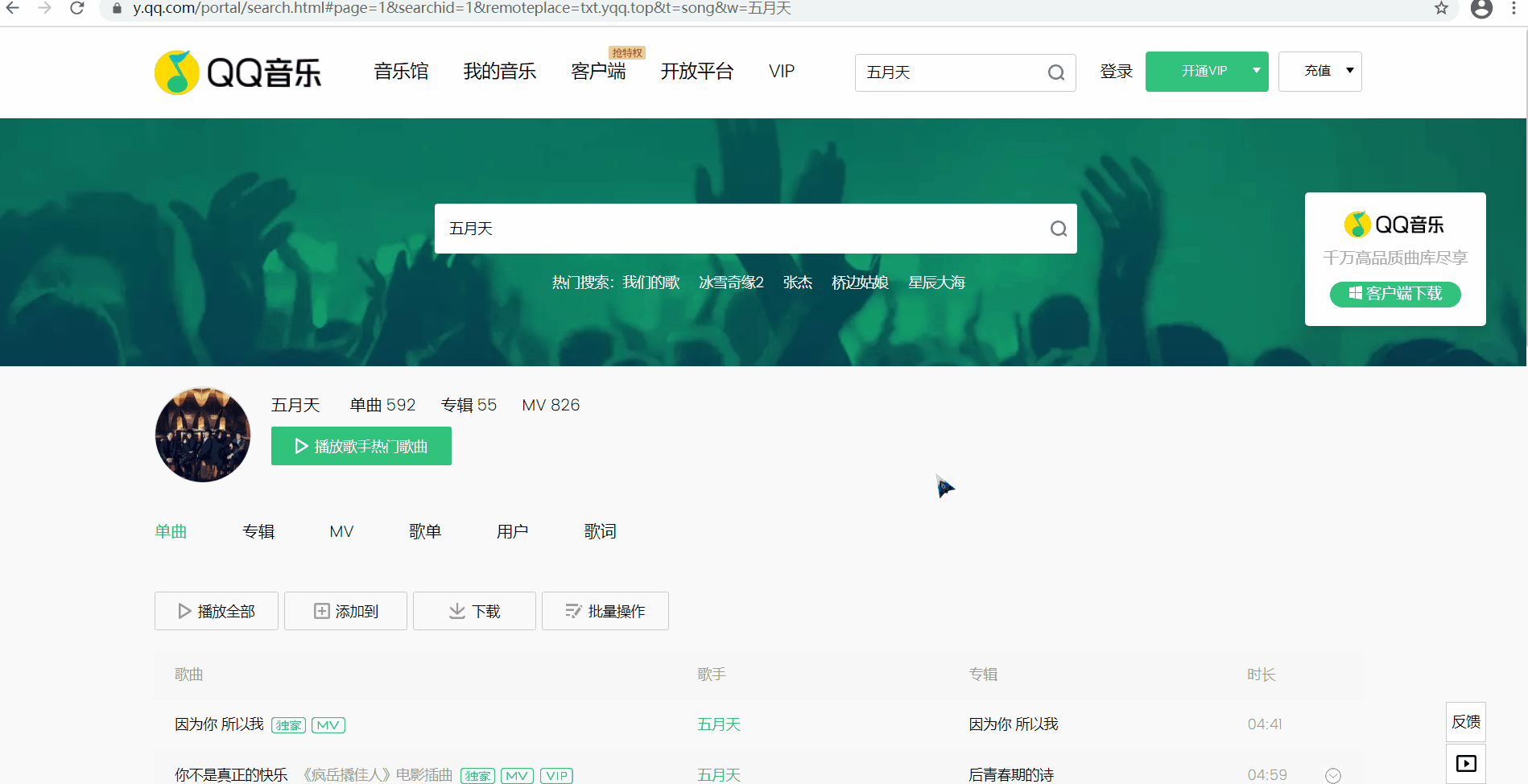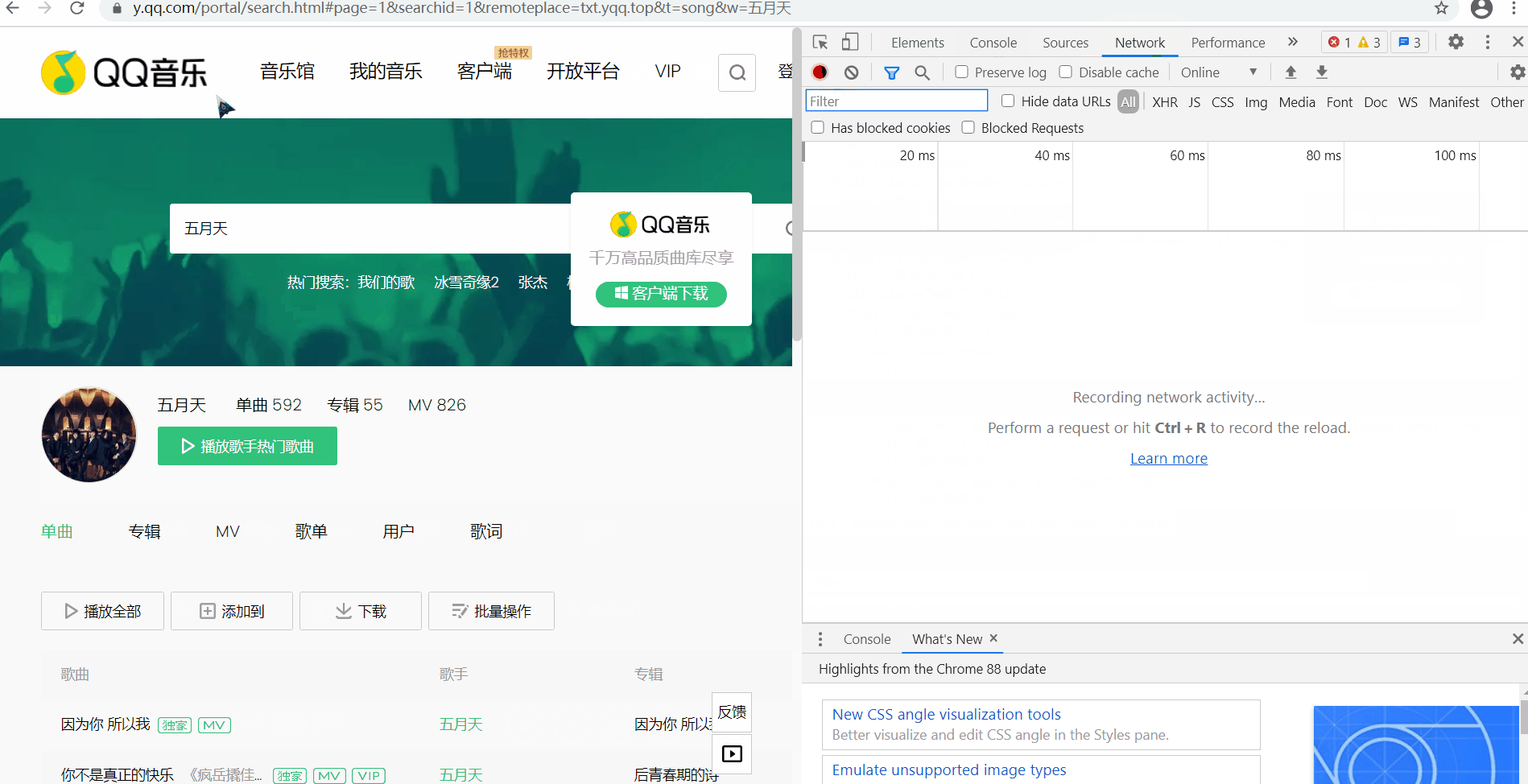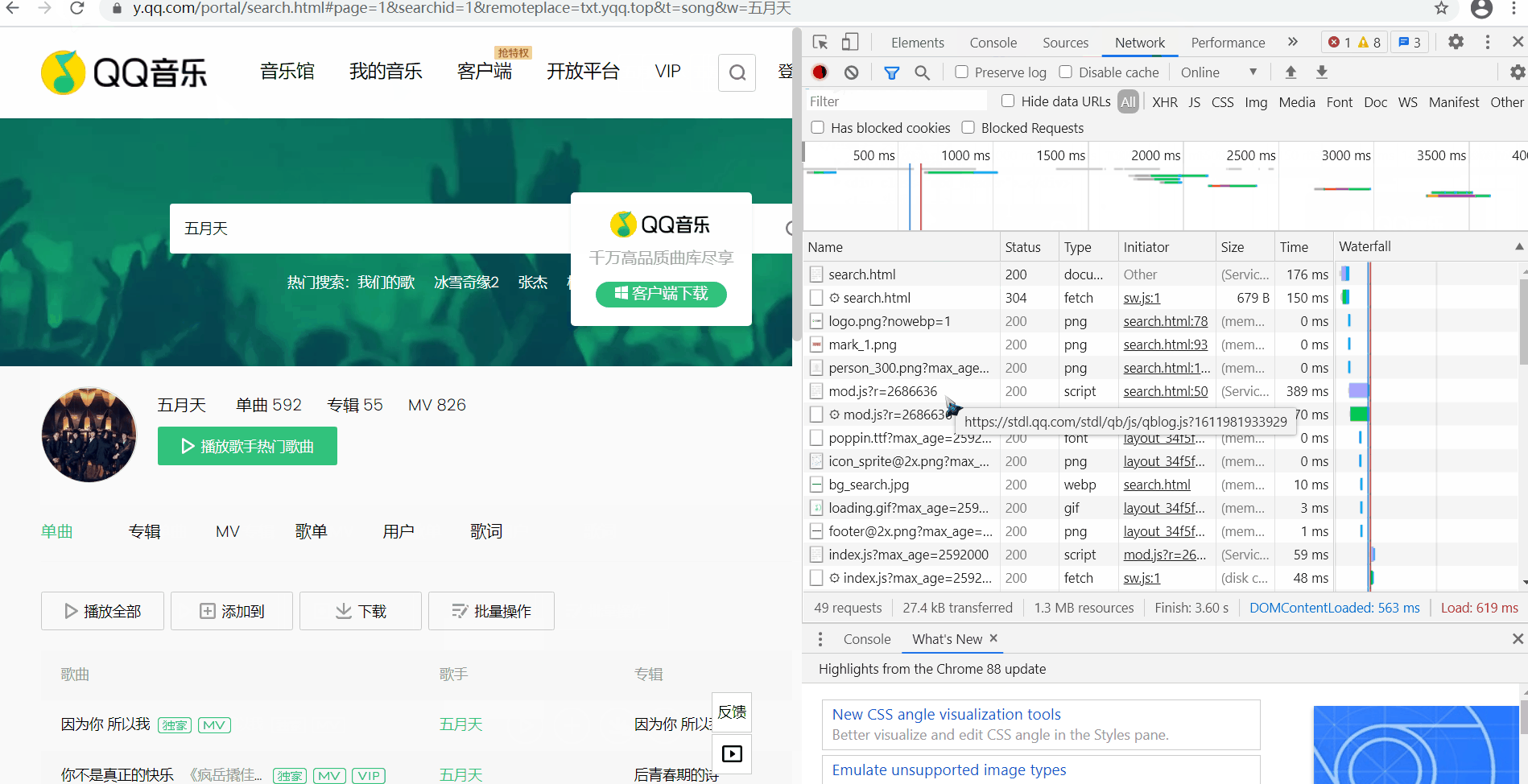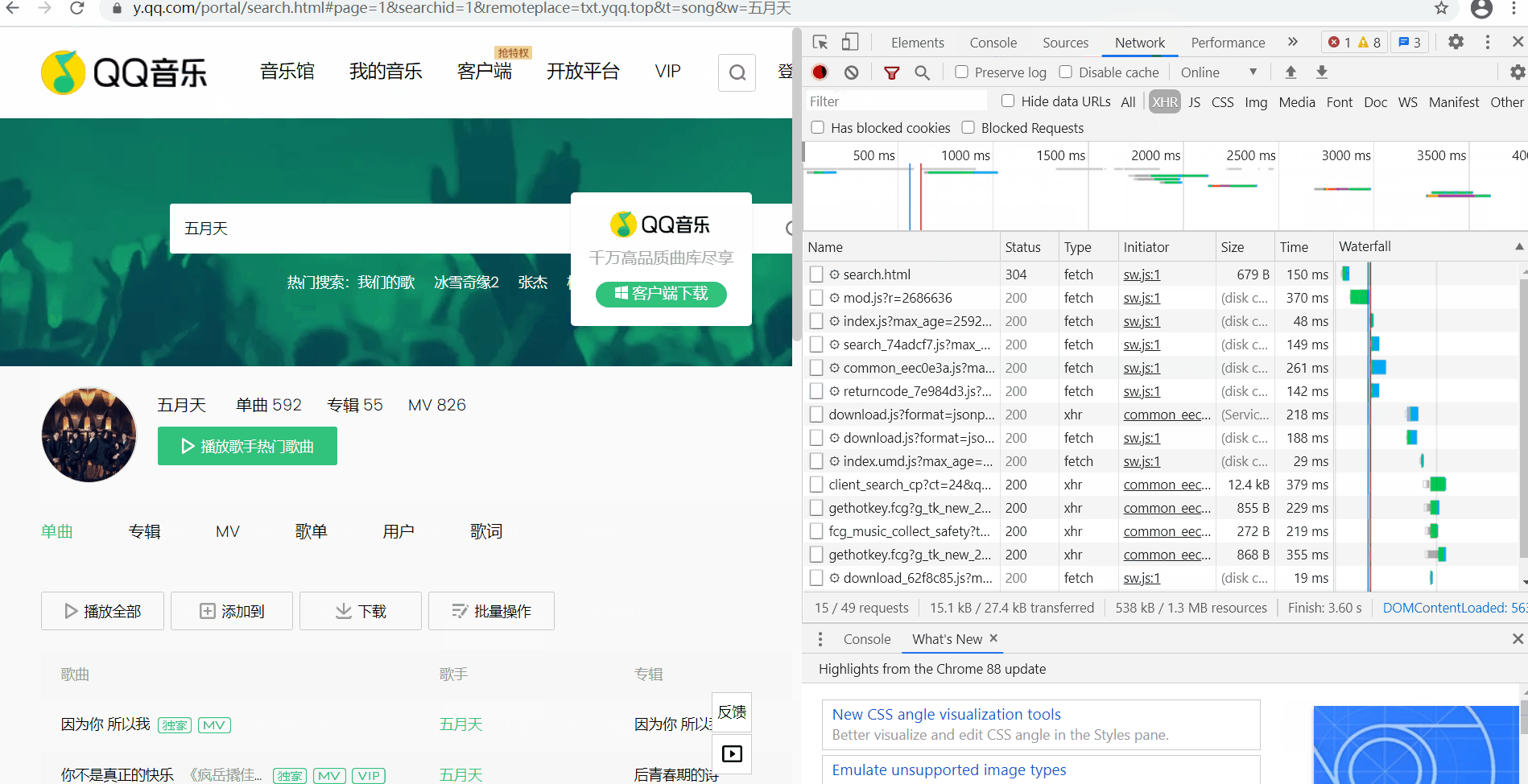
③第三行是分类查看
| ALL | 查看全部 |
| XHR | 不需要刷新网页就可以进行数据传输的对象 |
| Doc | Document,网页的第一个请求 |
| Img | 只查看图片 |
| Media | 只查看媒体文件 |
| Other | 其他 |
| JS和CSS | JS是前端脚本语言,CSS是页面样式文件 |
| Font | 字体 |
| WS和Manif | 爬虫不需要了解 |
三、什么是json❓
1、json是一种特殊的字符串——>由列表/字典的语法写成(json能够有组织地存储信息。)
a = "1,2,3,4" type(a) #<class 'str'> b =[1,2,3,4] type(b) #<class 'list'> c ="[1,2,3,4]" type(c) #c就相当于一个json文件 #<class 'str'>
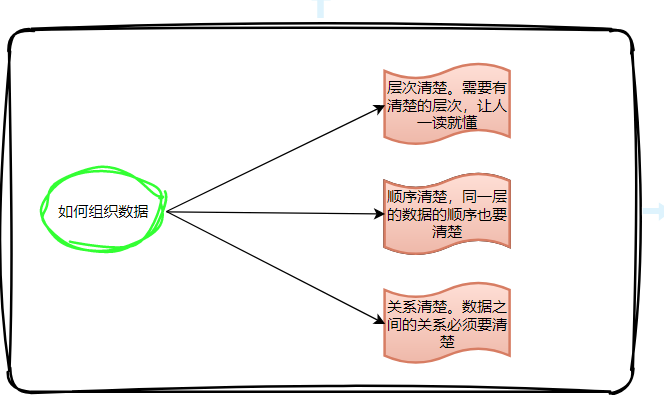
2、组织数据的规律:
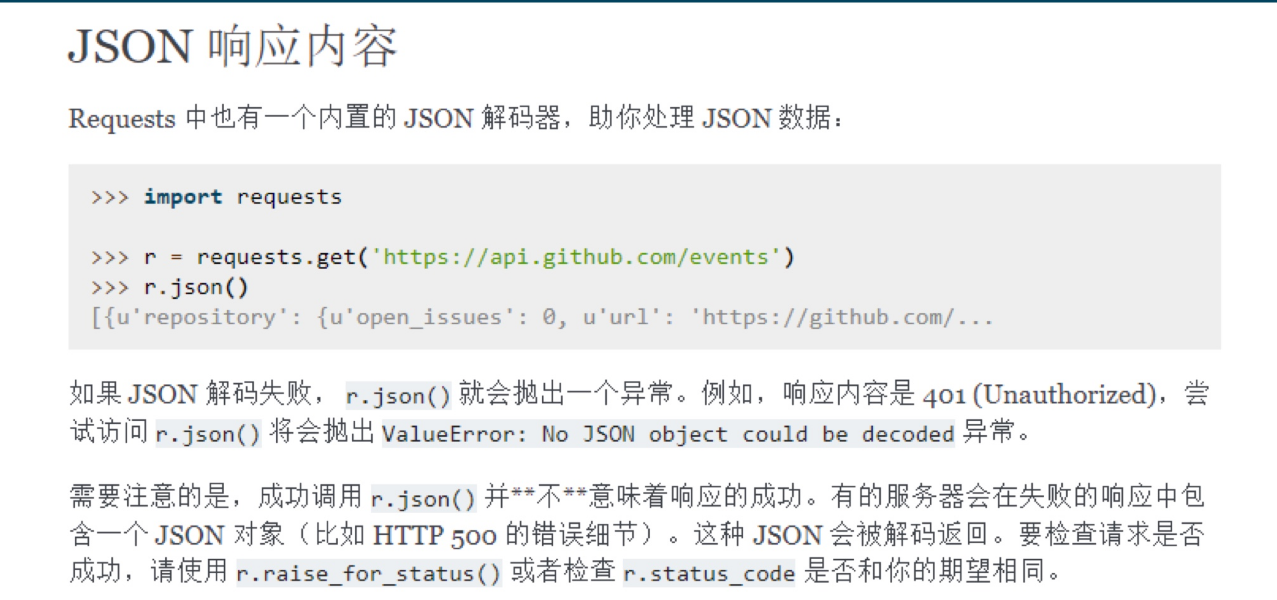
3、如何解析json数据❓
案例:📖
""" 1、爬取qq音乐五月天的歌曲信息 2、歌曲名、播放时间、链接等数据 3、至少爬取三到五页的内容 4、使用的模块:requests """ # 导入库 import requests def send_request(url): headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36"} res = requests.get(url, headers=headers) json_music = res.json() list_music = json_music['data']['song']['list'] for music in list_music: print('歌名:' + music['name']) # 以name为键,查找歌曲名 print('所属专辑:' + music['album']['name']) # 查找专辑名 print('播放时长:' + str(music['interval']) + '秒') # 查找播放时长 print('播放链接:https://y.qq.com/n/yqq/song/' + music['mid'] + '.html\n\n') # 查找播放链接 # 主函数 def main(): for i in range(1, 4): url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=71026466913918890&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p={}&n=10&w=%E4%BA%94%E6%9C%88%E5%A4%A9&g_tk_new_20200303=5381&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0'.format( i) send_request(url) if __name__ == '__main__': main() print('爬取完成')
上一节 下一节 返回目录
👆 👆 👆

 浙公网安备 33010602011771号
浙公网安备 33010602011771号