
01了解爬虫和浏览器的工作原理
爬虫
一、认识什么是爬虫?
网络爬虫又称网络蜘蛛,网络机器人,是一种按照一定的规则地抓取万维网信息的程序或脚本,简单理解就是爬取网页中的数据
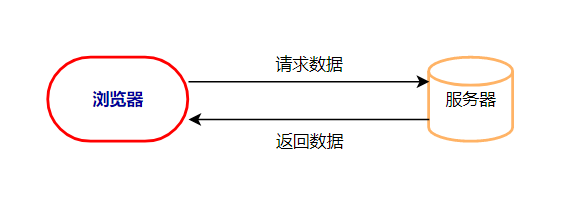
1、浏览器的工作原理
①浏览器中输入一个网址,也叫做URL,然后浏览器就会去存储放置这个网址资源文件的服务器获取这个网址的内容,这个过程就叫做「请求」(Request)
②当服务器收到了我们的「请求」之后,它会把对应的网站数据返回给浏览器,这个过程叫做「响应」(Response)。
2、爬虫工作原理:
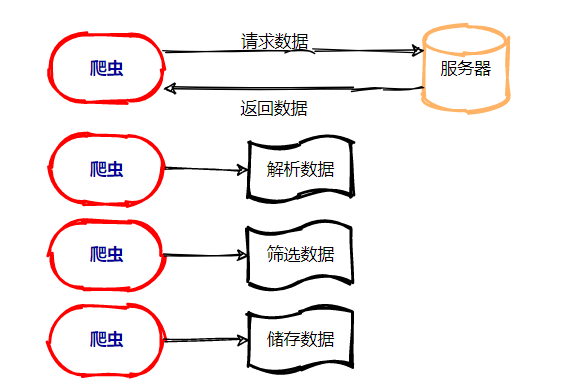
6、编写爬虫:
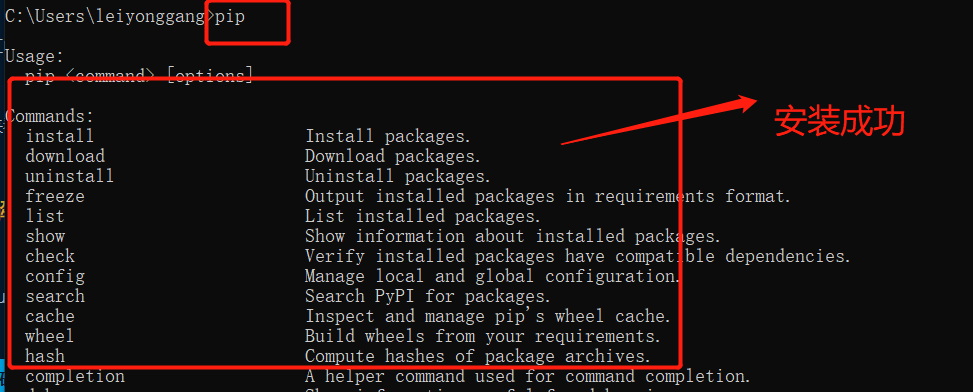
①首先得确定你的pip包是否安装配置成功
②获取数据
Windows电脑里叫命令提示符(cmd),输入pip install requests回车安装即可。
②了解requests库
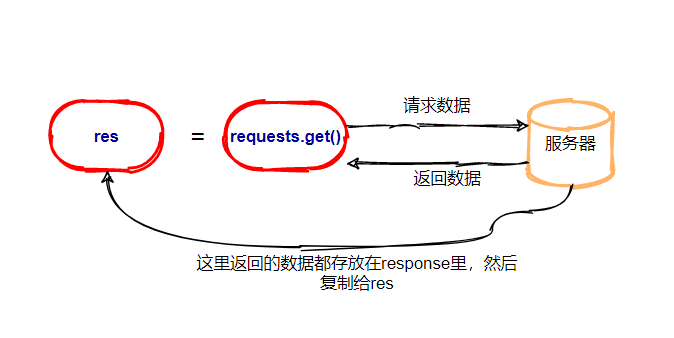
import requests res = requests.get('https://img.kaikeba.com/web/kkb_index/img_index_logo.png') print(type(res)) #打印变量res的数据类型
运行结果:
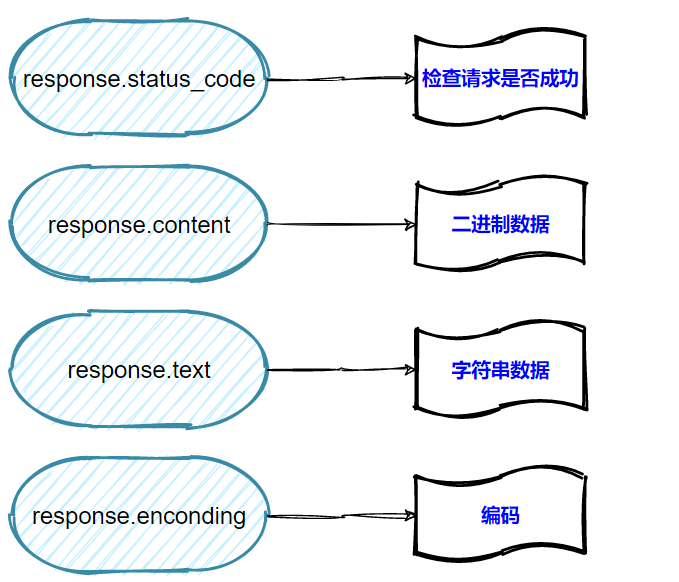
7、 Response对象的四种常用属性:
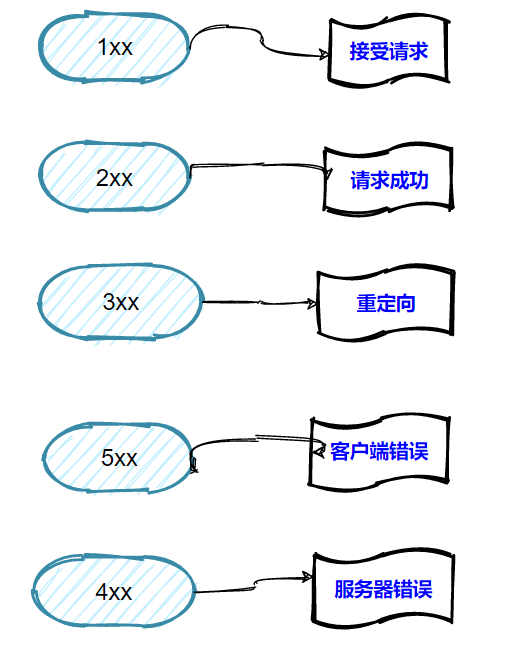
8、状态码
爬取一张图片:
import requests res = requests.get('https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1595644103551&di=6258c39f4c37181792ef64de1df95126&imgtype=0&src=http%3A%2F%2Fa3.att.hudong.com%2F14%2F75%2F01300000164186121366756803686.jpg') pic=res.content photo = open('banner.jpg','wb') photo.write(pic) photo.close()

爬取一篇文章:
import requests res = requests.get('https://xiaoke.kaikeba.com/example/gexu/shudaonan.txt') novel=res.text print(novel)

案例:
1、使用requests爬取文章,开掘一座文学理论富矿,并用open方法将爬取的数据写入文件中以及文章的书本图片
import requests from bs4 import BeautifulSoup url = 'https://baijiahao.baidu.com/s?id=1661382527708632196&wfr=spider&for=pc' res = requests.get(url) soup = BeautifulSoup(res.text,'html.parser') print(soup) test = soup.find_all('span',class_='bjh-p') list = [] for i in test: a=i.text list.append(a) wenzhang = ','.join(list) wenzhang1 = wenzhang.replace(',', '\n') with open('C:/Users/leiyonggang/Desktop/text.txt','w') as t: t.write(wenzhang1) soup1 = BeautifulSoup(res.content,'html.parser') image_html = soup1.find('img',class_='normal').attrs['src'] print(image_html) the_image = requests.get(image_html) with open("C:/Users/leiyonggang/Desktop/photo.jpg", "wb+") as f: f.write(the_image.content)
2、爬取百度logo图片。
import requests url = 'https://www.baidu.com/img/dong_e9e7c4c83bda2982cdb306cb77571742.gif' res = requests.get(url) print(res.content) photo = open('C:/Users/leiyonggang/Desktop/banner.gif','wb') photo.write(res.content) photo.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号