CUDA12.8+Window 环境下安装 GOT-OCR2.0(Installing GOT-OCR2.0 in CUDA12.8+Window environment)
GOT-OCR2.0 是一个端到端的的OCR项目,它采用了多模态视觉-语言大模型架构:预训练VitDet 视觉模型+ 阿里通义千问Qwen语言模型,具有多方面优良特性。
本人环境:window11 + python3.10 + cuda12.8 成功安装了GOT-OCR2.0,期间也遇到了一些问题和解决方案,分享给和我有同样问题的小伙伴。
1. 下载 GOT-OCR2.0
2. 搭建虚拟环境并进入环境
conda create -n got-ocr python=3.10 -y
conda activate got
3. 安装 pytorch
进入 pytorch 官网,再根据你的环境选择 pytorch 安装命令
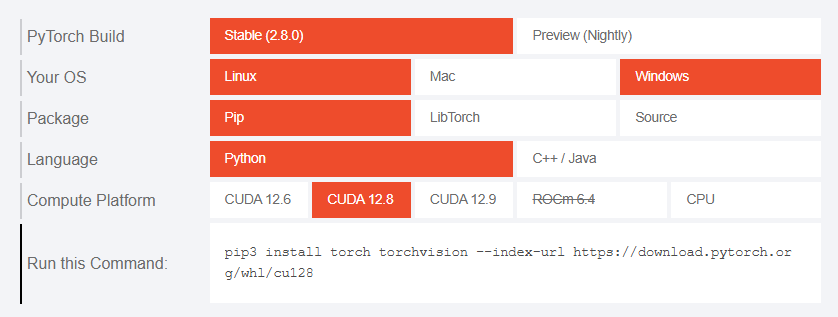
这里我使用如下命令:
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu128
安装完后使用 pip list 命令查看如下所示:

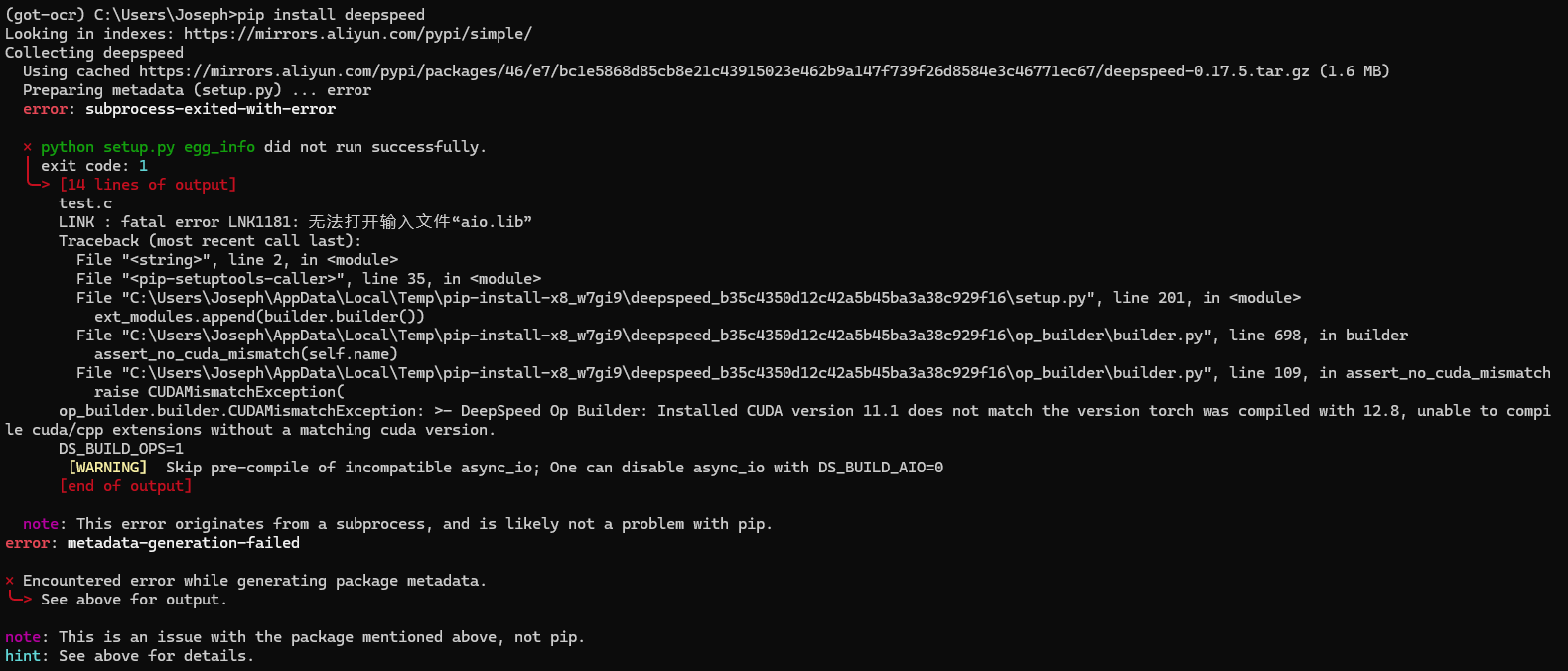
4. 安装deepseed
这时候如果安装官方的安装步骤,在安装到 deepseed 的时候会出现错误,报如下错误,所以这里先单独拎出来安装这个包。
因为用 pip 命令安装会出错,所以这里使用安装 whl 文件的方法进行 deepseed 的安装。通过查找,我在github上找到了针对 python3.10 编译好的 deepseed 的 whl 文件,因为我的 cuda 版本是12.8,所以我选择了CUDA12.1d的命令进行安装,即:
pip install https://github.com/daswer123/deepspeed-windows/releases/download/11.2/deepspeed-0.11.2+cuda121-cp311-cp311-win_amd64.whl
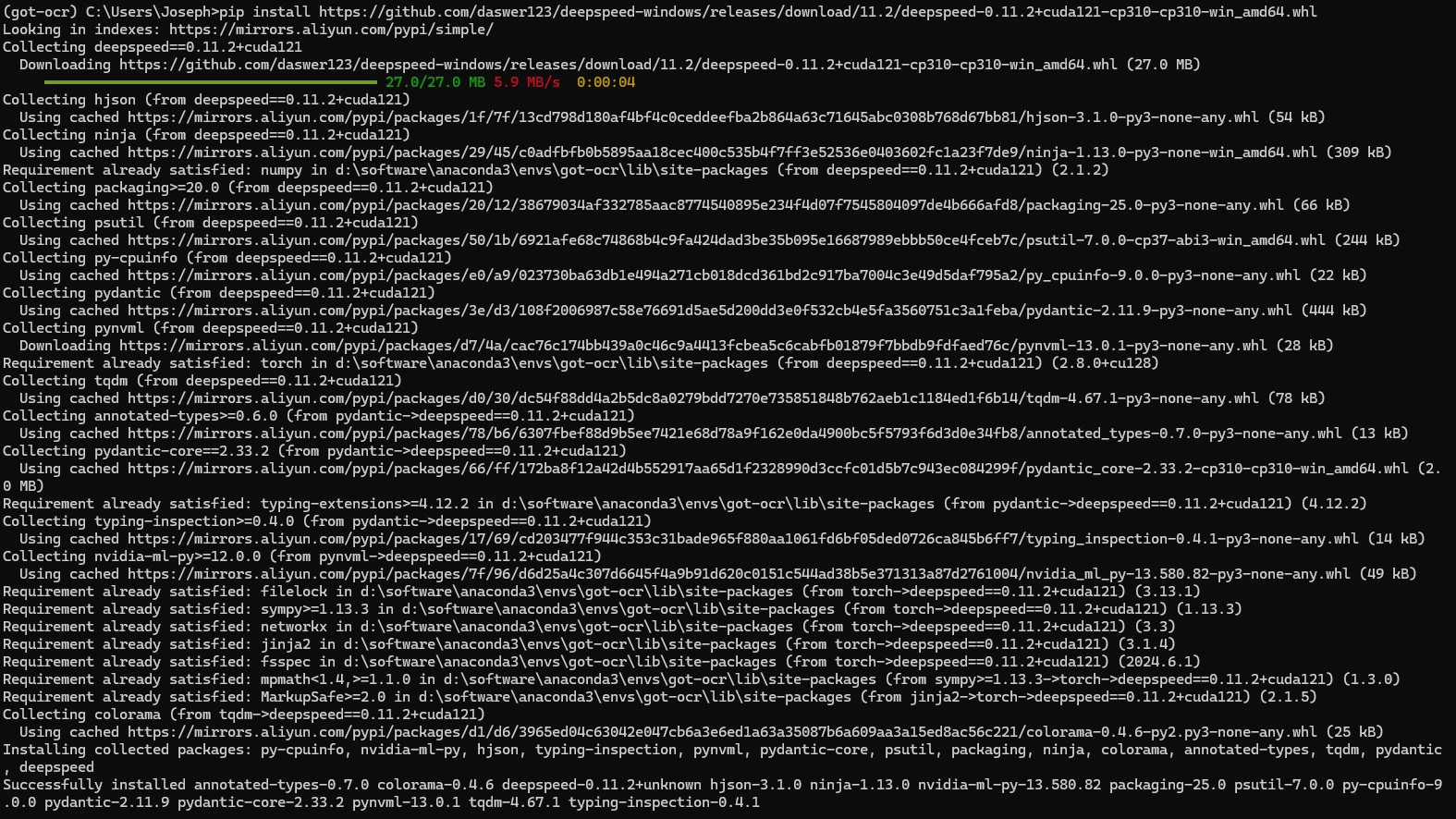
5. 安装剩下的包
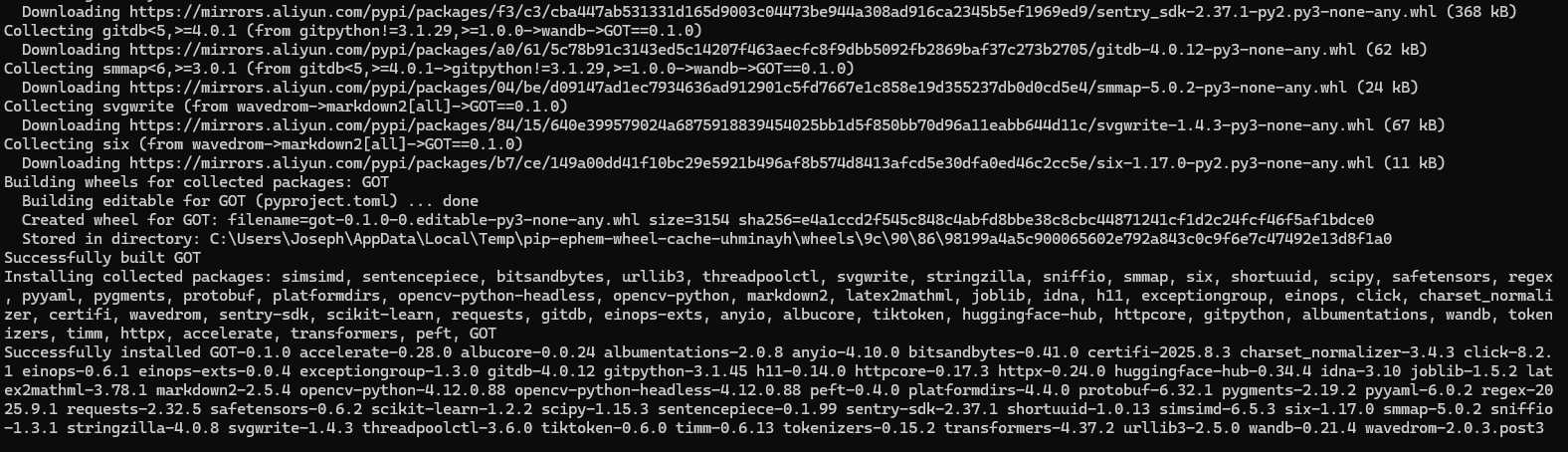
因为我们已经安装好了deepseed,所以我们就把 GOT-OCR2.0 文件夹下的 pyproject.toml 文件中的 "deepspeed==0.12.3", 这一行删除了然后再保存,保存好了之后再运行以下命令以完成剩下包的安装。(这里不用删除 torch 和 torchvision 是因为它们没有指定安装版本,所以检测到有 torch 和 torchvision 就不会再进行重新升级安装)
pip install -e .
安装好后的如下所示:
到这里,你就完成了 GOT-OCR2.0 的安装,已经可以正常使用GOT-OCR2.0 的 OCR 功能了。
这里提一下,在官方网站上后面还有一步是安装 Flash-Attention 的,Flash-Attention 是一个高性能的注意力机制实现库,专门用于优化 Transformer 模型中的自注意力计算,安装后之后会让程序运行更快,显存占用更低,但是不安装它程序也可以正常运行。查了下,虽然从 v2.3.2 版本开始, Flash-Attention 或许能兼容 Windows 系统,但是 Windows 系统的编译仍不够完善,所以这里就不对 Flash-Attention 进行安装。
6. 下载模型文件
这里使用在云端硬盘下载 GOT_weights.zip,下载后放入 GOT_weights 文件夹下
7. 使用 GOT-OCR2.0 进行 OCR 识别
命令:
python GOT/demo/run_ocr_2.0.py --model-name GOT_weights/GOT_weights --type ocr --image-file D:/data/python_project/ocr_new/data/1234.jpg
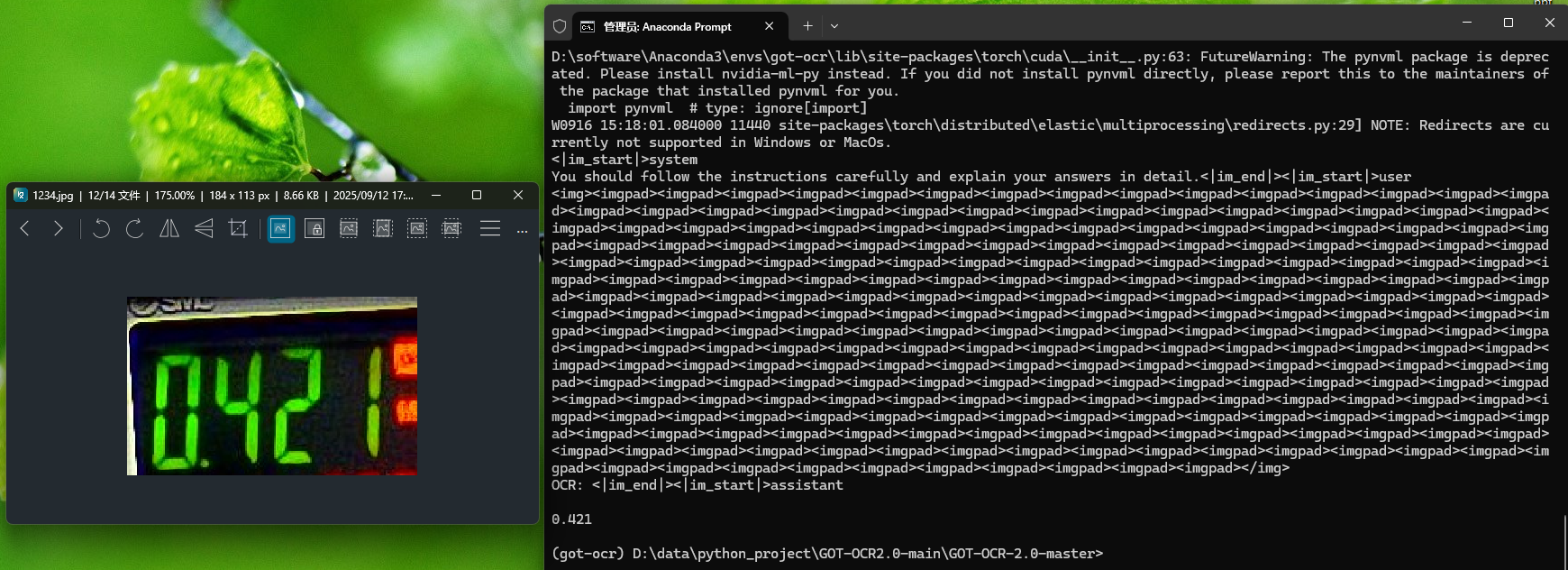
可以看出,在只是要求识别任务下,效果还是不错。
8. 获取识别结果
查找了资料,也看了源码,还是不知道在代码哪里可以看到最终检测结果框和结果变量存储的部分,但是有时候需要获取识别结果,因此想到了通过获取控制台输出的方式来获取识别结果,具体代码实现如下所示,注意,为了得到纯粹的识别结果,需要先注释 run_ocr_2.0.py 文件的 114 行 print(prompt) 代码,即

运行 GOT-OCR2.0 并获取控制台输出代码:
1 import subprocess
2 import sys
3
4 def run_ocr_and_capture_output(image_path, model_path):
5 """
6 运行GOT-OCR2.0并捕获控制台输出
7 """
8 # 构建命令
9 cmd = [
10 sys.executable, # 当前Python解释器
11 "GOT/demo/run_ocr_2.0_myself.py",
12 "--model-name", model_path,
13 "--image-file", image_path,
14 "--type", "ocr"
15 ]
16
17 try:
18 # 运行命令并捕获输出
19 result = subprocess.run(
20 cmd,
21 capture_output=True, # 捕获标准输出和错误输出
22 text=True, # 以文本形式返回
23 encoding='utf-8' # 指定编码
24 )
25
26 # 检查是否成功
27 if result.returncode == 0:
28 print("✅ OCR执行成功!")
29 return result.stdout
30 else:
31 print("❌ OCR执行失败!")
32 print("错误信息:", result.stderr)
33 return None
34
35 except Exception as e:
36 print(f"执行命令时出错: {e}")
37 return None
38
39 # 使用示例
40 if __name__ == "__main__":
41 image_file = 'D:/data/python_project/ocr_new/data/1234.jpg'
42 model_path = './GOT_weights/GOT_weights'
43
44 output_text = run_ocr_and_capture_output(image_file, model_path)
45
46 if output_text:
47 print("捕获到的识别结果:")
48 print(output_text)
49
50 # 保存到文件
51 with open("ocr_result.txt", "w", encoding="utf-8") as f:
52 f.write(output_text)
53 print("结果已保存到 ocr_result.txt")
代码运行结果:
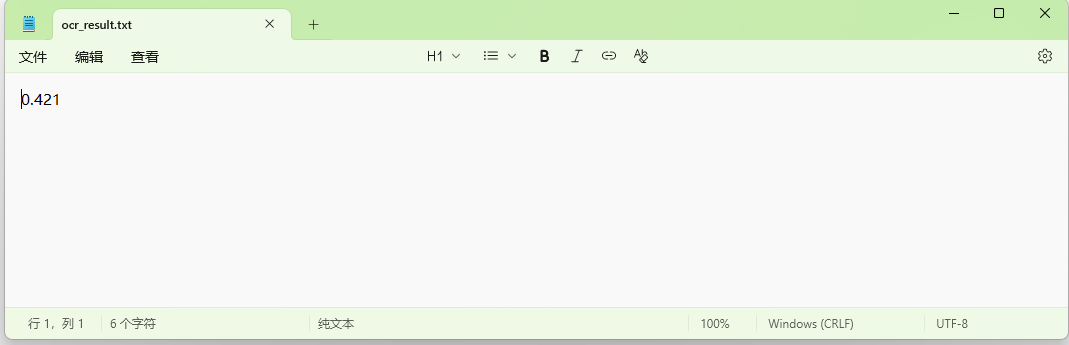
以上就是在 window11 + CUDA12.8 环境下配置 GOT-OCR2.0 的步骤,虽然运行出结果,但是还是有些美中不足的地方,如 flash-attention 稳定支持 window 系统的时候,可以把这个包安装上去,以及如何在源码中找到获取 GOT-OCR2.0 检测框和识别结果的方法,如果有小伙伴知道的,欢迎评论区交流探讨。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号