学习笔记:哈希
哈希
引入

哈希表又称散列表,一种以「key-value」形式存储数据的数据结构。所谓以「key-value」形式存储数据,是指任意的键值 key 都唯一对应到内存中的某个位置。只需要输入查找的键值,就可以快速地找到其对应的 value。可以把哈希表理解为一种高级的数组,这种数组的下标可以是很大的整数,浮点数,字符串甚至结构体。
实现
Hash 的核心思想在于,将输入映射到一个值域较小、比较方便的范围。
要让键值对应到内存中的位置,就要为键值计算索引,也就是计算这个数据应该放到哪里。这个根据键值计算索引的函数就叫做哈希函数,也称散列函数。举个例子,如果键值是一个人的身份证号码,哈希函数就可以是号码的后四位,当然也可以是号码的前四位。生活中常用的「手机尾号」也是一种哈希函数。在实际的应用中,键值可能是更复杂的东西,比如浮点数、字符串、结构体等,这时候就要根据具体情况设计合适的哈希函数。哈希函数应当易于计算,并且尽量使计算出来的索引均匀分布。
能为 key 计算索引之后,我们就可以知道每个键值对应的值 value 应该放在哪里了。假设我们用数组 a 存放数据,哈希函数是 f,那键值对 (key, value) 就应该放在 a[f(key)] 上。不论键值是什么类型,范围有多大,f(key) 都是在可接受范围内的整数,可以作为数组的下标。
在 OI 中,最常见的情况应该是键值为整数的情况。当键值的范围比较小的时候,可以直接把键值作为数组的下标,但当键值的范围比较大,比如以 \(10^9\) 范围内的整数作为键值的时候,就需要用到哈希表。一般把键值模一个较大的质数作为索引,也就是取 \(f(x)=x \bmod M\) 作为哈希函数。
单哈希
for(int i = 0 ; i < s[x].length() ; i ++)
res *= 114514,res %= mod,
res += (s[x][i] ^ 48) * (i + 1),res %= mod;
进制哈希
首先设一个进制数 base,并设一个模数 mod,进制哈希就是把一个串转化为一个值,这个值是 base 进制的,储存在哈希表中。注意一下在存入的时候取模一下即可。
for(int i = 0 ; i < s[x].length() ; i ++)
res = (res * base + s[x][i]) % mod;
双哈希
其实就是用两种不同的方式来算 hash,哈希冲突的概率是降低了很多,不过常数大,容易被卡。
for(int i = 0 ; i < s[x].length() ; i ++)
a[x].f += (s[x][i] ^ 48) * (i + 1),a[x].f %= mod;
for(int i = 0 ; i < s[x].length() ; i ++)
a[x].g = (a[x].g * base + s[x][i]) % mod;
关于冲突
如果对于任意的键值,哈希函数计算出来的索引都不相同,那只用根据索引把 (key, value) 放到对应的位置就行了。但实际上,常常会出现两个不同的键值,他们用哈希函数计算出来的索引是相同的。这时候就需要一些方法来处理冲突。
闭散列
也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。当发生地址冲突后,求解下一个地址。假如冲突很多,\(1\) 占了 \(1\) 的位置,\(1\) 只能占 \(2\) 的位置,\(2\) 占 \(3\) 的位置……再放 \(1\) 或者 \(2\) 的时候,就只能放在 \(4\) 的位置。具体地,我们可以看看初赛题……
相信(玩过)打过初赛的都能够理解……
开散列
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。(图是贺的……)
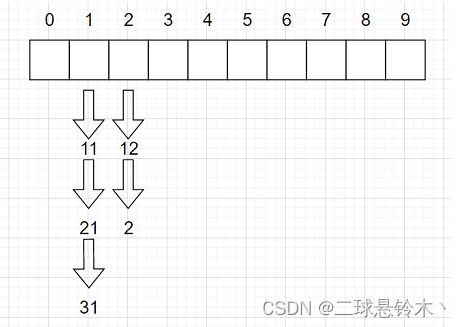
拉链法在每个元素下再拉一个数组(也可以是其他数据结构),有几个挂几个,这样就不会相互影响、抢占别人的位置了。
应用
这边贴一道笔者没长脑子挂大分的题……
test20231002 T4 string
形式化题意
给定一个字符串集合,求有多少个串使得这个串可以被断成两部分,每部分都是字符串集合中某个串的前缀。
输入
输入文件为 string.in。
为了方便选手拿暴力分,输入第一行一个整数 \(case\) 代表测试点编号。
输入第二行一个正整数 \(n\) 代表字符串集合中串个数。后面 \(n\) 行每行一个字符串。
输出
输出文件为 string.out。
输出一行一个正整数代表答案。
样例
样例 #1 输入
0
2
ab
bc
样例 #1 输出
9
说明:串 \(\texttt{aa}\)、\(\texttt{aba}\)、\(\texttt{aca}\)、\(\texttt{abac}\)、\(\texttt{acab}\)、\(\texttt{aac}\)、\(\texttt{aab}\)、\(\texttt{acac}\)、\(\texttt{abab}\) 都可以,一共 9 种。
样例 #2 输入
0
3
baab
bcaa
caca
样例 #2 输出
115
范围
设第 \(i\) 个字符串长度为 \(S_i\),\(S_i\) 之和为 \(S\)。
对于测试点 \(1-2\),\(S\le 50\);
对于测试点 \(3-6\),\(S\le 1000\);
对于测试点 \(7-14\),\(n\le 10000\),\(S_i\le 30\);
对于所有数据,保证 \(S_i\) 不为 \(0\),\(S\le 106\)。
具体做法
哈希即可。
具体地,笔者做法是令:
对于任意两个字符串的哈希函数 \(f(x)\),\(g(x)\),定义这两个字符串相等当且仅当 \(f(x)=g(x)\)。
这样就拿到了 30 pts 的高分……
一些玩法
哈希代替 KMP。
#include <iostream>
#include <cstring>
#define MAXL 1000005
using namespace std;
const int base = 19260817;
const int mod = 1e9 + 7;
int lena, lenb;
char a[MAXL], b[MAXL];
int nxt[MAXL], has[MAXL], sum;
int bas[MAXL];
int main(){
ios::sync_with_stdio(false);
cin.tie(0);cout.tie(0);
cin >> a + 1 >> b + 1;
lena = strlen(a + 1);lenb = strlen(b + 1);
int j = 0;
for(int i = 2 ; i <= lenb ; i ++){
while(j != 0 && b[i] != b[j + 1])j = nxt[j];
if(b[i] == b[j + 1])j++;
nxt[i] = j;
}
j = 0;
for(int i = 1 ; i <= lena ; i ++){
while(j != 0 && a[i] != b[j + 1])j = nxt[j];
if(a[i] == b[j + 1])j++;
if(j == lenb)cout << i - lenb + 1 << endl;
}
for(int i = 1 ; i <= lenb ; i ++){
if(i != 1)cout << " ";
cout << nxt[i];
}cout << endl;
for(int i = 1 ; i <= lena ; i ++)
has[i] = (has[i - 1] * base + a[i]) % mod;
bas[0] = 1;
for(int i = 1 ; i <= lena ; i ++)
bas[i] = bas[i - 1] * base;
for(int i = 1 ; i <= lenb ; i ++)
sum = (sum * base + b[i]) % mod;
for(int i = lenb ; i <= lena ; i ++)
if(has[i] - has[i - lenb] * bas[lenb] == sum)cout << i - lenb + 1 << endl;
cout << endl;return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号