
AutoAgent在WSL下的安装和使用(本地ollama + qwen3:8b)
感谢:https://blog.csdn.net/j8267643/article/details/151626900

AutoAgent
https://github.com/HKUDS/AutoAgent
AutoAgent 有一个开箱即用的多代理系统,您可以在起始页中选择它来使用它。这个多智能体系统是一个通用的人工智能助手,具有与 OpenAI 的深度研究相同的功能,并且在 GAIA 基准测试中与其相当的性能。user mode
🚀 高性能:使用 Claude 3.5 而不是 OpenAI 的 o3 模型匹配 Deep Research。
🔄 模型灵活性:兼容任何 LLM(包括 Deepseek-R1、Grok、Gemini 等)
💰 性价比高:Deep Research 每月 200 美元订阅的开源替代品
🎯 用户友好:易于部署的 CLI 界面可实现无缝交互
📁 文件支持:处理文件上传以增强数据交互
AutoAgent 最显着的特点是其自然语言定制功能。与其他代理框架不同,AutoAgent 允许您仅使用自然语言创建工具、代理和工作流。只需选择 或 模式,即可开始通过对话构建代理的旅程。agent editorworkflow editor
WSL下安装AutoAgent
依次执行如下命令:
#t先安装AutoAgent虚拟环境及所需
sudo apt update && sudo apt upgrade -y
sudo apt install --install python3.12 python3.12-venv python3-pip python3-tk ffmpeg
#后两个python3-tk ffmpeg我没装,结果运行auto main时报错了
# 安装构建依赖(如需)
sudo apt install build-essential libssl-dev libffi-dev
# 创建项目目录
mkdir autoagent
cd autoagent
# 创建虚拟环境(二选1)
python3 -m venv autoagent
python3.12 -m venv autoagent
#如果python3.12 -m venv autoagent建立虚拟环境不成功,可能是pip包的问题,则改成下面不带pip的安装命令:
# 创建不包含pip的虚拟环境,后续再手动安装pip
python3 -m venv --without-pip autoagent
#激活虚拟环境
source autoagent/bin/activate
#再手动安装pip
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python get-pip.py
#设置国内代理
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
#到此,可以安装autoagent啦
pip install -e .
到此,安装完毕,看了一下,文件好大:8.8G
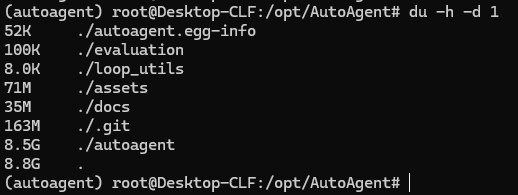
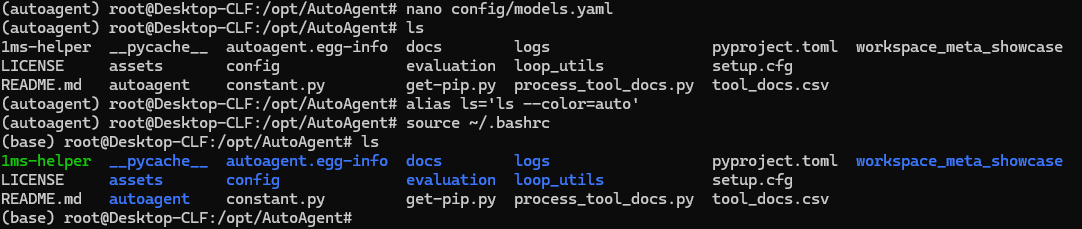
不知道为啥,我的虚拟环境启用之后,ls命令显示的颜色就没有了。查了一下,运行以下两个命令可修复:
alias ls='ls --color=auto'
source ~/.bashrc
环境配置
API 密钥设置
创建一个环境变量文件,就像 一样,并为您要使用的 LLM 设置 API 密钥。并非每个 LLM API Key 都是必需的,请使用您需要的。.env.template
# 复制环境模板
cp .env.template .env
# 配置API密钥(编辑.env文件)
# 必需配置
GITHUB_AI_TOKEN=your_github_token
# 可选配置(按需启用)
OPENAI_API_KEY=sk-your-openai-key
ANTHROPIC_API_KEY=your-anthropic-key
DEEPSEEK_API_KEY=your-deepseek-key
GEMINI_API_KEY=your-gemini-key
MISTRAL_API_KEY=your-mistral-key
HUGGINGFACE_API_KEY=your-hf-key
GROQ_API_KEY=your-groq-key
多模型配置示例
先在AutoAgent目录下mkdir config,再执行nano config/models.yaml,参考以下内容:
# config/models.yaml
default_provider: "anthropic"
providers:
anthropic:
model: "claude-3-5-sonnet-20241022"
api_key: ${ANTHROPIC_API_KEY}
openai:
model: "gpt-4o"
api_key: ${OPENAI_API_KEY}
base_url: "https://api.openai.com/v1"
deepseek:
model: "deepseek/deepseek-chat"
api_key: ${DEEPSEEK_API_KEY}
base_url: "https://api.deepseek.com/v1"
gemini:
model: "gemini/gemini-2.0-flash"
api_key: ${GEMINI_API_KEY}
fallback_order: ["anthropic", "openai", "deepseek", "gemini"]
我想设置为自己的ollama中的模型,地址是localhost:11344,没有 api_key, model有两个,一个是deepseek-r1:8b,另一个是qwen3:8b,怎么实现呢?
方法一:使用one-api把ollama转化为openai标准接口
one-api设置参考我的这个文章:
https://www.cnblogs.com/treasury-manager/p/18812761
布署完成后用下面的命令测试是否OK
#测试二,测试qwen3:8b
curl http://localhost:3000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-xxx" \
-d '{
"model": "qwen3:8b",
"messages": [{"role": "user", "content": "你好,我是 qwen3"}]
}'
然后在WSL下直接运行下面的命令:
COMPLETION_MODEL="openai/qwen3:8b" \
LLM_BASE_URL="http://localhost:3000/v1" \
LLM_API_KEY="sk-XXX" \
FN_CALL=False \
auto main
关键参数说明:
- COMPLETION_MODEL需遵循 LiteLLM 格式,由于通过 OpenAI 兼容端点调用,前缀为 openai/,后跟模型名 qwen3:8b(与 One-API 中配置的模型名一致)。
- LLM_BASE_URL指向你的 One-API 服务地址(即命令中的 http://localhost:3000/v1 ),与 curl 命令中的请求地址对应。
- LLM_API_KEY填写 One-API 的访问密钥(即命令中的 sk-xxx),用于身份验证。
- 添加 FN_CALL=False 环境变量,明确禁用函数调用模式,适配不支持该功能的模型(如你使用的 qwen3:8b)。
运行成功,哈哈哈!!!
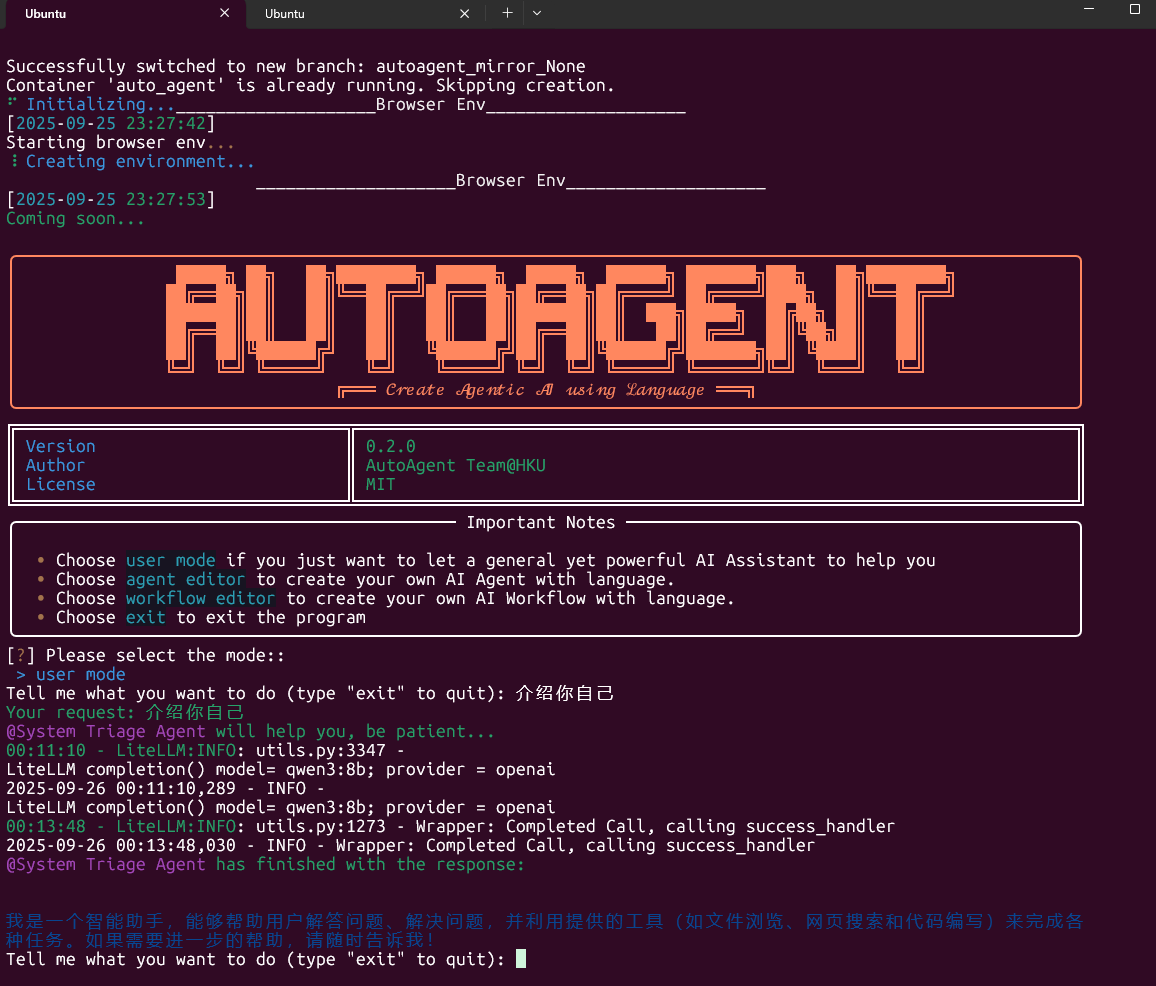
思考:
AutoAgent 本身是通过 LiteLLM 支持第三方 LLM 代理(包括 One-API),autoagent 0.1.0 requires litellm==1.55.0,
可通过环境变量或配置文件指定 One-API 的接口信息。
我们可通过启动命令设置环境变量,在启动 AutoAgent 时,直接通过环境变量指定 ollama 的基础 URL、模型名称和 API 密钥
减少中间环节(无需 One-API 转发),降低延迟。
#测试本地ollama模型可用性
curl http://localhost:11434/api/generate -d '{"model":"qwen3:8b","prompt":"hello"}'
#再在WSL下运行以下命令
COMPLETION_MODEL="ollama/qwen3:8b" \ # 模型名需以 "ollama/" 为前缀,与本地 Ollama 模型名一致
LLM_BASE_URL="http://localhost:11434" \ # 本地 Ollama 服务地址
LLM_API_KEY="ollama" \ # Ollama 无需真实密钥,填写任意值(如 "ollama")即可
FN_CALL=False \ # 禁用函数调用(与之前一致,适配 qwen3:8b)
auto main
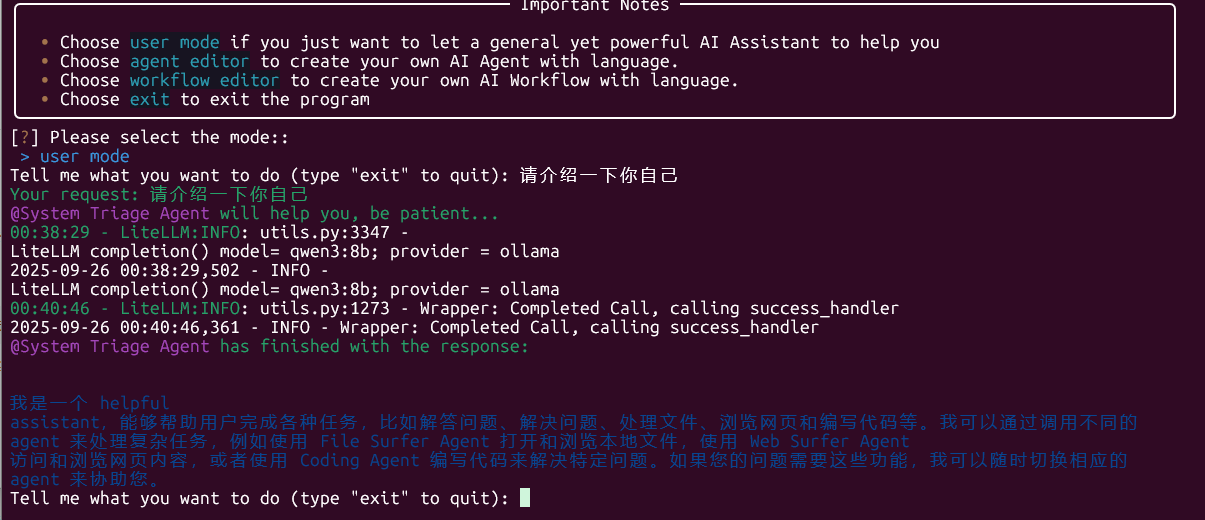
完美!
方法二:使用litellm作为代理来连接 ollama 模型(这个方法不用试了,因为litellm本身已经固化在autoagent中,不过原理依然可以学习,故而留下 )
https://docs.litellm.ai/docs/
使用litellm作为代理来连接 ollama 模型,此方法是完全可行的,并且在很多场景下是更灵活的解决方案。这种方式特别适合需要统一 API 接口、兼容多种模型调用方式的场景
核心原理
litellm 是一个开源工具,能将各种 LLM 模型(包括本地 ollama 模型)的接口转换为统一的 OpenAI 兼容格式。通过在本地启动litellm代理,AutoAgent 可以像调用 OpenAI API 一样调用 ollama 模型,无需修改太多底层代码。
步骤:
# 1. 安装litellm(带代理功能)
pip install litellm[proxy]
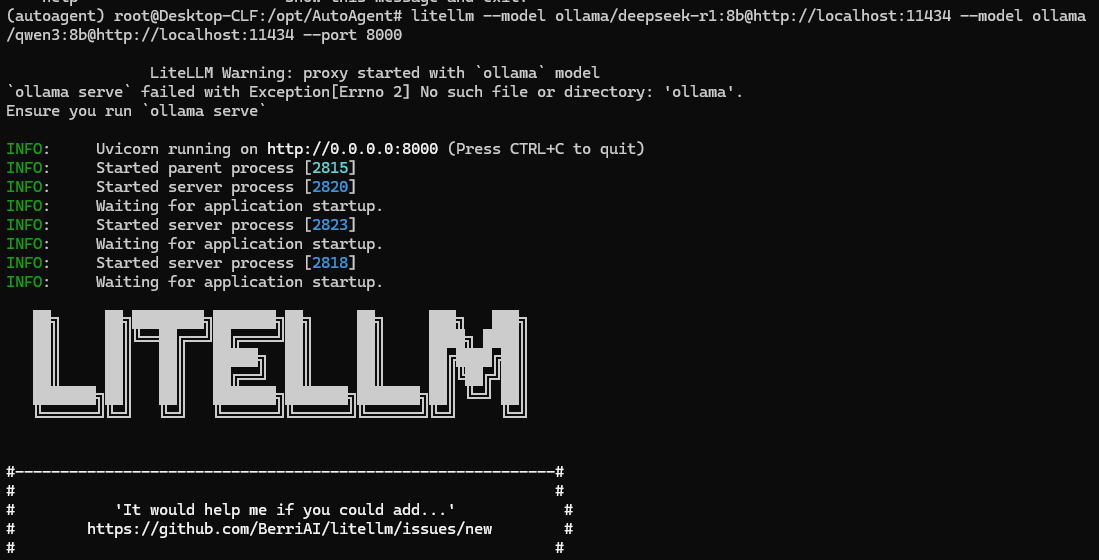
# 2. 启动代理,指定ollama模型(以deepseek-r1:8b为例)
litellm --model ollama/deepseek-r1:8b --port 11434 # 监听11434端口
# 代理 deepseek-r1:8b 模型,指定 Ollama 地址为 http://localhost:11434
litellm --model ollama/deepseek-r1:8b --ollama-base-url http://localhost:11434 --port 8000
#通过命令行参数(适合简单场景)直接在启动命令中用 --model 重复指定多个模型(需注意格式)
litellm --model ollama/deepseek-r1:8b@http://localhost:11434 --model ollama/qwen3:8b@http://localhost:11434 --port 8000
# 3. 在AutoAgent的配置文件中,将openai提供商的base_url指向litellm代理
# config/models.yaml 中修改openai配置:
openai:
model: "ollama/deepseek-r1:8b" # 或qwen3:8b
api_key: "anything" # litellm代理无需真实API密钥,填任意值即可
base_url: "http://localhost:11434" # 指向litellm代理端口
# 4. 运行AutoAgent,此时会通过litellm代理调用本地ollama模型
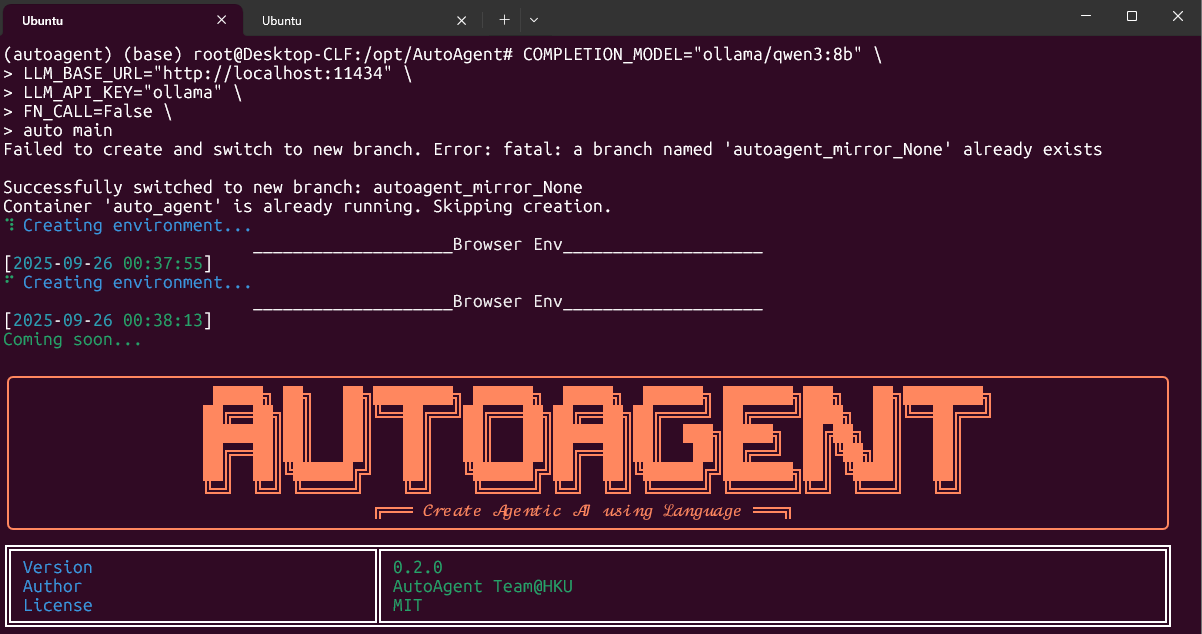
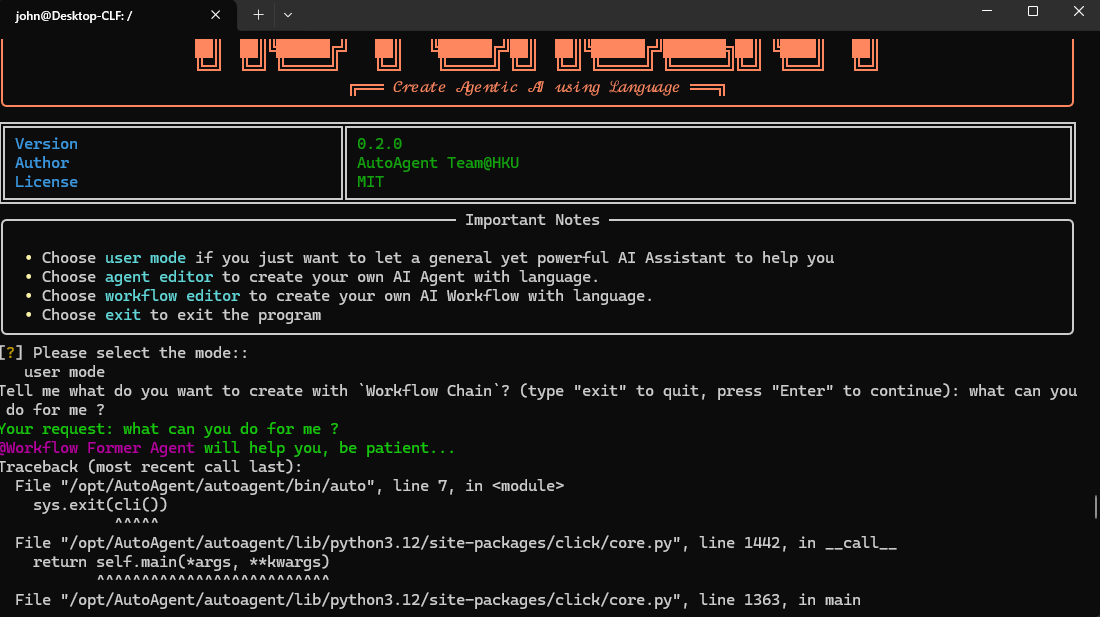
Error: fatal: a branch named 'autoagent_mirror_None' already exists 提示分支存在,直接删除仓库目录重新克隆
bash
# 删除整个仓库目录
rm -rf /opt/AutoAgent/workspace_meta_showcase/showcase_auto_agent/workplace/AutoAgent
重新运行程序,让其自动克隆仓库并创建分支
auto main
调用方式(验证是否生效)
启动代理后,可通过 OpenAI 兼容接口调用不同模型,例如用 curl 测试:
#调用 deepseek-r1:8b:
bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-r1", # 对应配置中的 model_name(或直接用 "ollama/deepseek-r1:8b")
"messages": [{"role": "user", "content": "你好,我是 deepseek-r1"}]
}'
#调用 qwen3:8b:
bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3", # 对应配置中的 model_name(或直接用 "ollama/qwen3:8b")
"messages": [{"role": "user", "content": "你好,我是 qwen3"}]
}'
关键说明
若多个模型来自同一 Ollama 服务(localhost:11434),api_base 可统一指定(命令行用 --ollama-base-url,配置文件中每个模型可复用同一地址)。
调用时,model 字段可使用配置文件中自定义的 model_name(如 deepseek-r1),也可直接使用完整名称(如 ollama/deepseek-r1:8b),两种方式均可识别。
如需为不同模型设置不同参数(如温度、最大 tokens),可在配置文件的 litellm_params 中分别指定(参考之前的 “模型参数设置” 方法)。
通过这种方式,LiteLLM 可以同时代理多个 Ollama 模型,满足多模型切换使用的需求。
致谢:https://blog.csdn.net/weixin_40101756/article/details/138812562
方法二:修改文档配置
拟修改文档如下(不知道管用不):
default_provider: "ollama" # 可改为你希望的默认提供商
providers:
anthropic:
model: "claude-3-5-sonnet-20241022"
api_key: ${ANTHROPIC_API_KEY}
openai:
model: "gpt-4o"
api_key: ${OPENAI_API_KEY}
base_url: "https://api.openai.com/v1"
deepseek:
model: "deepseek/deepseek-chat"
api_key: ${DEEPSEEK_API_KEY}
base_url: "https://api.deepseek.com/v1"
gemini:
model: "gemini/gemini-2.0-flash"
api_key: ${GEMINI_API_KEY}
# 新增ollama配置
ollama:
# 第一个模型:deepseek-r1:8b(默认使用这个)
model: "deepseek-r1:8b"
# 无需API密钥,留空或删除该字段
api_key: ""
# ollama的本地地址
base_url: "http://localhost:11344/v1"
# 第二个模型可通过调用时指定model参数切换使用
fallback_order: ["ollama", "anthropic", "openai", "deepseek", "gemini"] # 加入ollama到 fallback 顺序
关键修改说明:
新增了 ollama 提供商配置,包含:
base_url 设置为你的本地 ollama 地址(注意添加 /v1 路径,符合 OpenAI 兼容 API 规范)
由于 ollama 不需要 API 密钥,将 api_key 设为空字符串
默认模型设为 deepseek-r1:8b
可以根据需要修改 default_provider 为 "ollama",使其成为默认使用的模型提供商
将 ollama 添加到 fallback_order 中,使其参与故障转移机制
使用第二个模型的方式:
当需要使用 qwen3:8b 时,在调用模型的代码中指定模型参数为 qwen3:8b 即可,无需修改配置文件。例如(伪代码):
python
运行
model = get_model(provider="ollama", model="qwen3:8b")
这样的配置既保留了原有模型,又添加了本地 ollama 的两个模型,且无需 API 密钥即可使用。但此方法二未经验证。
如何使用 AutoAgent
1.(SOTA 🏆 开放深度研究)user mode
AutoAgent 有一个开箱即用的多代理系统,您可以在起始页中选择它来使用它。这个多智能体系统是一个通用的人工智能助手,具有与 OpenAI 的深度研究相同的功能,并且在 GAIA 基准测试中与其相当的性能。user mode
🚀 高性能:使用 Claude 3.5 而不是 OpenAI 的 o3 模型匹配 Deep Research。
🔄 模型灵活性:兼容任何 LLM(包括 Deepseek-R1、Grok、Gemini 等)
💰 性价比高:Deep Research 每月 200 美元订阅的开源替代品
🎯 用户友好:易于部署的 CLI 界面可实现无缝交互
📁 文件支持:处理文件上传以增强数据交互
🎥 深度研究(又名用户模式)
2.(无工作流的代理创建)agent editor
AutoAgent 最显着的特点是其自然语言定制功能。与其他代理框架不同,AutoAgent 允许您仅使用自然语言创建工具、代理和工作流。只需选择 或 模式,即可开始通过对话构建代理的旅程。agent editorworkflow editor
3.(使用工作流创建代理)workflow editor
您还可以使用自然语言描述和模式创建代理工作流,如下图所示。(提示:此模式暂时不支持工具创建。workflow editor
具体使用指南
1. CLI模式快速启动
# 启动完整模式(用户模式+代理编辑+工作流编辑)
auto main
*在运行这个auto main命令之前,有个12.9G的依赖库要安装:最好先手动运行:sudo docker pull tjbtech1/metachain:amd64_latest
如果拉不下来,就加1毫秒的代理:sudo bash -c "$(curl -sSL https://n3.ink/helper)"
再运行:
sudo docker pull docker.1ms.run/tjbtech1/metachain:amd64_latest
下载完成后,要将其重命名(本质是添加一个新标签),例如改为 tjbtech1/metachain:amd64_latest,可以执行:
bash
sudo docker tag docker.1ms.run/tjbtech1/metachain:amd64_latest tjbtech1/metachain:amd64_latest
命令说明:
docker tag:用于给镜像添加新标签的命令。
验证重命名结果:执行以下命令查看镜像列表,确认新标签已添加:
bash
sudo docker images | grep metachain
如果需要,可以删除原标签(保留新标签即可):
bash
sudo docker rmi docker.1ms.run/tjbtech1/metachain:amd64_latest
这样操作后,Docker 会将新标签的镜像识别为 tjbtech1/metachain:amd64_latest,满足程序对镜像名称的要求。
然后再安装playwright(依赖)
虚拟环境下,运行:playwright install
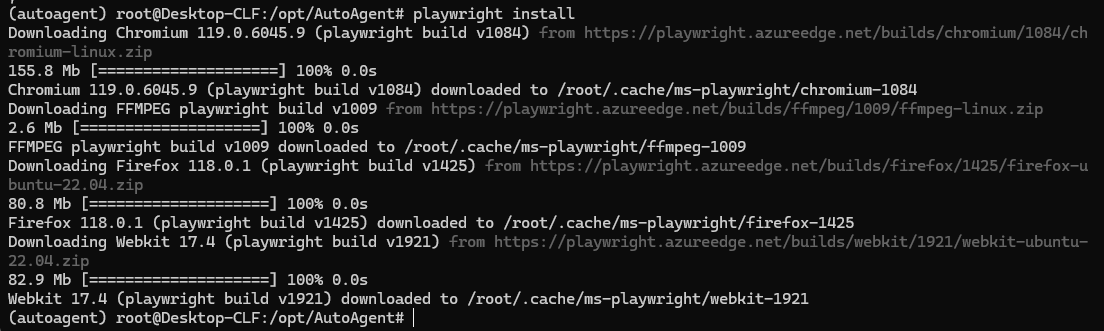
我的天哪,经过千难万险,下载了20G数据之后,终于见得真容了:
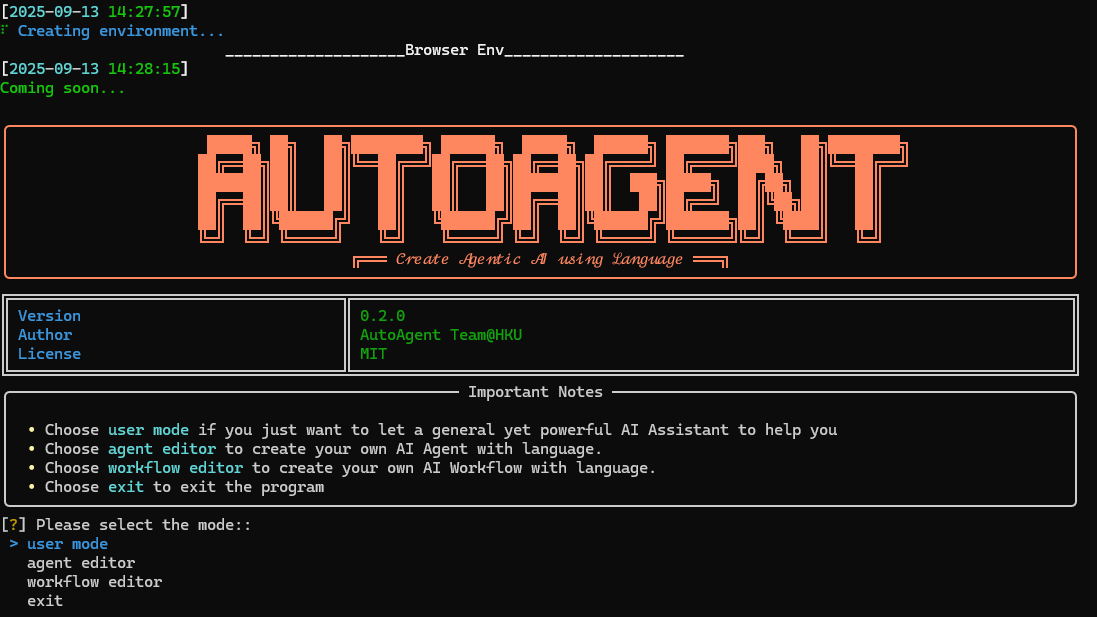
但是一运行具体的request,就遇到错误提示:
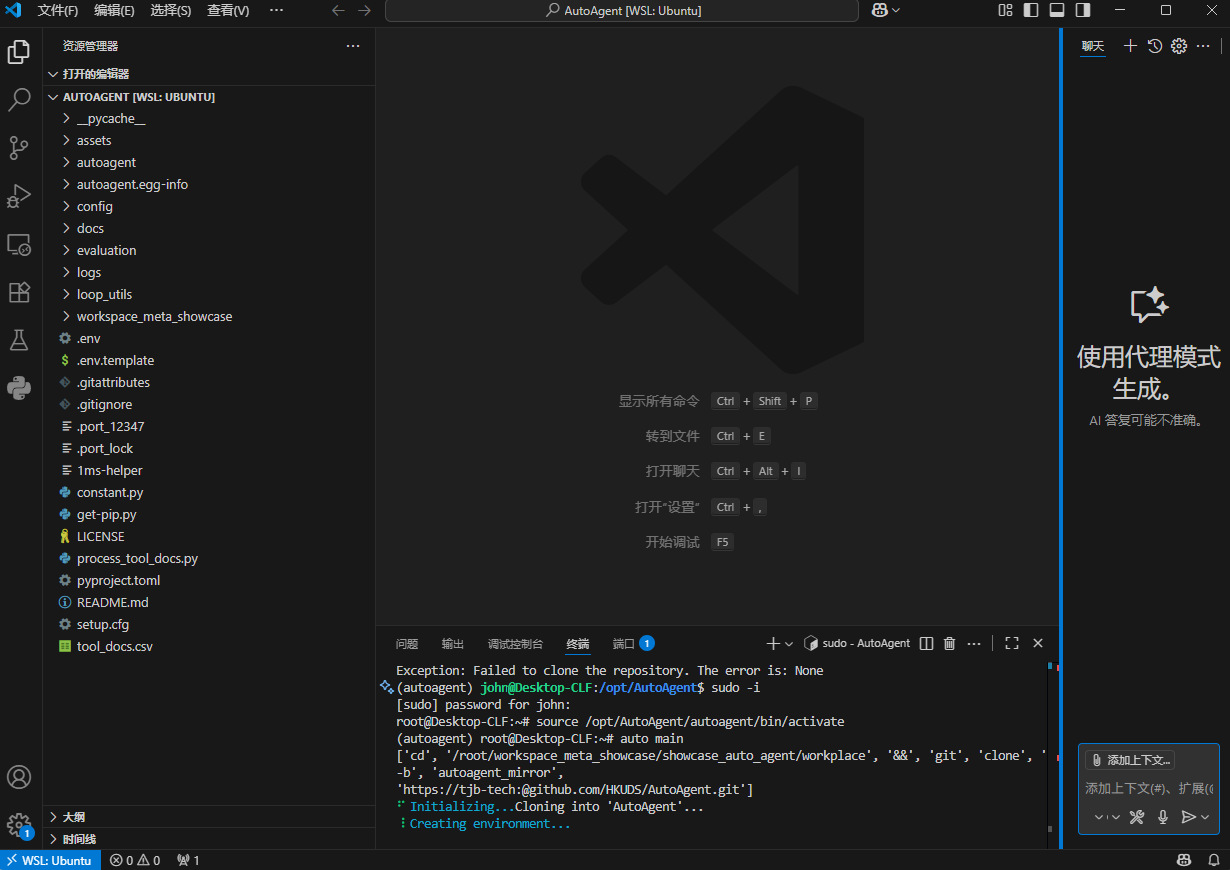
在vs code下使用 AutoAgent(没搞定,权限有问题,和WSL的保存路径也不一样,麻烦)
命令行输入:
#切换回root用户
sudo -i
#切换到虚拟环境
source /opt/AutoAgent/autoagent/bin/activate
运行auto main
2. 或仅启动深度研究模式
auto deep-research
3. 使用特定模型
COMPLETION_MODEL="gpt-4o" auto main
4. 自定义端口和容器名
auto main --port 8080 --container_name "my-agent"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号