
WSL2安装DOCKER加载Nvidia驱动再运行Ollama+Deepseek R1+One API
参考:https://zhuanlan.zhihu.com/p/28098780023
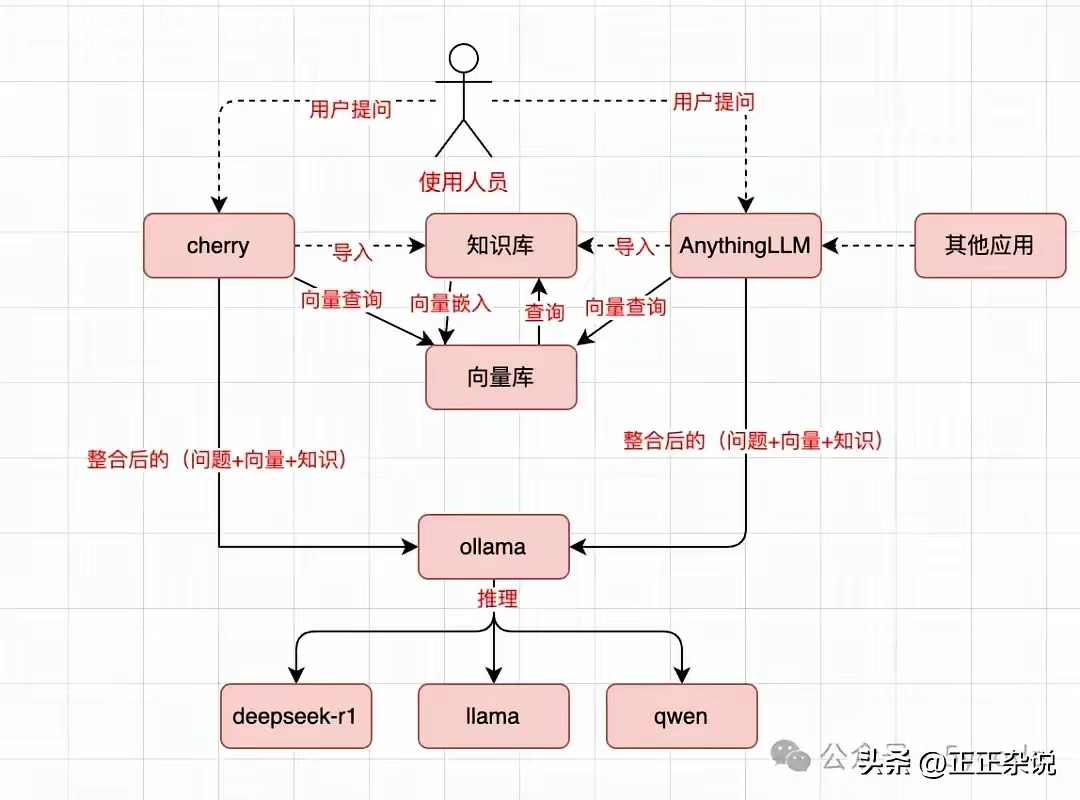
WSL2安装DOCKER
安装Docker Desktop即可,然后设置它与WSL相关的选项
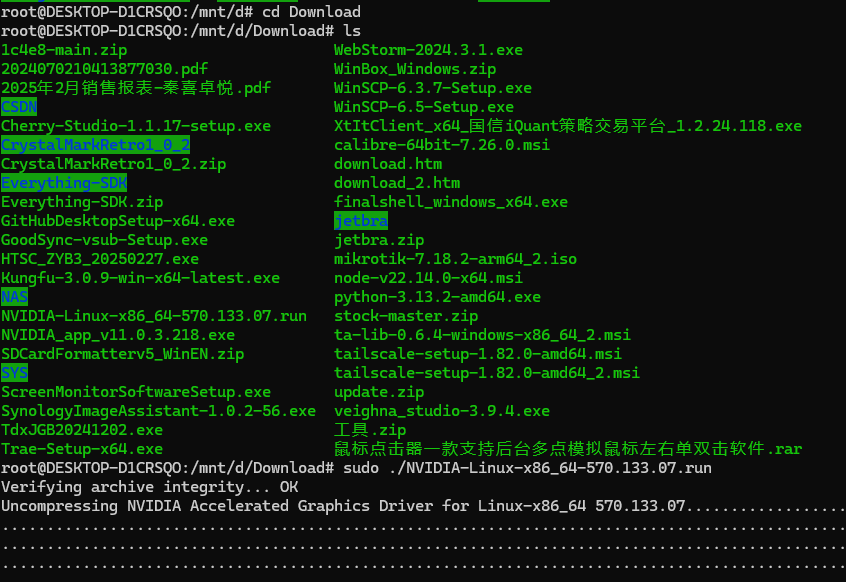
下载Nvidia在linux下的驱动
注意在Nvidia官网找到自己对应的驱动,我的是:NVIDIA-Linux-x86_64-570.133.07.run
在wsl下进入windows下载的目录,然后运行安装命令: sudo ./NVIDIA-Linux-x86_64-570.133.07.run
如果不能运行,就先运行:chmod +x NVIDIA-Linux-x86_64-570.133.07.run
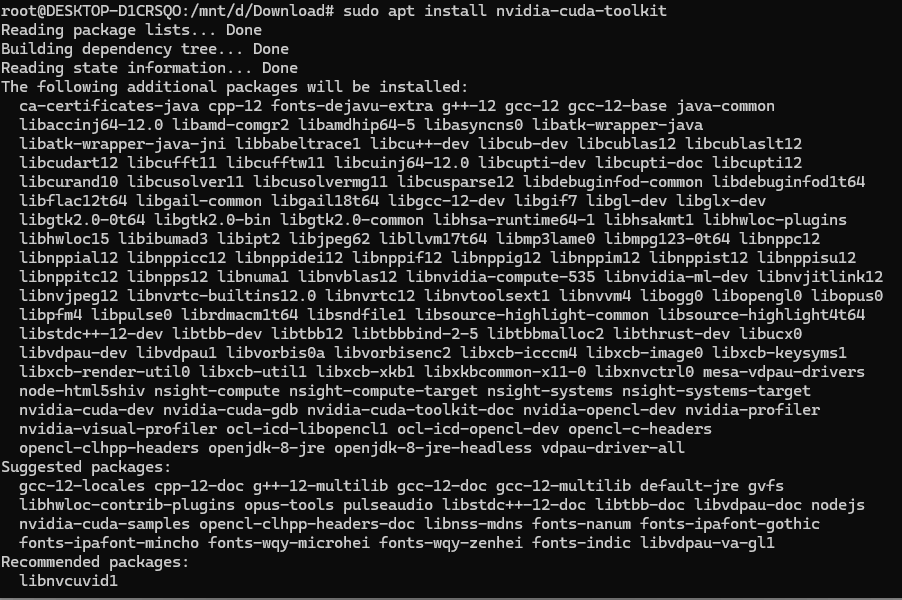
然后运行命令:sudo apt install nvidia-cuda-toolkit
正常安装完后可以运行nvidia-smi命令,查看已经安装的驱动版本
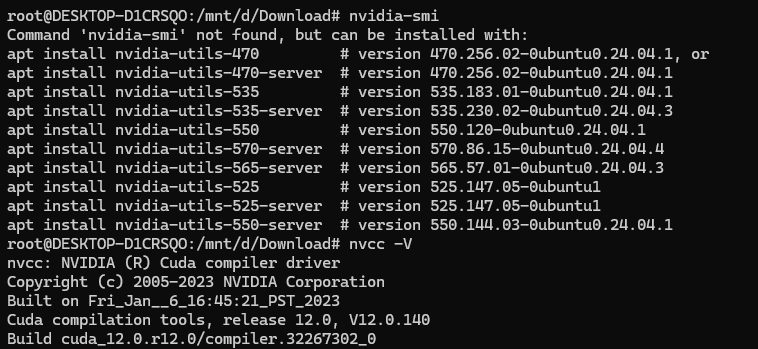
如果不行,我只能按它提示运行:apt install nvidia-utils-570-server (因为这个是最接近我的驱动的那个版本)
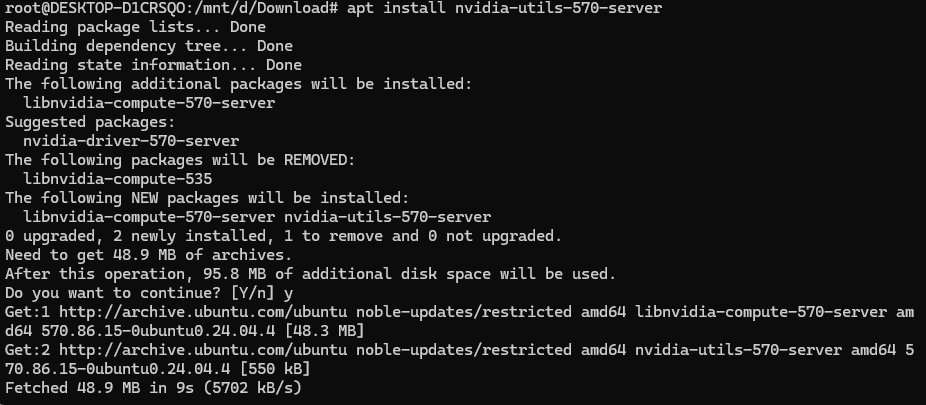
正常安装完后,再运行,可以看到驱动版本出来了:
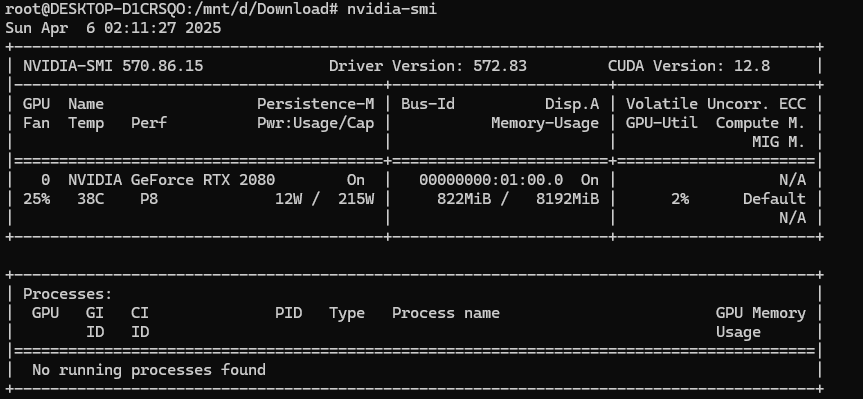
docker安装Ollama
通用命令:docker pull ollama/ollama
加速镜像命令:docker pull docker.1ms.run/ollama/ollama
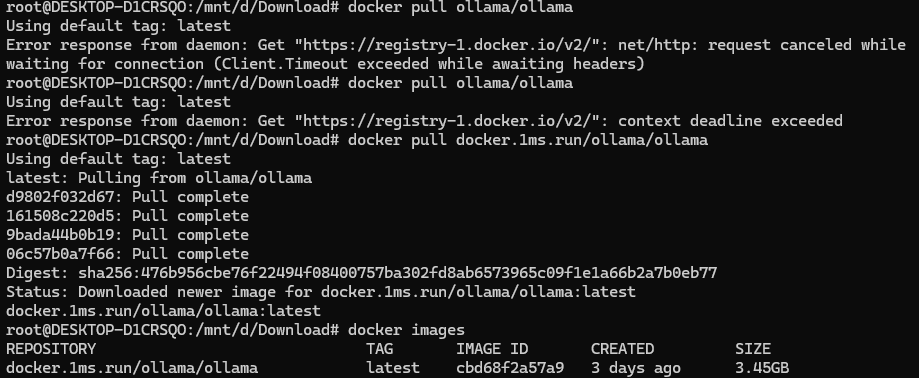
运行ollama容器及英伟达toolkit
参考:https://ollama.cadn.net.cn/docker.html
运行容器,可以等一会儿再运行
docker run -d --name ollama -v /home/docker/ollama:/root/.ollama -p 11434:11434 docker.1ms.run/ollama/ollama
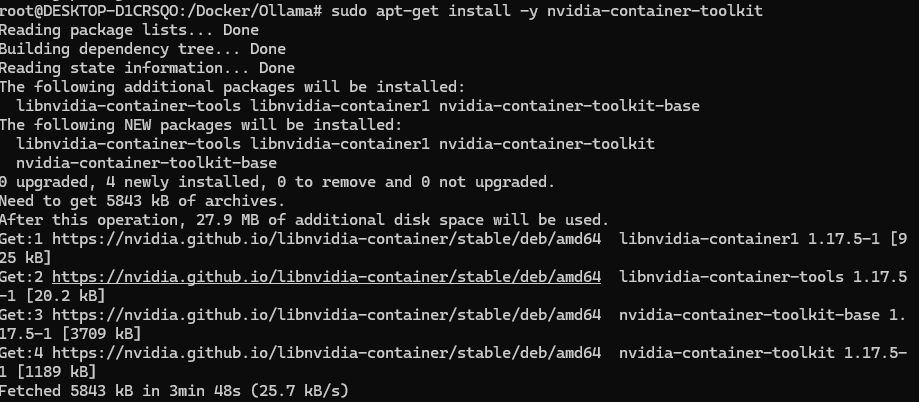
使用 Apt 安装,配置存储库
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey \
| sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list \
| sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' \
| sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
安装 NVIDIA Container Toolkit 软件包
sudo apt-get install -y nvidia-container-toolkit
配置 Docker 以使用 Nvidia 驱动程序
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
启动ollama容器并下载模型
Ollama 下载:https://ollama.com/download
Ollama 官方主页:https://ollama.com
Ollama 官方 GitHub 源代码仓库:https://github.com/ollama/ollama/
官网提供了一条命令行快速安装的方法(普通安装)。
curl -fsSL https://ollama.com/install.sh | sh
带有GPU的ollama安装
docker run -d --name ollama --gpus=all -v /home/docker/ollama:/root/.ollama -p 11434:11434 docker.1ms.run/ollama/ollama
Ollama安装完毕后,还需要继续下载大模型,支持的大模型可以在Ollama官网找到:https://ollama.com/library
在Ollama中安装运行qwen3:14b
https://ollama.com/library/qwen3:14b
在ollama容器中执行命令:
docker exec -it ollama ollama run qwen3:14b
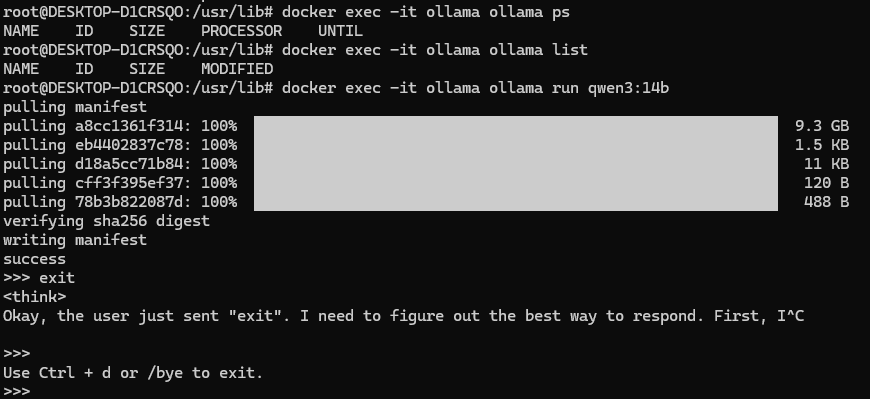
在Ollama中安装运行Deepseek R1
https://ollama.com/library/deepseek-r1
安装命令:
docker exec -it ollama ollama run deepseek-r1:7b
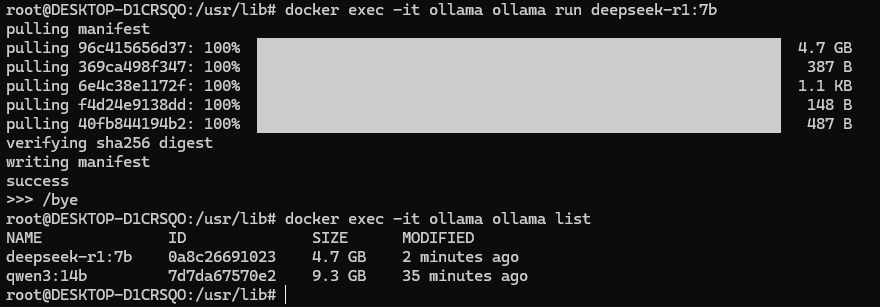
更新模型的方法
#进入ollama容器
root@DESKTOP-D1CRSQO:~# docker exec -it ollama bash
root@988d17197d71:/# ollama list
NAME ID SIZE MODIFIED
deepseek-r1:7b 0a8c26691023 4.7 GB 2 weeks ago
qwen3:14b 7d7da67570e2 9.3 GB 2 weeks ago
#删除ollama容器中的AI模型
root@988d17197d71:/# ollama rm deepseek-r1:7b
deleted 'deepseek-r1:7b'
root@988d17197d71:/# ollama list
NAME ID SIZE MODIFIED
qwen3:14b 7d7da67570e2 9.3 GB 2 weeks ago
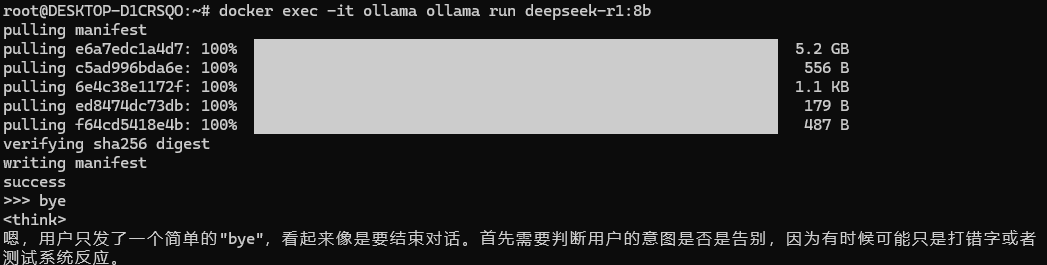
使用/bye退出容器,使用下面的命令来更新latest模型:
docker exec -it ollama ollama run deepseek-r1:8b
更新ollama
在 WSL或Linux 系统上,请重新运行安装脚本
curl -fsSL https://ollama.com/install.sh | sh
Ollama 支持的 API 端点
端点 说明
http://localhost:11434/api/generate 生成文本(DeepSeek LLM)
http://localhost:11434/api/tags 列出可用模型
http://localhost:11434/api/show?name=deepseek-coder 查看模型信息
http://localhost:11434/api/pull 下载新模型
你可以在终端输入以下命令来查看 DeepSeek 模型是否正确加载:
curl http://localhost:11434/api/show?name=deepseek-coder
返回示例:
{
"name": "deepseek-coder",
"size": "33b",
"parameters": {...}
}
总结
-
Ollama 运行的 DeepSeek 端口是 11434,不是 8000。 -
使用 http://localhost:11434/api/generate 进行推理,而不是 OpenAI 的 /v1/chat/completions。 -
Ollama API 采用 "prompt" 代替 "messages",请求格式不同。 -
可以使用 stream=True 实现流式输出,提高交互体验。
给ollama设置可视化界面
Ollama默认没有提供WEB界面,输入命令进入容器,然后通过命令行来使用:
docker exec -it ollama /bin/bash
Cherry Studio
我觉得它比open-webui好用,所以优先介绍它
https://www.cherry-ai.com/
安装教程:https://docs.cherry-ai.com/pre-basic/installation
CherryStudio 支持多种添加数据的方式:
- 文件夹目录:可以添加整个文件夹目录,该目录下支持格式的文件会被自动向量化;
- 网址链接:支持网址 url,如https://docs.siliconflow.cn/introduction;
- 站点地图:支持 xml 格式的站点地图,如https://docs.siliconflow.cn/sitemap.xml;
- 纯文本笔记:支持输入纯文本的自定义内容。
提示:
导入知识库的文档中的插图暂不支持转换为向量,需要手动转换为文本;
使用网址作为知识库来源时不一定会成功,有些网站有比较严格的反扒机制(或需要登录、授权等),因此该方式不一定能获取到准确内容。创建完成后建议先搜索测试一下。
一般网站都会提供sitemap,如CherryStudio的sitemap,一般情况下在网站的根地址(即网址)后加/sitemap.xml可以获取到相关信息。如aaa.com/sitemap.xml 。
如果网站没提供sitemap或者网址比较杂可自行组合一个sitemap的xml文件使用,文件暂时需要使用公网可直接访问的直链的方式填入,本地文件链接不会被识别。
可以让AI生成sitemap文件或让AI写一个sitemap的HTML生成器工具;
直链可以使用oss直链或者网盘直链等方式来生成。如果没有现成工具也可到ocoolAI官网,登录后使用网站顶栏的免费文件上传工具来生成直链。
安装open-webui
如果你希望通过更加友好的 Web 界面来与 Ollama 进行交互,推荐使用 Open-webui。你可以使用以下命令来部署 Open-webui 容器:
参考:https://docs.openwebui.com/getting-started/quick-start
命令:docker pull ghcr.io/open-webui/open-webui:main
如果上面这个拉不下来,就试试1毫秒加速:https://1ms.run/r/dyrnq/open-webui
命令:docker pull docker.1ms.run/dyrnq/open-webui
方法一:
与 Ollama 在同一台服务器上部署:
docker run -d -p 8080:8080 --add-host=host.docker.internal:host-gateway -v /home/docker/open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
与 Ollama 不在同一台服务器上部署:
docker run -d -p 8080:8080 -e OLLAMA_BASE_URL=http://你服务器的ip地址:11434 -v /home/docker/open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
说明:
docker run:这是 Docker 的基本命令,用于启动一个新的容器。
-d:表示在后台运行容器,即启动后容器不会立即退出。
-p 8080:8080:将容器内部的 8080 端口映射到宿主机的 8080 端口。这样,你就可以通过 http://localhost:8080 来访问 Open-webui。
-e OLLAMA_BASE_URL=http://你服务器的ip地址:11434:设置环境变量 OLLAMA_BASE_URL,告诉 Open-webui Ollama 服务的地址。这里的 http://你服务器的ip地址:11434 需要替换成你实际的 Ollama 服务地址。
-v /home/docker/open-webui:/app/backend/data:将本地目录 /home/docker/open-webui 挂载到容器内的 /app/backend/data 目录。这个目录通常用于存放 Open-webui 的数据和配置文件。
--name open-webui:给容器起一个名字,方便管理。
--restart always:设置容器在退出后自动重启。
ghcr.io/open-webui/open-webui:main:指定要运行的镜像。ghcr.io/open-webui/open-webui 是镜像仓库地址,main 是镜像标签。
方法二:
原文链接:https://blog.csdn.net/qq_36693723/article/details/145597221
如果你电脑安装了ollama,不使用gpu,使用如下命令:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
为了应用支持Nvidia GPU的open webui,使用如下命令:
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
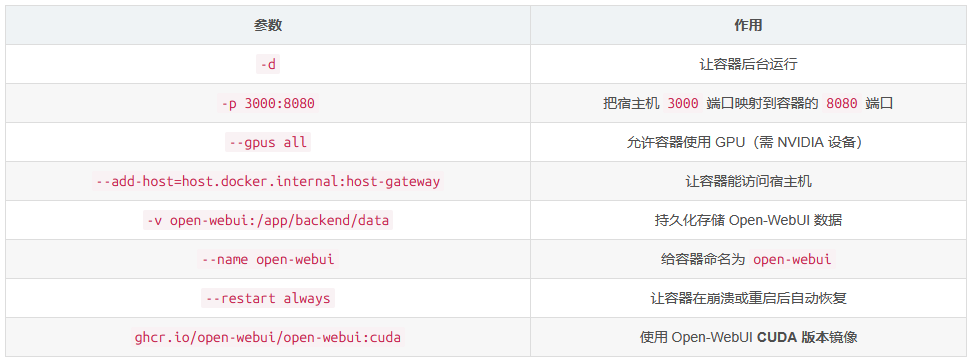
我自己用的命令:
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always docker.1ms.run/dyrnq/open-webui:cuda
至于到底用哪个命令,取决于你的DOCKER里的image的名字,用以下两个名字(2选1)查看即可:
#哪个能用就用哪个吧
docker exec -it ollama ollama ps
docker exec -it ollama ollama list

优化命令(可选)
启用支持GPU的open webui,并增加健康检查:
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway --health-cmd "curl -fsSL http://localhost:8080 || exit 1" --health-interval 60s --health-retries 5 --health-timeout 20s --health-start-period 60s --restart=always -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:cuda
我自己用的命令:
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway --health-cmd "curl -fsSL http://localhost:8080 || exit 1" --health-interval 60s --health-retries 5 --health-timeout 20s --health-start-period 60s --restart=always -v open-webui:/app/backend/data --name open-webui docker.1ms.run/dyrnq/open-webui:cuda
-
增加了健康检查机制(--health-cmd)
(基础版):
仅依靠 --restart=always,Docker 只有在容器完全崩溃时才会重启它。
如果 Web 服务挂掉了(但容器仍然运行),Docker 无法检测到,导致 WebUI 看似“正常运行”,但实际上用户无法访问。优化(改进版):
通过 --health-cmd "curl -fsSL http://localhost:8080 || exit 1",每 60 秒检查一次 API 是否存活,确保 WebUI 真正可用。
如果 API 失去响应,Docker 会自动将容器标记为 unhealthy,并可能触发重启。
完成后,打开浏览器访问 http://localhost:8080,你将可以通过 Open-webui 界面与 Ollama 进行交互,体验更加直观的操作。
我实际访问的:http://localhost:3000/auth?redirect=%2F
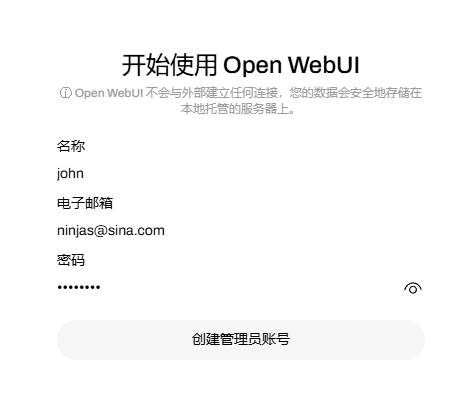
哈哈哈哈:
openwebui更新:
官方方法:
https://docs.openwebui.com/getting-started/updating
用到的工具:
https://containrrr.dev/watchtower/
将Ollama接入one-api
one-api是一个开源AI中间件服务,可以聚合各家大模型API,比如OpenAI、ChatGLM、文心一言等,聚合后提供统一的OpenAI调用方法。举个例子:ChatGLM和文心一言的API调用方法并不相同,one-api可以对其进行整合,然后提供一个统一的OpenAI调用方法,调用时只需要改变模型名称即可,从而消除接口差异和降低开发难度。
one-api具体安装方法请参考官方项目地址:https://github.com/songquanpeng/one-api
我分了两步,第一步是布署mysql(one-qpi要求),下面是docker-compose.yml的文件内容,我是在WSL里布署的:
services:
mysql:
image: mysql:latest # 当前是 9.4.0 版本
container_name: mysql-wsl
restart: always
environment:
MYSQL_ROOT_PASSWORD: password # root 密码, 自己定义
MYSQL_DATABASE: apione # 自动创建的数据库
TZ: Asia/Shanghai
ports:
- "3307:3306" # 主机端口:容器端口
volumes:
- /opt/MySQL/data:/var/lib/mysql # 数据持久化
- /opt/MySQL/conf:/etc/mysql/conf.d # 配置挂载(若有自定义配置)
- /opt/MySQL/logs:/var/log/mysql # 日志目录
networks:
- mysql-network
networks:
mysql-network:
driver: bridge
第二步是生成one-api容器
services:
one-api:
image: justsong/one-api:latest
container_name: one-api
restart: always
ports:
- "3000:3000"
environment:
- TZ=Asia/Shanghai
# 补充字符集、时间解析参数,避免初始化失败
- SQL_DSN=root:password@tcp(mysql-wsl:3306)/apione?charset=utf8mb4&parseTime=True&loc=Local
volumes:
- /opt/one-api:/data
# 加入 MySQL 所在的外部网络,确保容器名解析互通
networks:
- mysql_mysql-network #我没写错,是多个mysql_
# 声明外部网络(由 MySQL Compose 提前创建,无需重复创建)
networks:
mysql_mysql-network:
external: true
布署成功后,可访问:http://localhost:3000
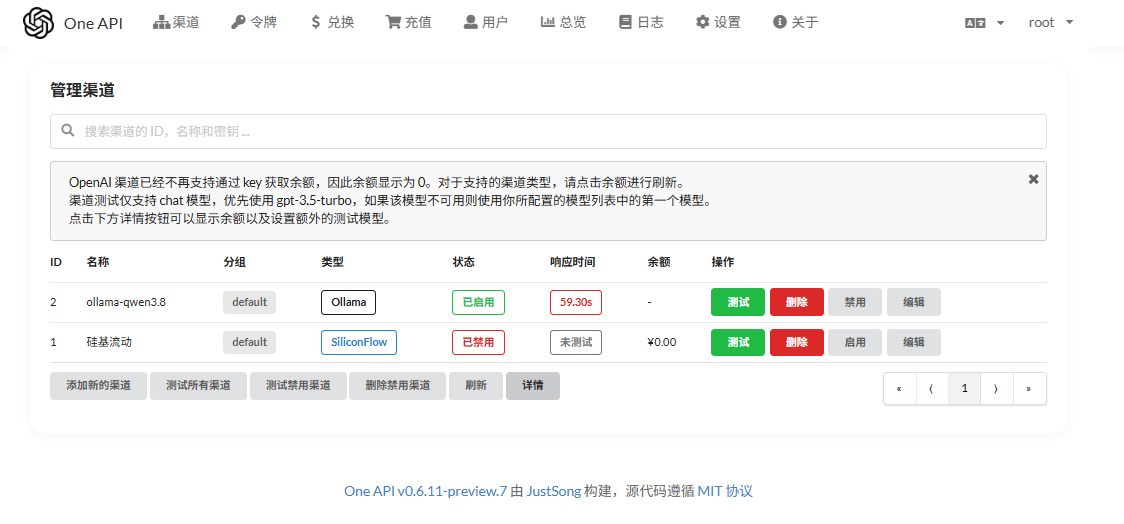
通过one-api后台 >> 渠道 >> 添加一个新的渠道。具体设置如下:
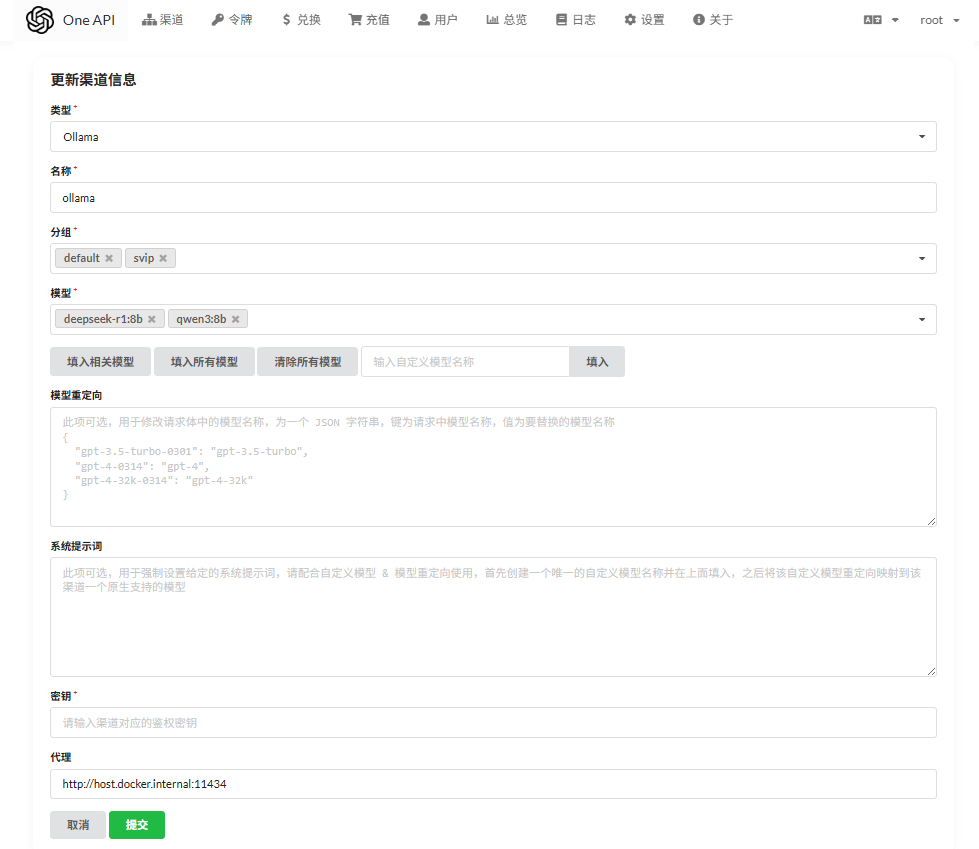
这里,我把ollama里安装的两个模型都写了进去,分别是:qwen3:8b, deepseek-r1:8b
docker网络的问题会有些麻烦
有多种思路,一种是让OneApi的容器跑在 host 网络模式下,
可使用 host.docker.internal 这个地址,当然前提都是 ollama 的 host 设置为 0.0.0.0, 在添加渠道的时候,类型选择 Ollama,
自定义模型部分填入我们部署的 deepseek-r1:8b 和 qwen3:8b , 然后代理填写 http://host.docker.internal:11434
注意:在 Linux 环境中,host.docker.internal 可能无法工作,但你可以直接使用宿主机的 IP 地址。例如,如果宿主机的 IP 地址是 192.168.1.100,可以在OneApi中使用 http://192.168.1.100:11434 来访问 Ollama 服务。
OK,然后你可以创建一个令牌 :
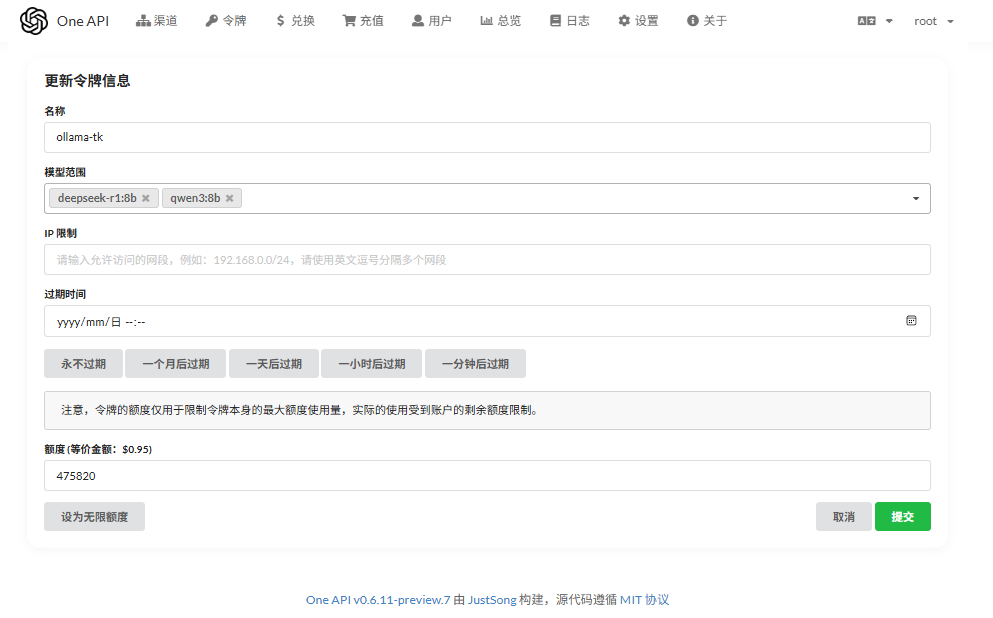
服务测试
确认 Ollama 是否正确运行
如果你使用 Ollama 部署了 DeepSeek,默认 API 运行在 11434 端口。
#首先,检查 Ollama 是否正常运行:
curl http://localhost:11434/api/tags
#如果返回:
{"models":["deepseek-coder:latest", "deepseek-chat:latest"]}
#说明 Ollama 运行正常,并且已安装 DeepSeek 模型。
#先查询服务支持的所有模型,获取正确的模型名称:
curl http://localhost:3000/v1/models \
-H "Authorization: Bearer sk-XXX"
#返回了如下结果
{"data":[{"id":"deepseek-r1:8b","object":"model","created":1626777600,"owned_by":"custom","permission":null,"root":"deepseek-r1:8b","parent":null},{"id":"qwen3:8b","object":"model","created":1626777600,"owned_by":"custom","permission":null,"root":"qwen3:8b","parent":null}],"object":"list"}
调用测试(测试成功)
使用以下命令测试调用:
注意:JSON 格式不支持这种注释# 注释符号,会导致解析失败。请彻底删除以下测试代码中所有注释内容,确保 JSON 结构纯净。
#测试一,测试deepseek-r1:8b
curl http://localhost:3000/v1/chat/completions \completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-xxx" \
-d '{
"model": "deepseek-r1:8b",
"messages": [{"role": "user", "content": "你好,测试一下"}]
}'
#测试二,测试qwen3:8b
curl http://localhost:3000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-xxx" \
-d '{
"model": "qwen3:8b",
"messages": [{"role": "user", "content": "你好,我是 qwen3"}]
}'
#测试三,测试多个role
curl http://localhost:3000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-xxx" \
-d '{
"model": "qwen3:8b",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
]
}'
注:
将 localhost:3000 替换为 one-api 的域名。
将 sk-xxx 替换为 one-api 创建的令牌。
Python 调用 Ollama 运行的 DeepSeek
参考:https://www.cnblogs.com/lidy5436/p/18711009
发送对话请求,Ollama 的 API 端点与 OpenAI 兼容 API 不同,需要使用 /api/generate:
import requests
import json
API_URL = "http://localhost:11434/api/generate" # Ollama API 端点
headers = {
"Content-Type": "application/json"
}
data = {
"model": "deepseek-coder", # 你的 DeepSeek 模型名称
"prompt": "请介绍一下 DeepSeek。",
"stream": False # 关闭流式输出
}
response = requests.post(API_URL, headers=headers, json=data)
if response.status_code == 200:
result = response.json()
print("AI 回复:", result["response"])
else:
print("请求失败:", response.status_code, response.text)
📌 注意
-
"model" 需要匹配你的 Ollama 里安装的 DeepSeek 模型,比如 "deepseek-coder"。 -
Ollama API 采用 "prompt" 而不是 "messages"。 -
端口是 11434,不是 8000。
开启流式输出
如果希望让 Ollama 流式返回 DeepSeek 的回复,可以这样处理:
import requests
import json
API_URL = "http://localhost:11434/api/generate"
headers = {
"Content-Type": "application/json"
}
data = {
"model": "deepseek-coder",
"prompt": "请介绍一下 DeepSeek。",
"stream": True # 开启流式输出
}
response = requests.post(API_URL, headers=headers, json=data, stream=True)
for line in response.iter_lines():
if line:
json_data = json.loads(line.decode("utf-8"))
print(json_data.get("response", ""), end="", flush=True)
这样可以实时打印 DeepSeek 的 AI 回复。
One API 使用方法
在渠道页面中添加你的 API Key,之后在令牌页面中新增访问令牌。
之后就可以使用你的令牌访问 One API 了,使用方式与 OpenAI API 一致。
你需要在各种用到 OpenAI API 的地方设置 API Base 为你的 One API 的部署地址,例如:https://openai.justsong.cn,API Key 则为你在 One API 中生成的令牌。
注意,具体的 API Base 的格式取决于你所使用的客户端。
OPENAI_API_KEY="sk-xxxxxx"
OPENAI_API_BASE="https://:/v1"
python 调用 one api 服务测试(我还没试)
我们用获取到的令牌来测试一下。其调用方式与 OpenAI API 一致,只需将:
model_dict的key,就是在one api“创建新渠道”里定义的“名称”
OpenAI 的网址 'base_url',改成你部署的 OneAPI 的网址,例:'http://localhost:3000/v1';
OpenAI 的令牌 'api_key',改成你的令牌,测试的示例代码如下:
from openai import OpenAI
model_dict = {
'ollama': {
'api_key': 'sk-xxx',
'base_url': 'http://localhost:3000/v1',
'model_name': 'qwen3:8b'
}
}
class LLM_API:
def __init__(self, api_key, base_url, model):
self.client = OpenAI(
api_key=api_key,
base_url=base_url,
)
self.model = model
def __call__(self, messages, temperature=0.7):
completion = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=temperature,
)
return completion.choices[-1].message.content
if __name__ == '__main__':
model = 'ollama'
llm = LLM_API(model_dict[model]['api_key'], model_dict[model]['base_url'], model_dict[model]['model_name'])
user_question = "你是谁"
messages = [{"role": "user", "content": user_question},]
print(llm(messages))
其他问题和用法
Ollama面临的安全风险
Ollama 作为一款开源工具,为用户提供了便捷的本地大模型部署和调用方式。通过 Docker 安装与部署,用户可以快速上手并灵活使用各类大型模型。
然而,由于 Ollama 缺乏内置鉴权机制,用户在生产环境中需采取适当的安全措施。未来若能完善鉴权机制,Ollama 将成为 AI 开发者的得力助手。
由于 Ollama 默认无鉴权机制,部署到服务器上存在安全隐患。以下是两种提高安全性的方法:
Linux 内置防火墙
将 Docker 部署 Ollama 的网络模式改为 host。
通过防火墙限制仅允许指定 IP 访问 11434 端口。
Nginx 反向代理
将 Ollama 的端口映射为 127.0.0.1:11434。
使用 Nginx 反向代理,并设置 IP 白名单和黑名单。
Docker Desktop 硬盘映像文件 (.vhdx) 从C盘迁移到D盘的方法
原数据目录:通常位于 C:\Users\你的用户名\AppData\Local\Docker\wsl\data\docker_data.vhdx
进入Docker Desktop设置页面,Setting -- Resources -- Disk image location, 在这里设置新的文件夹地址,比如: D:/Docker, 然后点右下角Apply & Restart
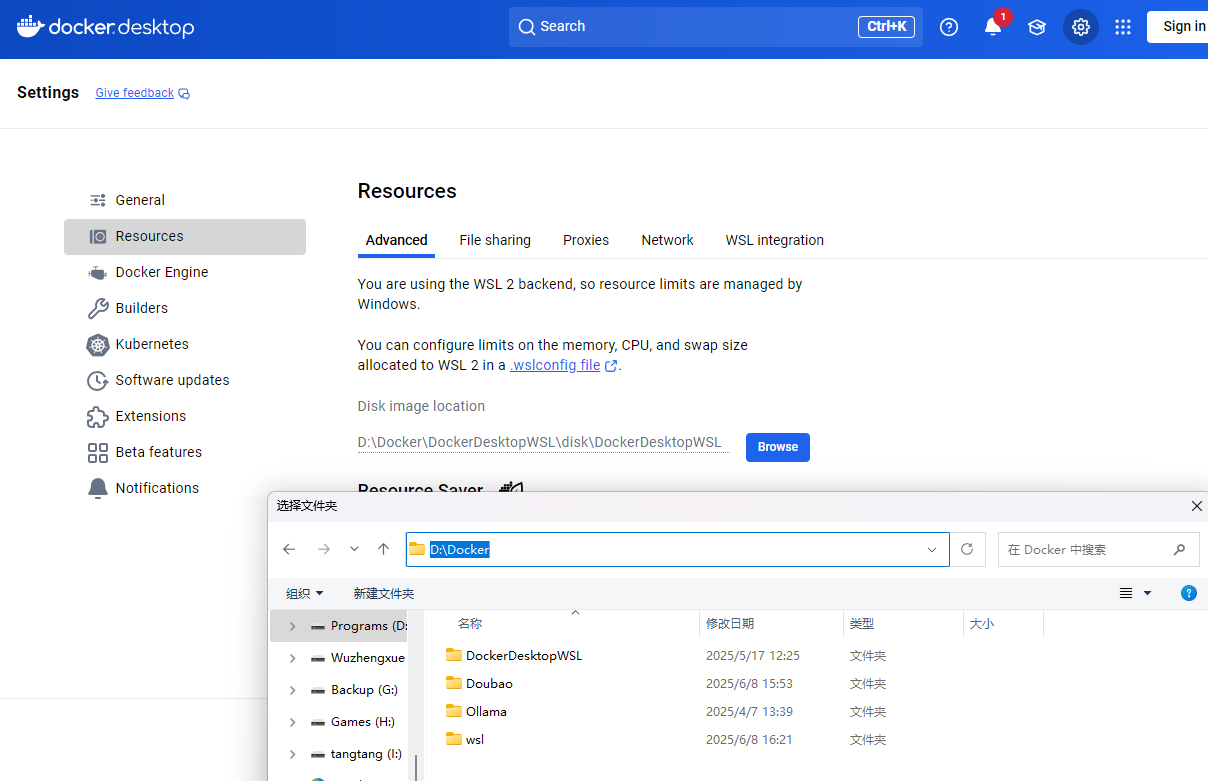
它会自动在D:/Docker下再依次建立:DockerDesktopWSL\disk目录,新的docker_data.vhdx就在这里放着,你看一下文件属性,发现这个文件只有2G左右。
此时,停止所有的Docker Desktop文件运行并退出,再更新,否则容易出错。
我原来那个docker_data.vhdx文件有30G左右,我直接把我的docker_data.vhdx文件复制到D:/Docker/DockerDesktopWSL/disk/docker_data.vhdx,覆盖它原来的文件。
覆盖完成后,再打开Docker Desktop,就会发现,之前安装的容器全在里面啦!哈哈哈
Ollama 使用常见的指令:
ollama serve #启动ollama
ollama create #从模型文件创建模型
ollama show #显示模型信息
ollama run #运行模型
ollama pull #从注册表中拉取模型
ollama push #将模型推送到注册表
ollama list #列出模型
ollama cp #复制模型
ollama rm #删除模型
ollama help #获取有关任何命令的帮助信息
问题修复
参考:https://www.cnblogs.com/treasury-manager/p/19074227
免费API申请
去AnyRouter申请免费API
参考:https://cloud.tencent.com/developer/article/2539872
Any Router是一个Claude Code免费共享平台,提供API中转服务。

国内用户可以通过 AnyRouter 提供的 API 中转服务,轻松绕过网络和注册限制,实现免费使用。以下是具体步骤:
去这里:https://anyrouter.top/
进入到Any Router首页,我使用LinuxDO登录,这是个很有意思的BBS:https://linux.do/
登录后,你会自动进入数据看板,并免费获得 100 美元的初始额度。
deepseek
https://platform.deepseek.com/sign_in
API:https://api.deepseek.com
腾讯云知识引擎原子能力界面
https://console.cloud.tencent.com/lkeap
API:https://api.lkeap.cloud.tencent.com/v1
硅基流动
https://cloud.siliconflow.cn/models
API:https://api.siliconflow.cn/v1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号