《深度剖析CPython解释器》7. 解密Python中字符串的底层实现,以及相关操作
楔子
这一次我们分析一下Python中的字符串,首先Python中的字符串是一个变长对象,因为不同长度的字符串所占的内存空间是不一样的;但同时字符串又是一个不可变对象,因为一旦创建就不可以再修改了。
而Python中的字符串是通过unicode来表示的,因此在底层对应的结构体是PyUnicodeObject。但是为什么需要unicode呢?
首先计算机存储的基本单位是字节,由8个比特位组成,由于英文字母算上大小写只有52个,再加上若干字符,数量不会超过256个,因此一个字节完全可以表示,这些字符称之为ASCII字符。但是随着非英文字符的出现,导致一个字节已经无法表示了,只能曲线救国,对于一个字节无法表示的字符,使用多个字节表示。
但是这样会出现两个问题:
不支持多国语言,例如中文的编码不可以包含日文;没有统一标准,例如中文有GB2312、GBK、GB18030等多个标准;所以由于编码不统一,开发人员经常在不同的编码间来回转换,会错误频出。为了彻底解决这个问题,unicode标准诞生了。unicode对世界上的文字系统进行了系统的整理、编码,让计算机可以用统一的方式处理文本,而且目前已经支持超过13万个字符,天然地支持多国语言。
但是问题来了,unicode能表示这么多的字符,那么占用的内存一定不低吧。是的,根据当时的编码,一个unicode字符最高会占用到4字节。但是对于西方人来说,明明一个字符就够用了,为啥需要那么多。于是又出现了utf-8,它是为unicode提供的新一个新的编码规则,具有可变长的功能。对于1个ASCII字符那么会使用一个字节存储,对于非ASCII字符会使用3个字节存储。
但Python3中表示unicode字符串时,使用的却不是utf-8,至于原因我们下面来分析一下。国外有一篇文章,题目翻译过来说的是"Python在存储字符串的时候如何节省内存",写的非常好,我们来看看。
Python在存储字符串的时候如何节省内存
从Python3开始,str类型使用的是Unicode。而根据编码的不同,Unicode的每个字符最大可以占到4字节,从内存的角度来说, 这种编码有时会比较昂贵。
为了减少内存消耗并且提高性能,python的内部使用了三种编码方式表示Unicode。
Latin-1 编码:每个字符一字节;UCS2 编码:每个字符两字节;UCS4 编码:每个字符四字节;
在Python编程中,所有字符串的行为都是一致的,而且大多数时间我们都没有注意到差异。然而在处理大文本的时候,这种差异就会变得异常显著、甚至有些让人出乎意料。
为了看到内部表示的差异,我们使用sys.getsizeof函数,返回一个对象所占的字节数。
import sys
print(sys.getsizeof("a")) # 50
print(sys.getsizeof("憨")) # 76
print(sys.getsizeof("💻")) # 80
我们看到都是一个字符,但是它们占用的内存却是不一样的。
正如你所见,Python面对不同的字符会采用不同的编码。需要注意的是,Python中的每一个字符串都需要额外占用49-80字节,因为要存储一些额外信息,比如:哈希、长度、字节长度、编码类型等等。
import sys
# 对于ASCII字符,显然一个占1字节,显然此时编码是Latin-1编码
print(sys.getsizeof("ab") - sys.getsizeof("a")) # 1
# 对于汉字,日文等等,一个占用2字节,此时是UCS2编码
print(sys.getsizeof("憨憨") - sys.getsizeof("憨")) # 2
print(sys.getsizeof("です") - sys.getsizeof("で")) # 2
# 像emoji,则是一个占4字节 ,此时是UCS4编码
print(sys.getsizeof("💻💻") - sys.getsizeof("💻")) # 4
而采用不同的编码,那么底层结构体实例额外的部分也会占用不同大小的内存。如果编码是Latin-1,那么这个结构体实例额外的部分会占49个字阶;编码是UCS2,占74个字节;编码是UCS4,占76个字节。然后字符串所占的字节数就等于:额外的部分 + 字符个数 * 单个字符所占的字节。
import sys
# 所以一个空字符串占用49个字节, 此时会采用占用内存最小的Latin-1编码
print(sys.getsizeof("")) # 49
# 此时使用UCS2
print(sys.getsizeof("憨") - 2) # 74
# UCS4
print(sys.getsizeof("👴") - 4) # 76
为什么python底层存储字符串不使用utf-8编码
我们先来抛出一个问题:首先我们知道Python支持通过索引查找一个字符串中指定位置的字符,而且Python中默认是以字符为单位的,不是字节(我们后面还会提),比如s[2]搜索的就是字符串s中的第3个字符。
s = "My姫様"
print(s[2]) # 姫
那么问题来了,我们知道Python中通过索引查找字符串的指定字符,时间复杂度为O(1),那么Python是怎么通过索引、比如这里的s[2],一下子就跳到第3个字符呢?显然是通过指针的偏移,用索引乘上每个字符占的字节数,得到偏移量,然后从头部向后偏移指定数量的字节即可,这样就能在定位到指定字符的同时保证时间复杂度为O(1),但是这就需要一个前提:字符串中每个字符所占的大小必须是相同的,如果字符占的大小不同(比如有的占用1字节、有的占用3字节),显然无法通过指针偏移的方式了,这个时候还想准确定位的话,只能按顺序对所有字符都逐个扫描,但这样的话时间复杂度肯定不是O(1),而是O(n)。
我们以golang为例,golang中的字符串默认就是使用的utf-8。
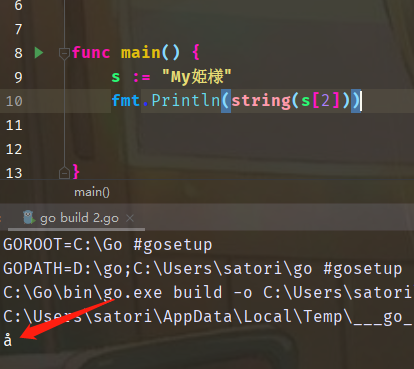
惊了,我们看到打印的并不是我们希望的结果。因为golang底层使用的是utf-8,不同的字符可能会占用不同的编码。但是golang中通过索引定位的时候,时间复杂度是O(1),所以golang它就无法定位到准确的字符。
golang的字符串在通过索引定位的时候,比如这里的s[2],会跳转两个字节,因为不同字符占的字节可能是不同的,因此在计算偏移量的时候只能以占用最小的、ASCII字符所占的字节为单位,即1个字节,所以计算的。只不过前面两个字符碰巧都是英文,每个占1字节,所以跳到了"姫"这个位置上。如果出现了非ASCII字符,那么是绝对跳不准的。而且在获取的时候,也只能获取1个字节。但是使用utf-8的话,非ASCII字符是占3个字节,显然一个字节是无法表示的。
所以Python会使用3个编码,对应编码的字符分别是1、2、4字节。因此Python在创建字符串的时候,会先扫描。或者尝试使用占字节数最少的Latin1编码存储,但是范围肯定有限。如果发现了存储不下的字符,只能改变编码,使用UCS2,继续扫描。但是又发现了新的字符,这个字符UCS2也无法存储,因为两个字节最多存储65535个不同的字符,所以会再次改变编码,使用ucs4存储。ucs4占四个字节,肯定能存下了。
一旦改变编码,字符串中的所有字符都会使用同样的编码,因为它们不具备可变长功能。比如这个字符串:"hello古明地觉",肯定都会使用UCS2,不存在说"hello"使用Latin1,"古明地觉"使用UCS2,因为一个字符串只能有一个编码。当通过索引获取的时候,会将索引乘上每个字符占的字节数,这样就能跳到准确位置上,因为字符串里面的所有字符占用的字节都是一样的,然后获取也会获取指定的字节数。比如:使用UCS2编码,那么定位到某个字符的时候,会取两个字节,这样才能表示一个完整的字符。
import sys
# 此时全部是ascii字符,那么Latin1编码可以存储
# 所以结构体实例额外的部分占49个字节
s1 = "hello"
# 有5个字符,一个字符一个字节,所以加一起是54个字节
print(sys.getsizeof(s1)) # 54
# 出现了汉字,那么Latin肯定存不下,于是使用UCS2
# 所以此时结构体实例额外的部分占74个字节
# 但是别忘了此时的英文字符也是ucs2,所以也是一个字符两字节
s2 = "hello憨"
# 6个字符,74 + 6 * 2 = 86
print(sys.getsizeof(s2)) # 86
# 这个牛逼了,ucs2也存不下,只能ucs4存储了
# 所以结构体实例额外的部分占76个字节
s3 = "hello憨💻"
# 此时所有字符一个占4字节,7个字符
# 76 + 7 * 4 = 104
print(sys.getsizeof(s3)) # 104
除此之外,我们再举一个例子更形象地证明这个现象。
import sys
s1 = "a" * 1000
s2 = "a" * 1000 + "💻"
# 我们看到s2只比s1多了一个字符
# 但是两者占的内存,s2却将近是s1的四倍。
print(sys.getsizeof(s1), sys.getsizeof(s2)) # 1049 4080
# 我们知道s2和s1的差别只是s2比s1多了一个字符,但就是这么一个字符导致s2比s1多占了3031个字节
# 显然这多出来的3031个字节不可能是多出来的字符所占的大小,什么字符一个会占到三千多个字节
# 尽管如此,但它也是罪魁祸首,不过前面的1000个字符也是共犯
# 我们说Python会根据字符串选择不同的编码,s1全部是ascii字符,所以Latin1能存下,因此一个字符只占一个字节
# 所以大小就是49 + 1000 = 1049
# 但是对于s2,python发现前1000个字符Latin1能存下,但是不幸的是,最后一个字符发现存不下了,只能使用UCS4
# 而字符串的所有字符只能有一个编码,为了保证索引查找的时候,时间复杂度为O(1),这是Python的设计策略
# 因此导致前面一个字节就能存下的字符,每一个也变成了4个字节。
# 而我们说使用UCS4,结构体额外的内存会占76个字节
# 因此s2的大小就是:76 + 1001 * 4 = 76 + 4004 = 4080
# 相信下面你肯定能分析出来
print(sys.getsizeof("爷的青春回来了")) # 88
print(sys.getsizeof("👴的青春回来了")) # 104
所以如果字符串中的所有字符对应的ASCII码都在0~255范围内,则使用1字节Latin1对其进行编码。基本上,Latin1能表示前256个Unicode字符。它支持多种拉丁语,如英语、瑞典语、意大利语、挪威语。但是它们不能存储非拉丁语言,比如汉语、日语、希伯来语、西里尔语。这是因为它们的代码点(数字索引)定义在1字节(0-255)范围之外。
大多数流行的自然语言都可以采用2字节(UCS2)编码。当字符串包含特殊符号、emoji或稀有语言时,使用4字节(UCS4)编码。Unicode标准有将近300个块(范围)。你可以在0XFFFF块之后找到4字节块。假设我们有一个10G的ASCII文本,我们想把它加载到内存中,但如果我们在文本中插入一个表情符号,那么字符串的大小将增加4倍。这是一个巨大的差异,你可能会在实践当中遇到,比如处理NLP问题。
print(ord("a")) # 97
print(ord("憨")) # 25000
print(ord("💻")) # 128187
所以最著名和最流行的Unicode编码都是utf-8,但是python不在内部使用它,而是使用Latin1、UCS2、UCS4。至于原因我们上面已经解释的很清楚了,主要是Python的索引是基于字符:
当一个字符串使用utf-8编码存储时,根据它所表示的字符,每个字符会根据自身选择一个合适的编码。这是一种存储效率很高的编码,但是它有一个明显的缺点。由于每个字符的字节长度可能不同,因此就导致无法按照索引瞬间定位到单个字符,即便能定位,也无法定位准确。如果想准,那么只能逐个扫描所有字符。
因此要对使用utf-8编码的字符串执行一个简单的操作,比如s[5],就意味着Python需要扫描每一个字符,直到找到需要的字符,这样效率是很低的。但如果是固定长度的编码就没有这样的问题,所以当Latin 1存储的"hello",在和"憨色儿"组合之后,整体每一个字符都会向大的方向扩展、变成了2字节。这样定位字符的时候,只需要将"索引 * 2"计算出偏移的字节数、然后跳转该字节数即可。但如果原来的"hello"还是一个字节、而汉字是2字节,那么只通过索引是不可能定位到准确字符的,因为不同类型字符的编码不同,必须要扫描整个字符串才可以。但是扫描字符串,效率又比较低。所以python内部才会使用这个方法,而不是使用utf-8。
所以对于golang来讲,如果想像Python一样,那么需要这么做:
package main
import (
"fmt"
)
func main() {
s := "My姫様"
//我们看到长度为8, 因为它使用utf-8编码
//底层一个非ascii字符占3字节, 所以总共8字节
fmt.Println(s, len(s)) // My姫様 8
//如果想像Python一样,那么golang中提供了一个rune, 相当于int32, 此时直接使用4个字节
r := []rune(s)
fmt.Println(string(r), len(r)) // My姫様 4
//虽然打印的内容是一样的,但是此时每个字符都使用4字节存储
//此时跳转会和Python一样偏移 2 * 4 个字节, 然后获取也会获取4个字节, 因为一个字符占4个字节
//所以不光索引跳转会将索引乘上4, 在获取的时候也会一次获取4个字节
//因为都知道一个字符占4字节了,所以肯定获取指定数量的字节,这样才能表示完整字符
fmt.Println(string(r[2])) //姫
}
其实可以想一下C中的数组,比如int类型的数组,那么数组指针在往后偏移一个单位的时候,偏移的也是1个int(4字节),而不是1个字节,这是显然的;然后获取的时候也会一次获取4个字节,因为这样才能表示一个int。但是utf-8表示的unicode字符串里面的字符可能占用不同的字节,那么显然没办法实现Python中字符串的索引查找效果,所以Python内部的字符串没有使用utf-8。
因此Python才会提供了三种编码,先使用占用最小的Latin1,不行的话再使用UCS2、UCS4,总之会确保每个字符占用的字节是一样的,原因的话我们上面分析的很透彻了。并且无论是索引还是切片、还是计算长度等等,都是基于字符的,显然这也符合人类的思维习惯。
然后字符串还有intern机制,原文中也提到了,但是我们会在本文的后面介绍。下面先看字符串底层的结构,以及支持的相关操作是如何实现的。
字符串的底层实现
我们之前提到了,字符串采用不同的编码,底层的结构体实例所占用的额外内存是不一样的。其实本质上是,字符串会根据内容的不同,而选择不同的存储单元。
至于到底是怎么做到的,我们只能去源码中寻找答案了,与str相关的源码:Include/unicodeobject.h和Objects/unicodeobject.c
enum PyUnicode_Kind {
/* String contains only wstr byte characters. This is only possible
when the string was created with a legacy API and _PyUnicode_Ready()
has not been called yet. */
PyUnicode_WCHAR_KIND = 0,
/* Return values of the PyUnicode_KIND() macro: */
PyUnicode_1BYTE_KIND = 1,
PyUnicode_2BYTE_KIND = 2,
PyUnicode_4BYTE_KIND = 4
};
我们在unicodeobject.h中看到,str对象根据底层存储会根据unicode的不同而分为以下几类:
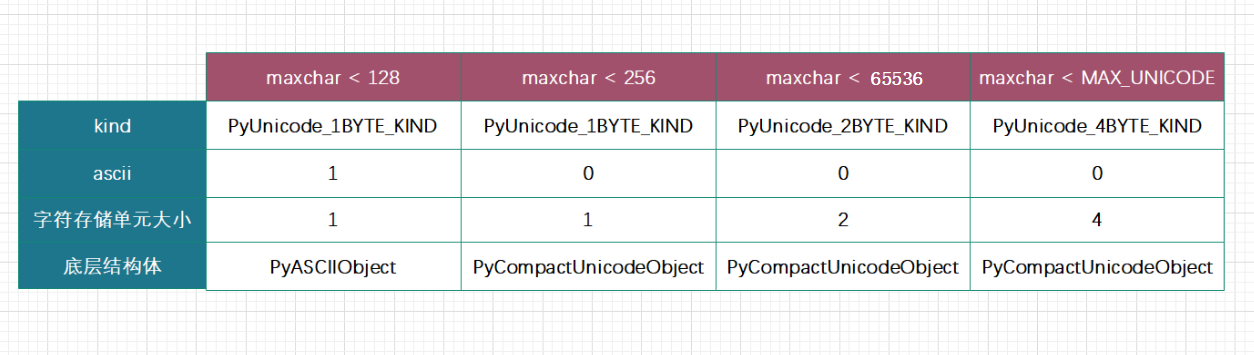
PyUnicode_1BYTE_KIND:所有字符码位均在 U+0000 到 U+00FF 之间PyUnicode_2BYTE_KIND:所有字符码位均在 U+0000 到 U+FFFF 之间,且至少一个大于 U+00FF(否则每个字符就用1字节了)PyUnicode_4BYTE_KIND:所有字符码位均在 U+0000 到 U+10FFFF 之间,且至少一个大于 U+FFFF
如果文本字符码位均在 U+0000 到 U+00FF 之间,单个字符只需 1 字节来表示;而码位在 U+0000 到 U+FFFF 之间的文本,单个字符则需要 2 字节才能表示;以此类推。这样一来,根据文本码位范围,便可为字符选用尽量小的存储单元,以最大限度节约内存。
typedef uint32_t Py_UCS4; //我们看到4字节使用的是无符号32位整型
typedef uint16_t Py_UCS2;
typedef uint8_t Py_UCS1; //Latin-1
既然unicode内部的存储结构会因字符而异,那么unicode底层就必须有成员来维护相应的信息,所以Python内部定义了若干标志位:
interned:是否被intern机制维护,这个机制我们会在本文后面介绍kind:类型,用于区分字符底层存储单元的大小。如果是Latin1编码,那么就是1;UCS2编码则是2;UCS4编码则是4compact:内存分配方式,对象与文本缓冲区是否分离ascii:字符串是否是纯ASCII字符串, 如果是1就是1, 否则就是0。注意: 虽然每个字符都会对应ASCII码,但是只有对应的ASCII码为0~127之间的才是ASCII字符。所以虽然一个字节可表示的范围是0~255,但是128~255之间的并不是ASCII字符。
而为unicode字符串申请空间,底层可以调用一个叫PyUnicode_New的函数,这也是一个特型API。比如:元组申请空间可以使用PyTuple_New,列表申请空间可以使用PyList_New等等,会传入一个整型,创建一个能够容纳指定数量元素的结构体实例。而PyUnicode_New则接受一个字符个数以及最大字符maxchar初始化unicode字符串对象,之所以会多出一个maxchar,是因为要根据它来为unicode字符串对象选择最紧凑的字符存储单元,以及结构体。
下面我们就来分析字符串底层对应的结构体。
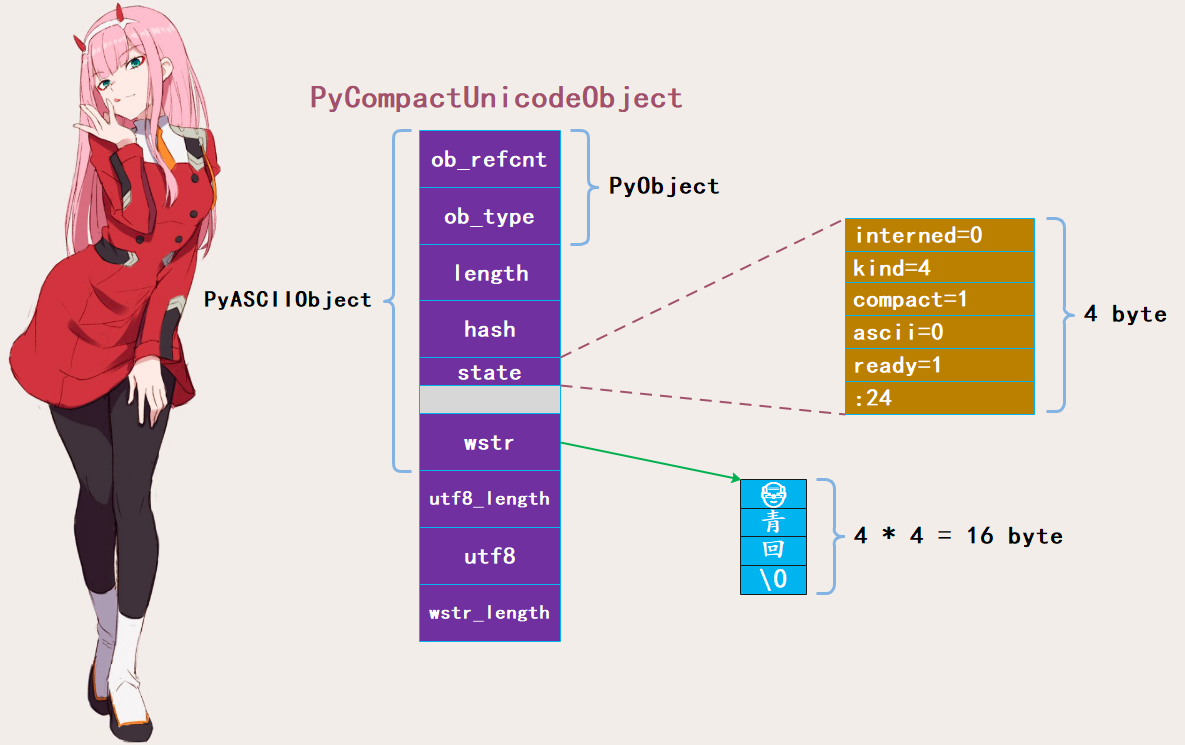
PyASCIIObject
如果 str 对象保存的文本均为 ASCII ,即 maxchar<128,则底层由 PyASCIIObject 结构进行存储:
/* ASCII-only strings created through PyUnicode_New use the PyASCIIObject
structure. state.ascii and state.compact are set, and the data
immediately follow the structure. utf8_length and wstr_length can be found
in the length field; the utf8 pointer is equal to the data pointer. */
typedef struct {
PyObject_HEAD
Py_ssize_t length; /* Number of code points in the string */
Py_hash_t hash; /* Hash value; -1 if not set */
struct {
unsigned int interned:2;
unsigned int kind:3;
unsigned int compact:1;
unsigned int ascii:1;
unsigned int ready:1;
unsigned int :24;
} state;
wchar_t *wstr; /* wchar_t representation (null-terminated) */
} PyASCIIObject;
PyASCIIObject结构体也是其他 Unicode 底层结构体的基础,所有字段均为 Unicode 公共字段:
ob_refcnt:引用计数ob_type:类型指针length:字符串长度hash:字符串的哈希值state:unicode对象标志位,包括intern、kind、ascii、compact等wstr:一个指针,指向由宽字符组成的字符数组。字符串和字节序列一样,底层都是通过字符数组来维护具体的值。
以字符串"abc"为例,看看它在底层的存储结构:
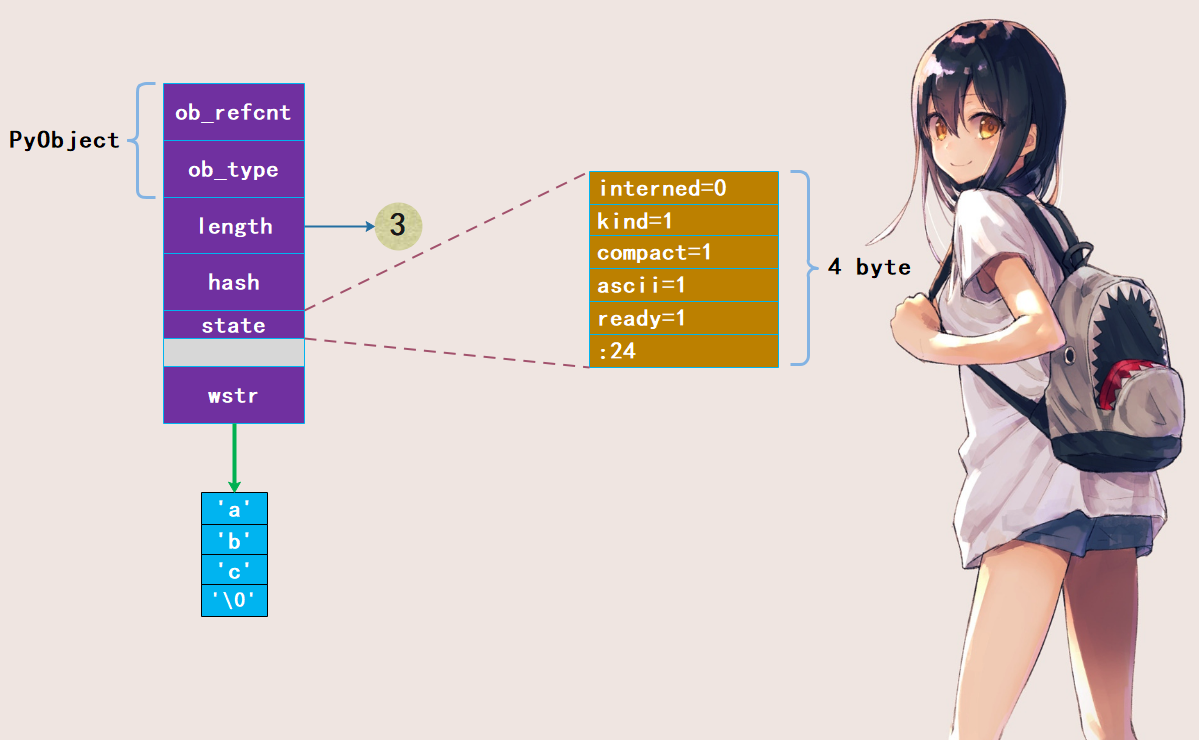
注意:state 成员后面有一个 4 字节的空洞,这是结构体字段内存对齐造成的现象。在 64 位机器上,指针大小为 8 字节,为优化内存访问效率,必须以 8 字节对齐。现在我们知道一个空字符串为什么占据49个字节了,因为ob_refcnt、ob_type、length、hash、wstr 都是 8 字节,所以总共 40 字节;而 state 是 4 字节,但是留下了 4 字节的空洞,加起来也是 8 字节,所以总共占 40 + 8 = 48 个字节,但是 Python 的 unicode 字符串在 C 中也是使用字符数组来存储的,只不过此时的字符不再是 char 类型,而是 wchar_t。但是它的内部依旧有一个 '\0',所以还要加上一个 1,总共 49 字节。
对于 "abc" 这个 unicode 字符串来说,占的总字节数就是 49 + 3 = 52。
import sys
print(sys.getsizeof("abc")) # 52
# 长度为n的ASCII字符串, 大小就是49 + n
print(sys.getsizeof("a" * 1000)) # 1049
PyCompactUnicodeObject
如果文本不全是 ASCII ,Unicode 对象底层便由 PyCompactUnicodeObject 结构体保存:
/* Non-ASCII strings allocated through PyUnicode_New use the
PyCompactUnicodeObject structure. state.compact is set, and the data
immediately follow the structure. */
typedef struct {
PyASCIIObject _base;
Py_ssize_t utf8_length; /* Number of bytes in utf8, excluding the
* terminating \0. */
char *utf8; /* UTF-8 representation (null-terminated) */
Py_ssize_t wstr_length; /* Number of code points in wstr, possible
* surrogates count as two code points. */
} PyCompactUnicodeObject;
我们看到PyCompactUnicodeObject是在PyASCIIObject的基础上增加了3个字段。
utf8_length:字符串的utf-8编码长度utf8:字符串使用utf-8编码的结果,这里是缓存起来从而避免重复的编码运算wstr_length:宽字符的数量

我们说 PyCompactUnicodeObject 只是多了3个字段,显然多出了 24 字节。那么之前的 49+24 等于 73,咦不对啊,我们不是说一个是 74 一个 76 吗?你忘记了 '\0',如果使用 UCS2,那么 '\0' 也占两个字节,所以应该是 73 -1 + 2 = 74;同理 UCS4 是 73 - 1 + 4 = 76,所以此时 unicode 字符串所占内存我们算是分析完了。然后我们再来看看这几种不同编码下对应的字符串结构吧。
PyUnicode_1BYTE_KIND
如果 128 <= maxchar < 256,虽然一个字节可以存储的下,但Unicode 对象底层也会由 PyCompactUnicodeObject 结构体保存,字符存储单元为 Py_UCS1(Latin-1) ,大小为 1 字节。以字符串 "sator¡" 为例:

import sys
# 虽然此时所有的字符都占一个 1 字节,但是只有当 maxchar < 128 的时候,才会使用 PyASCIIObject
# 如果大于等于 128, 那么会使用 PyCompactUnicodeObject 存储, 只不过内部字符依旧每个占一字节
print(sys.getsizeof("sator¡")) # 79
# 我们知道对于使用 UCS2 的 PyCompactUnicodeObject 来说, 空字符串会占 74 字节
# 而 \0 占了两个字节,所以除去 \0,额外部分是 72 字节
# 而这里是 Latin-1,\0 是一个字节,所以一个空字符串应该占 73 字节,加上这里的 6 个字符,总共是 79 字节。
# 因此当使用 Latin1 编码的时候,不一定就是 PyASCIIObject, 只有当 0 < maxchar < 128 的时候才会使用 PyASCIIObject
# 所以如果将上面的 "sator¡" 改成 "satori",那么就会使用 PyASCIIObject 存储了。
# 此外还要注意所占的内存, 因为 Latin1 和 UCS2、UCS4 三个编码都可以对应 PyCompactUnicodeObject
# 而不包括 \0 的话,那么一个 PyCompactUnicodeObject 是占据72字节的,如果算上 \0
# 那么使用 Latin1 编码的空字符串就是 73 字节,使用 UCS2 编码的空字符串就是 74 字节,使用 UCS4 编码的空字符串就是 76 字节,因为 \0 分别占 1、2、4 字节
PyUnicode_2BYTE_KIND
如果 256 <= maxchar < 65536,Unicode 对象底层同样由 PyCompactUnicodeObject 结构体保存,但字符存储单元为 UCS2 ,大小为 2 字节。以字符串 "My姫様" 为例:
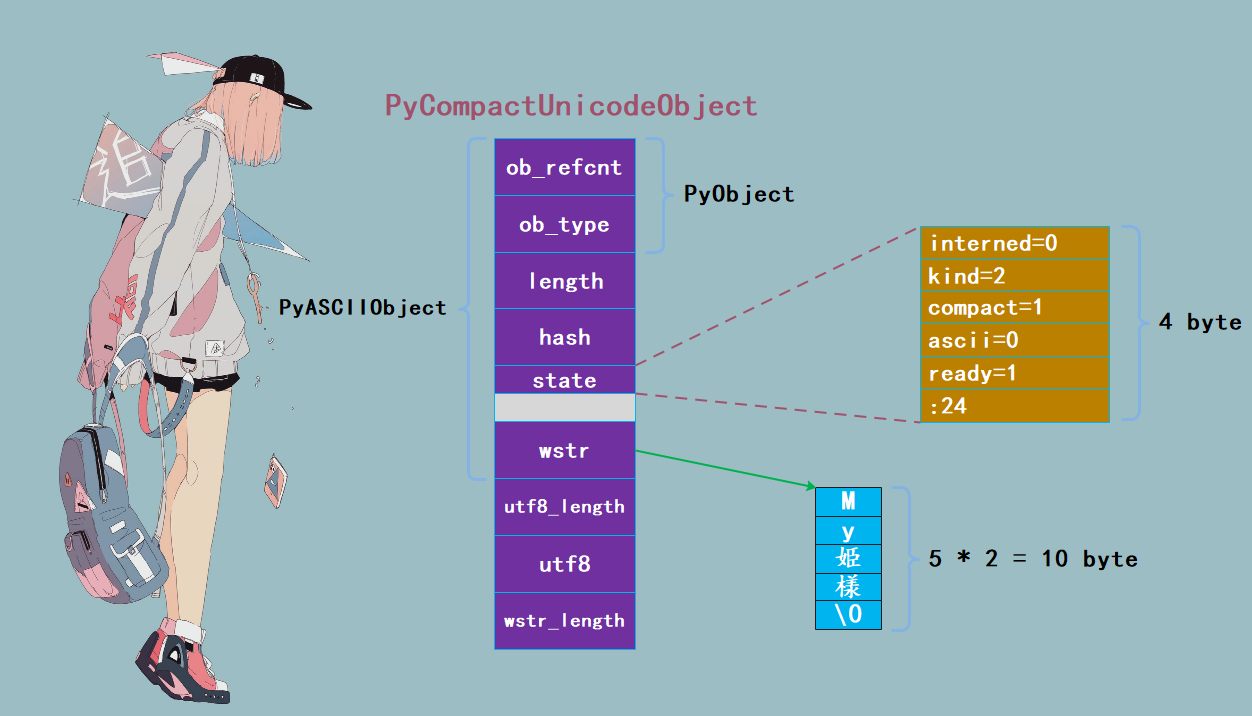
import sys
# 74 + 4 * 2, 或者72 + 5 * 2
print(sys.getsizeof("My姫様")) # 82
当文本中包含了 Latin1 无法存储的字符时,会使用两字节的 UCS 保存,但是连前面的英文字符也变成两字节了。至于原因我们上面已经分析的很透彻了,因为定位的时候是获取的字符,但如果采用变长的 utf-8 方式存储导致不同字符占的内存大小不一,那么就无法在 O(1) 的时间内取出准确的字符了,只能从头到尾依次遍历。而 Go 基于 utf-8,因此它无法获取准确的字符,只能转成 rune,此时内部一个字符直接占4字节。
PyUnicode_4BYTE_KIND
如果 65536 <= maxchar < 429496296,便只能使用4字节存储单元的UCS4了,以字符串"👴青回"为例:
import sys
# 76 + 3 * 4, 或者72 + 4 * 4
print(sys.getsizeof("👴青回")) # 88
因此此时每个字符都采用UCS4编码,因此每个字符占四个字节,这是Python内部采取的策略。
我们后面通过分析字符串的一些操作的时候,会更加深刻的体会到。
PyUnicodeObject
不是说Python中字符串底层对应PyUnicodeObject吗?目前出现了PyASCIIObject和PyCompactUnicodeObject,那么PyUnicodeObject呢?
typedef struct {
PyCompactUnicodeObject _base;
union {
void *any;
Py_UCS1 *latin1;
Py_UCS2 *ucs2;
Py_UCS4 *ucs4;
} data; /* Canonical, smallest-form Unicode buffer */
} PyUnicodeObject;
这便是 PyUnicodeObject 的定义了,里面 data 是一个共同体,这里我们没有必要关注,我们直接把它当成 PyCompactUnicodeObject 来用即可。
字符串的操作
先来看看str类型对象在底层的定义吧。
PyTypeObject PyUnicode_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"str", /* tp_name */
sizeof(PyUnicodeObject), /* tp_size */
//...
unicode_repr, /* tp_repr */
&unicode_as_number, /* tp_as_number */
&unicode_as_sequence, /* tp_as_sequence */
&unicode_as_mapping, /* tp_as_mapping */
//...
};
首先哈希操作(unicode_hash)之类的肯定是支持的,然后我们关注一下tp_as_number、tp_as_sequence、tp_as_mapping,我们看到三个操作簇居然都满足。不过有了bytes的经验,我们知道tp_as_number里面的实际上只有取模,也就是格式化(bytes和str在很多行为上都是相似的,但是这两者的区别我们后面会说,目前认为str对象可以编码成bytes对象,bytes对象可以解码成str对象即可)。
我们来看一下这几个操作簇吧。
//不出我们所料, 只有一个取模
static PyNumberMethods unicode_as_number = {
0, /*nb_add*/
0, /*nb_subtract*/
0, /*nb_multiply*/
unicode_mod, /*nb_remainder*/
};
//所以我们看到这个和bytes对象是几乎一样的,因为我们说了str对象和bytes都是不可变的变长对象,并且可以相互转化
//它们的行为时高度相似的
static PySequenceMethods unicode_as_sequence = {
(lenfunc) unicode_length, /* sq_length */
PyUnicode_Concat, /* sq_concat */
(ssizeargfunc) unicode_repeat, /* sq_repeat */
(ssizeargfunc) unicode_getitem, /* sq_item */
0, /* sq_slice */
0, /* sq_ass_item */
0, /* sq_ass_slice */
PyUnicode_Contains, /* sq_contains */
};
//也和bytes对象一样
static PyMappingMethods unicode_as_mapping = {
(lenfunc)unicode_length, /* mp_length */
(binaryfunc)unicode_subscript, /* mp_subscript */
(objobjargproc)0, /* mp_ass_subscript */
};
下面我们先来重点看一下PyUnicode_Concat这个操作,它是用来将两个字符串相加、组合成一个新的字符串。
PyObject *
PyUnicode_Concat(PyObject *left, PyObject *right)
{
//参数left和right显然指向两个unicode字符串
//result则是指向相加之后的字符串
PyObject *result;
//还记得这个Py_UCS4吗, 它是相当于一个无符号32位整型
Py_UCS4 maxchar, maxchar2;
//显然是left的长度、right的长度、相加之后的长度
Py_ssize_t left_len, right_len, new_len;
//检测是否是PyUnicodeObject
if (ensure_unicode(left) < 0)
return NULL;
if (!PyUnicode_Check(right)) {
//如果右边不是str对象的话,报错
PyErr_Format(PyExc_TypeError,
"can only concatenate str (not \"%.200s\") to str",
right->ob_type->tp_name);
return NULL;
}
//属性的初始化, ensure_unicode实际上是调用了PyUnicode_Check和PyUnicode_READY这两部
//当然这些都是Python内部做的检测,我们不用太关心
if (PyUnicode_READY(right) < 0)
return NULL;
//这里快分支
//如果其中一方为空的话,那么直接返回另一方即可,显然这里的快分支命中率就没那么高了,但还是容易命中的
if (left == unicode_empty)
return PyUnicode_FromObject(right);
if (right == unicode_empty)
return PyUnicode_FromObject(left);
//计算left的长度和right的长度
left_len = PyUnicode_GET_LENGTH(left);
right_len = PyUnicode_GET_LENGTH(right);
//如果相加超过PY_SSIZE_T_MAX,那么会报错, 因为要维护字符串的长度,显然长度是有范围的
//但是几乎不存在字符串的长度会超过PY_SSIZE_T_MAX的
if (left_len > PY_SSIZE_T_MAX - right_len) {
PyErr_SetString(PyExc_OverflowError,
"strings are too large to concat");
return NULL;
}
//计算新的长度
new_len = left_len + right_len;
//计算存储单元占用的字节数
maxchar = PyUnicode_MAX_CHAR_VALUE(left);
maxchar2 = PyUnicode_MAX_CHAR_VALUE(right);
//取大的那一方,因为一个是UCS2一个是UCS4,那么相加之后肯定会选择UCS4
maxchar = Py_MAX(maxchar, maxchar2);
//通过PyUnicode_New申请能够容纳new_len宽字符的PyUnicodeObject, 并且字符的存储单元是大的那一方
result = PyUnicode_New(new_len, maxchar);
if (result == NULL)
return NULL;
//将left拷进去
_PyUnicode_FastCopyCharacters(result, 0, left, 0, left_len);
//将right拷进去
_PyUnicode_FastCopyCharacters(result, left_len, right, 0, right_len);
assert(_PyUnicode_CheckConsistency(result, 1));
return result;
}
和bytes对象一样,+的效率非常低下,所以官方建议通过join的方式。
PyObject *
PyUnicode_Join(PyObject *separator, PyObject *seq)
{
PyObject *res;
PyObject *fseq;
Py_ssize_t seqlen;
PyObject **items;
fseq = PySequence_Fast(seq, "can only join an iterable");
if (fseq == NULL) {
return NULL;
}
items = PySequence_Fast_ITEMS(fseq);
seqlen = PySequence_Fast_GET_SIZE(fseq);
res = _PyUnicode_JoinArray(separator, items, seqlen);
Py_DECREF(fseq);
return res;
}
PyObject *
_PyUnicode_JoinArray(PyObject *separator, PyObject *const *items, Py_ssize_t seqlen)
{
//...
}
代码比较长,但是逻辑不难理解,这里就不贴了。就是获取列表或者元组里面的每一个unicode字符串对象的长度,然后加在一起,并取最大的存储单元,然后一次性申请对应的空间,再逐一进行拷贝。所以拷贝是避免不了的,+这种方式导致低效率的主要原因就在于大量PyUnicodeObject的创建和销毁。
因此如果我们要拼接大量的PyUnicodeObject,那么使用join列表或者元组的方式;如果数量不多,还是可以使用+的,毕竟维护一个列表也是需要资源的。使用join的方式,只有在PyUnicodeObject的数量非常多的时候,优势才会凸显出来。
初始化
然后我们在看看PyUnicodeObject的初始化,Python很多方式,从C中原生的字符串创建PyUnicodeObject对象。比如:PyUnicode_FromString、PyUnicode_FromStringAndSize、PyUnicode_FromUnicodeAndSize、PyUnicode_FromUnicode、PyUnicode_FromWideChar等等
PyUnicode_FromString(const char *u)
{
size_t size = strlen(u);
// PY_SSIZE_T_MAX是一个与平台相关的数值,在64位系统下是4GB
//如果创建的字符串的长度超过了这个值,那么会报错
//个人觉得这种情况应该不会发生,就跟变量的引用计数一样
//只要不是吃饱了撑的,写恶意代码,基本不会超过这个阈值
if (size > PY_SSIZE_T_MAX) {
PyErr_SetString(PyExc_OverflowError, "input too long");
return NULL;
}
//会进行检测字符串是哪种编码格式,从而决定分配几个字节
return PyUnicode_DecodeUTF8Stateful(u, (Py_ssize_t)size, NULL, NULL);
}
字符串对象的intern机制
如果字符串的interned标识位为1,那么Python虚拟机将为其开启interned机制。那么,什么是interned机制呢?
在Python中,某些字符串也可以像小整数对象池中的整数一样,共享给所有变量使用,从而通过避免重复创建来降低内存使用、减少性能开销,这便是intern机制。
Python的做法是在内部维护一个全局字典,所有开启intern机制的字符串均会保存在这里,后续如果需要使用的话,会先尝试在全局字典中获取,从而实现避免重复创建的功能。
void
PyUnicode_InternInPlace(PyObject **p)
{
PyObject *s = *p;
PyObject *t;
//对PyUnicodeObjec进行类型和状态检查
if (!PyUnicode_CheckExact(s))
return;
//检测interned标识位, 判断是否开启intern机制
if (PyUnicode_CHECK_INTERNED(s))
return;
//创建intern机制的dict
if (interned == NULL) {
interned = PyDict_New();
if (interned == NULL) {
PyErr_Clear(); /* Don't leave an exception */
return;
}
}
Py_ALLOW_RECURSION
//下面的内容单独分析
t = PyDict_SetDefault(interned, s, s);
Py_END_ALLOW_RECURSION
if (t == NULL) {
PyErr_Clear();
return;
}
if (t != s) {
Py_INCREF(t);
Py_SETREF(*p, t);
return;
}
Py_REFCNT(s) -= 2;
_PyUnicode_STATE(s).interned = SSTATE_INTERNED_MORTAL;
}
在PyDict_SetDefault函数中首先会进行一系列的检查,包括类型检查、因为intern共享机制只能用在字符串对象上,所以检查传入的对象是否已经被intern机制处理过了。
我们在代码中看到了interned = PyDict_New(),这个PyDict_New()是python中的dict对象,因此可以发现在程序中有一个key、value映射关系的集合。
intern机制中的PyUnicodObject采用了特殊的引用计数机制,将一个PyUnicodeObject对象a的PyObject指针作为key和valu添加到intered中时,PyDictObjec对象会通过这两个指针对a的引用计数进行两次+1操作。这会造成a的引用计数在python程序结束前永远不会为0,这也是最后面Py_REFCNT(s) -= 2; 要将计数减2的原因。
Python在创建一个字符串时,会首先检测是否已经有该字符串对应的PyUnicodeObject对象了,如果有,就不用创建新的,这样可以节省空间。但其实不是这样的,事实上,节省内存空间是没错的,可Python并不是在创建PyUnicodeObject的时候就通过intern机制实现了节省空间的目的。从PyUnicode_FromString中我们可以看到,无论如何一个合法的PyUnicodeObject总是会被创建的,而intern机制也只对PyUnicodeObject起作用。
对于任何一个字符串,Python总是会为它创建对应的PyUnicodeObject,尽管创建出来的对象所维护的字符数组,在intern机制中已经存在了(有另外的PyUnicodeObject也维护了相同的字符数组)。而这正是关键所在,通常Python在运行时创建了一个PyUnicodeObject对象temp之后,基本上都会调用PyUnicode_InternInPlace对temp进行处理,如果维护的字符数组有其他的PyUnicodeObject维护了,或者说其他的PyUnicodeObject对象维护了一个与之一模一样的字符数组,那么temp的引用计数就会减去1。temp由于引用计数为0而被销毁,只是昙花一现,然后归于湮灭。
所以现在我们就明白了intern机制,并不是说先判断是否存在,如果存在,就不创建。而是先创建,然后发现已经有其他的PyUnicodeObject维护了一个与之相同的字符数组,于是intern机制将引用计数减一,导致引用计数为0,最终被回收。
但是这么做的原因是什么呢?为什么非要创建一个PyUnicodeObject来完成intern操作呢?这是因为PyDictObject必须要求必须以PyObject *作为key。
关于PyUnicodeObject对象的intern机制,还有一点需要注意。实际上,被intern机制处理过后的字符串分为两类,一类处于SSTATE_INTERNED_IMMORTAL,另一类处于SSTATE_INTERNED_MORTAL状态,这两种状态的区别在unicode_dealloc中可以清晰的看到,SSTATE_INTERNED_IMMORTAL状态的PyUnicodeObject是永远不会被销毁的,它与python解释器共存亡。
PyUnicode_InternInPlace只能创建SSTATE_INTERNED_MORTAL的PyUnicodeObject对象,如果想创建SSTATE_INTERNED_IMMORTAL对象,必须通过另外的接口来强制改变PyUnicodeObject的intern状态。
void
PyUnicode_InternImmortal(PyObject **p)
{
PyUnicode_InternInPlace(p);
if (PyUnicode_CHECK_INTERNED(*p) != SSTATE_INTERNED_IMMORTAL) {
_PyUnicode_STATE(*p).interned = SSTATE_INTERNED_IMMORTAL;
Py_INCREF(*p);
}
}
但是问题来了,什么样的字符才会开启intern机制呢?
在Python3.8中,如果一个字符串的所有字符都位于0 ~ 127之间,那么会开启intern机制。
>>> a = "abc" * 1000
>>> b = "abc" * 1000
>>> a is b # 之前的话是不超过20个字符,但是在Python3.8中这个限制被扩大了很多
True
>>>
>>> a = "abc" * 2000
>>> b = "abc" * 2000
>>> a is b
False # 显然3 * 2000,6000个字符是不会开启intern机制的,所以长度限制是多少,有兴趣可以自己试一下
>>>
在Python3.8中,如果一个字符串只有一个字符,并且位于0~255之间,那么会开启intern机制。
>>> a = chr(255) * 2
>>> b = chr(255) * 2
>>> a is b # 不位于0~127之间,所以不是ASCII字符,因此没有开启intern机制
False
>>>
>>> a = chr(255)
>>> b = chr(255)
>>> a is b
True # 但如果只有一个字符的话,则会开启
>>> # 另外,空字符串也会开启
>>> a = ""
>>> b = ""
>>> a is b
True
实际上,存储单个字符这种方式有点类似于bytes对象中的缓存池。是的,正如整数有小整数对象池、bytes对象有字符缓存池一样,字符串也有其对应的PyUnicodeObject缓存池。
在Python中的整数对象中,小整数的对象池是在Python初始化的时候被创建的,而字符串对象体系中的缓存池则是以静态变量的形式存在的。在Python初始化完成之后,缓冲池的所有PyUnicodeObject指针都为空。
当创建一个PyUnicodeObject对象时,如果字符串只有一个字符,且位于0~255。那么会先对该字符串进行intern操作,再将intern的结果缓存到池子当中。同样当再次创建PyUnicodeObject对象时,检测维护的是不是只有一个字符,然后检查字符是不是存在于缓存池中,如果存在,直接返回。
str对象和bytes对象之间的关系
首先str对象我们称之为字符串,bytes对象我们称之为字节序列,把字符串中的每一个字符都转成对应的编码,那么得到就是字节序列了。因为计算机存储和网络通讯的基本单位都是字节,所以字符串必须以字节序列的形式进行存储或传输。
那么如何转化呢?首先我们需要清楚两个概念:字符集和编码。
字符集顾名思义就是由字符组成的集合,每个字符在集合中都有唯一编号,像ASCII、unicode都是字符集。只不过 ASCII 能够容纳的字符是有限的,而 unicode 可以容纳世界上所有的字符。
而编码则负责告诉你字符在字符集中对应的编号,编码有:gbk、utf-8等等
s = "姫様"
# 采用utf-8编码, encode成bytes对象
print(s.encode("utf-8")) # b'\xe5\xa7\xab\xe6\xa7\x98'
for _ in s.encode("utf-8"):
print(_)
"""
229
167
171
230
167
152
"""
# 说明"姫"对应的ASCII码是: 229 167 171, 因为utf-8编码的话, 一个汉字占3个字节
# 我们使用utf-8解码, 也能得到对应的字符串
print(s.encode("utf-8").decode("utf-8")) # 姫様
print(bytearray([229, 167, 171, 230, 167, 152]).decode("utf-8")) # 姫様
因此字符串和字节序列在某种程度上是很相似的,字符串按照指定的编码进行encode即可得到字节序列(将字符转成ASCII码),字节序列按照相同的编码decode即可得到字符串(将ASCII码转成字符)。
# 比如我有一个gbk编码的字节序列,但是在传输的时候需要utf-8编码的字节序列
b = b'\xc4\xe3\xba\xc3'
# 所以我们就按照gbk解码成字符串,因为不同的编码会得到不同的ASCII码
# 因此encode和decode都要使用同一种编码, 如果前后使用了不同的编码,那么在decode的时候会因为无法正确解析而报错
s = b.decode("gbk")
print(s) # 你好
# 然后我们使用utf-8进行encode
b = s.encode("utf-8") + "我很可爱".encode("utf-8")
# 再使用utf-8进行decode
print(b.decode("utf-8")) # 你好我很可爱
但是对于ASCII字符来说,由于不管采用哪一种编码,它们得到的ASCII码都是固定的,所以在显示的时候直接以字符本身显示了。
s = "abc"
# a对应的ASCII码是97, 所以你在C中写char c = 'a'和char c = 97是完全等价的
print(s.encode("utf-8")) # b'abc'
print(bytearray([97, 98, 99]).decode("utf-8")) # abc
# 所以我们创建一个字节序列的时候,也可以这么做
print(b"abc") # b'abc'
# 但是我们不可以b'憨', 因为'憨'这个字符不是ASCII字符, ASCII字符要求对应的ASCII码唯一、并且小于128
# 所以在不同的编码下会对应不同的ASCII码,比如gbk编码的话对应两个ASCII码, utf-8对应三个ASCII码
# 因此b'憨'的话,由于不知道使用哪一种编码, 所以Python不允许这么做,而是通过'憨'.encode的方式来手动指定编码
# 而'abc'都是纯ASCII字符,不管采用哪一种编码都会得到相同的ASCII码,所以Python允许这么做
# 当然对ASCII字符使用ASCII码也是可以的
小结
字符串的内容还是比较多的,在源码中有一万六千多行,显然我们没办法一步一步地全部分析完,有兴趣的可以自己深入研究一下。其实我们能把字符串的存储搞明白,其实已经是前进了一大步了。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号