
TOON 格式终于赢了!AI 大模型基准测试揭示惊人真相
最近在深入研究 TOON.NET 的时候,发现了一组非常有意思的基准测试数据。说实话,我对结果有点震惊——一个相对较新的格式,居然在多个主流 AI 大模型上的表现都远超 JSON 和 YAML。今天就想和大家好好聊聊这个发现,以及它背后的意义。
什么是 TOON?为什么它如此特殊
在深入测试结果之前,咱们得先理解 TOON 到底是个啥。
TOON(Text-Oriented Object Notation) 是一种轻量级的数据序列化格式,它的设计理念就是为了在保持人类可读性的同时,最大化地减少 token 消耗。相比 JSON 和 YAML 的冗长语法,TOON 采用了更加紧凑的表示方式:
- 元数据前置:通过
[size]{fields}的方式声明数组大小和对象字段,一次性告诉模型即将到来的数据结构 - 紧凑的值表示:避免了 JSON 中大量的引号、冒号、括号等符号
- 结构化的分隔:用冒号和缩进来表达层级关系,而不是嵌套的括号
这种设计对 AI 模型来说有个天然的好处——结构信息更清晰,需要的上下文窗口更小。但这只是我的推测,真正的验证需要拿数据说话。
实战测试:从本地部署到数据分析
我决定按照项目提供的方式,亲自跑一遍完整的基准测试。过程其实不复杂,但需要一点点耐心。
环境准备
首先确保你的电脑装了 .NET 10 SDK 和 VSCode。这是跑测试的基础。然后克隆项目到本地:
git clone https://github.com/AIDotNet/Toon.NET
启动基准测试
进入基准测试目录:
cd benchmarks\AIDotNet.Toon.ModelBenchmarks
运行启动脚本(这是我最喜欢的地方——直接一个 bat 脚本,省去了手动配置的麻烦):
.\run-benchmark.bat
脚本会交互式地询问你的配置。我这次的参数设置是:
======================================================
AIDotNet.Toon 模型基准测试 启动脚本 (Windows .bat)
该脚本将引导你输入 API Key 和模型后启动程序
======================================================
请输入 OPENAI_API_KEY:[你的 API Key]
请输入模型名称(逗号分隔):gpt-5-mini,gpt-4o-mini,gemini-2.5-flash,grok-code-fast-1,claude-haiku-4.5
可选:每个任务运行次数 BENCHMARK_RUNS:5
可选:模型级并发 BENCHMARK_MODEL_PARALLELISM:5
然后就是等待。测试会并行执行多个模型和格式组合,进度条会实时显示:

数据揭露:TOON 的压倒性优势
等待大约 3 分多钟后,测试完成了。输出的汇总结果直接让我眼前一亮:
正在启动基准测试(首次运行将进行构建)...
模型格式准确性基准(.NET)
claude-haiku-4.5 总结
┌──────────────┬──────────┬─────────────┬─────────────┐
│ 格式 │ 准确率 % │ 提示 Tokens │ 生成 Tokens │
├──────────────┼──────────┼─────────────┼─────────────┤
│ JSON │ 41.7 │ 150.2 │ 18.6 │
│ JSON compact │ 50.0 │ 115.2 │ 13.1 │
│ TOON │ 91.7 │ 110.5 │ 6.8 │
│ YAML │ 52.8 │ 120.3 │ 10.8 │
└──────────────┴──────────┴─────────────┴─────────────┘
gemini-2.5-flash 总结
┌──────────────┬──────────┬─────────────┬─────────────┐
│ 格式 │ 准确率 % │ 提示 Tokens │ 生成 Tokens │
├──────────────┼──────────┼─────────────┼─────────────┤
│ JSON │ 72.2 │ 152.1 │ 150.8 │
│ JSON compact │ 75.0 │ 111.2 │ 199.3 │
│ TOON │ 100.0 │ 106.2 │ 181.0 │
│ YAML │ 88.9 │ 123.9 │ 173.4 │
└──────────────┴──────────┴─────────────┴─────────────┘
gpt-4o-mini 总结
┌──────────────┬──────────┬─────────────┬─────────────┐
│ 格式 │ 准确率 % │ 提示 Tokens │ 生成 Tokens │
├──────────────┼──────────┼─────────────┼─────────────┤
│ JSON │ 41.7 │ 137.9 │ 9.4 │
│ JSON compact │ 36.1 │ 110.4 │ 8.3 │
│ TOON │ 83.3 │ 107.0 │ 4.1 │
│ YAML │ 50.0 │ 117.3 │ 9.5 │
└──────────────┴──────────┴─────────────┴─────────────┘
gpt-5-mini 总结
┌──────────────┬──────────┬─────────────┬─────────────┐
│ 格式 │ 准确率 % │ 提示 Tokens │ 生成 Tokens │
├──────────────┼──────────┼─────────────┼─────────────┤
│ JSON │ 58.3 │ 134.8 │ 277.4 │
│ JSON compact │ 58.3 │ 108.4 │ 323.7 │
│ TOON │ 83.3 │ 105.2 │ 152.8 │
│ YAML │ 75.0 │ 114.9 │ 300.4 │
└──────────────┴──────────┴─────────────┴─────────────┘
grok-code-fast-1 总结
┌──────────────┬──────────┬─────────────┬─────────────┐
│ 格式 │ 准确率 % │ 提示 Tokens │ 生成 Tokens │
├──────────────┼──────────┼─────────────┼─────────────┤
│ JSON │ 58.3 │ 330.0 │ 6.9 │
│ JSON compact │ 58.3 │ 301.9 │ 5.4 │
│ TOON │ 97.2 │ 290.7 │ 3.4 │
│ YAML │ 66.7 │ 301.3 │ 5.3 │
└──────────────┴──────────┴─────────────┴─────────────┘
关键数据洞察
1. 准确率:TOON 全面领先
看看准确率那一列,我觉得这是最能说明问题的地方:
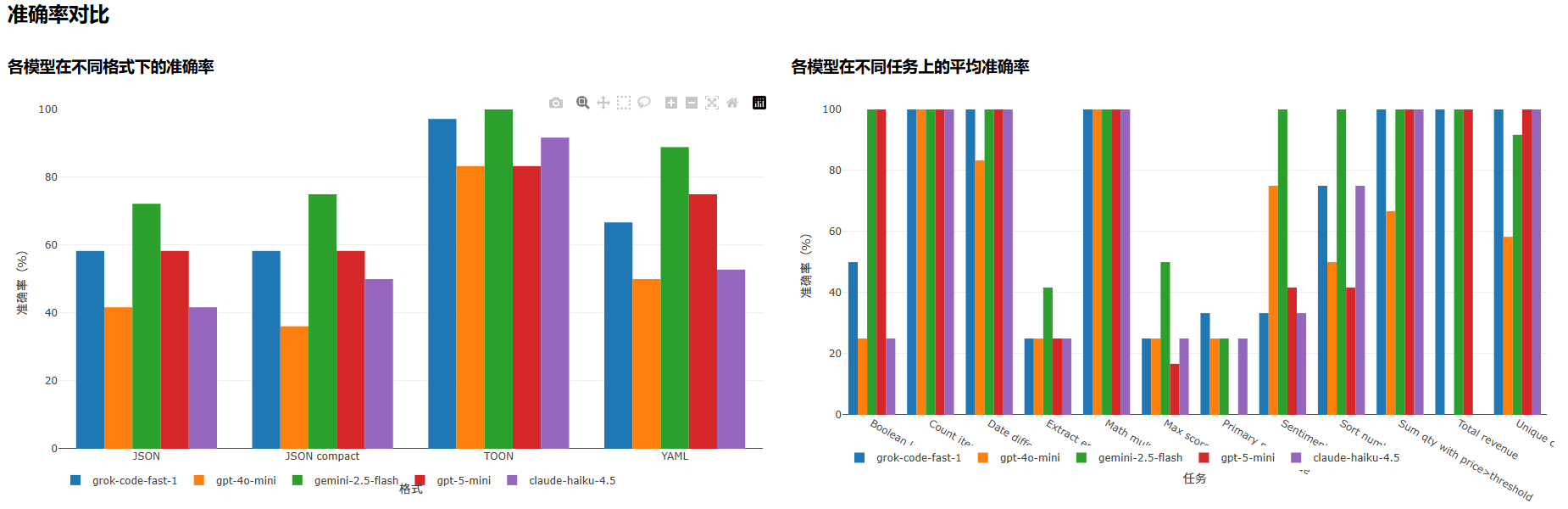
- gemini-2.5-flash:TOON 达到了完美的 100% 准确率,其他格式最高也只有 88.9%(YAML)
- grok-code-fast-1:TOON 以 97.2% 击败其他所有格式,JSON 和 JSON compact 只有 58.3%
- claude-haiku-4.5:TOON 的 91.7% 远超 JSON 的 41.7% 和 YAML 的 52.8%
- gpt-4o-mini:TOON 的 83.3% 高出第二名 YAML(50%)整整 33 个百分点
- gpt-5-mini:TOON 的 83.3% 同样稳健领先
这不是偶然现象,而是一个在所有五个主流大模型上都能重现的规律。
2. Token 消耗:成本与效率的双重胜利
这里更有意思。不仅准确率高,TOON 的 token 占用也是最低的:
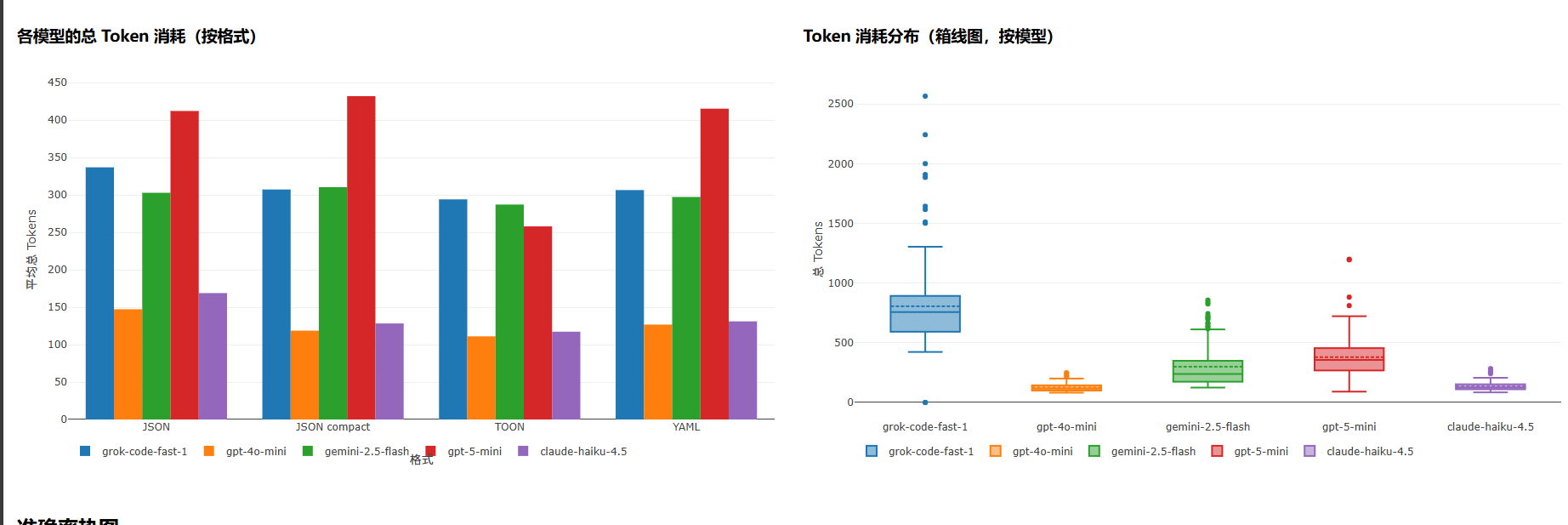
看看提示 Token 和生成 Token 的平均消耗:
| 模型 | 格式 | 平均提示 Tokens | 平均生成 Tokens | 平均总 Tokens |
|---|---|---|---|---|
| claude-haiku-4.5 | JSON | 150.2 | 18.6 | 168.9 |
| claude-haiku-4.5 | JSON compact | 115.2 | 13.1 | 128.3 |
| claude-haiku-4.5 | TOON | 110.5 | 6.8 | 117.3 |
| claude-haiku-4.5 | YAML | 120.3 | 10.8 | 131.1 |
| gemini-2.5-flash | JSON | 152.1 | 150.8 | 302.9 |
| gemini-2.5-flash | JSON compact | 111.2 | 199.3 | 310.4 |
| gemini-2.5-flash | TOON | 106.2 | 181.0 | 287.2 |
| gemini-2.5-flash | YAML | 123.9 | 173.4 | 297.3 |
| gpt-4o-mini | JSON | 137.9 | 9.4 | 147.3 |
| gpt-4o-mini | JSON compact | 110.4 | 8.3 | 118.7 |
| gpt-4o-mini | TOON | 107.0 | 4.1 | 111.1 |
| gpt-4o-mini | YAML | 117.3 | 9.5 | 126.8 |
| gpt-5-mini | JSON | 134.8 | 277.4 | 412.2 |
| gpt-5-mini | JSON compact | 108.4 | 323.7 | 432.0 |
| gpt-5-mini | TOON | 105.2 | 152.8 | 258.0 |
| gpt-5-mini | YAML | 114.9 | 300.4 | 415.3 |
| grok-code-fast-1 | JSON | 330.0 | 6.9 | 336.9 |
| grok-code-fast-1 | JSON compact | 301.9 | 5.4 | 307.3 |
| grok-code-fast-1 | TOON | 290.7 | 3.4 | 294.1 |
| grok-code-fast-1 | YAML | 301.3 | 5.2 | 306.5 |
看到这组数据,我当时的反应就是——这简直是在替开发者省钱。对于大规模数据传输的场景,token 消耗的降低直接转化为 API 调用成本的下降。
为什么 TOON 会这么"聪明"?
说实话,这个问题我琢磨了一会儿。为什么 AI 模型对 TOON 格式的理解能力会这么强?
我的初步理解是:
-
信息密度更高:TOON 的结构化表示让模型能更快速地建立起"这是一个包含 N 个元素、每个元素有 M 个字段"的心智模型,而不需要逐个解析括号和引号。
-
更少的干扰信息:JSON 的语法糖虽然对人类友好,但对模型来说是额外的认知负担。TOON 则直奔主题。
-
预测路径更清晰:TOON 的规则性强,模型的 next-token 预测变得更有把握。这在 token 生成阶段表现为更少的"纠结",生成结果也更准确。
实际应用场景:什么时候该用 TOON?
基于这些数据,我的建议是:
- 大数据量场景:API 调用传输 MB 级别的数据时,TOON 的 token 节省会非常显著
- 成本敏感项目:每一个 token 都算钱的时候,TOON 的优势不可忽视
- 高准确率要求:需要模型准确理解和处理结构化数据时,TOON 是更好的选择
- .NET 生态:如果你本身就是 .NET 栈,有现成的 SDK 支持,何乐而不为
C# 快速上手:用 TOON SDK 序列化数据
如果你是 .NET 开发者,我得好好介绍一下官方提供的 SDK,因为用起来真的很舒服。
安装
通过 NuGet 一行命令搞定:
dotnet add package AIDotNet.Toon
序列化为 TOON
using Toon;
var options = new ToonSerializerOptions
{
Indent = 2, // 用 2 个空格缩进
Delimiter = ToonDelimiter.Comma, // 用逗号分隔值
Strict = true, // 严格模式
LengthMarker = null // 不添加额外的长度标记
};
var data = new
{
users = new[]
{
new { name = "alice", age = 30 },
new { name = "bob", age = 25 }
},
tags = new[] { "a", "b", "c" },
numbers = new[] { 1, 2, 3 }
};
string toonText = ToonSerializer.Serialize(data, options);
// 输出结果是这样的:
// users[2]{name,age}:
// alice,30
// bob,25
// tags[3]: a,b,c
// numbers[3]: 1,2,3
看看这个输出格式,是不是特别清爽?没有多余的符号,每一个数据都清清楚楚地摆在那里。
反序列化(当前支持原子值)
using Toon;
var s = ToonSerializer.Deserialize<string>("hello", options); // "hello"
var n = ToonSerializer.Deserialize<double>("3.1415", options); // 3.1415
总结:一个小格式的大潜力
这次测试让我认识到,有时候看似"新奇"的技术方案,真的是在踏踏实实地解决实际问题。TOON 不是为了标新立异而标新立异,它的每一个设计决策都指向一个目标——让 AI 模型理解得更快、更准,让开发者的成本更低。
在 AI 时代,结构化数据的表示方式直接关系到应用的成本和体验。如果你还在用 JSON 传输大量数据给 AI 模型,不妨试试 TOON,相信你会有惊喜的发现。
项目地址:https://github.com/AIDotNet/Toon.NET
官方地址:https://github.com/toon-format/toon
toon标准:https://github.com/toon-format/spec
如果这篇文章对你有帮助,请记得给项目一个 Star!每一个 Star 都是对开源作者的认可,也会激励他们继续打磨这个工具。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号