Linux下的内存管理:02.深入jemalloc,多线程内存分配器的结构与算法
前言
在上一篇《从 malloc 到缺页中断》中,我们深入探索了 malloc 与内核的“垂直”交互:程序如何通过 brk/mmap 申请虚拟内存(VMA),以及如何在第一次写入时触发“缺页中断”(Page Fault),最终获得物理内存。
在这篇文章中,我们将讲解jemalloc这个被redis,Firefox等著名项目默认使用的现代的内存分配器,了解这个项目是怎么多线程情况下更高性能的分配效果。
我们将从它的核心设计(数据结构+算法)出发,深入探究 jemalloc 使用什么样的数据结构来管理内存,以及在 malloc 和 free 时执行了怎样的算法流程。最终,我们将通过关键路径的源码,印证我们的理解。
注:本文使用的是jemalloc-5.3.0版本
快速上手:jemalloc的使用
在我们深入内部之前,先看看怎么用它。
jemalloc 的使用非常简单,它利用了 LD_PRELOAD 动态链接库预加载机制,可以“劫持”程序中所有的 malloc / free / calloc / realloc 等调用。
假设你已经编译安装了 jemalloc (通常会得到 libjemalloc.so.2 这样的文件):
# 编译你的程序(正常编译即可)
gcc -o my_app my_app.c
# 运行时通过 LD_PRELOAD 强行使用 jemalloc
LD_PRELOAD=/path/to/libjemalloc.so.2 ./my_app
程序代码将无需任何修改,它在运行时就会自动使用 jemalloc 的内存分配策略。
jemalloc的核心思想
jemalloc 的核心思想可以总结为:“分而治之” + “多级缓存”。
它将整个内存空间划分成一套精巧的多层级结构,其设计的核心目的就是:不惜一切代价避免加锁,尤其是避免加全局锁。
Arena:隔离线程,减少竞争
jemalloc 将整个内存空间划分成多个 Arena(内存竞技场)。这是一个至关重要的设计。
- 默认情况下,jemalloc 会创建 n * CPU核心数 个 Arena(例如 4 核 CPU,默认可能是 16 个)。
- 当一个线程第一次需要分配内存时,jemalloc 会通过轮询(Round-Robin)的方式为其固定分配一个 Arena。
- 关键点: 多个线程可能共享一个
Arena,但jemalloc的策略使得线程被高度分散在不同的Arena中。
这有什么好处?
假设有 16 个 Arena 和 100 个线程。最理想情况下,大概 6-7 个线程共享 1 个 Arena。每个 Arena 都有自己的锁,jemalloc 降低了锁的压力,极大地提高了并发度。
大小对象分离:Bin 与 Extent
每个 Arena 内部,管理者两种截然不同的内存分配方式:小对象(Small) 和 大对象(Large)。
-
小对象(Small Objects):
jemalloc将小对象(例如,< 32KB)划分为几十个大小等级(Size Classes),如 8字节、16字节、32字节、48字节...Arena中有一个bin数组,每个bin负责一个特定的大小等级。Bin只是一个管理者,它真正管理的是一组Slab(在jemalloc源码中常称为run或slab,在代码中具体表现为edata_t)。- 一个
Slab是一个连续的内存页(如 4KB),它被预先切割成N个固定大小的块(block),这个大小由它所属的Bin决定。例如,一个 4KB 的Slab被 32 字节的Bin管理,它就会被切成 128 个 32 字节的 block。
-
大对象(Large Objects):
- 对于超过小对象阈值的大内存,
jemalloc不再使用Bin/Slab。 Arena会直接以页(Page)为单位来管理它们。Arena内部维护着一个基数树(Radix Tree)(一种比红黑树更优化的树状结构)来挂载和管理这些空闲的大内存页(Extent)。
- 对于超过小对象阈值的大内存,
TCache:极速的线程私有缓存(性能核心)
Arena 已经将锁的竞争从“全局”降低到了“小组”。但 jemalloc 追求极致,连“小组”内的竞争也要(尽可能)消除。这就是 TCache(Thread-Specific Cache) 的使命。
jemalloc会为每一个使用它的线程创建一个TCache。TCache是线程私有的,因此对它的一切操作都完全不需要加锁。TCache内部也有一组bin(cache_bin_t),与Arena的bin对应。TCache的bin中存放的是一个空闲 block 的指针数组。
这就是 jemalloc 性能的精髓所在:
- 当线程
malloc一个小对象时,它首先在自己的TCache中寻找对应大小的bin。 - (极速路径) 如果
TCache中有空闲 block,直接从链表中取出一个返回。全程无锁,快如闪电。 - (进货路径) 如果
TCache空了,它会向自己绑定的Arena“进货”(Refill)。 - “进货”时,
TCache会锁住Arena中对应的Bin,然后批量(例如 20 个)从Slab中获取 block,填充到自己的TCache中,然后解锁。 - 最后,返回一个 block 给用户。
free 小对象时反之:优先(无锁)放回 TCache,TCache 满了再一次性(有锁)“刷回”(Flush)给 Arena。
通过
TCache,jemalloc将有锁的Arena访问摊薄到了N次无锁的TCache访问中,极大地提高了平均分配性能。
源码剖析
理论终须源码印证。下面我们将简单的查看内部到底是怎么分配内存的
核心入口:arena_malloc
je_malloc 在选择了 Arena 之后,会调用 arena_malloc。这是 Arena 内部的“总指挥室”。
// 这是一个 Arena 内部的总入口
JEMALLOC_ALWAYS_INLINE void *
arena_malloc(tsdn_t *tsdn, arena_t *arena, size_t size, szind_t ind, bool zero,
tcache_t *tcache, bool slow_path) {
// 关键分支点 1: 检查 TCache 是否存在
if (likely(tcache != NULL)) {
// 关键分支点 2: 是否为小对象
if (likely(size <= SC_SMALL_MAXCLASS)) {
// 路径 A: TCache - 小对象
return tcache_alloc_small(...);
}
// 关键分支点 3: 是否为“可缓存的”大对象
if (likely(size <= tcache_maxclass)) {
// 路径 B: TCache - 大对象
return tcache_alloc_large(...);
}
// 如果对象太大,TCache 不管,掉下去
}
// 路径 C: 终极 fallback
// 1. TCache 被禁用
// 2. TCache 路径尝试后失败 (slow_path = true)
// 3. 对象太大 TCache 不管
return arena_malloc_hard(tsdn, arena, size, ind, zero);
}
源码解读:
此函数完美地展现了jemalloc的分层设计。它优先尝试TCache。TCache被分为“小对象缓存”和“(中)大对象缓存”。如果TCache路径走不通,才会进入arena_malloc_hard这个“硬核分配”路径。
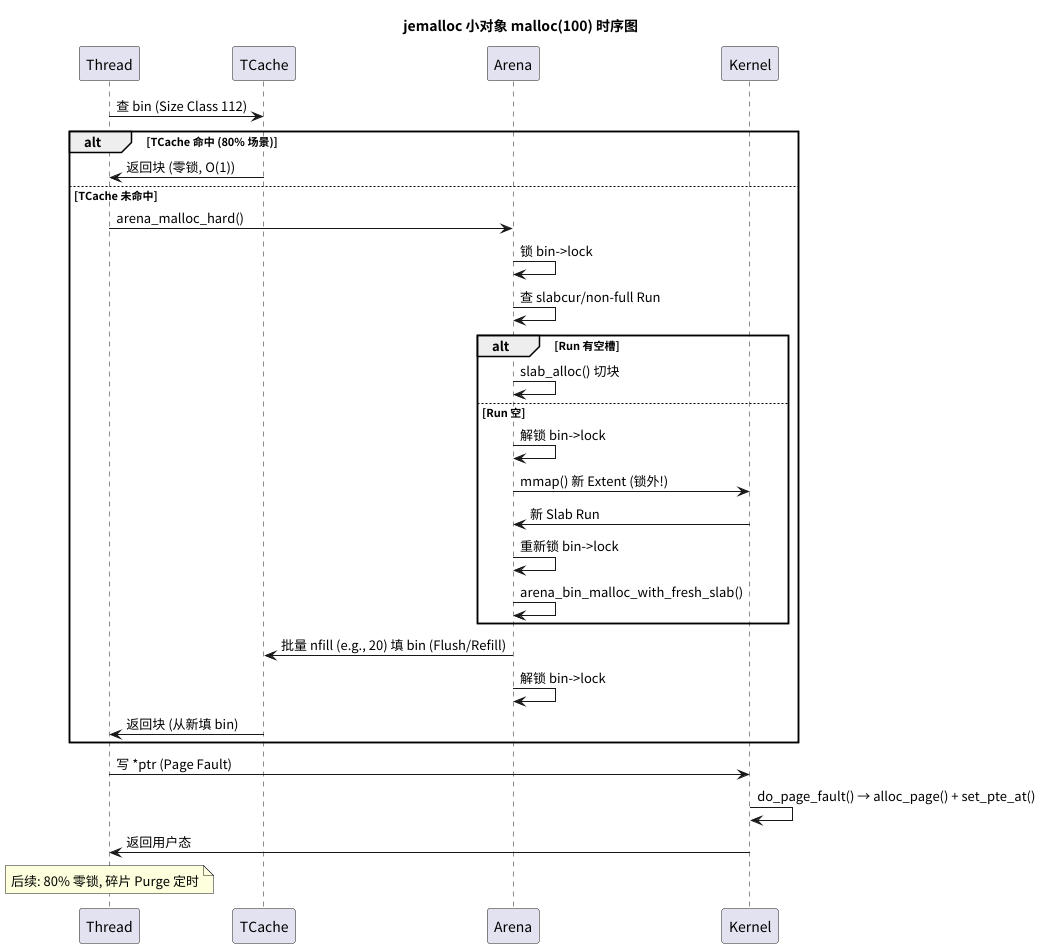
小对象分配
极速路径:tcache_alloc_small
这是 jemalloc 90% 时间都在走的路径。
JEMALLOC_ALWAYS_INLINE void *
tcache_alloc_small(tsd_t *tsd, arena_t *arena, tcache_t *tcache,
size_t size, szind_t binind, bool zero, bool slow_path) {
void *ret;
bool tcache_success;
// 定位到 TCache 中对应的 bin
cache_bin_t *bin = &tcache->bins[binind];
// 1. 【极速路径】尝试从 bin 的空闲链表头部弹出一个
ret = cache_bin_alloc(bin, &tcache_success);
// 2. 【TCache 未命中】
if (unlikely(!tcache_success)) {
// TCache 没货了
// ... (省略一些 arena_choose 和-d 禁用检查) ...
// 3. 刷回(Flush)一下可能暂存的 block,为“进货”做准备
tcache_bin_flush_stashed(...);
// 4. 【核心】进入“硬核分配”路径,即“进货”
ret = tcache_alloc_small_hard(tsd_tsdn(tsd), arena, tcache,
bin, binind, &tcache_hard_success);
if (tcache_hard_success == false) {
return NULL; // 进货失败 (OOM)
}
}
// ... (处理 zero 和 stats 统计) ...
return ret;
}
源码解读:
性能的秘密就在unlikely(!tcache_success)。如果TCache命中,函数在几个CPU时钟周期内就返回了(完全无锁)。只有当TCache未命中时,才需要调用tcache_alloc_small_hard去执行“进货”这个慢操作。
tcache_alloc_small_hard
这个函数是“进货”的准备阶段,它负责计算“进多少货”。
void *
tcache_alloc_small_hard(tsdn_t *tsdn, arena_t *arena,
tcache_t *tcache, cache_bin_t *cache_bin, szind_t binind,
bool *tcache_success) {
// ...
// 1. 计算要“进货”多少个 (nfill),这是一个动态计算的值
unsigned nfill = cache_bin_info_ncached_max(&tcache_bin_info[binind])
>> tcache_slow->lg_fill_div[binind];
// 2. 【核心】调用 Arena,批量填充 TCache 的 bin
arena_cache_bin_fill_small(tsdn, arena, cache_bin,
&tcache_bin_info[binind], binind, nfill);
// 3. 进货完成,TCache 的 bin 已经填满
// 再次调用(必定成功),从 TCache 中拿一个
ret = cache_bin_alloc(cache_bin, tcache_success);
return ret;
}
源码解读:
tcache_alloc_small_hard的职责很清晰:计算批量(nfill)-> 调用Arena执行批量填充 -> 填充后再次cache_bin_alloc。
真正复杂、有锁的操作,被封装在arena_cache_bin_fill_small中。
arena_cache_bin_fill_small (Arena 批量填充)
这是 jemalloc 中最精妙、最复杂的操作之一。锁,将在这里出现。
void
arena_cache_bin_fill_small(tsdn_t *tsdn, arena_t *arena,
cache_bin_t *cache_bin, ..., const unsigned nfill) {
// ... (准备工作,声明一个指针数组) ...
bool made_progress = true; // 标记是否取得进展
edata_t *fresh_slab = NULL; // 预备的新 Slab
bool alloc_and_retry = false; // 是否需要分配新 Slab 并重试
unsigned filled = 0; // 已填充数量
bin_t *bin = arena_bin_choose(...); // 找到 Arena 的那个 bin
label_refill: // GOTO 标签,用于重试
// 1. 【加锁】
// 这是 TCache 路径上遇到的第一个真正的锁!
malloc_mutex_lock(tsdn, &bin->lock);
while (filled < nfill) {
// 2. 尝试从当前 Slab (slabcur) 批量分配
edata_t *slabcur = bin->slabcur;
if (slabcur != NULL && edata_nfree_get(slabcur) > 0) {
// ... (计算并批量分配) ...
arena_slab_reg_alloc_batch(slabcur, ...);
made_progress = true;
filled += cnt;
continue; // 继续循环,看是否还需要
}
// 3. 当前 Slab 满了,尝试从“非满”Slab 列表中找一个
if (!arena_bin_refill_slabcur_no_fresh_slab(tsdn, arena, bin)) {
assert(bin->slabcur != NULL);
continue; // 找到了,回到 while 顶部继续分配
}
// 4. “非满”列表也空了,看看是否已有预备的 fresh_slab
if (fresh_slab != NULL) {
arena_bin_refill_slabcur_with_fresh_slab(...);
fresh_slab = NULL;
continue; // 激活了新Slab,回到 while 顶部
}
// 5. 真的没辙了。如果上次取得了进展,我们允许去分配新 Slab
if (made_progress) {
alloc_and_retry = true;
break; // 退出 while 循环,准备去分配
}
// 6. 连新 Slab 都分配过了,还是没进展,OOM
break;
} // while 循环结束
// 7. 【解锁】
malloc_mutex_unlock(tsdn, &bin->lock);
// 8. 【精妙之处】
if (alloc_and_retry) {
// 走到这里,说明 bin->lock 已经被释放
// 9. 【分配新 Slab】
// 这是一个慢操作 (可能涉及 mmap),
// 但它是在 *锁外* 执行的!
fresh_slab = arena_slab_alloc(tsdn, arena, binind, ...);
alloc_and_retry = false;
made_progress = false; // 重置进展
// 10. 重新跳回“label_refill”,准备重新加锁并尝试
goto label_refill;
}
// 11. 结束,将所有“进货”的指针加载到 TCache 的 bin 中
cache_bin_finish_fill(cache_bin, ...);
}
源码解读:
- 加锁: 它必须锁住
Arena的bin才能安全地操作Slab列表。- 最小化锁持有时间: 它在锁内只做快操作(检查
slabcur、检查nonfull列表)。- 锁外执行慢操作: 当必须执行
arena_slab_alloc(内部可能涉及mmap系统调用)这种“超级慢”的操作时,它会先释放锁,执行慢操作,然后再goto回去重新加_(并重试)。goto的妙用: 这里的goto完美地实现了一个“释放-重试”循环,避免了在锁内执行不可预测时长的操作。
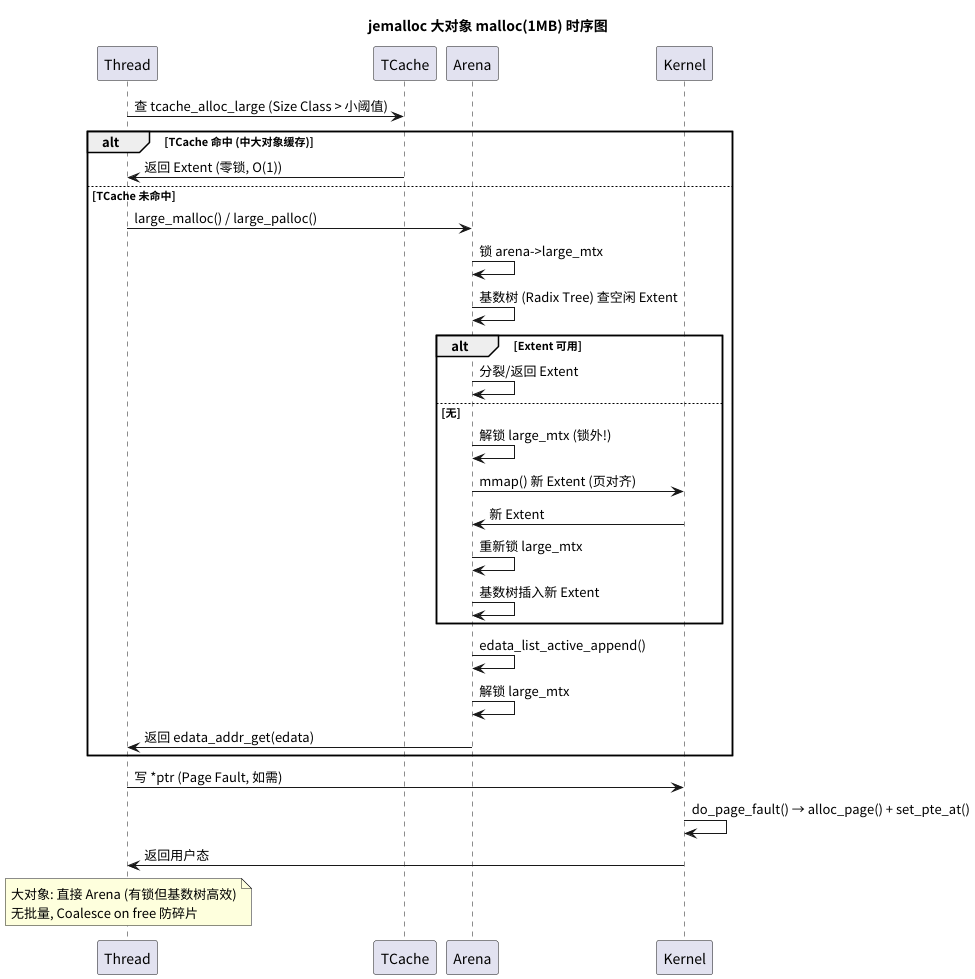
大对象
tcache_alloc_large 和 large_palloc
jemalloc 也会尝试缓存“不大不小”的对象(例如 32KB ~ 512KB)。
// 路径 B: TCache - 大对象
JEMALLOC_ALWAYS_INLINE void *
tcache_alloc_large(tsd_t *tsd, arena_t *arena, tcache_t *tcache, size_t size,
szind_t binind, bool zero, bool slow_path) {
// 1. 【极速路径】和 tcache_alloc_small 一样,尝试 TCache 命中
cache_bin_t *bin = &tcache->bins[binind];
ret = cache_bin_alloc(bin, &tcache_success);
if (unlikely(!tcache_success)) {
// 2. 【TCache 未命中】
// 注意!大对象“进货”策略不同
// 它不会“批量进货”,因为太贵了
// 它选择直接去 Arena 要一个
// 3. 【核心】直接调用大对象分配器
ret = large_malloc(tsd_tsdn(tsd), arena, sz_s2u(size), zero);
// ... (如果成功,ret 会返回,但不会放入 TCache)
}
// ...
return ret;
}
large_malloc 最终会调用到 large_palloc(Page-aligned allocation)。
// 真正的大对象分配(有锁)
void *
large_palloc(tsdn_t *tsdn, arena_t *arena, size_t usize, size_t alignment,
bool zero) {
// ... (ausize 计算对齐) ...
// 1. 选一个 Arena (如果需要,可能会选 Huge Arena)
if (likely(!tsdn_null(tsdn))) {
arena = arena_choose_maybe_huge(tsdn_tsd(tsdn), arena, usize);
}
// 2. 【核心】
// edata = arena_extent_alloc_large(...)
// 这函数会进入 Arena,锁住 Arena 的大对象管理结构(基数树)
// 查找一个足够大的空闲 Extent (页块)
// 如果找不到,就 mmap 新的内存
if (unlikely(arena == NULL) || (edata = arena_extent_alloc_large(tsdn,
arena, usize, alignment, zero)) == NULL) {
return NULL; // OOM
}
// 3. 【加锁】
// 将这个分配的 extent 记录到 Arena 的 large 链表中
// (注意:这里用了 arena->large_mtx,是独立的锁)
if (!arena_is_auto(arena)) {
malloc_mutex_lock(tsdn, &arena->large_mtx);
edata_list_active_append(&arena->large, edata);
malloc_mutex_unlock(tsdn, &arena->large_mtx);
}
return edata_addr_get(edata);
}
源码解读:
大对象分配路径清晰得多:
TCache只会缓存(cache_bin_alloc)之前free过的大对象。TCache不会为大对象“批量进货”。- 当
TCache未命中时,直接调用large_palloc。large_palloc总是需要加锁(arena->large_mtx或arena_extent_alloc_large内部的锁),以操作Arena的基数树来查找、分裂或mmap新的内存页。
arena_malloc_hard 和 arena_malloc_small
如果 TCache 被禁用(tcache == NULL),或者 TCache 路径失败,arena_malloc 就会调用 arena_malloc_hard。
void *
arena_malloc_hard(tsdn_t *tsdn, arena_t *arena, size_t size, szind_t ind,
bool zero) {
// ... (arena_choose_maybe_huge) ...
// 1. 小于等于最大小对象
if (likely(size <= SC_SMALL_MAXCLASS)) {
// 路径 C.1: 直接调用 Arena 的小对象分配 (无 TCache)
return arena_malloc_small(tsdn, arena, ind, zero);
}
// 路径 C.2: 调用大对象分配 (无 TCache)
return large_malloc(tsdn, arena, sz_index2size(ind), zero);
}
arena_malloc_small 是 arena_cache_bin_fill_small 的“单次分配”版本。
// 在没有 TCache 时,线程每次都要调用这个函数
static void *
arena_malloc_small(tsdn_t *tsdn, arena_t *arena, szind_t binind, bool zero) {
// ...
bin_t *bin = arena_bin_choose(...);
// 1. 【加锁】
// 每次分配都必须加锁!
malloc_mutex_lock(tsdn, &bin->lock);
// 2. 尝试从 bin 分配(先 slabcur,再 non-full)
void *ret = arena_bin_malloc_no_fresh_slab(tsdn, arena, bin, binind);
if (ret == NULL) {
// 3. 分配失败,【解锁】
malloc_mutex_unlock(tsdn, &bin->lock);
// 4. 【锁外】分配新 Slab (慢操作)
fresh_slab = arena_slab_alloc(tsdn, arena, binind, ...);
// 5. 【重新加锁】
malloc_mutex_lock(tsdn, &bin->lock);
// 6. 再次尝试(因为锁被释放过)
ret = arena_bin_malloc_no_fresh_slab(tsdn, arena, bin, binind);
if (ret == NULL) {
if (fresh_slab == NULL) { /* OOM */ }
// 7. 使用刚刚分配的新 Slab
ret = arena_bin_malloc_with_fresh_slab(...);
}
}
// 8. 【解锁】
malloc_mutex_unlock(tsdn, &bin->lock);
// ...
return ret;
}
源码解读:
这段代码完美地反衬了TCache的重要性。
- 没有 TCache:
malloc一次小对象 = 加锁 1 次。如果Slab不足 = 解锁 1 次 +mmap1 次 + 重加锁 1 次 + 解锁 1 次。- 有了 TCache:
malloc一次小对象 = 0 次锁。只有在N次malloc后(N是批量大小),才需要执行一次上述的加锁/解锁/分配流程。性能差距,高下立判。
free 的过程:对称的艺术
free 的过程与 malloc 完全对称:
free(小对象):
- 极速路径:(无锁)将 block
push回TCache对应bin。 - 刷回路径: 当
TCache的bin满了,触发tcache_flush。Flush会加锁Arena的bin,批量将TCache中的 block 归还给它们各自的Slab(通过bitmap标记为空闲)。
free(大对象):
- (有锁)
free大对象会绕过TCache(或在TCache满时),直接调用Arena的large_free。 Arena会加锁,将这个Extent(页块)归还到基数树中。- 核心: 归还时,
jemalloc会检查这个Extent前后相邻的地址是否也是空闲Extent,如果是,则将它们合并(Coalesce)成一个更大的空闲块。这是对抗内存碎片的终极武器。
总结
jemalloc 之所以能提升性能,正是因为它巧妙的运用“数据结构 + 算法”运用,在“性能”与“并发”的平衡木上找到了最优解:
- 分治(Arenas): 用空间换时间,将全局锁竞争分散为
N个Arena锁竞争。 - 缓存(TCache): 用“线程私有”的
TCache实现了小对象分配的无锁极速路径,这是其性能超越ptmalloc的最核心原因。 - 均摊(Batching):
TCache的“进货”和“刷回”都是批量操作,将昂贵的锁操作成本均摊到N次无锁访问中。 - 隔离(Lock-Dropping): 在必须加锁的慢路径中(如
arena_cache_bin_fill_small),它精妙地在锁外执行mmap等慢操作,最大限度地缩短了锁的持有时间。 - 合并(Coalescing): 大对象释放时的自动合并机制,有效对抗了内存碎片。
jemalloc 就像一个精密的、多级联动的缓冲系统,它用尽一切办法让线程在“无锁”的 TCache 独木桥上奔跑,只有在万不得已时,才让它们去“有锁”的 Arena 公路排队,并且连排队都设计了“慢车道(mmap)让行”的规则。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号