Linux下的内存管理:01.从 malloc 到缺页中断——一次完整的内存分配剖析
前言
在之前的文章中,我们讲述了,从源码到进程中的过程,了解了源码是怎么变成进程,linux系统是怎么使用静态库与动态库的。
在这个小节我们就开始一个新的篇章,准备对linux的内存管理下的相关内容进行分析,了解Linux下的内存管理机制。
本篇内容就从最基础的malloc开始,讲述malloc背后的故事。
malloc为什么会慢?
如果 malloc 内部就像我们实现一个环形缓冲区时那么简单,只是移动指针,将需要的内存从一大块内存中取出,那么实际的内存分配不应该是任何性能瓶颈,但是在开发中,我们可能会遇见各种内存分配引发的性能问题:
- 多线程锁竞争(Contention): 当给程序增加线程的数量时,发现没有性能,反而下降了? 因为可能多个线程在
malloc内部竞争同一把锁。 - 隐藏的页面错误(Page Faults)): 为什么
malloc申请到内存的时候,延迟极低,但是当第一次写入内存的时候,延迟一下子提高了?因为当时申请内存的时候只是一个 "标记",使用的时候才去真实请求。 - 系统调用开销(Syscall Overhead):为什么有的
malloc快如闪电,有的却延迟极高? 因为可能触发了昂贵的系统调用。 - 内存碎片(Fragmentation): 为什么系统中显示我程序的内存占用总是比我自己统计的要高?因为glibc可能没有将你的内存归还给操作系统。
- 缓存与TLB失效(Cache & TLB Misses): 为什么我的算法在逻辑上应该很快,但是数据跑起来很慢?因为你频繁触发了页面中段,CPU的缓存与TLB完全失效了。
正是内存可能会导致程序出现问题,我们才要去学习和了解malloc内部实现的机制,方便之后在遇到问题的时候,有思路查找和解决问题。
malloc的基本原理
首先需要强调的,也是最重要的一个内容: malloc并不是一个系统调用 (Sysyem Call),他是一个c标准库中提供的 用户态 函数。
我们在linux上使用的 malloc通常是glibc提供的,也是工作在用户空间空间管理内存的,就像大家知道的用户态与内核态切换会带来较大的性能损耗, malloc也会尽可能避免和内核打交道。
malloc自身的内存管理
glibc实现了一个名叫ptmalloc2的非常精巧的内存管理器,当你调用malloc分配,使用free释放内存的时候,实际上就是是向这个家伙去要和归还内存。
ptmalloc2自己会管理操作系统申请内存和归还的过程,为了实现尽量实现 少和内核打交道的目标,ptmalloc2内部有复杂的机制:
- Arena: 为了解决多线程锁竞争,
ptmalloc2会为不同的线程(核心)创建不同的“Arena”。每个Arena都是一个独立的内存池。线程分配时,会先尝试在自己的Arena中获取内存,这样就不用和其它线程抢锁了。这就是为什么jemalloc或tcmalloc(Google的)这类现代分配器在高并发下性能更好的原因,它们在“每线程缓存”上做得更彻底。 - Bins: 在Arena内部,被
free掉的内存块不会马上还给操作系统。它们会被根据大小,放进不同的“箱子”(空闲链表,free lists)里。- Fast Bins: 用于存放非常小的、刚被释放的内存块。下次你申请同样大小的内存时,它可以“闪电般”地从这里取出,连锁都不用加(使用原子操作)。
- Small Bins / Large Bins: 存放其它大小的空闲块。
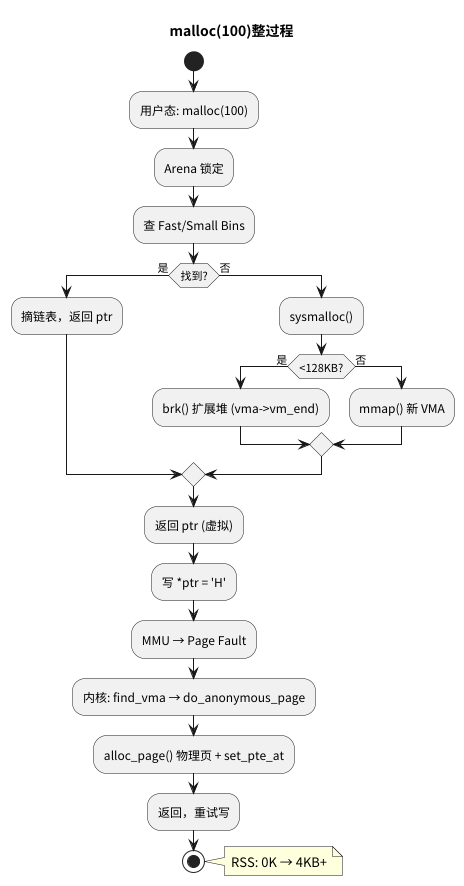
malloc(100) 的典型流程:
- 获取当前线程的Arena。
- (尝试)锁定这个Arena(如果是多线程)。
- 根据100字节的大小,计算出实际需要的块大小(需要加上头部管理信息)。
- 快速路径: 尝试从Fast Bins或Small Bins中寻找一个大小合适的空闲块。
- 如果找到: 完美!
ptmalloc2将这个块从链表上摘下,标记为“已使用”,解锁,然后返回指针给你。这个过程极快,完全在用户态完成,没有内核介入。 - 如果没找到: 事情开始变得有趣了。这个时候就必须和内核交流了。
向内核请求内存
当ptmalloc2发现自己的Bins里没有合适的内存块时,它必须向内核申请。它有两个主要的工具:brk 和 mmap。
-
brk(sbrk):- 这是“传统”的方式。 每一个进程都有一个“堆”(Heap)内存区域。
brk系统调用的作用就是移动“堆”的顶部指针(program break)。 void* sbrk(intptr_t increment);ptmalloc2会通过brk(SIZE)告诉内核:“请把我的堆内存扩大SIZE个字节”。- 优点: 连续的内存,管理简单。
- 缺点: 极其不灵活。 如果你
free了堆中间的一块内存,brk无法“收缩”这部分,除非你free的是最顶部的内存。这会导致严重的内存碎片,内存“只增不减”。
- 这是“传统”的方式。 每一个进程都有一个“堆”(Heap)内存区域。
-
mmap(Memory Map):- 这是“现代”的方式。
mmap是一个功能强大无比的系统调用,它可以让内核在进程的 虚拟地址空间 中“凭空”创建一块新的、独立的内存区域。 void* mmap(NULL, SIZE, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);- 这个调用告诉内核:“请给我一块
SIZE大小的、可读可写、私有且匿名的(不关联任何文件)内存”。 - 优点: 极其灵活。当C++的
delete调用free,并且ptmalloc2发现这个mmap出来的区域整个被释放了,它会使用munmap系统调用,将这块内存 完整地归还给操作系统。 - 缺点: 开销比
brk略大,且容易产生大量离散的内存区域(VMA)。
- 这是“现代”的方式。
ptmalloc2的策略是:
- 小内存(默认 < 128KB): 优先使用
brk来扩展主Arena的Heap。 - 大内存(默认 >= 128KB): 直接使用
mmap。这就是为什么你malloc一个超大数组时,程序占用的“虚拟内存”会暴增。 - 非主线程的Arena: 也会使用
mmap来创建“线程堆”。
内核开始去规划分配内存
现在我们进入了内核态。无论你调用brk还是mmap,内核 都不会立即分配物理内存(RAM)。
这可能是最重要的一个概念:Linux内核是“懒惰”的(Lazy Allocation)。
当你调用mmap申请1GB内存时,内核只是在你的进程的“内存地图”(mm_struct)里创建了一个条目,这个条目叫 VMA (Virtual Memory Area)。
VMA只是一张契约,它记录着:“这个进程 有权 访问从虚拟地址0xABCD0000到0xABCDFFFF的内存,权限是‘可读可写’”。
此时,物理RAM一字节都没有被占用。mmap系统调用(或brk)在微秒级就返回了。
页面中断,真正开始分配物理内存
malloc成功返回了一个指针ptr。你的C++代码开始 使用 这块内存:
char* ptr = (char*)malloc(1024 * 1024); // 申请 1MB
*ptr = 'H'; // 重点在这里!第一次写入
当CPU执行*ptr = 'H'时,奇妙的事情发生了:
- CPU的 MMU(内存管理单元) 尝试将这个虚拟地址
ptr翻译成物理地址。 - MMU会去查询 页表(Page Table)。
- MMU发现,这个虚拟地址对应的页表项(PTE)是空的,或者标记为“不存在”(Present=0)。
- 硬件中断! MMU无法完成翻译,它会立刻暂停你的程序,触发一个 #PF 异常,即“页面错误”(Page Fault)。
- 控制权立刻从“用户态”切换到“内核态”,交给内核的Page Fault处理器(
do_page_fault)。
内核的Page Fault处理器开始工作:
- 检查“契约”: 内核查看进程的VMA列表。“这个地址
ptr是不是合法的?哦,是的,VMA表里记录了它有权访问这里。”(如果没记录,就是非法的,内核会杀死进程,这就是 Segment Fault)。 - 分配物理内存: 这是一个合法的“缺页”,只是因为内核偷懒还没分配。内核会立即调用它的“页分配器”(Buddy System,伙伴算法),从空闲的物理RAM中找出一个物理页框(Page Frame)(通常是4KB)。
- 清零(可选): 为安全起见(防止泄露其它进程的数据),内核会先把这4KB物理内存清零。
- 建立映射: 内核会更新页表,将你访问的 虚拟地址
ptr所在的页,映射到刚刚分配的 物理页框。 - 返回用户态: 内核处理完毕,返回用户态。
- CPU重新执行失败的指令:
*ptr = 'H'。 - 这一次,MMU通过页表,成功将虚拟地址翻译成物理地址,数据被写入RAM。
这就是为什么你malloc很快,但第一次memset很慢的原因。 你在memset时,在为这块内存的 每一个 4KB页面(Page)支付“Page Fault”的开销。
实验验证
我们在这个小节通过最简单的程序来观察,内存分配和缺页中断的过程
准备源码和可执行程序
准备一个简单的C程序 (test_mem.c):
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int main()
{
printf("My PID is: %d\n", getpid());
// 1. 一个小的分配
printf("Allocating small block (100 bytes)...\n");
void* small_ptr = malloc(100);
memset(small_ptr, 1, 100);
printf("Small block allocated at: %p\n", small_ptr);
// 2. 一个大的分配
printf("Allocating large block (100 MB)...\n");
void* large_ptr = malloc(100 * 1024 * 1024);
printf("Large block allocated (virtually) at: %p\n", large_ptr);
// 在这里暂停,让我们有机会观察
printf("Press ENTER to write to large block (trigger Page Faults)...\n");
getchar();
// 3. 触发 Page Fault
memset(large_ptr, 2, 100 * 1024 * 1024);
printf("Large block written.n");
printf("Press ENTER to exit...n");
getchar();
free(small_ptr);
free(large_ptr);
return 0;
}
# 编译并运行
gcc test_mem.c -o test_mem
strace 追踪系统调用
strace可以捕获程序发起的所有系统调用。
# -f 跟踪子进程, -e trace=memory 限制只看内存相关的系统调用
strace -f -e trace=memory ./test_mem
你会看到(简化后的)输出:
My PID is: 41302
Allocating small block (100 bytes)...
Small block allocated at: 0x5e99d577e6b0
Allocating large block (100 MB)...
mmap(NULL, 104861696, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7efaff1ff000
Large block allocated (virtually) at: 0x7efaff1ff010
Press ENTER to write to large block (trigger Page Faults)...
Large block written.
Press ENTER to exit..
munmap(0x7efaff1ff000, 104861696) = 0 <-- free大内存时,munmap被调用
+++ exited with 0 +++
结论:
- 小的
malloc(100)直接获取到了,没有由向内核重新申请。 - 大的
malloc(100MB)由mmap分配。 memset(写入操作)没有触发新的系统调用,但它触发了内核态的 Page Fault。
实验二:pmap 查看内存地图
打开另一个终端,在程序等待你按回车时,查看它的内存地图。
# 替换41302为你的PID
pmap -x 41302
在按回车写入前,你会看到:
Address Kbytes RSS Dirty Mode Mapping
......
00005e99d577e000 132 4 4 rw--- [ anon ] <-- 最初malloc100使用的
00007efaff1ff000 102404 4 4 rw--- [ anon ] <-- mmap 的 100MB 区域
...
查看0x5e99d577e6b0和0x7efaff1ff000所在区域的相关内容,注意看 RSS(Resident Set Size),这是 真正 占用的物理内存。
[anon](mmap区域)的RSS是 4K!我们有132k的 虚拟 内存,占用了4k,因为就使用100字节的内存。
[anon](mmap区域)的RSS也是 4K!我们有100MB的 虚拟 内存,但没有占用同等大小的 物理 内存。
按下回车,让memset执行完后,再次运行pmap -x 41302:
Address Kbytes RSS Dirty Mode Mapping
...
00005e99d577e000 132 4 4 rw--- [ anon ]
00007efaff1ff000 102404 102404 102404 rw--- [ anon ]
...
RSS现在变成了 102404K! 所有的物理内存都在memset时,通过Page Fault被分配了。
从glibc到Linux内核的源码阅读
下面的代码对glibc和内核中的源码进行了高度简化和伪代码化的,但它们精确地反映了核心逻辑和函数调用链。
1. 用户态:glibc 的 ptmalloc2 (malloc/malloc.c)
从malloc(100)开始。它会调用_int_malloc,这是ptmalloc2的心脏。
_int_malloc:在 Bins 中寻找
假设我们调用malloc(100)。ptmalloc2会先将其对齐并加上头部信息,比如需要nb = 112字节。
// (在 glibc/malloc/malloc.c 中的 _int_malloc)
static void*
_int_malloc(mstate av, size_t bytes)
{
size_t nb = request2size(bytes); // nb = 112
mchunkptr victim; // 这是我们要找的空闲块
// 1. 尝试 "Fast Bins" (针对极小且刚释放的块)
if (nb <= get_max_fast()) {
int idx = fastbin_index(nb); // 计算它属于哪个 fastbin
mfastbinptr *fb = &&fastbin (av, idx);
victim = *fb; // 拿到链表头
if (victim != 0) {
// 找到了!
*fb = victim->fd; // 从链表中移除 (fd = forward pointer)
// ... (一些检查) ...
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;; // 闪电般返回
}
}
// 2. Fast Bins 中没有,尝试 "Small Bins"
if (in_smallbin_range(nb)) {
idx = smallbin_index (nb);
bin = bin_at (av, idx);
victim = *b; // 拿到链表头
if ((victim = last (bin)) != bin) {
// 找到了!
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
}
// 3. Small Bins 也没有,事情开始变慢...
// 它会尝试合并 "Fast Bins" (malloc_consolidate),
// 然后去 "Large Bins" 找,
// 再去 "Unsorted Bin" (一个“垃圾回收”箱) 找...
// 4. 【关键】所有 Bins 都找遍了,还是没有!
// 我们必须向操作系统 "进货" 了。
// (在 _int_malloc 的非常后面)
victim = sysmalloc(nb, av); // <--- 在这里调用 sysmalloc!
if (victim != 0) {
// sysmalloc 成功从 OS 拿到了内存
// ... (可能需要从这块新内存中切一小块出来) ...
void *p = sysmalloc (nb, av);
if (p != NULL)
alloc_perturb (p, bytes);
return p;
}
}
_int_malloc的全部工作就是避免调用sysmalloc。- 它优先检查
fastbins、smallbins、unsorted_bin、largebins。 - 只有当所有“库存”都用完时,它才会调用
sysmalloc去“进货”。
sysmalloc是用户态和内核态的“边界”。它决定是扩展堆(brk)还是创建一个新的匿名映射(mmap)。
sbrk(bytes)和mmap(...)都是C库对系统调用的封装。现在,我们切换到内核态。
2. 内核态:brk 系统调用 (mm/mmap.c)
当glibc调用sbrk(SIZE)时,它最终会触发brk系统调用。
// (在 mm/mmap.c)
// SYSCALL_DEFINE1 是一个宏,它定义了一个系统调用
// "brk" 是系统调用名, "unsigned long, brk" 是参数
SYSCALL_DEFINE1(brk, unsigned long, brk_addr)
{
struct mm_struct *mm = current->mm; // 获取当前进程的内存描述符
unsigned long newbrk, oldbrk;
// ... (加锁:mmap_write_lock(mm)) ...
// 'mm->start_brk' 是堆的起始地址 (程序加载时固定)
// 'mm->brk' 是堆的 *当前* 结尾 (program break)
oldbrk = mm->brk;
min_brk = mm->start_brk;
if (brk_addr < min_brk)
goto out; // 错误:不能把堆缩到起始点之前
// 检查是否超过了资源限制 (RLIMIT_DATA)
if (check_data_rlimit(rlimit(RLIMIT_DATA), brk, mm->start_brk,
mm->end_data, mm->start_data))
goto out;
// 【核心】do_brk_flags 是真正干活的
// 它只负责处理 VMA (地契),不分配物理内存
if (do_brk_flags(&vmi, brkvma, oldbrk, newbrk - oldbrk, 0) < 0)
goto out;
if (newbrk == oldbrk)
goto out; // 地址没变,什么也不做
mm->brk = newbrk; // 更新进程的 "program break" 记录
out:
// ... (解锁) ...
return origbrk; // 返回新的 'program break' 地址
}
// (也在 mm/mmap.c)
static int do_brk_flags(struct vma_iterator *vmi, struct vm_area_struct *vma,
unsigned long addr, unsigned long len, unsigned long flags)
{
struct mm_struct *mm = current->mm;
if (vma) {
// 我们已经有了一个 [heap] VMA,现在只是要扩展它
// ... (检查新旧 VMA 是否可以合并) ...
// 【最关键的一行】
// 内核只是简单地更新了 VMA 的结束边界!
// 没有一行业代码是去分配物理内存(RAM)的!
vma->vm_end = addr + len;
}
// 这是第一次调用 brk,我们需要创建 [heap] VMA
vma = vm_area_alloc(mm);
// ... (设置 vma->vm_start, vma->vm_end, vma->vm_flags) ...
vm_flags_init(vma, flags);
vma->vm_page_prot = vm_get_page_prot(flags);
vma_start_write(vma);
if (vma_iter_store_gfp(vmi, vma, GFP_KERNEL))
goto mas_store_fail;
.....
}
brk系统调用极快。它所做的只是在内核中修改一个vm_area_struct(地契)的vm_end值。它承诺了这块虚拟地址是合法的,但没有分配一字节的物理RAM。
3. 内核态:mmap 系统调用 (mm/mmap.c)
当glibc调用mmap(...)时,它触发mmap系统调用(现代内核通常是mmap_pgoff)。
// (在 mm/mmap.c)
// (SYSCALL_DEFINE6 定义了6个参数的系统调用)
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)
{
return ksys_mmap_pgoff(addr, len, prot, flags, fd, pgoff);
}
中间经过 ksys_mmap_pgoff->vm_mmap_pgoff->do_mmap
// (也在 mm/mmap.c)
unsigned long do_mmap(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flags, ...)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma;
// 1. 找到一个空闲的虚拟地址范围
// (如果 addr = 0,内核会帮你找)
addr = get_unmapped_area(file, addr, len, pgoff, flags);
if (IS_ERR_VALUE(addr))
return addr; // -ENOMEM 或其他错误
// 延迟实际物理页分配到 page fault
addr = mmap_region(file, addr, len, vm_flags, pgoff, uf);
//.如果用户指定了 MAP_POPULATE,预分配
if (!IS_ERR_VALUE(addr) &&
((vm_flags & VM_LOCKED) ||
(flags & (MAP_POPULATE | MAP_NONBLOCK)) == MAP_POPULATE))
*populate = len;
// 返回虚拟地址
return addr;
}
和brk一样,mmap也只是在“画饼”。它创建了一个vm_area_struct(地契),将其插入到进程的地址空间,然后就返回了。
4. 内核态:Page Fault(缺页中断) (arch/x86/mm/fault.c)
这是魔法发生的地方。当C++代码执行*ptr = 'H'时,CPU硬件触发了一个#PF中断。
// (在 arch/x86/mm/fault.c)
// 'do_page_fault' 是内核的中断处理函数
// 'regs' 是CPU寄存器
void do_user_addr_fault(struct pt_regs *regs,
unsigned long error_code,
unsigned long address)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma;
//【检查地契】在进程的 VMA 列表 (红黑树) 中查找
// 这个 'address' 是否属于一个合法的 VMA?
vma = find_vma(mm, address);
if (unlikely(!vma)) {
bad_area(regs, error_code, address);
return;
}
if (likely(vma->vm_start <= address))
goto good_area;
if (unlikely(!(vma->vm_flags & VM_GROWSDOWN))) {
bad_area(regs, error_code, address);
return;
}
if (unlikely(expand_stack(vma, address))) {
bad_area(regs, error_code, address);
//
// 恭喜! 这不是一次 "非法" 访问,
// 只是因为内核“偷懒”还没分配物理页。
// 我们称之为 "Demand Paging" (按需调页)
// 'handle_mm_fault' 是通用的、与架构无关的处理函数
fault = handle_mm_fault(vma, address, flags, regs);
if (fault & VM_FAULT_COMPLETED)
return;
// ... (处理成功,返回用户态,重新执行 'mov' 指令) ...
return;
bad_area:
// 这里就是 SEGFAULT (SIGSEGV) 的诞生地
// ... (force_sig_info(SIGSEGV, ...)) ...
}
// (在 kernel/mm/memory.c)
// mm/memory.c
vm_fault_t handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags, struct pt_regs *regs)
{
struct vm_fault vmf = {
.vma = vma,
.address = address,
.flags = flags,
};
.....
return handle_pte_fault(&vmf);
}
static vm_fault_t handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
if (unlikely(pmd_none(*vmf->pmd))) {
.....
if (!vmf->pte) {
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf);
else
return do_fault(vmf);
}
....
}
// (在 kernel/mm/memory.c)
static int do_anonymous_page(struct vm_area_struct *vma, ...)
{
// 1. 【物理分配】
// 这是我们第一次看到物理内存分配!
// 'alloc_page_vma' 会调用 "伙伴算法" (Buddy Allocator)
// __GFP_ZERO 标志告诉它 "请给我一个已经清零的物理页"
struct page *page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
if (!page)
return oom; // 内核 OOM!
// 2. 【建立映射】
// 创建一个新的 Page Table Entry (PTE)
// 这个 PTE 将 虚拟地址 链接到 物理页 (page)
__SetPageUptodate(page);
entry = mk_pte(page, vma->vm_page_prot);
entry = pte_sw_mkyoung(entry);
// 3. 【写入页表】
// 将这个 PTE 原子地写入到进程的页表中
set_pte_at(vma->vm_mm, address, ptep, entry);
// 4. 更新 RSS 计数器 (你 Pmap 看到的)
// ...
// 成功!
}
*ptr = 'H'触发do_page_fault。- 内核通过
find_vma检查“地契”,确认访问合法。 handle_mm_fault发现页表项(PTE)是空的。do_anonymous_page被调用,它执行两个关键操作:alloc_page_vma(伙伴算法) 分配一个 4KB 物理页框。set_pte_at将这个物理页框的地址写入页表。
- 中断处理函数返回,CPU重新执行
*ptr = 'H'。 - 这一次,MMU查找页表,找到了有效的PTE,成功将虚拟地址翻译为物理地址,写入完成。
这就是从malloc(100)到*ptr = 'H',再到RAM中一个特定晶体管状态被改变的完整旅程。
小结
现在,当你再遇到C++内存分配的性能问题时,你的思路就清晰了:
-
问题:多线程卡顿(锁竞争)。
- 原因:
ptmalloc2的Arena锁在高度并发下表现不佳。 - 解决: 换一个分配器。通过
LD_PRELOAD环境变量,将你的程序链接到libjemalloc.so或libtcmalloc.so。这通常能带来立竿见影的性能提升,因为它们有更激进的“每线程缓存”。
- 原因:
-
问题:服务启动时,或访问大数据时P99延迟高(Page Faults)。
- 原因:
malloc后第一次访问触发了大量的“缺页中断”。 - 解决:
- 预热(Warm-up): 在
malloc后,立刻用memset(或在单独的初始化线程中)把内存“摸”一遍,提前支付Page Fault的开销。 madvise: 使用madvise(ptr, size, MADV_WILLNEED)来“建议”内核预先把页面换入。MAP_POPULATE: 如果你是直接用mmap,可以加MAP_POPULATE标志,让内核在mmap返回前就分配好物理内存(不再懒惰)。
- 预热(Warm-up): 在
- 原因:
-
问题:程序内存只增不减(碎片)。
- 原因:
- 小对象分配导致
brk管理的堆无法收缩。 ptmalloc2为了性能,会“囤积”free的内存,不还给OS。
- 小对象分配导致
- 解决:
- 对象池(Object Pools): C++开发者的利器。对于频繁创建和销毁的 同尺寸 对象(如
Bullet、Packet),自己实现一个对象池。一次malloc一大块,然后用链表管理空闲对象。这完全避开了malloc的内部锁和复杂逻辑。 mmap: 对那些“大且短命”的分配(如临时缓冲区),考虑绕过malloc,直接使用mmap和munmap。
- 对象池(Object Pools): C++开发者的利器。对于频繁创建和销毁的 同尺寸 对象(如
- 原因:
-
问题:算法慢(TLB/Cache失效)。
- 原因:
malloc返回的内存页在物理上可能是零散的。当你的数据结构(如链表、树)在内存中“跳跃”访问时,会不断导致TLB Miss(地址翻译缓存失效),CPU需要花费几百个周期去“遍历页表”。 - 解决:
- 数据导向设计(DOD): 尽量使用连续内存,比如用
std::vector代替std::list。 - 自定义分配器(C++ Allocator): 为你的
std::map或std::list提供一个自定义分配器,它从一个连续的内存池(Slab)中分配节点,保证高度的“内存局部性”。 - 巨页(Huge Pages): 对于GB级的超大内存(如数据库缓存),使用2MB或1GB的“巨页”(Huge Pages)来代替4KB的页。这能极大减少TLB条目,大幅提升性能。
- 数据导向设计(DOD): 尽量使用连续内存,比如用
- 原因:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号