coredump的那些事:04.多线程程序的调试
前言
在之前的文章中,我们依次讲解了
- coredump的配置与生成
- gdb使用coredump进行调试
- DWARF调试信息的生成与使用
但是之前的程序都是简单的单线程程序,但是实际中我们面临的更多的是多线程下的崩溃问题,相比于单线程程序
多线程因为以下原因更加复杂:
- 程序在不同线程中同时执行
- 崩溃的线程可能与另一个线程的状态相关
- 竞态问题导致的问题在调试中难以复现
因此这篇文章我们就来进入更复杂主题:多线程程序的调试
基础知识
linux线程模型
- linux中的线程不是特殊的对象,线程与进程都是
task_struct这个结构 - 区别在于线程独占调用堆栈与寄存器,但是与父进程共享地址空间,文件描述符等资源
coredump与线程
- 某个线程的崩溃会导致整个进程coreudmp
- coredump发生时,内核会遍历整个task_struct,将每个线程的寄存器,上下文与栈信息都写入文件中
当我们在 gdb 中使用 info threads,看到的每一个线程,背后就是内核在 coredump 里写下的 task_struct → 内核栈 + 用户栈 的信息
gdb多线程下的常用命令
查看线程列表
info threads
列出当前进程(或 core 文件)里的所有线程
gdb 会显示每个线程的 ID、状态、当前执行的函数位置
切换到指定线程
thread N
切换到第 N 个线程(注意:gdb 的线程号与系统 ps -L 看到的 LWP 不同,但可以通过 info threads 映射)
打印所有线程的堆栈
thread apply all bt
对所有线程执行 bt(backtrace),快速查看全局状态
在排查死锁和卡住的情况时非常有用
只对部分线程操作
thread apply 3 5 bt
只对线程 3 和 5 打印堆栈
查看某线程的局部变量
thread 3
bt
frame 2
info locals
条件断点
break <function> if <condition>
在调试竞态或复杂多线程问题时,条件断点非常有用
跟踪线程切换
set print thread-events on
程序运行时,gdb 会提示线程的创建/销毁情况
注意线程号与 LWP 映射:
gdb 内部编号与系统 LWP 不同。
可以通过 info threads 查看 LWP,再用 ps -L -p <PID> 对照。
多线程问题调试示例
这一章节我们通过3个经典的问题去试验下多线程下gdb的使用
崩溃问题
流程演示
//crash_demo.cpp
#include <iostream>
#include <thread>
#include <chrono>
void thread_func_normal()
{
int counter = 0;
while (true) {
std::cout << "[Thread A] counter = " << counter++ << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
}
}
void thread_func_crash() {
std::this_thread::sleep_for(std::chrono::seconds(2));
std::cout << "[Thread B] about to crash..." << std::endl;
int* p = nullptr;
*p = 42; // 故意制造段错误 (SIGSEGV)
}
int main() {
std::thread t1(thread_func_normal);
std::thread t2(thread_func_crash);
t1.join();
t2.join();
return 0;
}
使用如下命令去产生coredump文件
g++ -g -O0 -pthread -o crash_demo crash_demo.cpp
ulimit -c unlimited
echo "/tmp/%e.core" | sudo tee /proc/sys/kernel/core_pattern
./crash_demo
gdb ./crash_demo core
此时的页面可能如下所示,gdb调试器会直接进入崩溃的线程,可以使用print命令打印变量的值

print p # 打印变量的值

info locals # 查看所有的局部变量

查看所有的局部变量就可以直接发现是局部变量被修改成空指针了,然后可以去继续调查局部变量为什么修改的原因,这个时候就可以去看代码了,定位到这里基本就可以辅助去调查问题了
过程小结
- 定位崩溃时的堆栈
gdb调试器会自动停在触发崩溃信号的线程上,此时就能看到崩溃现场
bt
- 查看局部变量和寄存器
info locals
print p
如果是空指针或者野指针,就可以确定原因了
如果是越界问题,顺便打印上下文
- 查看其他线程的状态
有时候崩溃的线程只是受害者, 其实是别的线程修改了相关的内存
thread apply all bt
- 配合其他工具使用
如果怀疑内存被破坏,可以配合工具Valgrind memcheck等工具。
死锁问题
当一段程序没有崩溃,但是卡住的时候,大概是死锁问题。
流程演示
//deadlock_demo.cpp
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
std::mutex mtx1;
std::mutex mtx2;
void thread_func_A()
{
std::lock_guard<std::mutex> lockA(mtx1);
std::this_thread::sleep_for(std::chrono::seconds(1));
std::lock_guard<std::mutex> lockB(mtx2); // 死锁
std::cout << "Thread A acquired both locks\n";
}
void thread_func_B()
{
std::lock_guard<std::mutex> lockB(mtx2);
std::this_thread::sleep_for(std::chrono::seconds(1));
std::lock_guard<std::mutex> lockA(mtx1); // 死锁
std::cout << "Thread B acquired both locks\n";
}
int main()
{
std::thread t1(thread_func_A);
std::thread t2(thread_func_B);
t1.join();
t2.join();
return 0;
}
g++ -g -O0 -pthread -o deadlock_demo deadlock_demo.cpp
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope # 允许系统去通过gdb接管进程
./deadlock_demo # 程序卡住
gdb ./deadlock_demo <PID> # pid 可以通过 ps -ef | grep deadlock_demo 命令查询
此时进入gdb展示如下内容;
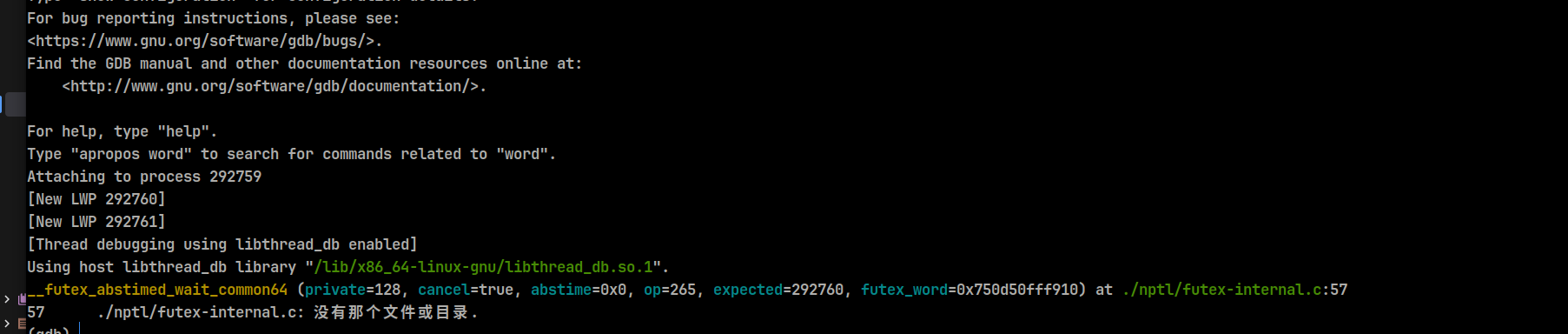
展示此时的所有线程的堆栈:
thread apply all bt
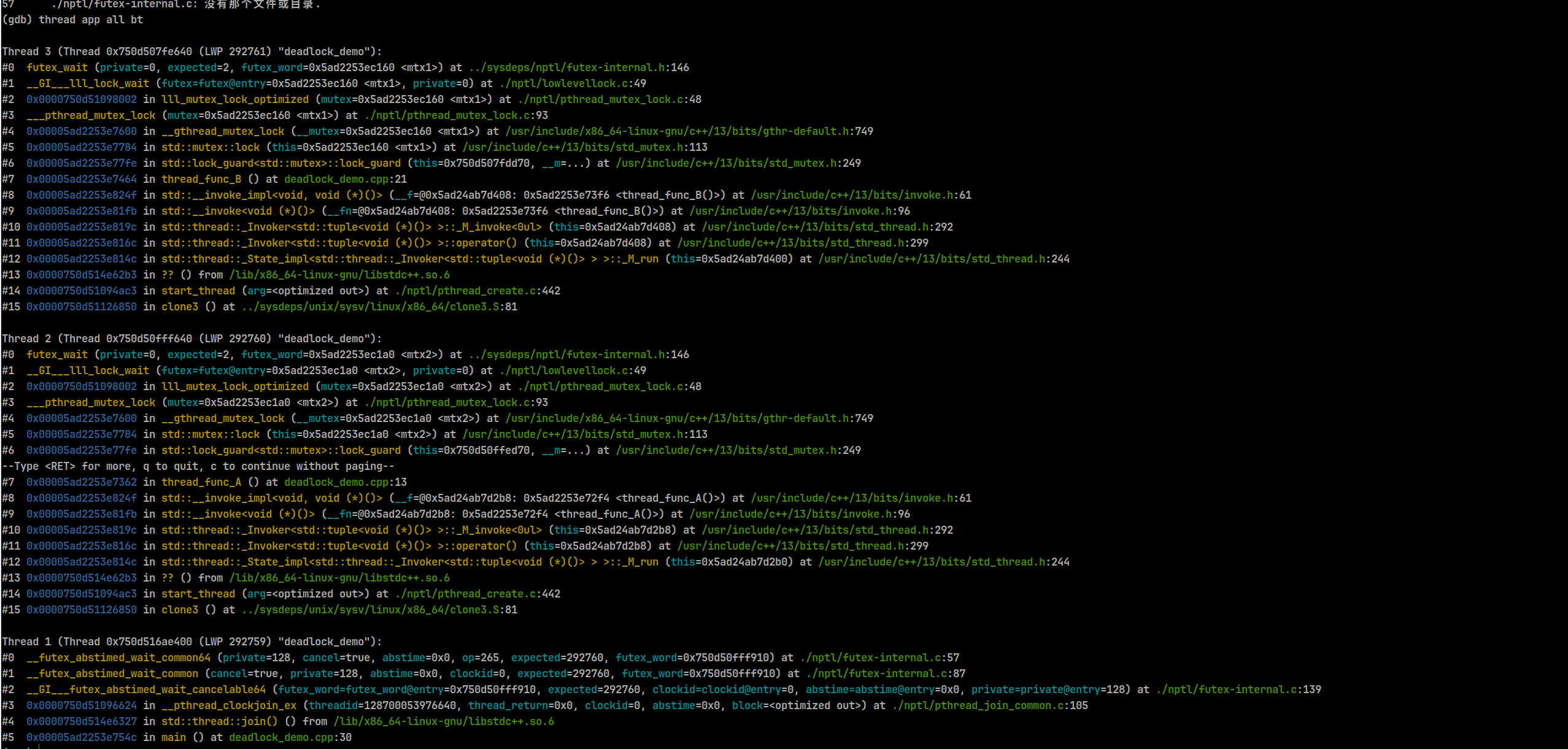
重点看futex_wait系统调用,发现线程3在 thread_func_B 中一直在等待 mtx1,线程2在 thread_func_A 中一直等待 mtx2;
确定之后就查看是怎么加锁的,分析逻辑
过程小结
- 首先利用
gdb -p <PID>attach到进程 - 然后打印所有线程的堆栈
thread apply all bt
如果发现有多个线程都卡在 futex_wait,说明都在等锁
- 逐一分析栈帧
查看每个线程持有的锁和等待的锁 - 判断是否形成了循环等待
- 确认死锁
如果有环路并且相关的线程都卡在futex_wait,就都是死锁
小trick
- 跟踪
futex系统调用,因为多线程的加锁/等待会进入此系统命令
catch syscall futex
continue
- 查看 mutex owner
(gdb) p ((pthread_mutex_t*)&mtx1)->__data.__owner
竞态问题
当结果一会准确一会错误的时候,很有可能是竞态问题
流程演示
// race_demo.cpp
#include <iostream>
#include <thread>
int global_counter = 0;
void thread_func()
{
for (int i = 0; i < 1'000'000; i++) {
global_counter++; // 无锁写入 → 数据竞争
}
}
int main() {
std::thread t1(thread_func);
std::thread t2(thread_func);
t1.join();
t2.join();
std::cout << "Final counter = " << global_counter << std::endl;
return 0;
}
实际上竞态问题使用gdb调试不是一个很好的选择,可以使用更好的工具,比如 Valgrind和 TSAN,这里使用 valgrind演示
g++ -g -O0 -pthread -o race_demo race_demo.cpp
valgrind --tool=helgrind ./race_demo
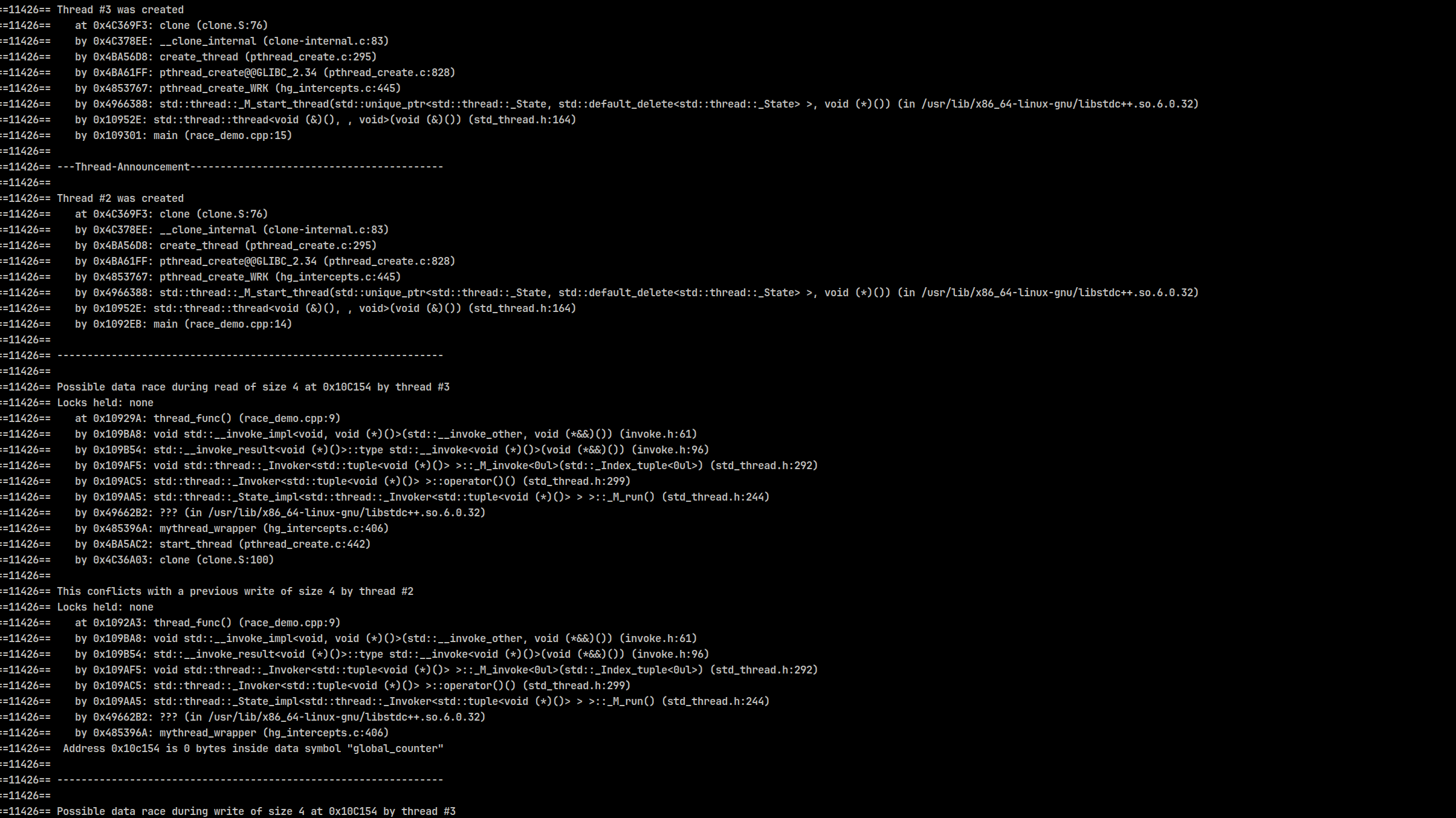
注意查找 Locks held: none 字样,找到可能的问题所在
自动化与工程化技巧
收集线程栈
gdb -p <PID> -batch -ex "set pagination off" -ex "thread apply all bt full" > stacks.txt
线程命名
在代码里加:
pthread_setname_np(pthread_self(), "worker-1");
这个方法只在linux上有效,并且是拓展不是标准
总结
多线程的调试比单线程复杂的多,典型问题包括:
-
崩溃:gdb 自动停在故障线程,重点分析指针与内存。
-
死锁:通过 thread apply all bt 和 futex 等系统调用判断循环等待。
-
竞态:gdb 不擅长,推荐使用 Helgrind / TSAN 等工具检测。
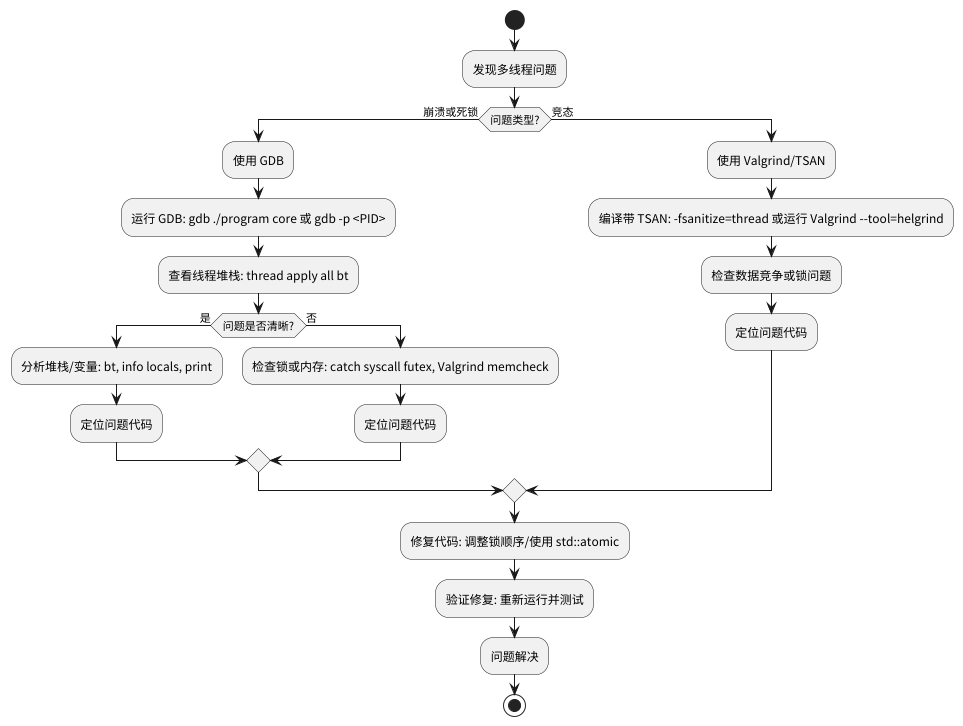
一个好的流程是:
- 分析出问题的大致类型
- 先利用gdb快速定位问题
- 然后使用专业工具(Valgrind, TSAN)去验证补充信息
![debug_flow]()
个人认为最好的手段: - 给出充分的时间进行设计,从线程模型和锁设计层面反思,避免出现此类问题(逃)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号