spdlog源码阅读:05.spdlog中的设计模式
前言:从功能到架构,探寻 spdlog 的设计之美
在本系列之前的文章中,我们深入剖析了 spdlog 的异步机制、核心组件,并且尝试拓展实现一个压缩sink,还尝试进行了性能优化实践。
我们理解了 spdlog 在功能和性能上“做了什么”以及“怎么做的”。现在,我们跳出具体实现的细节,从设计模式的角度重新看一下这个库,
深入探讨 spdlog 是如何巧妙地运用策略模式 (Strategy)、组合模式 (Composite)、工厂模式 (Factory)、以及单例模式 (Singleton),来构建其灵活、高效且用户友好的体系的。
1. 策略模式 (Strategy Pattern):解耦日志行为的核心
策略模式的核心思想是:定义一系列算法,将每一个算法封装起来,并使它们可以相互替换。
为什么使用策略模式?
对于一个日志库而言,其核心任务是记录日志,但日志的“行为”是多变的:
- 日志消息应该以什么样的格式 (Format)呈现?
- 日志消息应该被发送到哪个目的地 (Destination)?
spdlog 通过策略模式,将 logger 的核心记录逻辑与具体的格式化策略和输出策略完全解耦。
在 spdlog 中是如何实现的?
spdlog 中有两处经典的策略模式应用:Formatter 对 Sink 的策略 和 Sink 对 Logger 的策略。
a) Formatter:定义日志的“格式化策略”
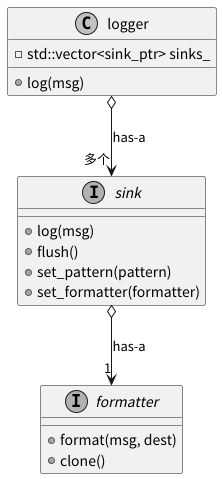
spdlog 定义了一个 formatter 接口,所有具体的格式化器都实现这个接口。sink 对象则拥有 (has-a) 一个 formatter 策略。
// spdlog/formatter.h
class formatter {
public:
virtual ~formatter() = default;
virtual void format(const details::log_msg &msg, memory_buf_t &dest) = 0;
virtual std::unique_ptr<formatter> clone() const = 0;
};
每个 sink 对象都持有一个 formatter。当 sink 需要记录日志时,它不关心如何格式化,而是把这个任务委托给它持有的 formatter 策略对象。
// spdlog/sinks/base_sink.h
template <typename Mutex>
class SPDLOG_API base_sink : public sink {
public:
// ...
void log(const details::log_msg &msg) final override
{
std::lock_guard<Mutex> lock(mutex_);
sink_it_(formatted); // sink_it_ 是子类实现的具体输出逻辑 , 实际调用 formatter_ 的 format 方法,执行格式化策略
}
protected:
// 持有一个 formatter 策略
std::unique_ptr<spdlog::formatter> formatter_;
Mutex mutex_;
// ...
};
b) Sink:定义日志的“输出策略”
同样地,spdlog 定义了一个 sink 接口,代表不同的输出目的地策略。logger 类则拥有 (has-a) 一个或多个 sink 策略。
// spdlog/sinks/sink.h
class sink {
public:
virtual ~sink() = default;
virtual void log(const details::log_msg &msg) = 0;
virtual void flush() = 0;
virtual void set_pattern(const std::string &pattern) = 0;
virtual void set_formatter(std::unique_ptr<spdlog::formatter> sink_formatter) = 0;
// ...
};
logger 类中持有一个 sink 的集合。当用户调用 logger->info(...) 时,logger 将日志消息打包后,委托给它持有的所有 sink 策略对象去处理。
class SPDLOG_API logger {
public:
......
protected:
std::string name_;
std::vector<sink_ptr> sinks_;
spdlog::level_t level_{level::info};
spdlog::level_t flush_level_{level::off};
err_handler custom_err_handler_{nullptr};
details::backtracer tracer_;
}
下面是logger,sink和formatter三个类的类图:
这样做有什么好处?
- 高度解耦: logger、sink、formatter 三者职责清晰,logger 不关心输出细节,sink 不关心格式化细节。
- 极强的扩展性: 用户可以轻松创建自己的 sink(如写入数据库)和 formatter(如输出为 JSON),并与现有 logger 无缝集成。
- 灵活性: 可以在运行时动态地为 sink 更换 formatter,改变日志格式。
2. 组合模式 (Composite Pattern):统一处理多个目的地
组合模式的核心思想是:将对象组合成树形结构以表示“部分-整体”的层次结构,使得用户对单个对象和组合对象的使用具有一致性。
为什么使用组合模式?
我们常常希望一条日志能同时输出到多个地方,比如控制台和文件。组合模式使得 logger 在处理这种情况时无需区分是在跟一个 sink 还是多个 sink 打交道。
在 spdlog 中是如何实现的?
如上节代码所示,spdlog 的 logger 类中持有一个 std::vector<sink_ptr> 成员 sinks_。当记录日志时,logger::sink_it_() 方法会简单地遍历这个 vector,并对其中的每一个 sink 调用 log() 方法。
这里的实现完美地体现了组合模式的核心思想——统一对待单个对象和对象集合。对于 logger(客户端)来说,它处理 sinks_ 的逻辑是完全一致的,无论这个 vector 中只有一个 sink 还是有十个。
spdlog 还提供了一个更经典的组合模式实现——dist_sink,它本身是一个 sink,内部也包含一个 sink 的集合,其 log() 方法就是遍历并调用内部所有 sink 的 log()。
这样做有什么好处?
- 简化客户端代码: logger 的实现变得非常简单,一个循环就解决了向所有目的地输出的问题。
- 灵活性: 用户可以自由地向 logger 的 sinks_ 列表添加或移除 sink,动态地改变日志的输出组合。
3. 工厂模式 (Factory Pattern):简化对象的创建过程
在 spdlog 中,工厂模式更多的是以工厂函数 (Factory Function) 结合 模板化的工厂结构体 (Factory Struct) 的形式体现,它提供了一个集中的、简化的方式来创建复杂的、预配置好的 logger 对象。
为什么使用工厂模式?
手动创建一个功能完备的 logger 对象比较繁琐。尤其是异步的logger,还需要去手动创建线程池和设置队列大小。工厂模式将这些复杂的创建逻辑封装起来,向用户提供一个简单、易用的创建接口。
在 spdlog 中是如何实现的?
spdlog 提供了一系列工厂函数,如 basic_logger_mt。这些函数巧妙地利用模板参数来接收一个“工厂”类型,这个工厂类型决定了是创建同步 logger还是异步 logger。
// 一个异步文件日志的创建示例
void async_example()
{
// 使用 async_factory 作为模板参数,创建异步 logger
auto async_file = spdlog::basic_logger_mt<spdlog::async_factory>("async_file_logger", "logs/async_log.txt");
}
// 这是同步工厂的实现
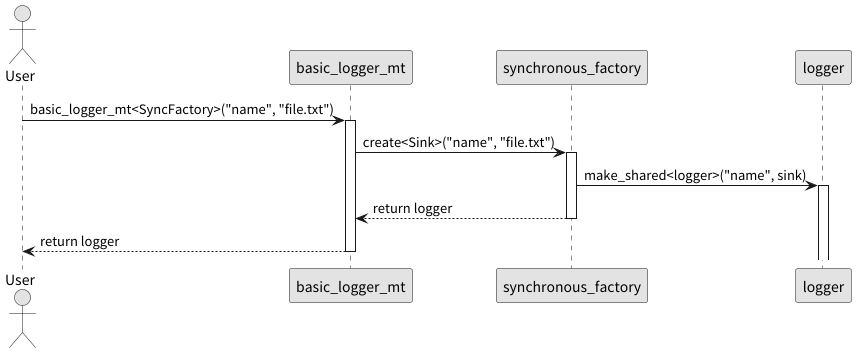
struct synchronous_factory {
template <typename Sink, typename... SinkArgs>
static std::shared_ptr<spdlog::logger> create(std::string logger_name, SinkArgs &&...args) {
auto sink = std::make_shared<Sink>(std::forward<SinkArgs>(args)...);
auto new_logger = std::make_shared<spdlog::logger>(std::move(logger_name), std::move(sink));
details::registry::instance().initialize_logger(new_logger);
return new_logger;
}
};
// 这是异步工厂的实现
template<async_overflow_policy OverflowPolicy = async_overflow_policy::block>
struct async_factory_impl
{
template<typename Sink, typename... SinkArgs>
static std::shared_ptr<async_logger> create(std::string logger_name, SinkArgs &&... args)
{
// ... (省略创建和获取全局线程池的逻辑) ...
auto sink = std::make_shared<Sink>(std::forward<SinkArgs>(args)...);
auto new_logger = std::make_shared<async_logger>(std::move(logger_name), std::move(sink),
std::move(tp), OverflowPolicy);
details::registry::instance().initialize_logger(new_logger);
return new_logger;
}
};
using async_factory = async_factory_impl<async_overflow_policy::block>;
.......
最终的工厂函数 basic_logger_mt 接收这个工厂类型作为模板参数,并调用其 create 方法。
template <typename Factory = spdlog::synchronous_factory>
inline std::shared_ptr<logger> basic_logger_mt(const std::string &logger_name,
const filename_t &filename,
bool truncate = false,
const file_event_handlers &event_handlers = {})
{
// 调用传入的 Factory 的静态 create 方法来创建 logger
return Factory::template create<sinks::basic_file_sink_mt>(logger_name, filename, truncate,event_handlers);
}
下面是工厂调用的时序图:
这样做有什么好处?
- 极大地简化了用户的使用: 用户可以用一行代码创建一个功能完备的同步或异步 logger。
- 高度灵活与解耦: 通过模板参数注入不同的工厂实现,使得创建不同类型 logger 的逻辑得以复用和解耦。
- 保证了最佳实践: 工厂函数创建的 logger 通常是经过预配置的、符合最佳实践的实例(例如,_mt 后缀的都是线程安全的)。
通过这种模板方法和手段实现工厂也是C++实现工厂模式的一个优点,避免了重复创建无意义的工厂接口类,而是通过模板去实现静态多态
4. 单例模式 (Singleton Pattern):提供全局便捷访问
单例模式确保一个类只有一个实例,并提供一个全局访问点。
为什么使用单例模式?
对于许多简单的应用场景,用户不希望手动创建和管理 logger 实例,而是希望有一个像 printf 一样方便的全局日志函数。spdlog 通过单例模式提供了一个全局的 logger 注册表 (registry) 和一个默认的 logger。
在 spdlog 中是如何实现的?
spdlog 提供了全局的日志函数,如 spdlog::info, spdlog::error 等。
#include "spdlog/spdlog.h"
int main()
{
// 直接使用全局函数进行日志记录
spdlog::info("Welcome to spdlog!");
spdlog::error("Some error message with arg: {}", 1);
}
这些全局函数内部都通过调用 default_logger_raw() 来获取一个默认的 logger 实例。
template <typename... Args>
inline void debug(format_string_t<Args...> fmt, Args &&...args) {
// 调用默认 logger 的 debug 方法
default_logger_raw()->debug(fmt, std::forward<Args>(args)...);
}
而这个默认的 logger 由 spdlog::registry 类管理。registry 类自身就是通过单例模式实现的,它使用 C++11 之后线程安全的“Meyers' Singleton”模式。
// spdlog/details/registry.h
class SPDLOG_API registry {
public:
// ...
// 提供一个静态方法 instance() 来获取唯一的实例
static registry &instance();
std::shared_ptr<logger> default_logger();
void set_default_logger(std::shared_ptr<logger> new_default_logger);
void register_logger(std::shared_ptr<logger> new_logger);
// ...
private:
registry(); // 构造函数私有化
~registry();
std::unordered_map<std::string, std::shared_ptr<logger>> loggers_;
std::shared_ptr<logger> default_logger_;
// ...
};
// spdlog/details/registry.cpp
SPDLOG_INLINE registry ®istry::instance() {
// C++11 保证了静态局部变量的初始化是线程安全的
static registry s_instance;
return s_instance;
}
这样做有什么好处?
- 便捷性: 为用户提供了极其方便的全局日志接口,大大降低了入门和日常使用的复杂度。
- 全局注册与管理: 提供了一个中心化的位置来注册、获取和管理所有命名的 logger,方便统一配置。
- 平衡了便利与灵活: spdlog 在提供单例便利的同时,也允许用户创建和管理自己的 logger 实例,不与全局注册表绑定。这种设计非常出色,兼顾了易用性和灵活性,避免了单例模式在大型项目中可能带来的强耦合和测试困难问题。
结论
通过对 spdlog 中设计模式的剖析,我们不难发现,这些经典模式并非孤立存在,而是相互协作,共同构成了 spdlog 优雅的架构:
- 策略模式 提供了核心的灵活性,使得日志的格式化和输出行为可以被轻松替换和扩展。
- 组合模式 使得 logger 能够统一、透明地处理单个或多个输出目的地,简化了客户端逻辑。
- 工厂模式 (结合模板) 则封装了复杂的对象创建过程,为用户提供了简洁、易用的入口。
- 单例模式 为简单的使用场景提供了极大的便利,并提供了一个全局的管理中心。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号