spdlog源码阅读:06.spdlog性能优化,thread_local SPSC 队列与最小堆合并排序实践
探索 spdlog 异步日志性能优化:thread_local SPSC 队列与最小堆合并排序实践
引言
在本系列的前四篇文章中,我们对 spdlog 的异步机制、文件 Sink、自定义 Sink 扩展以及核心格式化引擎 pattern_formatter 进行了深入剖析。通过这些分析,我们对 spdlog 的设计哲学和实现细节有了全面的理解。spdlog 以其丰富的功能和相对不错的性能得到了广泛应用,但其默认的异步日志模型(基于共享的 MPMC 阻塞队列)在高并发、多生产者场景下,队列的锁竞争可能成为性能瓶颈。
受到 nanolog 等高性能日志库关于利用 thread_local 减少前端竞争思想的启发,本文将详细阐述一种对 spdlog 异步日志机制的改进方案。核心思路是将原有的“多生产者-单消费者 (MPSC)”模型,演进为“多个独立的单生产者-单消费者 (SPSC) 模型集合 + 后端统一合并处理”的架构,旨在显著降低生产者线程间的锁竞争,并利用最小堆保证全局日志的时间顺序,以期获得性能上的提升。
通过本文,你将了解到:
- 该改进方案的设计思想与架构。
- 如何利用
thread_local为每个生产者线程创建独立的 SPSC 队列。 - 后端消费者线程如何发现、管理这些动态创建的队列。
- 如何通过最小堆(优先级队列)对来自不同 SPSC 队列的日志消息进行时间戳排序,以保证全局顺序。
- 关键组件(如
details::thread_pool_local、spsc_blocking_queue)的设计与核心实现。 - 以及笔者通过实验验证此方案相较于原版
spdlog带来的性能提升。
注:本文的改进方案基于对 spdlog v1.15.1 的理解和修改实践。
核心改进思路:从 MPMC 到 “thread_local SPSC 集合 + 最小堆合并”
spdlog 默认的异步模型中,所有生产者(业务线程)共享一个中央的 mpmc_blocking_queue。在高并发写入时,对该队列的互斥锁(std::mutex)的竞争会成为影响前端(业务线程)性能的瓶颈。
我们的改进思路旨在通过以下方式优化这一模型:
- 前端无锁化 (或极低锁): 为每一个首次进行日志记录的生产者线程,通过
thread_local动态创建一个专属于该线程的、轻量级的 SPSC (Single-Producer, Single-Consumer) 阻塞队列。日志消息直接写入这个线程局部队列。由于每个队列只有一个生产者(即线程自身),写入操作可以降低锁的开销。 - 后端集中处理与排序: 单个后台消费者线程负责从所有这些
thread_localSPSC 队列中收集日志消息。 - 保证全局顺序: 收集到的日志消息可能来自不同的生产者线程,其时间戳可能是交错的。为了保证最终输出的日志具有全局严格的时间顺序,消费者线程在将消息送往 Sink 之前,会使用一个基于时间戳的最小堆(优先级队列)对这些消息进行排序。
整体架构从原先的:
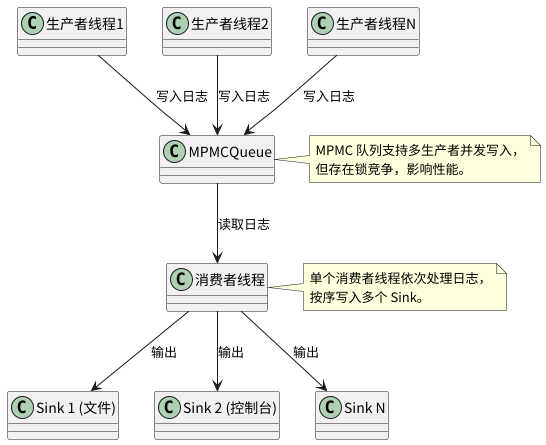
演变为:
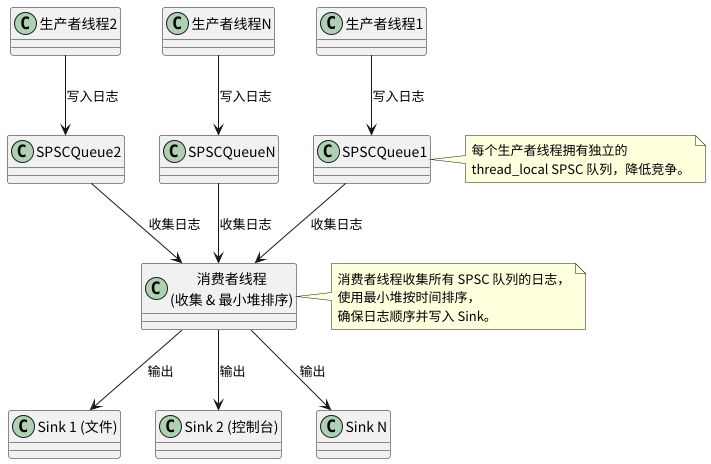
关键组件设计与实现
为了实现上述思路,我们需要对 spdlog 的核心异步组件 details::thread_pool 进行改造,并引入新的队列类型。我们将改造后的线程池称为 details::thread_pool_local,新的 logger 实现称为 async_logger_local。
1. thread_local SPSC 队列的创建与管理
thread_local q_ptr_local_: 在details::thread_pool_local中,我们定义一个static thread_local的指向 SPSC 队列的智能指针。
using item_type = async_msg_local;
using q_type = details::spsc_blocking_queue<item_type>;
using q_type_ptr = std::shared_ptr<q_type>;
static thread_local q_type_ptr q_ptr_local_;
- 按需创建: 当一个生产者线程首次调用日志接口(如
async_logger_local::sink_it_内部会调用到thread_pool_local::post_async_msg_)时,会检查q_ptr_local_是否为空。如果为空,表示该线程尚未拥有自己的 SPSC 队列。- 此时,需要创建一个新的 SPSC 队列实例(
std::make_shared<q_type>(queue_capacity))。 - 这个新创建的队列指针不仅赋值给
q_ptr_local_,还需要注册到一个全局的、消费者线程可见的队列池中,例如q_ptrs_front_(一个std::vector<q_type_ptr>,需要用锁保护其访问)。
- 此时,需要创建一个新的 SPSC 队列实例(
- 前端写入: 生产者线程后续的日志消息都将直接写入其
q_ptr_local_指向的线程局部 SPSC 队列。
if (q_ptr_local_ == nullptr)
{
std::unique_lock<std::recursive_mutex> lock(que_mutex_); // que_mutex_ 保护 q_ptrs_front_
q_ptr_local_ = std::make_shared<q_type>(INITIAL_QUEUE_CAPACITY); // q_type 是新的SPSC队列类型
q_ptrs_front_.push_back(q_ptr_local_); // 注册到全局队列池
}
// ... 将消息写入 q_ptr_local_ ...
2. spsc_blocking_queue 的设计
为了配合上述模型,需要一个新的队列 spsc_blocking_queue(或类似名称)。
- 生产者写入 (
enqueue):- 由于是单生产者,写入端可以进行高度优化。
- 当队列满时,行为由
async_overflow_policy_local控制,例如阻塞生产者 (block),或者丢弃消息(overrun_oldest或discard_new)。
void enqueue(T &&item)
{
std::unique_lock<std::mutex> lock(queue_mutex_);
pop_cv_.wait(lock, [this] { return !this->q_.full(); });
q_.push_back(std::move(item));
}
- 消费者读取 (
dequeue):- 由于是单消费者(特指从这个特定 SPSC 队列实例读取的消费者,即我们的后端主消费者线程),读取端也可以优化。
- 关键特性是支持非阻塞读取。当队列为空时,它应该立即返回一个表示“无数据”的状态,而不是阻塞消费者。这是因为后端消费者需要轮询多个这样的 SPSC 队列。
bool dequeue(T &popped_item)
{
{
std::unique_lock<std::mutex> lock(queue_mutex_);
if (q_.empty())
return false;
popped_item = std::move(q_.front());
q_.pop_front();
}
pop_cv_.notify_one();
return true;
}
3. 后端消费者 (thread_pool_local::worker_loop_) 的工作流程
后端消费者线程(在 thread_pool_local 中通常只有一个)的工作循环 worker_loop_ 内部调用 process_msg_,其核心逻辑如下:
- 发现并接管新的 SPSC 队列:
- 定期检查全局的“前端队列池”
q_ptrs_front_(需要加锁访问)。 - 如果发现有新注册的 SPSC 队列,将它们从
q_ptrs_front_移动到一个“后端工作队列池”q_ptrs_back_(一个仅由消费者线程访问的std::vector<q_type_ptr>,因此后续对q_ptrs_back_的遍历无需加锁)。清空q_ptrs_front_以便前端可以继续注册。
```c++
// in details::thread_pool_local::process_msg_()
{
std::unique_lock<std::recursive_mutex> lock(que_mutex_); // 保护 q_ptrs_front_
if (!q_ptrs_front_.empty())
{
for (auto &t : q_ptrs_front_)
{
q_ptrs_back_.emplace_back(t); // 移动或复制指针
}
q_ptrs_front_.clear();
}
}
```
- 从所有 SPSC 队列收集日志到最小堆:
- 遍历
q_ptrs_back_中的每一个 SPSC 队列。 - 对每个队列,非阻塞地调用其
dequeue方法,尝试取出日志消息 (async_msg_local)。 - 将成功取出的日志消息放入一个基于时间戳的最小堆
msg_q_(std::priority_queue<std::unique_ptr<async_msg_local>, std::vector<std::unique_ptr<async_msg_local>>, CompareAsyncMsgLocalPtrTimestamp>)。CompareAsyncMsgLocalPtrTimestamp是一个自定义比较器,确保时间戳最小的消息在堆顶。
```c++
// in details::thread_pool_local::process_msg_()
for (auto &spsc_q_ptr : q_ptrs_back_)
{
async_msg_local incoming_msg;
while (spsc_q_ptr->dequeue(incoming_msg)) // 非阻塞 dequeue
{
// 假设 incoming_msg 包含时间戳
// LogMsg 包含时间戳 log_msg_obj.time
// async_msg_local 内部的 log_msg_obj.time
msg_q_.push(spdlog::details::make_unique<async_msg_local>(std::move(incoming_msg)));
}
}
```
- 从最小堆中取出并处理日志:
- 检查最小堆
msg_q_是否为空。 - 如果不为空,从堆顶取出时间戳最早的日志消息。
- 根据消息类型 (
log,flush,terminate) 进行处理,通常是调用async_logger_local实例的backend_sink_it_或backend_flush_方法,将消息传递给实际的 Sinks。
```c++
// in details::thread_pool_local::process_msg_()
bool processed_any_data = false;
while (!msg_q_.empty())
{
processed_any_data = true;
auto msg_ptr = std::move(const_cast<std::unique_ptr<async_msg_local>&>(msg_q_.top()));
msg_q_.pop();
switch (msg_ptr->msg_type)
{
case async_msg_type_local::log:
msg_ptr->worker_ptr->backend_sink_it_(*msg_ptr);
break;
case async_msg_type_local::flush:
msg_ptr->worker_ptr->backend_flush_();
break;
// ... terminate case ...
}
}
```
- 消费者调度与休眠:
- 如果在一轮完整的收割和处理后(即遍历了所有 SPSC 队列并将最小堆中的消息处理完),没有处理任何数据(所有队列都为空,最小堆也为空),那么消费者线程可以短暂休眠一小段时间(例如几纳秒或几微秒),避免忙等待消耗过多 CPU。
```c++
// in details::thread_pool_local::process_msg_()
if (!processed_any_data)
{
std::this_thread::sleep_for(std::chrono::nanoseconds(MIN_SLEEP_DURATION)); // 例如 1ns
}
```
- 优雅退出:
- 当
thread_pool_local析构时,会向所有 SPSC 队列(或通过一个特殊的全局信号)发送terminate消息。 worker_loop_在收到terminate信号或外部stop_标志被设置后,会退出循环前最后一次调用process_msg_(),以确保所有缓冲区的日志都被处理和刷新。
4. async_logger_local 的改动
async_logger_local 的改动相对较小,主要是其构造函数需要接收 std::weak_ptr<details::thread_pool_local>,并且其 sink_it_ 和 flush_ 方法内部调用的 thread_pool_ 的 post_log 和 post_flush 方法是新 thread_pool_local 提供的版本。
初步性能验证
通过本地的初步基准测试,将此改进方案与原版 spdlog (v1.15.1) 在相同的硬件条件下,使用spdlog提供的异步评测示例,测试basic_file_sink在阻塞状态下二者的性能区别。
结果显示,在多生产者线程(如 4 线程及以上)的场景下,由于前端 thread_local SPSC 队列显著减少了锁竞争,改进方案在日志吞吐量表现出了一定程度的性能提升。
测试环境
| 组件 | 描述 |
|---|---|
| CPU | Intel Core i7-13700KF, 16 核, 24 线程, 5.3 GHz (最大 5.4 GHz) |
| 缓存 | L3 30 MiB |
| 内存 | 32GB DDR4 |
| 存储 | Samsung SSD 980 PRO 2TB (NVMe) |
| 操作系统 | atzlinux 12 (Ubuntu-based), 内核 6.8.0-58 |
| 编译器 | GCC 11.4.0, -O3 优化 |
| 系统负载 | 平均负载 0.71-0.97 (低负载) |
测试条件
- 队列大小:8192。
- 生产者线程数:1、2、4、8。
- 测试方法:10 次运行取平均值,输出到文件 Sink。
- 指标:吞吐量(条/秒)。
吞吐量对比
| 生产者线程数 | spdlog 吞吐量 (条/秒) | 优化 SPSC 日志库 (条/秒) | 提升百分比 |
|---|---|---|---|
| 1 | 4,240,865 | 3,673,841 | -13.37% |
| 2 | 2,732,199 | 3,264,696 | +19.49% |
| 4 | 1,431,440 | 3,146,138 | +119.82% |
| 8 | 1,052,129 | 3,803,022 | +261.47% |
总结与展望
本文提出并实现了一种基于 thread_local SPSC 队列和后端最小堆合并排序的 spdlog 异步日志机制改进方案。通过为每个生产者线程提供独立的、写入端几乎无竞争的队列,并由后端消费者线程统一收集、排序和输出,该方案有效地解决了原 MPMC 队列在高并发下的锁竞争问题,并在保证全局日志时间顺序的前提下,获得了可观的性能提升。
代码层面的核心改动在于引入了 async_logger_local、details::thread_pool_local 以及一个支持非阻塞消费的 spsc_blocking_queue。thread_pool_local 通过 static thread_local 变量为每个日志线程按需创建队列,并通过一个集中的“前端队列池” (q_ptrs_front_) 进行注册。消费者线程则将这些队列转移到自己的“后端工作队列池” (q_ptrs_back_),轮询数据放入基于时间戳的最小堆,最后从堆中取出有序日志进行处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号