spdlog源码阅读:03.实现自定义压缩sink
引言
spdlog 是一个功能强大且高度可扩展的 C++ 日志库,其模块化设计允许开发者通过自定义 sink 实现灵活的日志输出。在前两篇文章中,我们分析了 spdlog 的异步日志机制以及 daily_file_sink 和 rotating_file_sink 的实现。本文将聚焦于 如何在 spdlog 中实现自定义 sink,以 compressed_file_sink 为例,详细讲解如何利用 zlib 库实现日志压缩功能,减少磁盘空间占用。
通过本文,你将学会:
- spdlog 中自定义 sink 的实现步骤。
compressed_file_sink如何通过 zlib 实现日志压缩。- 自定义 sink 的关键设计要点和注意事项。
注:本文分析的源码基于 spdlog v1.15.1 和提供的 compressed_file_sink 实现。
spdlog 中自定义 sink 的实现方法
spdlog 的 sink 机制是其扩展性的核心。所有 sink 都继承自 base_sink 模板类,通过实现两个关键虚函数 sink_it_ 和 flush_,即可定义日志的输出逻辑。以下是实现自定义 sink 的通用步骤:
- 继承 base_sink:创建一个新类,继承
base_sink<Mutex>,选择合适的互斥锁(如std::mutex用于多线程,null_mutex用于单线程)。 - 实现 sink_it_:定义日志消息的处理逻辑,如格式化、加工或输出到目标(如文件、网络)。
- 实现 flush_:确保缓冲区数据被刷新到目标,完成输出。
- 管理资源:在构造函数中初始化资源(如文件句柄、缓冲区),在析构函数中清理。
- 提供工厂函数:为多线程和单线程模式定义便捷的创建函数(如
compressed_file_logger_mt/st)。
compressed_file_sink 遵循上述步骤,通过集成 zlib 库实现了压缩日志的输出,下面我们以其为案例进行深入分析。
compressed_file_sink 实现解析
compressed_file_sink 是一个自定义 sink,通过缓冲日志消息、利用 zlib 压缩数据并写入文件,实现高效的日志存储。以下从 demo 入手,逐步剖析其实现原理。
使用 demo
以下是一个简单的 compressed_file_sink 使用示例:
#include "spdlog/spdlog.h"
#include "compressed_file_sink.h"
void compressed_file_example() {
auto compressed_logger = spdlog::compressed_file_logger_mt("compressed_logger", "logs/compressed_log.z", 8192, Z_DEFAULT_COMPRESSION);
compressed_logger->info("This is a compressed log message.");
compressed_logger->flush();
}
在这个 demo 中,我们创建了一个多线程的压缩日志 logger,日志消息通过 compressed_file_sink 压缩后写入 logs/compressed_log.z 文件。
日志消息流转与压缩实现
以 info("This is a compressed log message.") 为例,分析日志消息的处理流程,重点讲解压缩逻辑。
日志生产
- 调用 info 方法:
- 用户调用
logger->info,触发模板函数,最终调用base_sink的log方法,执行sink_it_虚函数。 - 在
compressed_file_sink::sink_it_中,日志消息被格式化并追加到内部缓冲区。
- 用户调用
void sink_it_(const details::log_msg &msg) override {
memory_buf_t formatted;
base_sink<Mutex>::formatter_->format(msg, formatted);
buffer_.append(formatted.data(), formatted.data() + formatted.size());
if (buffer_.size() >= buffer_capacity_) {
compress_and_write_();
}
}
- 缓冲管理:
- 格式化后的日志消息存储在
buffer_(类型为memory_buf_t)。 - 当
buffer_大小达到buffer_capacity_(默认 8192 字节)时,调用compress_and_write_进行压缩和写入。
- 格式化后的日志消息存储在
日志压缩与写入
compress_and_write_ 是压缩功能的核心,结合 zlib 库完成数据压缩并写入文件。以下是其实现步骤:
- 初始化 zlib 输入:
- 将
buffer_的数据传递给 zlib 压缩流strm_,设置输入指针(next_in)和长度(avail_in)。
- 将
strm_.avail_in = static_cast<uInt>(buffer_.size());
strm_.next_in = reinterpret_cast<Bytef *>(const_cast<char *>(buffer_.data()));
- 逐步压缩(Z_NO_FLUSH):
- 使用
deflate函数以Z_NO_FLUSH模式分步处理输入数据,输出到临时缓冲区compress_buffer_(类型为std::vector<unsigned char>)。 - 循环调用
deflate直到所有输入数据被消耗,收集压缩输出到compressed_output。
- 使用
do {
strm_.avail_out = static_cast<uInt>(compress_buffer_.size());
strm_.next_out = compress_buffer_.data();
deflate_ret = deflate(&strm_, Z_NO_FLUSH);
size_t have = compress_buffer_.size() - strm_.avail_out;
if (have > 0) {
compressed_output.insert(compressed_output.end(), compress_buffer_.data(), compress_buffer_.data() + have);
}
} while (strm_.avail_out == 0 && strm_.avail_in > 0);
- 结束压缩(Z_FINISH):
- 使用
Z_FINISH模式完成当前压缩块,生成完整的压缩数据。 - 继续调用
deflate直到返回Z_STREAM_END,确保所有输出被收集。
- 使用
do {
strm_.avail_out = static_cast<uInt>(compress_buffer_.size());
strm_.next_out = compress_buffer_.data();
finish_ret = deflate(&strm_, Z_FINISH);
size_t have = compress_buffer_.size() - strm_.avail_out;
if (have > 0) {
compressed_output.insert(compressed_output.end(), compress_buffer_.data(), compress_buffer_.data() + have);
}
} while (finish_ret != Z_STREAM_END);
- 写入文件:
- 压缩数据存储在
compressed_output中。 - 首先写入 4 字节的压缩块长度(
uint32_t),便于解压时解析。 - 然后写入压缩数据,使用
file_helper_.write完成文件 IO。
- 压缩数据存储在
uint32_t compressed_size = static_cast<uint32_t>(compressed_output.size());
if (compressed_size > 0) {
memory_buf_t size_buf;
size_buf.append(reinterpret_cast<const char *>(&compressed_size),
reinterpret_cast<const char *>(&compressed_size) + sizeof(compressed_size));
file_helper_.write(size_buf);
memory_buf_t data_buf;
data_buf.append(reinterpret_cast<const char *>(compressed_output.data()),
reinterpret_cast<const char *>(compressed_output.data()) + compressed_output.size());
file_helper_.write(data_buf);
}
- 重置与清理:
- 通过
deflateReset重置 zlib 流,为下一块压缩准备。 - 清空
buffer_,等待新的日志消息。
- 通过
deflateReset(&strm_);
buffer_.clear();
刷新与资源管理
- 刷新缓冲区:
- 用户调用
logger->flush()触发flush_方法,调用compress_and_write_压缩剩余数据,并通过file_helper_.flush()确保写入磁盘。
- 用户调用
void flush_() override {
compress_and_write_();
file_helper_.flush();
}
- 资源初始化与清理:
- 构造函数:初始化 zlib 流(
deflateInit)、打开文件(file_helper_.open)、预分配缓冲区(buffer_和compress_buffer_)。 - 析构函数:刷新缓冲区、释放 zlib 资源(
deflateEnd),file_helper_自动关闭文件。
- 构造函数:初始化 zlib 流(
explicit compressed_file_sink(const filename_t &filename, size_t buffer_capacity = 8192,
int compression_level = Z_DEFAULT_COMPRESSION) {
strm_.zalloc = Z_NULL;
strm_.zfree = Z_NULL;
strm_.opaque = Z_NULL;
int ret = deflateInit(&strm_, compression_level_);
if (ret != Z_OK) throw spdlog_ex("Failed to initialize zlib deflate", ret);
file_helper_.open(filename_, false);
buffer_.reserve(buffer_capacity_);
compress_buffer_.resize(buffer_capacity_);
}
~compressed_file_sink() override {
try {
std::lock_guard<Mutex> lock(base_sink<Mutex>::mutex_);
flush_();
deflateEnd(&strm_);
} catch (...) {}
}
关键类与设计
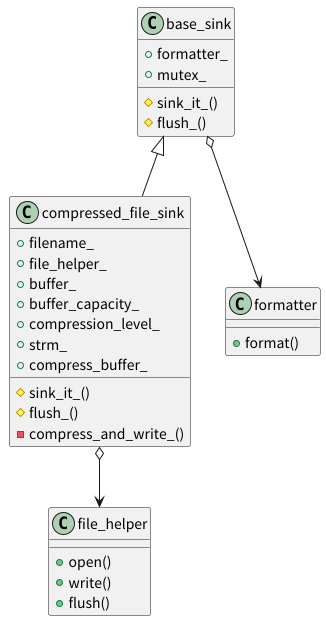
类层次结构
compressed_file_sink 的设计充分利用了 spdlog 的模块化架构,以下是关键类关系:
- base_sink:提供日志格式化和线程安全的基础功能,定义
sink_it_和flush_接口。 - compressed_file_sink:继承
base_sink,实现压缩逻辑,管理 zlib 流和缓冲区。 - file_helper:封装文件操作,负责打开、写入和刷新。
- formatter:格式化日志消息。
类图如下:
总结
通过分析 compressed_file_sink,我们深入理解了 spdlog 中自定义 sink 的实现方法。compressed_file_sink 利用 zlib 库,通过缓冲、分块压缩和长度前缀的机制,实现了高效的日志压缩功能。
未来可探索以下方向:
- 结合
daily_file_sink,实现按天分割的压缩日志。 - 尝试其他压缩库(如 zstd),提升压缩速度或比率。
希望本文能为你提供清晰的自定义 sink 实现指南!如需进一步探讨或优化建议,欢迎随时交流。
附:完整压缩源码和压缩日志读取器
#pragma once
#include <spdlog/common.h>
#include <spdlog/sinks/base_sink.h>
#include <spdlog/details/file_helper.h>
#include <spdlog/details/null_mutex.h>
#include <spdlog/details/synchronous_factory.h>
#include <spdlog/fmt/fmt.h>
#include <zlib.h>
#include <string>
#include <mutex>
namespace spdlog
{
namespace sinks
{
// 自定义压缩文件 Sink (使用 file_helper)
template<typename Mutex>
class compressed_file_sink : public base_sink<Mutex>
{
public:
// 构造函数
explicit compressed_file_sink(const filename_t &filename, size_t buffer_capacity = 8192,
int compression_level = Z_DEFAULT_COMPRESSION)
: filename_(filename), buffer_capacity_(buffer_capacity), compression_level_(compression_level)
{
// 初始化 zlib 压缩流
strm_.zalloc = Z_NULL;
strm_.zfree = Z_NULL;
strm_.opaque = Z_NULL;
int ret = deflateInit(&strm_, compression_level_);
if (ret != Z_OK)
{
throw spdlog_ex("Failed to initialize zlib deflate", ret);
}
// 使用 file_helper 打开文件 (false 表示不截断,实现追加效果)
try
{
file_helper_.open(filename_, false);
} catch (const spdlog_ex &ex)
{
deflateEnd(&strm_); // 清理 zlib 资源
throw ex; // 重新抛出文件打开异常
}
// 预分配缓冲区 (使用 spdlog::memory_buf_t)
buffer_.reserve(buffer_capacity_);
compress_buffer_.resize(buffer_capacity_); // 初始压缩缓冲区大小 (保持 vector<unsigned char> 以便与 zlib C API 交互)
}
// 析构函数:确保所有缓冲数据被压缩和写入
~compressed_file_sink() override
{
try
{
// 获取锁以安全地刷新
std::lock_guard<Mutex> lock(base_sink<Mutex>::mutex_);
flush_(); // 刷新剩余缓冲区
deflateEnd(&strm_); // 清理 zlib 资源
// file_helper 会在析构时自动关闭文件,无需显式调用 close()
} catch (...)
{
// 析构函数中不应抛出异常
}
}
compressed_file_sink(const compressed_file_sink &) = delete;
compressed_file_sink &operator=(const compressed_file_sink &) = delete;
protected:
// 核心日志记录方法
void sink_it_(const details::log_msg &msg) override
{
memory_buf_t formatted;
base_sink<Mutex>::formatter_->format(msg, formatted);
// 将格式化后的消息追加到内部缓冲区 buffer_
buffer_.append(formatted.data(), formatted.data() + formatted.size());
// 如果缓冲区达到阈值,则压缩并写入文件
if (buffer_.size() >= buffer_capacity_)
{
compress_and_write_();
}
}
// 强制刷新缓冲区
void flush_() override
{
compress_and_write_();
file_helper_.flush(); // 刷新 file_helper 的缓冲区
}
private:
// private:
void compress_and_write_()
{
if (buffer_.size() == 0)
{
return;
}
strm_.avail_in = static_cast<uInt>(buffer_.size());
strm_.next_in = reinterpret_cast<Bytef *>(const_cast<char *>(buffer_.data()));
std::vector<unsigned char> compressed_output;
int deflate_ret = Z_OK;
// 缓冲区用于 deflate 的单次输出
// 调整大小以更好地适应可能的压缩输出,可以根据需要调整
if (compress_buffer_.size() < buffer_.size() / 2)
{
compress_buffer_.resize(buffer_.size() / 2 + 128); // 简单策略:至少是输入一半+一些头部
}
// ---- Step 1: 使用 Z_NO_FLUSH 消耗所有输入 ----
do
{
strm_.avail_out = static_cast<uInt>(compress_buffer_.size());
strm_.next_out = compress_buffer_.data();
deflate_ret = deflate(&strm_, Z_NO_FLUSH); // 先处理输入,不清空内部状态
if (deflate_ret != Z_OK && deflate_ret != Z_BUF_ERROR)
{
// Z_STREAM_END 不应该在这里发生
throw spdlog_ex("zlib deflate(Z_NO_FLUSH) failed", deflate_ret);
}
size_t have = compress_buffer_.size() - strm_.avail_out;
if (have > 0)
{
compressed_output.insert(compressed_output.end(), compress_buffer_.data(),
compress_buffer_.data() + have);
}
// 继续,直到输出缓冲区不再被填满(表示deflate可以处理更多输入,如果还有的话)
// 并且还有输入数据需要处理
} while (strm_.avail_out == 0 && strm_.avail_in > 0);
// 此时,所有输入 (strm.avail_in) 应该已经被消耗,除非发生错误
if (strm_.avail_in != 0 && deflate_ret != Z_BUF_ERROR)
{
// 如果还有输入但 deflate 没有要求更多输出空间,这不正常
throw spdlog_ex("zlib deflate did not consume all input unexpectedly");
}
// ---- Step 2: 使用 Z_FINISH 结束当前流(块)并收集所有剩余输出 ----
int finish_ret = Z_OK;
do
{
strm_.avail_out = static_cast<uInt>(compress_buffer_.size());
strm_.next_out = compress_buffer_.data();
finish_ret = deflate(&strm_, Z_FINISH); // 结束当前块/流
// Z_FINISH 可能会返回 Z_OK 或 Z_BUF_ERROR 多次,直到返回 Z_STREAM_END
if (finish_ret != Z_OK && finish_ret != Z_STREAM_END && finish_ret != Z_BUF_ERROR)
{
throw spdlog_ex("zlib deflate(Z_FINISH) failed", finish_ret);
}
size_t have = compress_buffer_.size() - strm_.avail_out;
if (have > 0)
{
compressed_output.insert(compressed_output.end(), compress_buffer_.data(),
compress_buffer_.data() + have);
}
// 继续调用 Z_FINISH 直到它返回 Z_STREAM_END
} while (finish_ret != Z_STREAM_END);
// ---- Step 3: 写入文件 (与之前相同) ----
uint32_t compressed_size = static_cast<uint32_t>(compressed_output.size());
if (compressed_size > 0)
{
memory_buf_t size_buf;
size_buf.append(reinterpret_cast<const char *>(&compressed_size),
reinterpret_cast<const char *>(&compressed_size) + sizeof(compressed_size));
file_helper_.write(size_buf);
memory_buf_t data_buf;
data_buf.append(reinterpret_cast<const char *>(compressed_output.data()),
reinterpret_cast<const char *>(compressed_output.data()) + compressed_output.
size());
file_helper_.write(data_buf);
}
// ---- Step 4: 重置 zlib 流,为下一个独立块做准备 ----
// 因为我们使用了 Z_FINISH,流状态需要完全重置
int reset_ret = deflateReset(&strm_);
if (reset_ret != Z_OK)
{
throw spdlog_ex("Failed to reset zlib deflate stream", reset_ret);
}
// 清空内部缓冲区
buffer_.clear();
}
filename_t filename_; // 日志文件名
details::file_helper file_helper_; // 使用 spdlog 的文件助手
memory_buf_t buffer_; // 未压缩数据的内部缓冲区 (使用 memory_buf_t)
size_t buffer_capacity_; // 内部缓冲区阈值
int compression_level_; // zlib 压缩级别
z_stream strm_; // zlib 压缩流
std::vector<unsigned char> compress_buffer_; // 用于存放压缩数据的临时缓冲区
};
// 类型别名和工厂函数保持不变
using compressed_file_sink_mt = compressed_file_sink<std::mutex>;
using compressed_file_sink_st = compressed_file_sink<details::null_mutex>;
} // namespace sinks
template<typename Factory = spdlog::synchronous_factory>
inline std::shared_ptr<logger> compressed_file_logger_mt(const std::string &logger_name, const filename_t &filename,
size_t buffer_capacity = 8192,
int compression_level = Z_DEFAULT_COMPRESSION)
{
return Factory::template create<sinks::compressed_file_sink_mt>(logger_name, filename, buffer_capacity,
compression_level);
}
template<typename Factory = spdlog::synchronous_factory>
inline std::shared_ptr<logger> compressed_file_logger_st(const std::string &logger_name, const filename_t &filename,
size_t buffer_capacity = 8192,
int compression_level = Z_DEFAULT_COMPRESSION)
{
return Factory::template create<sinks::compressed_file_sink_st>(logger_name, filename, buffer_capacity,
compression_level);
}
} // namespace spdlog
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <zlib.h>
#include <cstdint> // for uint32_t
#include <stdexcept> // for runtime_error
// 解压缓冲区大小
const size_t DECOMPRESS_BUFFER_SIZE = 16384; // 16 KB
int main(int argc, char *argv[])
{
if (argc != 3)
{
std::cerr << "用法: " << argv[0] << " <compressed_log_file>" << " <decompression_log_file>" << std::endl;
return 1;
}
const char *filename = argv[1];
const char *decompressed_filename = argv[2];
std::ifstream infile(filename, std::ios::binary);
std::ofstream outfile(decompressed_filename, std::ios::binary);
if (!infile.is_open())
{
std::cerr << "错误: 无法打开文件 " << filename << std::endl;
return 1;
}
// 初始化 zlib 解压流
z_stream strm;
strm.zalloc = Z_NULL;
strm.zfree = Z_NULL;
strm.opaque = Z_NULL;
strm.avail_in = 0;
strm.next_in = Z_NULL;
int ret = inflateInit(&strm);
if (ret != Z_OK)
{
std::cerr << "错误: 初始化 zlib inflate 失败, code: " << ret << std::endl;
return 1;
}
std::vector<unsigned char> compressed_buffer;
std::vector<unsigned char> decompress_buffer(DECOMPRESS_BUFFER_SIZE);
uint32_t compressed_block_size = 0;
try
{
// 循环读取文件中的压缩块
while (infile.read(reinterpret_cast<char *>(&compressed_block_size), sizeof(compressed_block_size)))
{
if (compressed_block_size == 0)
{
// 可能是空块写入(虽然我们的sink实现不会写0长度块),跳过
continue;
}
// 读取指定大小的压缩数据
compressed_buffer.resize(compressed_block_size);
if (!infile.read(reinterpret_cast<char *>(compressed_buffer.data()), compressed_block_size))
{
std::cerr << "错误: 读取压缩数据块时文件提前结束或发生错误。" << std::endl;
// 根据需要决定是退出还是尝试继续处理已读取部分
break; // 或者 return 1;
}
strm.avail_in = compressed_block_size;
strm.next_in = compressed_buffer.data();
// 循环解压当前块
do
{
strm.avail_out = static_cast<uInt>(decompress_buffer.size());
strm.next_out = decompress_buffer.data();
ret = inflate(&strm, Z_NO_FLUSH); // 使用 Z_NO_FLUSH 进行正常解压
switch (ret)
{
case Z_NEED_DICT:
case Z_DATA_ERROR:
case Z_MEM_ERROR:
inflateEnd(&strm);
throw std::runtime_error(std::string("zlib inflate 错误: ") + strm.msg);
case Z_STREAM_ERROR:
inflateEnd(&strm);
throw std::runtime_error("zlib inflate 错误: 无效的流状态");
}
// 计算解压出的数据量
size_t have = decompress_buffer.size() - strm.avail_out;
if (have > 0)
{
// 将解压后的数据写入标准输出
std::cout.write(reinterpret_cast<const char *>(decompress_buffer.data()), have);
outfile.write(reinterpret_cast<const char *>(decompress_buffer.data()), have);
}
// 如果输出缓冲区满了,inflate 需要再次被调用来处理剩余的输入
} while (strm.avail_out == 0); // 继续解压直到输出缓冲区不再被填满
// 检查当前块是否解压完毕
if (strm.avail_in != 0)
{
// Z_SYNC_FLUSH 写入的块,解压时 inflate 可能在块结束时返回 Z_OK 而不是 Z_STREAM_END
// 只要输入被消耗完 (avail_in == 0) 就认为一个块处理完了
// 如果输入没消耗完但 inflate 又没返回错误,可能逻辑有问题
// 对于 Z_SYNC_FLUSH, 我们期望 avail_in 最终为 0
inflateEnd(&strm);
throw std::runtime_error("解压错误: 输入数据未完全消耗完但解压停止");
}
// inflateReset(&strm); // 不需要 reset,因为每次都读新块并设置 avail_in/next_in
// inflateInit 应该为每个独立块工作
// 修正:对于流式解压,应该持续使用同一个 strm,并在块之间可能需要 inflateSync
// 或者更简单的,如果块是独立压缩的(如我们的例子,虽然用了 Z_SYNC_FLUSH 但逻辑上独立)
// 可以在处理完一个块后调用 inflateReset
ret = inflateReset(&strm);
if (ret != Z_OK)
{
inflateEnd(&strm);
throw std::runtime_error("zlib inflateReset 失败");
}
} // end while read block size
// 检查是否因为读取错误而退出循环
if (!infile.eof() && infile.fail())
{
std::cerr << "错误: 读取文件时发生 I/O 错误。" << std::endl;
outfile.close();
}
} catch (const std::exception &e)
{
std::cerr << "运行时错误: " << e.what() << std::endl;
inflateEnd(&strm); // 确保清理
outfile.close();
return 1;
}
// 清理 zlib 资源
inflateEnd(&strm);
std::cout.flush(); // 确保所有输出都被写入
outfile.close();
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号