
AI Agent系列-Google AI Agent学习-安全与治理:自主进化:持续学习、Agent Gym 与两个前沿案例
1. Agent 如何学习与自我演化
与人类类似,智能体通过经验和外部信号进行持续学习然后进化,才能胜任人类社会更多的任务(这也是一个比较热门的研究领域,后面再单独聊)。
白皮书把 Agent 的“学习信号”分成几类:
- 运行时经验:日志、Trace、记忆,包含成功与失败的轨迹
- 外部信号:新政策文档、监管要求、业务规则更新
- 人类反馈:专家批注、人工审核意见、用户纠错等
有了这些信息之类,我们要将这些“历史记录”转化为可复用的抽象产物,进而提升 Agent 的能力。概括来说主要有如下方式:
- 增强上下文工程: 系统会持续优化其提示、少量示例以及从记忆中检索的信息。通过为每个任务优化提供给语言模型的上下文,它可以提高成功的可能性
- 工具优化与创建: 智能体的推理可以识别其能力上的不足并采取行动加以弥补。这可能包括获取新工具的访问权限、即时创建新工具(例如,Python脚本),或修改现有工具(例如,更新API模式)
- (除此之外,其实我们还可以利用真实世界的这些反馈数据对模型进行后训练微调,从而使模型在我们的场景下编写的更好)
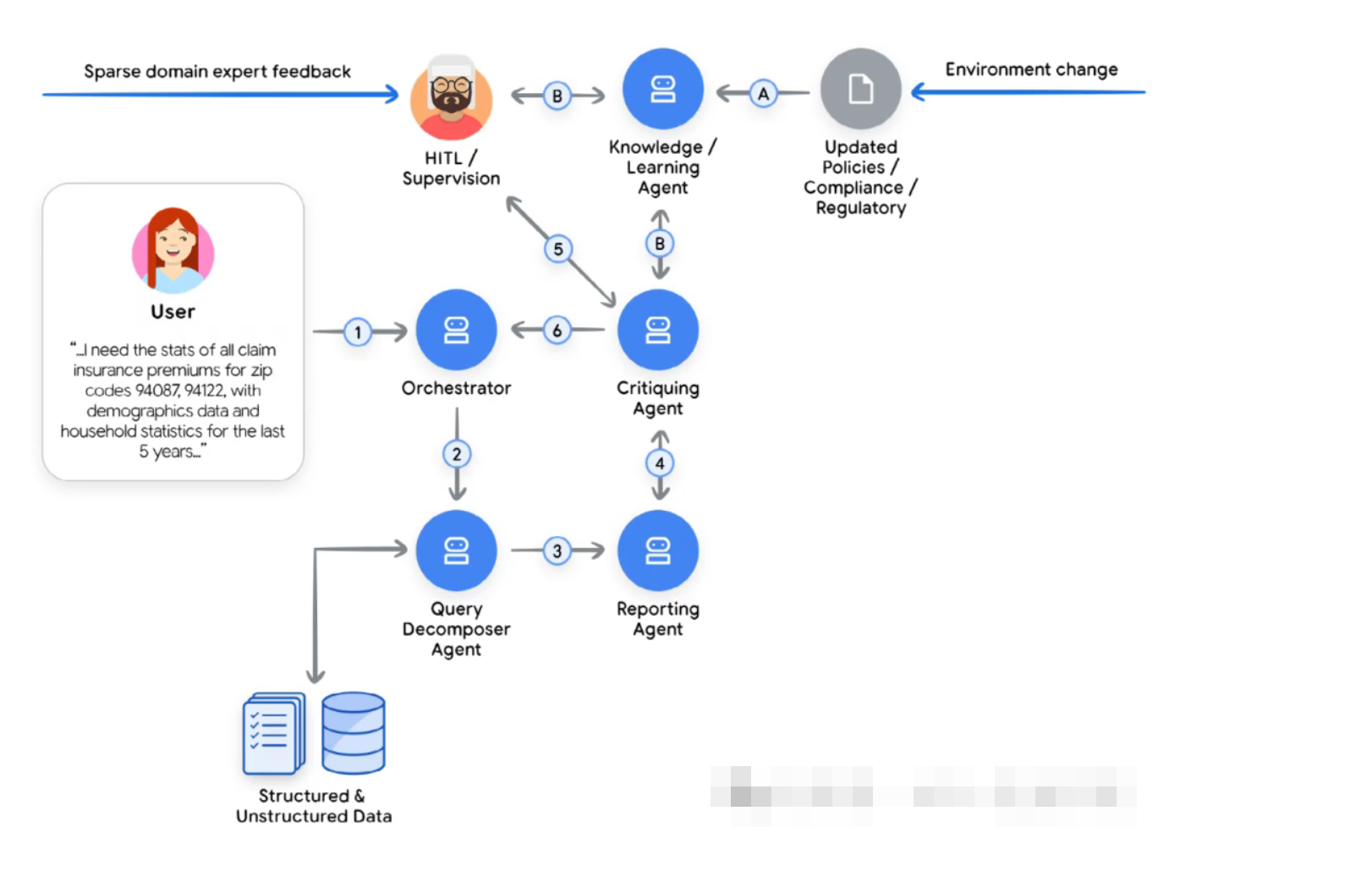
2. Agent Gym:离线仿真与极限压测
除了上面的内容,当前业界也正在研究更先进的方法,即构建一个专用平台,通过先进的工具和功能在离线流程中优化多智能体系统,而这些工具和功能并不属于多智能体运行时环境。这个在白皮书中,被称为 “Agent Gym”:
- 不在生产路径上,是一个独立的离线优化平台
- 提供高保真仿真环境,让 Agent 在合成或回放数据上“训练”
- 可以调用更强大的模型、更多外部工具(包括红队、动态评估与批判 Agent)
- 可以利用合成数据不断扩充、覆盖真实难例
- 在难以自动判断的场景下,Agent Gym 还可以主动“求助”人类专家,
把人类判断固化为下一轮优化的基准
它更像是企业版的“Agent 训练场 + 红蓝对抗实验室”。
3. 两个代表性案例
白皮书中举了两个 Google 内部的例子,简单描述如下,不再赘述。
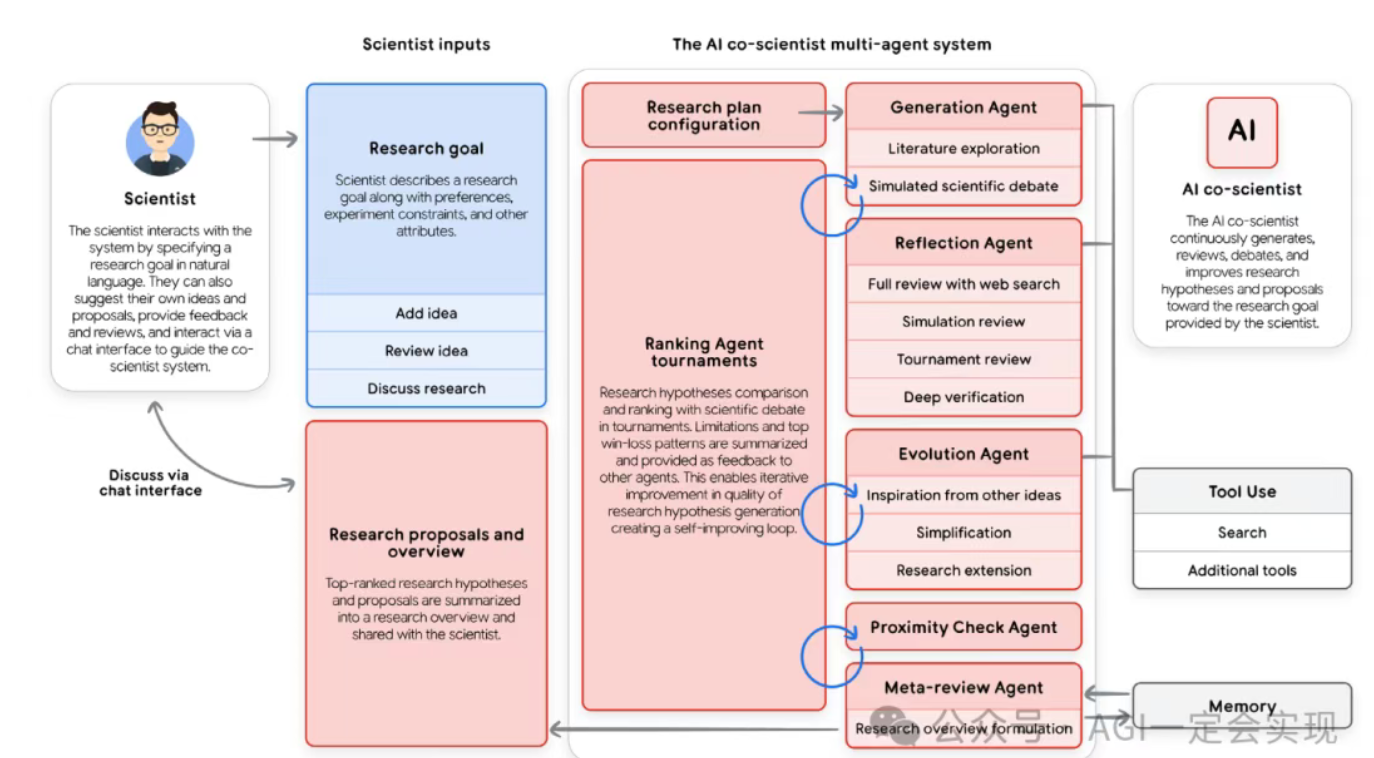
Google Co‑Scientist
- 面向科研的多 Agent 系统,作为“虚拟合作者”帮助探索科研假设空间
- 典型流程:
- 研究者定义目标与约束
- 系统生成项目计划,由 Supervisor Agent 分配给不同子 Agent
- 多个 Agent 在长时间尺度上生成、评估和改进假设
- 本质上是一个 Level 3/4 混合系统,既有多 Agent 协作,也开始具备自我改进能力
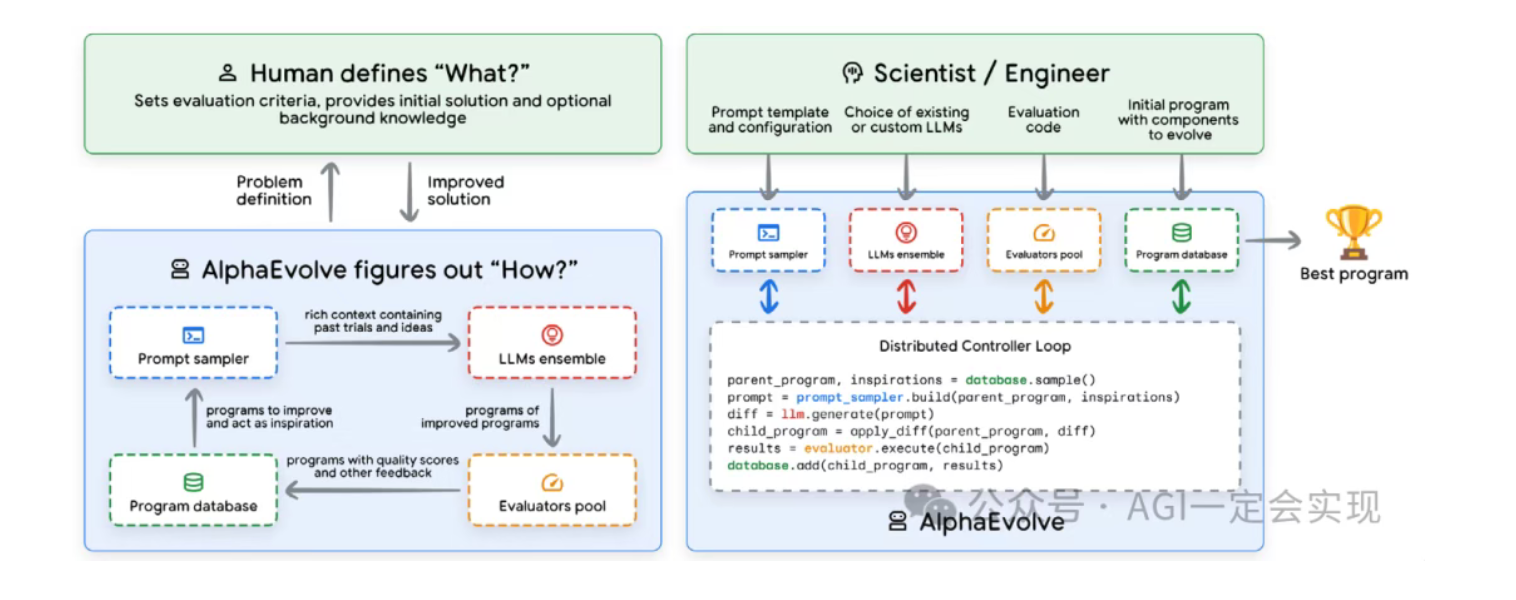
AlphaEvolve
- 用 Agent 体系探索数学与计算机科学中的复杂算法设计问题
- 核心机制:
- LM 负责生成候选算法(以可读代码形式)
- 评估器根据指标打分
- 通过“进化”过程选优并继续生成下一代
- 已在数据中心调度、芯片设计、矩阵乘法等场景中取得突破
- 适合“容易验证、难以直接构造”的问题空间
- 保留了人类专家在目标定义与指标设计上的关键角色,避免系统“钻空子”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号