China .NET Conf 2019-.NET技术架构下的混沌工程实践
这个月的8号、9号,个人很荣幸参加了China.NET Conf 2019 , 中国.NET开发者峰会,同时分享了技术专题《.NET技术架构下的混沌工程实践》,给广大的.NET开发小伙伴介绍混沌工程和高可用性改造实践。会后大家伙聚餐的时候,陈计节老师建议大家将各自的议题分享到社区,分享给大家。因此,今天和大家分享我的技术专题《.NET技术架构下的混沌工程实践》。
先放几张大会照片:

整个专题主要分为四个部分:
- .NET分布式、微服务架构下的高可用性挑战
- 混沌工程简介
- .NET混沌工程的实践和成果分享
- 展望和规划
一、.NET分布式、微服务架构下的高可用性挑战
目前,我们特来电的技术架构是分布式、微服务化的,线上超过1000台Server,高可用保障压力很大:
- 系统7*24小时运行,不允许宕机,一旦宕机出问题,直接影响全国人民出行;
- 系统SLA要求99.95% ,全年可宕机时间只有4.38小时;
- 服务调用链路越来越长,依赖越来越复杂,某个环节出问题,都有肯能导致服务雪崩、大规模宕机;
- 线上遭遇:网络抖动、内存泄露、线程阻塞、CPU被打爆、 数据库被打爆、中间件宕机等棘手问题;
- 每天上百次发布更新,系统高可用性保障压力非常大;
一张全链路监控图可以反映我们系统的复杂:
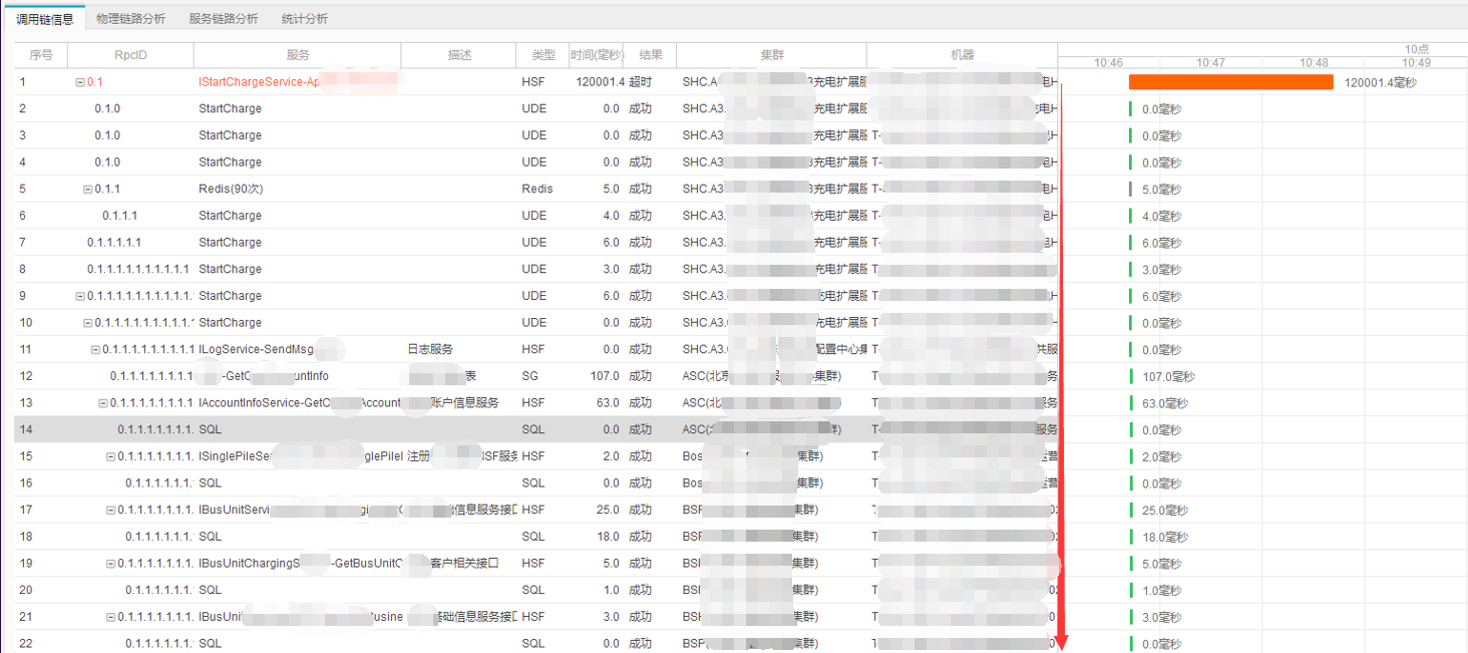
例如主机CPU被打爆的问题,线上经常会遇到:
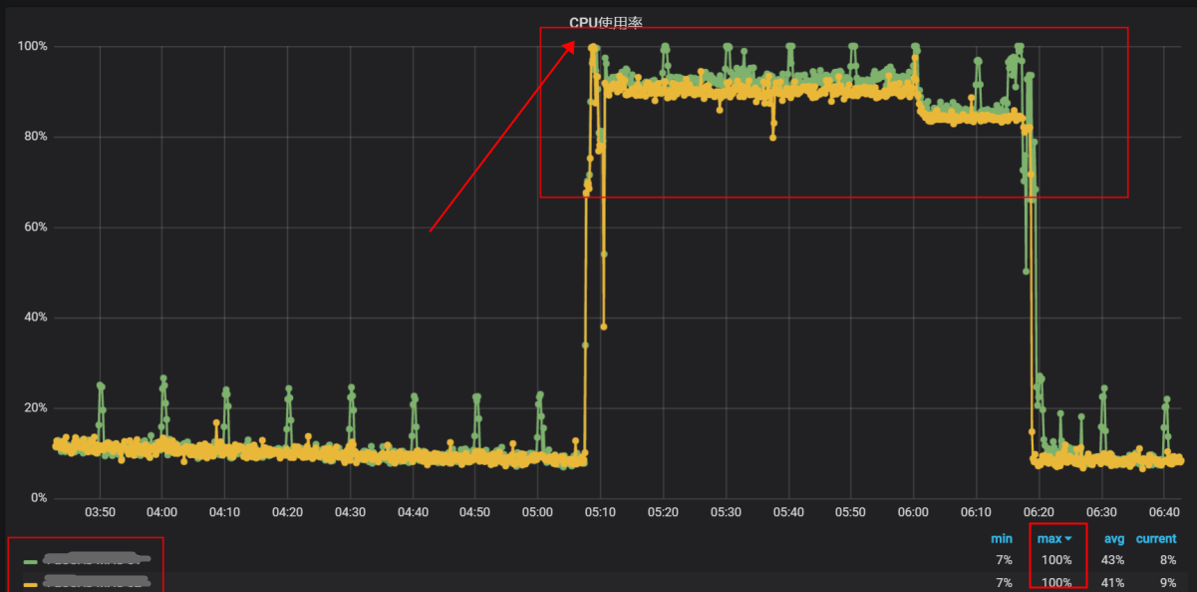
经历了线上各种高可用性问题后,我们做了很多反思和总结:
系统在实现了分布式、微服务化之后,我们到底有多少把握来保证系统的正常运行?
如果出现问题,整个分布式系统会变得非常“混乱”,甚至会引发系统的大规模宕机。
因此,我们有必要在线上事故出现之前,提前识别出系统有哪些弱点和问题,统一管控系统的固有混沌。
这套管控系统固有混沌的方法和体系,就是我们今天要介绍的主角:混沌工程。
二、混沌工程简介
1. 什么是混沌工程?
通过受控的实验,掌握系统运行行为的过程,称为混沌工程。
混沌工程的典型实践:Chaos Monkey
一只捣乱的猴子,在你的系统里面上蹦下窜,不停捣乱,直到搞挂你的系统。

2. 为什么需要混沌工程?
混沌工程可以提升整个系统的弹性。
通过混沌实验,可以发现系统脆弱的一面,主动发现这些问题,并解决这些问题。
3. 混沌工程怎么做?
混沌工程的一般实施步骤:
1 选择系统正常运行状态下的可度量指标,作为基准的“稳定状态”
2 混沌实验分为实验组和对照组,都能保持系统的“稳定状态”
3 对实验组注入混沌事件,如服务不可用、中间件宕机等混沌事件
4 比较实验组和对照组“稳定状态”的差异
如果混沌实验前后系统的“稳定状态”一致,则可以认为系统应对这种混沌事件是弹性的、高可用的。
相反的,如果打破了系统的稳定状态,我们就找到了一个系统弱点,然后尽可能地解决它,提升系统的高可用性。
4. 实施混沌工程的推荐原则
- 明确系统稳定运行的状态(指标)
- 混沌事件必须是现实世界可能发生的(合理的)
- 在生产环境进行混沌实验 :生产环境可以真实地反映系统的稳定性
- 持续集成:线上应用每天都在更新,通过持续集成的方式可以不断发现问题、解决问题。
- 最小化影响范围:线上进行混沌实验,必须可控,必须确定混沌实验的最小化影响范围。
这里大家会问:在生产环境上搞混沌实验,能行吗?
5. 现实中的混沌工程
生产环境必须以稳定为前提,因此推荐O2O模式的混沌实验:即线下演练、线上验证
在系统未经过大规模高可用性改造之前,建议首先进行全面的线下演练:
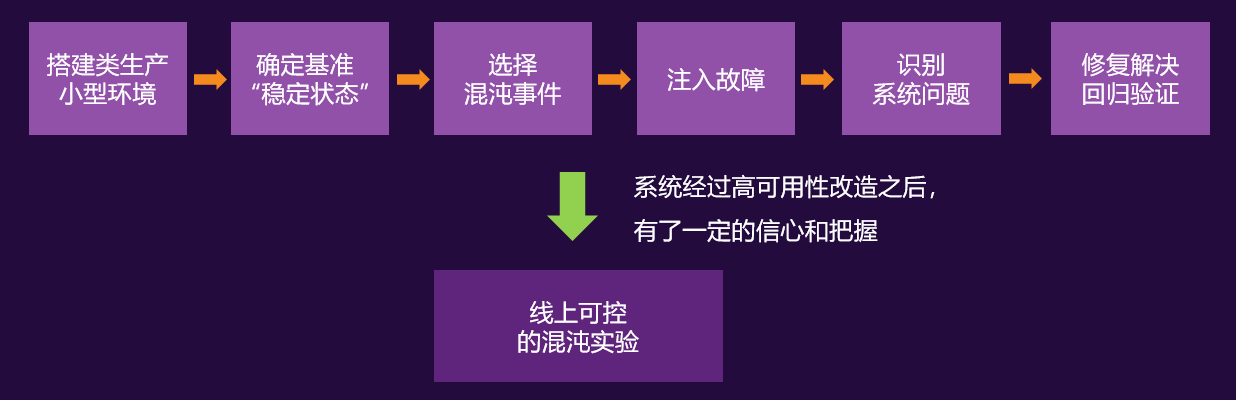
那么, .NET技术架构下的混沌工程怎么做?
三、.NET混沌工程的实践和成果分享
我们线上系统主要用到了以下.NET技术栈和开源技术:
- ASP.NET MVC
- 基于ASP.NET Core的Web运行框架-WRF
- 基于ASP.NET Web API的分布式服务网关-SG
- 基于.NET RPC通讯技术的分布式微服务平台-HSF
- 基于RabbitMQ和Kafka的消息应用中心-MAC
- iBatis.NET & Entity Framework
- RabbitMQ & RabbitMQ Client for .NET
- Kafka & Confluent.Kafka
- Redis
- Nginx
- …
在上述.NET 技术架构下,我们梳理了大量的混沌工程事件:

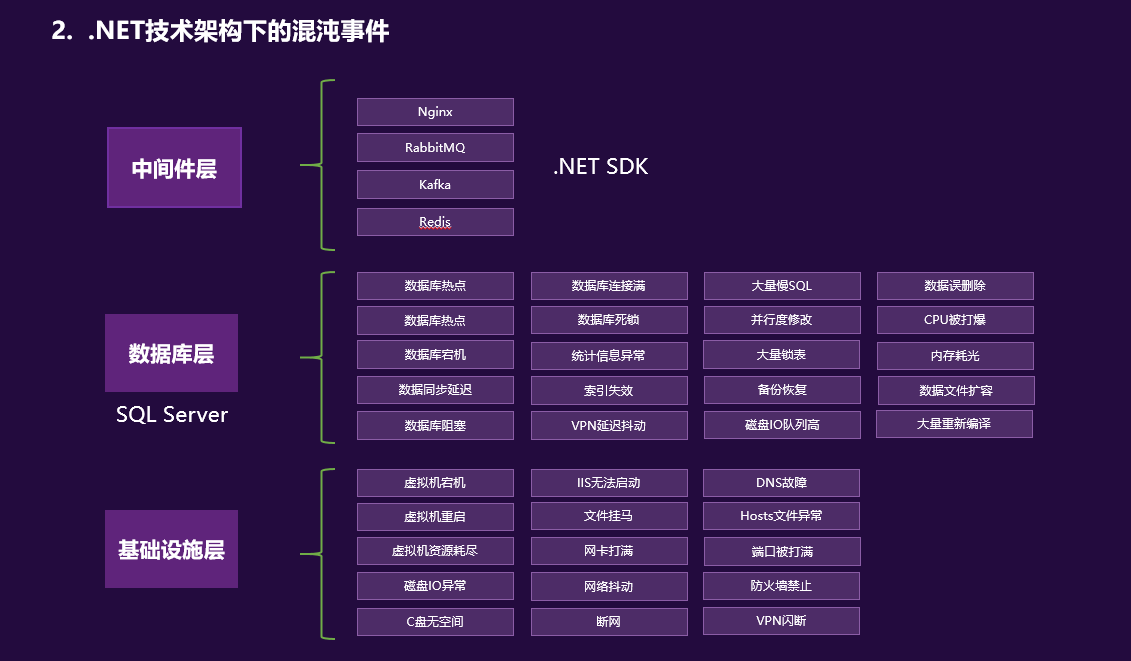

通过大量的混沌实验,我们逐步建立了提升系统高可用性的方法论和体系:

.NET技术架构下的高可用性改进-依赖治理、容错降级
业务场景:
随着业务复杂度的上升,服务调用链路越来越长,链路上存在大量不可控的因素:
-
- 网络抖动,导致服务异常
- Redis、MQ、DB等中间件不可用,导致服务超时、异常
- 依赖的服务不可用,直接影响服务调用方
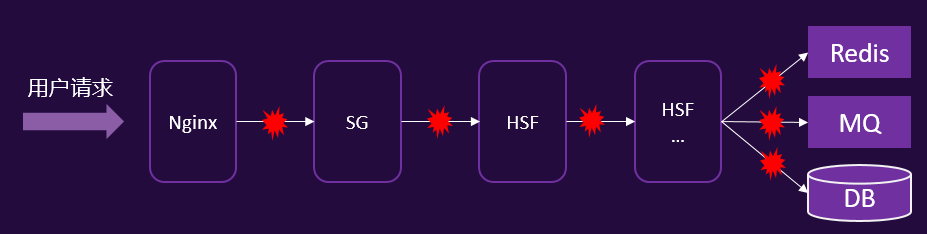
如何应对:识别强弱依赖,对弱依赖进行降级,对强依赖有限降级
-
- “用户有感知” 是强依赖
- “用户无感知” 是弱依赖
- 故障发生时,核心业务有损失的是强依赖,无损失的是弱依赖
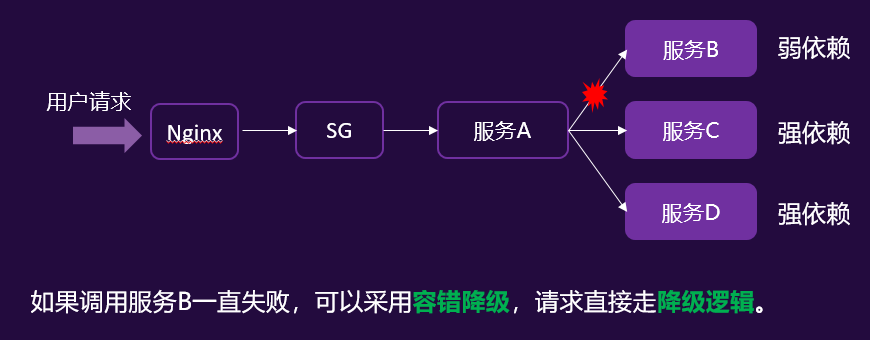
.NET技术架构下的高可用性改进-解耦/隔离
业务场景:
核心业务的调用链路很长,整个链路上包含主流程和辅流程
辅流程的重要性低,不能因为辅流程的不可用,影响了主流程。
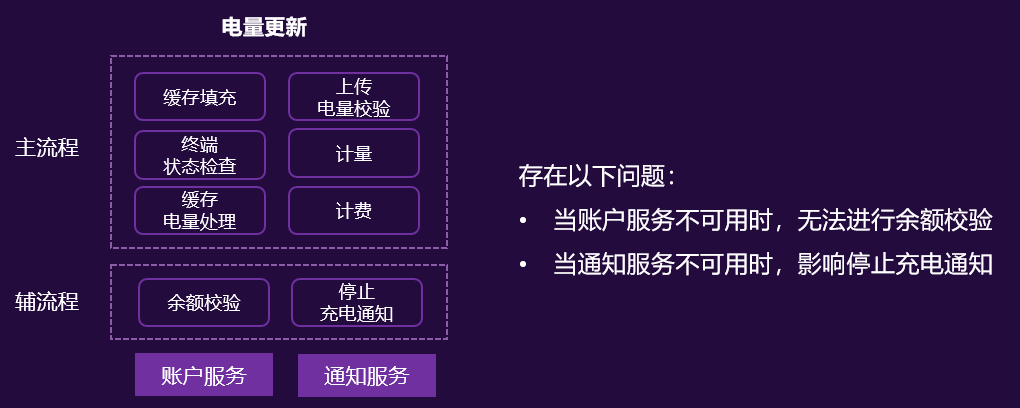
如何应对:

.NET技术架构下的高可用性改进-超时治理
业务场景:
对于服务超时,长时间等待会影响用户体验,并发大时还可能造成线程池被打爆。
同时可能产生服务级联反应,导致大范围服务雪崩。
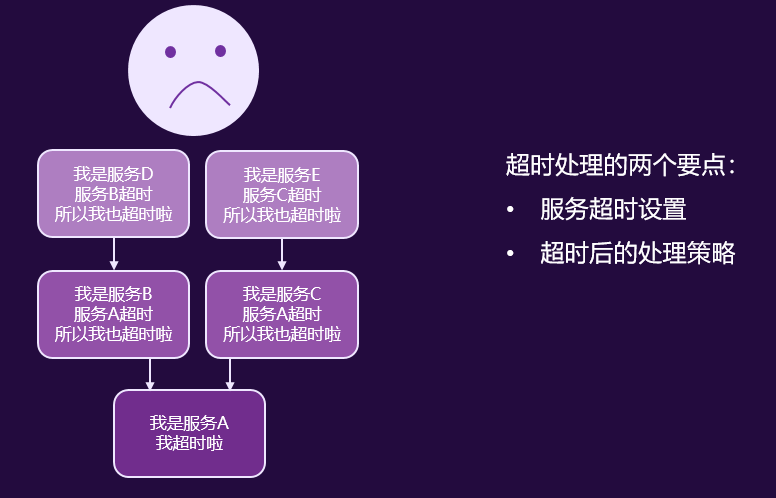
应对方案:
超时时间设置:服务刚上线时,可以根据压测情况预估一个值;
服务上线后再根据实际监控进行修改,比如设置99%的请求响应时间为超时时间。
超时后的处理策略:
如果不是核心服务,可直接超时返回失败。
如果是核心服务,可以设置相应的重试次数.
示例:
配置服务超时时间
设置Http请求超时时间
设置数据库连接超时、SQL执行超时
代码控制超时时间(例如:Polly的Timeout策略)
.NET技术架构下的高可用性改进-重试补偿
业务场景:
实际线上应用中,假如遇到网络抖动、发布重启、数据库阻塞超时等情况,都有可能引起服务调用失败。
应对方案:
通过失败重试、异常后的补偿,尽可能地保证业务可用。
重试情况下:业务要保证幂等性、保证最终一致性。
示例:
服务失败重试策略
消息发送、消费失败重试、补偿
代码层面失败重试补偿(例如:Polly的Retry策略)
高可用改进还有很多技巧,这里不一一详细给大家赘述了。
通过对系统进行全面的高可用性改进,提升了我们对线上系统的信心!
四、 展望和规划
2019年,我们启动了混沌工程实践,逐步建立了混沌工程的自有方法论和体系,通过近一年的混沌工程实践,混沌工程文化逐渐被开发团队所认可。目前,混沌工程已经逐步过渡到线上生产环境进行(这来自于足够的信心和把握)。但这只是一个起步,未来:
- 正式的混沌工程团队:通过多团队配合、保障资源的持续投入
- 覆盖所有的关键核心应用:让混沌工程深入到每个产品
- 坚持O2O混沌工程实践:线下演练、线上验证,更可控
- 混沌事件注入工具:ChaosBlade for .NET,工具让混沌工程更高效
- 持续的混沌实验:持续进行、持续改进
目标:通过混沌工程揭示问题、解决问题、形成闭环,不断提升系统高可用性。
以上是本次China.NET Conf 2019的技术专题,分享给大家。
周国庆
2019/11/15

 浙公网安备 33010602011771号
浙公网安备 33010602011771号