

深度学习(ACNet重参数化)
和RepVGG类似,ACNet也是通过重参数化提高推理性能。
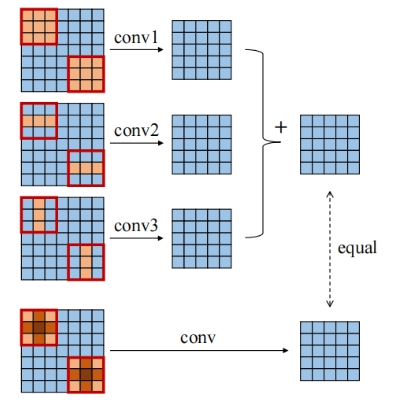
RepVGG是将3*3结构,1*1结构和直连结构并联在一起,而ACNet是将3*3结构,3*1结构和1*3结构并联在一起,最终在推理时融合为一个3*3结构。
形式如下图:
下面代码是按照自己的理解实现的重参数化Block,分为训练和部署两个分支,结果通过了allclose验证。
import torch import torch.nn as nn class AcNetBlock(nn.Module): def __init__(self, channels, deploy): super(AcNetBlock, self).__init__() self.deploy = deploy self.channels = channels self.conv3x3 = nn.Conv2d(channels, channels, kernel_size=3, stride=1, padding=1, bias=True) self.bn3x3 = nn.BatchNorm2d(channels) self.conv3x1 = nn.Conv2d(channels, channels, kernel_size=(3,1), stride=1, padding=(1,0), bias=True) self.bn3x1 = nn.BatchNorm2d(channels) self.conv1x3 = nn.Conv2d(channels, channels, kernel_size=(1,3), stride=1, padding=(0,1), bias=True) self.bn1x3 = nn.BatchNorm2d(channels) if deploy == False: self.conv3x3.weight.data = torch.randn(channels, channels, 3, 3) self.conv3x3.bias.data = torch.randn(channels) self.bn3x3.weight.data = torch.randn(channels) self.bn3x3.bias.data = torch.randn(channels) self.conv3x1.weight.data = torch.randn(channels, channels, 3, 1) self.conv3x1.bias.data = torch.randn(channels) self.bn3x1.weight.data = torch.randn(channels) self.bn3x1.bias.data = torch.randn(channels) self.conv1x3.weight.data = torch.randn(channels, channels, 1, 3) self.conv1x3.bias.data = torch.randn(channels) self.bn1x3.weight.data = torch.randn(channels) self.bn1x3.bias.data = torch.randn(channels) # Fusion conv self.fusion_conv = nn.Conv2d(channels, channels, kernel_size=3, stride=1, padding=1, bias=True) self.relu = nn.ReLU(inplace=True) def forward(self, x): if self.deploy == False: x1 = self.conv3x3(x) x1 = self.bn3x3(x1) x2 = self.conv3x1(x) x2 = self.bn3x1(x2) x3 = self.conv1x3(x) x3 = self.bn1x3(x3) x = x1 + x2 + x3 else: x = self.fusion_conv(x) return self.relu(x) def reparam3x3(self): conv_w = self.conv3x3.weight conv_b = self.conv3x3.bias bn_w = self.bn3x3.weight bn_b = self.bn3x3.bias bn_w = bn_w.div(torch.sqrt(self.bn3x3.eps + self.bn3x3.running_var)) fusion_w = torch.mm(torch.diag(bn_w), conv_w.view(self.channels, -1)).view(self.channels,self.channels,3,3) fusion_b = bn_w * (conv_b - self.bn3x3.running_mean) + bn_b print(fusion_w.shape,fusion_b.shape) return fusion_w, fusion_b def reparam3x1(self): conv_w = self.conv3x1.weight conv_b = self.conv3x1.bias bn_w = self.bn3x1.weight bn_b = self.bn3x1.bias bn_w = bn_w.div(torch.sqrt(self.bn3x1.eps + self.bn3x1.running_var)) fusion_w = torch.mm(torch.diag(bn_w), conv_w.view(self.channels, -1)).view(self.channels,self.channels,3,1) w = torch.zeros(self.channels, self.channels, 3, 3) w[:,:,:,1] = fusion_w.squeeze(3) fusion_b = bn_w * (conv_b - self.bn3x1.running_mean) + bn_b print(w.shape,fusion_b.shape) return w, fusion_b def reparam1x3(self): conv_w = self.conv1x3.weight conv_b = self.conv1x3.bias bn_w = self.bn1x3.weight bn_b = self.bn1x3.bias bn_w = bn_w.div(torch.sqrt(self.bn1x3.eps + self.bn1x3.running_var)) fusion_w = torch.mm(torch.diag(bn_w), conv_w.view(self.channels, -1)).view(self.channels,self.channels,1,3) w = torch.zeros(self.channels, self.channels, 3, 3) w[:,:,1,:] = fusion_w.squeeze(2) fusion_b = bn_w * (conv_b - self.bn1x3.running_mean) + bn_b print(w.shape,fusion_b.shape) return w, fusion_b def reparam(self): w_3x3, b_3x3 = self.reparam3x3() w_3x1, b_3x1 = self.reparam3x1() w_1x3, b_1x3 = self.reparam1x3() self.fusion_conv.weight.data = (w_3x3 + w_3x1 + w_1x3).clone() self.fusion_conv.bias.data = (b_3x3 +b_3x1 + b_1x3).clone() x = torch.randn(1, 20, 224, 224) net1 = AcNetBlock(20, False) torch.save(net1.state_dict(), "acnet.pth") net1.eval() y1 = net1(x) net2 = AcNetBlock(20, True) net2.load_state_dict(torch.load("acnet.pth")) net2.reparam() net2.eval() y2 = net2(x) print(y1.shape,y2.shape) print(torch.allclose(y1, y2, atol=1e-4)) torch.onnx.export(net1, x, "acnet.onnx", input_names=['input'], output_names=['output']) torch.onnx.export(net2, x, "acnet_deploy.onnx", input_names=['input'], output_names=['output'])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号