【刘知远NLP课 整理】Phrase & Sentence & Document Representation
【刘知远NLP课 整理】Phrase & Sentence & Document Representation
There are multi-grained semantic units in natural languages such as word, phrase, sentence, document. We have seen how to learn a word representation in link. In this post, we will focus on phrase, sentence and document representation learning.
Phrase Representation
Suppose a phrase \(p\) is composed by two words \(u\) and \(v\). The phrase embedding \(p\) is learned from its words' embedding, \(u\) and \(v\). Phrase representation methods can be divided into three categories: additive models, multiplicative models and others.
Additive Models
-
Vector addition:\(\boldsymbol{p}=\boldsymbol{u}+\boldsymbol{v}\)
-
Weight the constituents differentially in the addition: \(\boldsymbol{p}=\alpha \boldsymbol{u}+\beta \boldsymbol{v}\)(where 𝛼, 𝛽 are scalars)
-
A linear function of the Cartesian product: \(\boldsymbol{p}=A \boldsymbol{u}+B \boldsymbol{v}\)(where 𝐴, 𝐵∈\(ℝ^{(𝑑×𝑑)}\) are matrices)
Multiplicative Models
-
Element-wise multiplicative:\(\boldsymbol{p}=\boldsymbol{u}\) о \(\boldsymbol{v}\)
-
A linear function of the tensor product:\(\boldsymbol{p}=\boldsymbol{C u} \boldsymbol{v}\)(𝑪∈\(ℝ^{(𝑑×𝑑×𝑑)}\) is a tensor of rank 𝑑)

Considering Combination Rule
In the above models, all phrases use the same combination rules. However, language is much more complicated. Such as "very good" cannot be simply represented as "apple tree" by using the same linear combination of each single parts. So we should make composition matrices type-specific, which means phrases with different types use different composition matrices.
Phrases can be divided by type as
- Adjective-Noun: e.g., red apple, green tree
- Noun-Noun: e.g., tomato noodle, apple tree
- Verb-Object: e.g., have fun, eat apples
- Other: e.g., take off, put on
We use different parameters according to different types:
- Additive
- Multiplicative
- Others
These simple models we've mentioned connot fully capture the compositional meanings of phrases, because these models are proposed under the assumption that the meaning of a phrase can be represented by the linear combination of its parts. In addition, most of these models cannot capture the semantics of long text (i.e. sentences or documents) whose combination rules are much more complicated. Thus the neural network is needed.
Sentence Representation
Let's review the definition of language model and then introduce two common NN architectures.
Language Model
Language Modeling is the task of predicting the upcoming word. It can be formulated as \(P\left(w_{n} | w_{1}, w_{2}, \cdots, w_{n-1}\right)\).
The most famous language model is N-gram Model, which collects how frequent different n-grams are and use these to predict next word. e.g. 4-gram model: \(P\left(w_{j} | \text {never to late to}\right)=\frac{\text {count}\left(\text {too late to } w_{j}\right)}{ \text { count(too late to } )}\). However, N-gram model needs to store count for all possible n-grams so model size is \(𝑂(e^𝑛)\). Another problem is that traditional statistical models like N-gram will suffer the sparsity problem, which means it cannot handle new expressions.
In order to solve these problem, we need to use neural architectures.
Althought we can simply apply a MLP(Multi Layer Perceptron), but it is inefficient to adapt the change of order and unable to modify a variable length sentence as well. Therefore, the main types of neural network we use are Recurrent Neural Network(RNN) and Convolutional Neural Network(CNN).
Recurrent Neural Network (RNN)
RNN introduces a biological concept into neural networks, called sequential memory, which makes RNN can remember the past and its decisions are influenced by what it has learnt from the past. The memory stored in RNNs is changed dynamically during data processing.
A RNN cell takes the input value \(x_i\) and hidden state (memory) of last step \(h_{i-1}\) as input, and update the hidden state vector like a single-layer neural network. Then it generates output of this time-step according to the hidden state. The hidden states share the same parameters, so RNN can process sequences with no limited length.

This picture shows how RNN works as a language model:
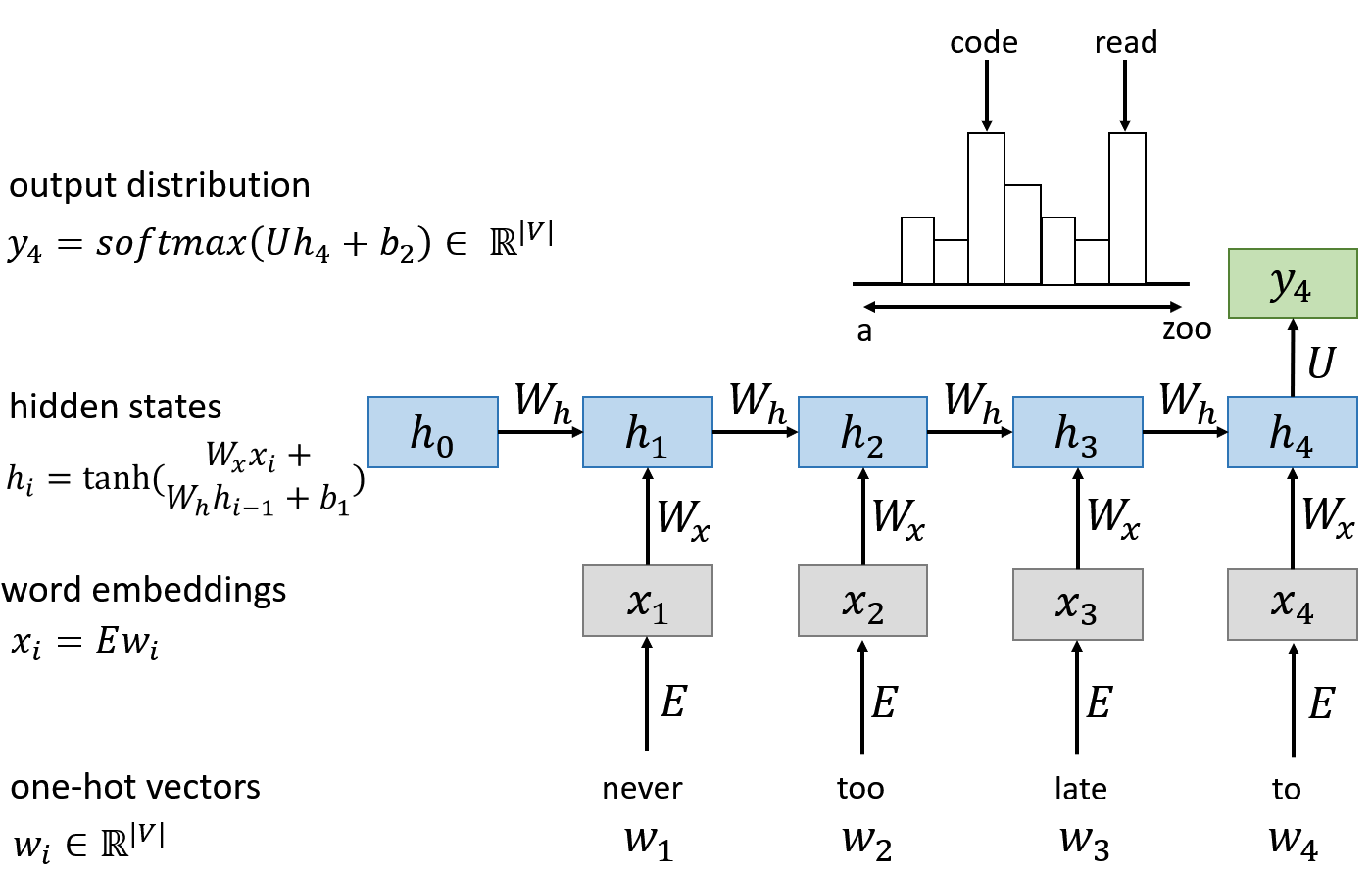
However, the recurrent computation is slow (the time complexity is O(n) ).
Besides, it's difficult for RNN models to access information from many steps back.
Further more, in many applications such as speech recognition and machine translation where we already have the whole sequence and we want to have an output depending on the whole input sequence. In this case, bidirectional RNNs are useful, which puts two RNNs from opposite directions together. The input sequence is fed in normal time order for one network, and in reverse time order for another network. Then, the outputs of the two networks are concatenated at each time step as the joint hidden states for prediction.
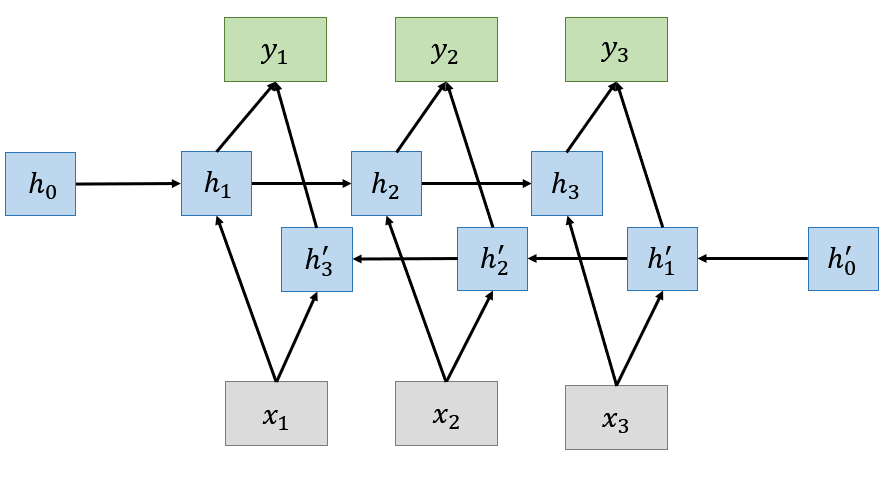
In order to achieve better performance, similar to the neural network, we can stack multiple layers of Bidirectional RNNs together to form a complex deep bidirectional RNN.

Due to the deep RNNs are quite computationally expensive to train, you don't usually see these stacked up to be more than 3 layers.
Convolutional Neural Network (CNN)
A CNN model can be divided into four parts: input layer, convolutional layer, max-pooling layer and non-linear layer.
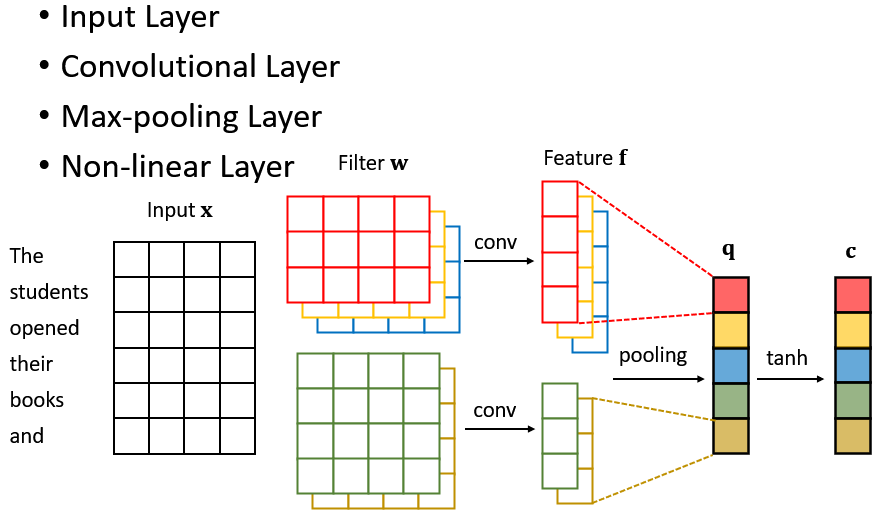
In the first layer the input layer, we need to transform words into input representations via word embeddings.
Next, in the convolution layer, we extract feature representation from input representation via a sliding convolving filter. Assuming the input window are \(h\) width, each step of convolution operation extracts feature from a \(h\)-gram phrase via a dot product operation, then the filter moves to the next \(h\)-gram phrase until it goes through all possible \(h\)-gram phrases.
In the third step, we apply a max-pooling operation over feature vector and take the maximum value \(q\) as the feature corresponding to this particular filter.
Finally, in the non-linear layer, we put the feature \(q\) go through tanh to produce the output.
As we have seen, the filter with \(h\) can extract features of h-gram phrases. Due to the length of phrases is not fixed, it is impossible to capture the features of all phrases with only one filter.
Therefore, we can apply multiple filters to capture different n-gram patterns in a sentence as the picture shows.
CNN has less parameters then RNN and it has better parallelization within sentences, but it can only extracting local and position-invariant features.
Document Representation
Both RNN and CNN are not powerful enough to capture information from a long document which consists of hundreds of words.
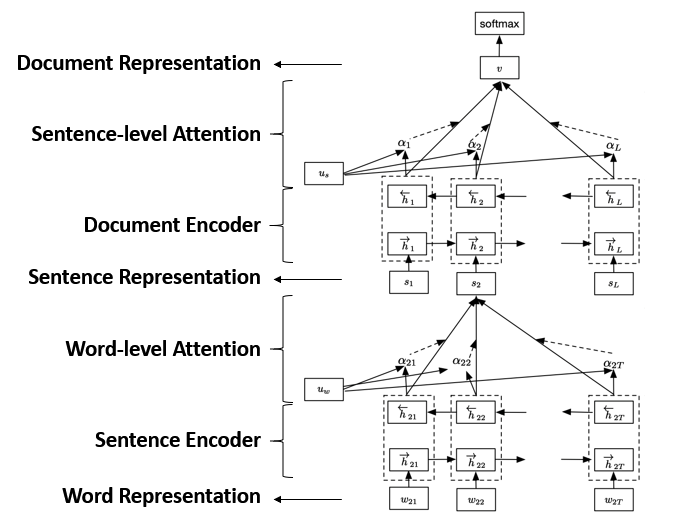
One way to solve this is using Hierarchical Structured Network.
First, we split the document into several sentences. Then we learn each sentence representation from word representation with an encoder such as CNN or RNN.
Afterwards, we use another encoder to adaptively encode semantics of sentences and their inherent relations into document representations.
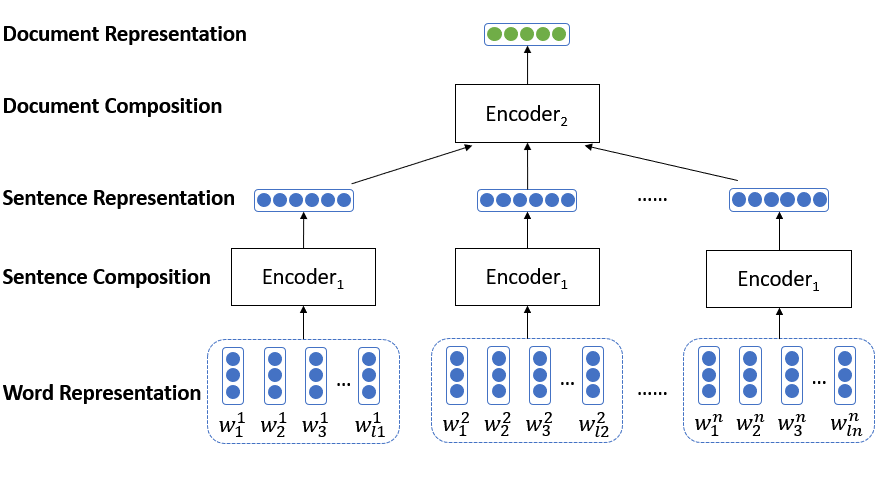
This model has a hierarchical structure that mirrors the hierarchical structure of documents, and outperforms standard RNN in many document modeling tasks.
However, the problem of this model is that it treats each word in sentences and each sentence in documents equally. In practice, this is unreasonable. For example, in a sentence, conjunctions usually don't have much information, and in a document, usually the first and the last sentences have the most important information.
Therefore, Hierarchical Attention Network was proposed.
Compared to the model we mentioned before, HAN introduces two levels of attention mechanisms, corresponding to the two level hierarchy in documents.
The attention mechanisms enable HAN to attend differentially to more or less important content when constructing the document representation. Those more important parts will gain higher weights and those less important parts gain lower.

At the word-level and the sentence-level of Hierarchical Attention Network, we apply the attention mechanism by regarding the word representation and the sentence representation as “values”, and a special context representation as “query”. Thus we get the scores for words and sentences, then calculate the sentence representation and the document representation by weighted sum.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号