TDengine IDMP 设计理念拆解:让数据“有名有姓”的三步法
为了解决“用起来”的问题,行业开始尝试自然语言查询、自动生成 SQL 等方式,并逐渐发展出 Chat BI 这类“智能问数”工具。
我们也尝试过类似路径,不断优化数据库性能、强化流计算能力、引入 AI 分析助手。但一个问题始终横亘在前:数据为什么始终“不会自己说话”?答案出现在一个凌晨的灵感中,也最终指向一个决定性的方向——我们必须重新设计工业数据管理平台。
7 月 29 日,
问题的本质:不是技术不够,而是语义缺失
这不是一时兴起的决定。过去八年,TDengine
某新能源集控中心,一天产生的数据超 5TB;某钢铁厂,测点数量数千万。但面对如此庞大的数据量,很多企业依然只能依靠固定的报表和仪表盘进行分析。业务人员提了一个新需求,还需依赖 IT 工程师用 SQL 编写查询逻辑,再反复沟通调整。数据在眼前,价值却迟迟无法兑现。
AI 能不能帮上忙?我们试过自然语言查询、自动生成 SQL、Chat BI。但很快发现,仅靠一个大模型并不能跨越这个鸿沟。AI 想要理解数据,前提是数据得有“语义”。
而当前工业数据的结构复杂、来源多样、上下文缺失严重。没有统一的数据目录,表字段名称五花八门;没有标准的单位体系,温度可能是华氏也可能是摄氏;缺乏情景化描述,某个字段“X1”到底代表电流还是电压,只有熟悉现场的工程师才知道。这些问题导致传统的 BI 工具、SQL 查询、甚至 Chat BI 等 AI 工具都无法有效发挥作用。
正是在这样的背景下,我们决定从“数据准备”的源头切入,重新设计平台架构,让整个系统从根基上彻底实现“AI-Ready”。
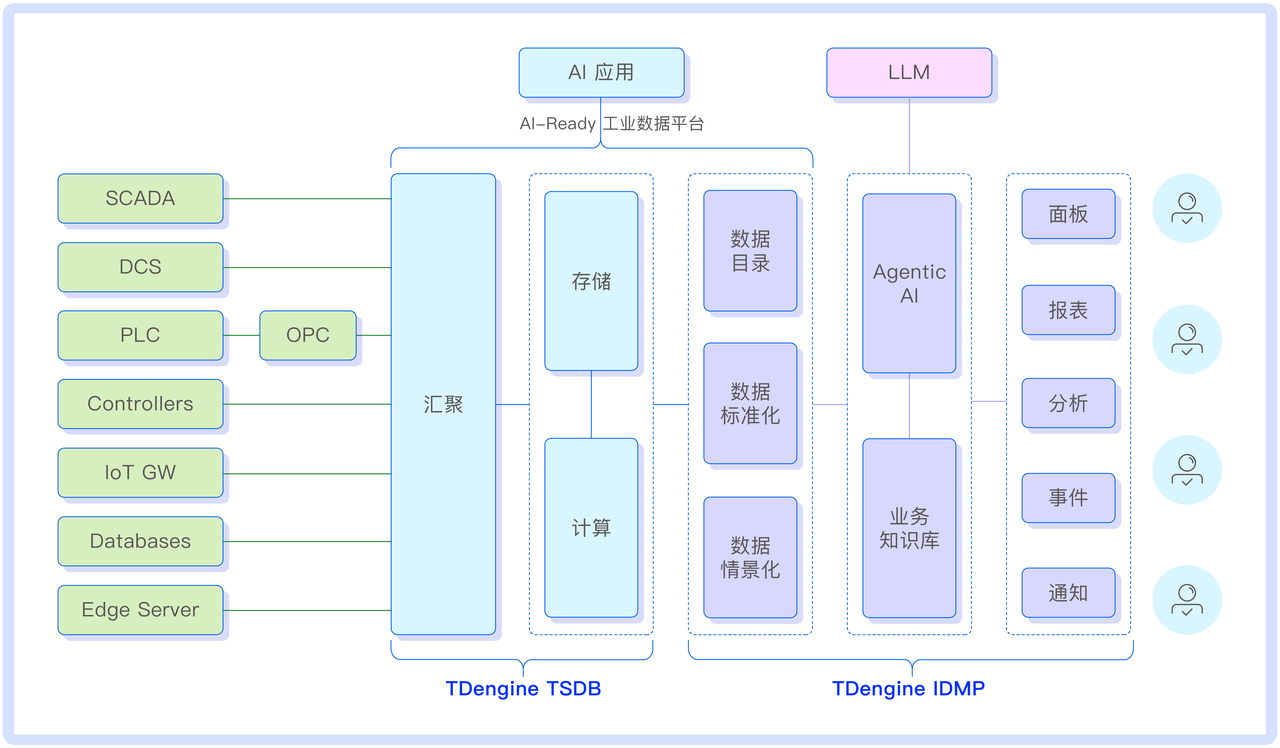
三项关键设计理念:让数据“有名有姓”,AI 才能“看懂说话”
我们最终提出的三项核心设计理念,也构成了 TDengine
设计理念一:构建统一的数据目录
工业企业的数据本身具有清晰的层级结构,比如“工厂-车间-产线-设备-测点”。但在实际的数据系统中,这些层级往往被打碎,设备的采集点、报警指标、KPI 等信息分散在不同表结构中,缺乏统一管理。
这意味着:你不再是去找一张表、一列数据,而是在管理一个具有上下文的“对象”——这符合人脑习惯,也为 AI 提供了语义基础。

设计理念二:推进数据的标准化
很多工业系统接入的原始数据来自不同协议、不同采集系统,命名不一、单位不同、精度不一。例如,“温度”这个概念,可能被命名为 Temp、T、Temp1,也可能以摄氏度、华氏度甚至无单位标识存在。

设计理念三:实现数据的情景化
光有结构和标准还不够。工业数据往往只有“数值”,却缺乏“背景”。一个指标是否异常,不仅取决于它的数值本身,还要看它处于什么状态、关联哪些事件、上下游是否也发生了变化。

“无问智推”:数据分析从拉到推的范式跃迁
传统数据分析模式本质上是“请求-响应”:你问什么,系统答什么——即便加上自然语言,也是“有问才有答”。而 IDMP
我们借助大语言模型的泛知识能力、上下文感知能力,将业务语义“压进”平台,使 AI 不仅能理解数据的含义,还能生成分析思路与可执行任务。某种程度上,这是工业数据平台进入“抖音模式”的开始:用户不再搜索,而是被推荐;不再拉取,而是被“推送”;不是靠经验,而是靠智能体的辅助决策。
可能大家有个疑问:为什么不是传统工业软件巨头来做 IDMP
而现在,有了 AI 的加持,我们终于可以把 TDengine
AI 原生,平台重塑:我们迈出的第一步
-
零代码建模能力,快速构建数据目录
-
支持标准化模板、元信息配置、数据上下文绑定
-
内嵌 LLM 智能体,支持“无问智推”的面板与分析任务生成
-
与 TDengine
基于这些能力,TDengine
这只是开始。未来,我们还将推出数据模型版本控制、根因分析报告自动生成、地图与组态功能支持等多个创新模块,并计划支持连接更多第三方数据库,进一步提升系统兼容性与行业适配力。
在 AI 重塑一切的今天,数据平台也应焕然一新。TDengine

 浙公网安备 33010602011771号
浙公网安备 33010602011771号