
Pseudo-Simulation for Autonomous Driving
Pseudo-Simulation for Autonomous Driving
Abstract
Existing evaluation paradigms for Autonomous Vehicles (AVs) face critical limitations. Real-world evaluation is often challenging due to safety concerns and a lack of reproducibility, whereas closed-loop simulation can face insufficient realism or high computational costs. Open-loop evaluation, while being efficient and data-driven, relies on metrics that generally overlook compounding errors. In this paper, we propose pseudo-simulation, a novel paradigm that addresses these limitations. Pseudo-simulation operates on real datasets, similar to open-loop evaluation, but augments them with synthetic observations generated prior to evaluation using 3D Gaussian Splatting. Our key idea is to approximate potential future states the AV might encounter by generating a diverse set of observations that vary in position, heading, and speed. Our method then assigns a higher importance to synthetic observations that best match the AV's likely behavior using a novel proximity-based weighting scheme. This enables evaluating error recovery and the mitigation of causal confusion, as in closed-loop benchmarks, without requiring sequential interactive simulation. We show that pseudo-simulation is better correlated with closed-loop simulations (R^2=0.8) than the best existing open-loop approach (R^2=0.7). We also establish a public leaderboard for the community to benchmark new methodologies with pseudo-simulation. Our code is available at https://github.com/autonomousvision/navsim.
Comments
现有的自动驾驶的评测方法有很多问题。
- 真实世界的路测往往由于安全问题和缺乏可重复性而具有挑战性
- 闭环仿真模拟可能面临真实感不足或计算成本高的问题
- 开环评测虽然是高效的和数据驱动的,但是其指标往往忽视累积误差即无法评估算法从错误轨迹中恢复的能力,也很难和真实路测结果对应在一起。
Q&A
1. pseudo-simulation 的 pipeline 是怎样的?
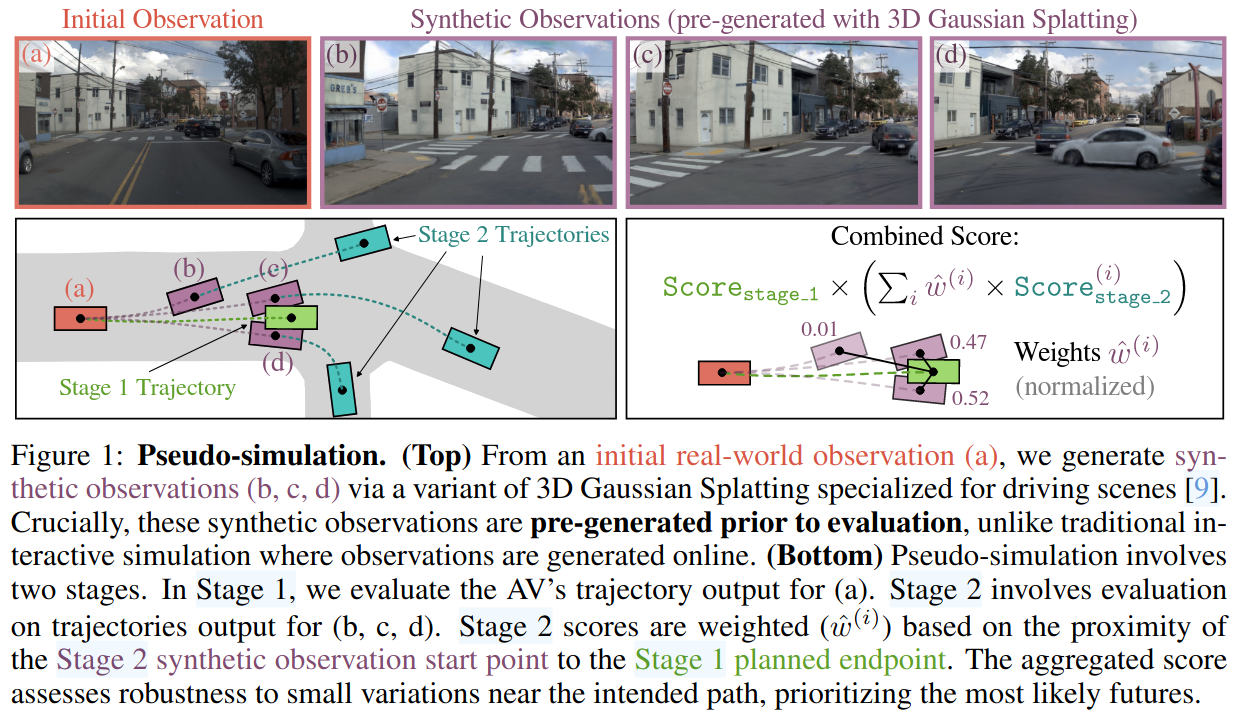
整体 pipeline 分为两阶段。阶段 1,使用原始数据作为模型输入,在阶段 2,生成若干图像作为模型输入,最终得分为阶段 1 和阶段 2 的融合。
阶段 1: Initial Observations
使用测试数据集中的观测作为 av 算法输入,得到自车未来 4s 的轨迹,然后生成一个未来时间段内的一个简化的场景 BEV 表征,得到一个得分以及在阶段 2 需要用到的 endpoint。
BEV Simulation
使用单车运动学模型和 LQR 控制器执行预测的 4s 轨迹。其他 agents 基于 IDM 对自车做出反应。
和标题 BEV Simulation 好像无关,可能是想表达自车与其他 agents 是在 bev 下预测控制的,不涉及高度 z?
Extended PDM Score
是对 navsim 中的 PDMS 的扩展
PDMS:
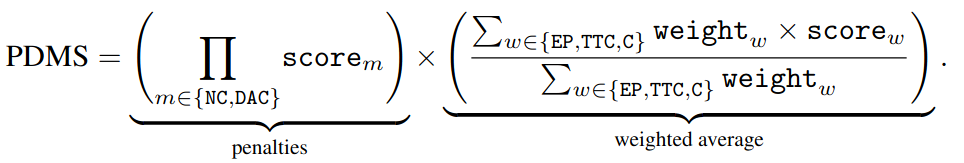
PDMS 由惩罚项和得分项两部分组成。
Penalties
惩罚自车不合理的行为,避免碰撞以及停留在道路上对于运动规划来说是必要的,因为它可以确保遵守交通规则以及行人和道路使用者的安全。
因此,对于和交通参与者发生碰撞,或者驶出可行驶区域,与护栏等障碍物碰撞的行为:NC(no collision), DAC (drivable area compliance), 这两项得分分别为 0,这会直接导致这一帧的 PDMS=0。与静态目标碰撞的得分 \(score_{NC}=0.5\)
Weighted Average
一些得分的加权平均: ego progress (EP), time-to-collision (TTC), and comfort (C)
EPDMS
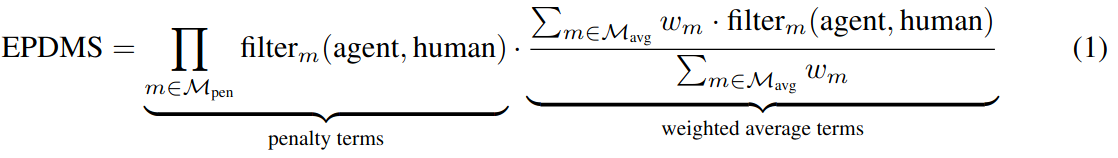
与 PDMS 类似,EPDMS 由惩罚项和得分项两部分组成,增加了一些对惩罚项和得分项:
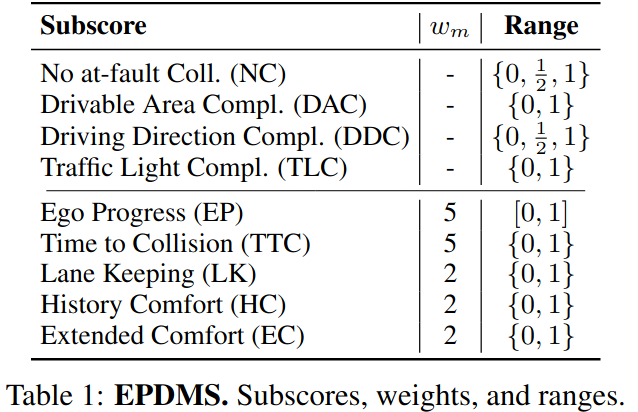
同时引入了滤波机制,防止对错误但合理的行为做出惩罚:

\(m\) 表示 PDMS 中的惩罚函数或者得分函数。如果在同一场景中人类专家驾驶员也实施了违反规则的行为,即 \(m(human)=0\),则忽略该惩罚。这避免了因标签噪声或有效行为而受到惩罚的违规行为,例如短暂地进入对面车道以绕过静态障碍物。
阶段 2: Synthetic Observations
在阶段 2,将预先生成的合成观测输入给 av 算法,重复阶段 1 计算得分,因为算法的输入是合成的,所以这个得分相对于阶段 1 来说不是很可信,根据阶段 2 轨迹起始点和阶段 1 轨迹的终止点之间的距离来确定阶段 2 得分对于最终得分的贡献占比,这就优先考虑了更有可能的未来。
一些生成场景例子:

起始点采样 Start Point Sampling
这是一个评测前的预处理缓解,与阶段 1 的轨迹无关,每一个阶段 2 的观测包含一个合理的起始点,一个 heading,和对应的运动历史,以及多视角相机图像。
对于测试集中的每一帧,在 4s 后的自车位置附近进行采样:
横向上,两边隔 0.5m 采样,共采样 2m;
纵向上,每隔 5m 采样,纵向上的采样范围覆盖了车辆最小刹车距离到最远可以到达距离(假设 4s 内最大加速度 4m/s2),那么速度越高可能的采样点就越多,实际中设定纵向最多采样 20 个点。
Heading and History Generation
对于每个采样的起始点,通过将其匹配到人类驾驶数据集中的最近轨迹来生成合理的航向和运动历史。这个匹配的过程主要是过滤掉不合适的轨迹:
- 速度差异大于 1m/s,加速度大于 1m/s2,heading 相比于专家差异大于 20 度。
- 去除不满足 EPDMS 中约束的起始点
- 如果滤波后,合理的合成观测不足 5 个,就去掉这个场景
需要看代码,论文描述不是很清楚
Neural Reconstruction and Rendering
使用当时 SOTA 的方法 MTGS: Multi-Traversal Gaussian Splatting 来做动态场景重建,因为数据集中很少有在相同位置处的轨迹,所以只使用一条轨迹来重建,并使用一个半自动化的滤波步骤来丢弃掉视觉质量低的场景。
Score Aggregation
对于每一个仿真观测单独计算 EPDMS,使用两个聚合函数得到最终的得分。
\(s_1\) 表示阶段 1 的得分,使用 \(\mathcal{A}_2(\{s_2^i\},\{x^i\},\hat{x})\) 对阶段 2 中的各个合成观测的得分进行聚合,具体的:
\(\hat{x}\) 表示基于阶段 1 的 4s 轨迹预测,得到的 4s 后的自车位置;
\(s_2^i\) 表示阶段 2 采样得到的各个起始点 \(x^i\) 的分数。
经过实验,\(\mathcal{A}_1\) 选择为简单的乘法,\(\mathcal{A}_2\) 选择核方差为 \(\sigma^2\) 的高斯加权平均,采样起始点距离阶段 1 的终点位置越近,对应得分权重越高:
2. 怎样解决现有评测方法中存在的问题的?
现有的评测方法主要可以分为两类:闭环和开环。
闭环评测
闭环评测时将车辆放在一个可交互的环境中评测模型。自动驾驶汽车在朝着既定目标前进的同时,需要保证安全。尽管现实世界的闭环部署提供了可靠的反馈,但它是昂贵的、有风险的和不可复制的,让这种方法很难去成为一种 benchmark。
作为一种可复现性更强的替代,闭环评测经常在仿真环境(比如 carla)中运行。在仿真环境中,可以实现快速迭代,生成的场景以及交通是可控的,并可以提供一些结构化的指标来做性能分析,比如碰撞、路线完成率。
但是真实世界中的驾驶在视觉上是复杂的,有各种天气环境以及不同的光照,车辆、行人等 agents 的行为是多样的,很难在仿真中完全模拟。现有的仿真平台大多是 3D 艺术人员和工程师手工构建的,限制了场景的真实感和跨场景的多样性。
开环评测
开环评测在做评测时,将规划预测的轨迹与数据集中的人类演示轨迹作比较。
数据集中的每一条数据包括传感器输入,一个目标点和人类驾驶员的未来行驶轨迹。自动驾驶模型在给定输入的情况下,预测出一条固定时间长度的轨迹,将这条轨迹与专家轨迹对比,计算轨迹点之间的位移偏差,比如 L2 距离,以及使用环境中的标注信息计算指标,比如碰撞率、与车道线的距离等。
开环评测使用的是真实数据作为输入,并且避免了交互建模的复杂性,指标比较容易计算,可以直接在大范围的数据集上应用。但是,开环仅在专家对齐的条件下做评测,不考虑分布偏移,即在开环下,规划的结果并不会真实的反应在轨迹上,即使车辆的未来位置可能发生偏移,下一帧的输入仍然与专家轨迹一致,然而在实车测试中,车辆可能会从演示轨迹中偏移出去,而开环评测没有测试其从这种偏移中恢复的能力。因此开环指标和实车表现之间的相关性较差。
除此之外,依赖自车状态作为输入的方法往往可以得到很高的开环分数 BEV-Planner ,也反映出指标的不合理,无法评测算法是否因果混淆,即图片或者输入数据 (ego 的一些状态) 是因为模型输出的规划结果才变化的,而不是先有图片的变化,模型才输出对应的规划结果
pseudo-simulation
新的范式旨在将开环评估的可扩展性与传统上仅限于交互式闭环测试的综合评估相结合。
2.1 如何评估算法从错误中恢复的能力?
如果 stage1 给出的轨迹有偏离车道或者其他错误轨迹的倾向,stage2 采样点中与这条错误轨迹被执行后的 endpoint 距离最近的得分占比会更高,以此可以评估算法从错误中恢复的能力。
2.2 与闭环评测的一致性怎么样?
为了评估 pseudo-simulation 与闭环仿真之间的相关性,使用 nuplan 的闭环仿真器对包括 rule-based 和 learning-based 在内的 83 个规划器做闭环仿真,计算闭环仿真得分 CLS, 同时计算 pseudo-simulation 的 EPDMS 得分,然后对两种得分做相关性分析,便可得到 pseudo-simulation 与真正的闭环评测之间的一致性。
因为 pseudo-simulation 是两阶段测评,每阶段都在评测一个 4s 的轨迹得分,总体是在评测(2x4=) 8s 的轨迹,因此闭环是评测 8s 的轨迹得分,最后结果:
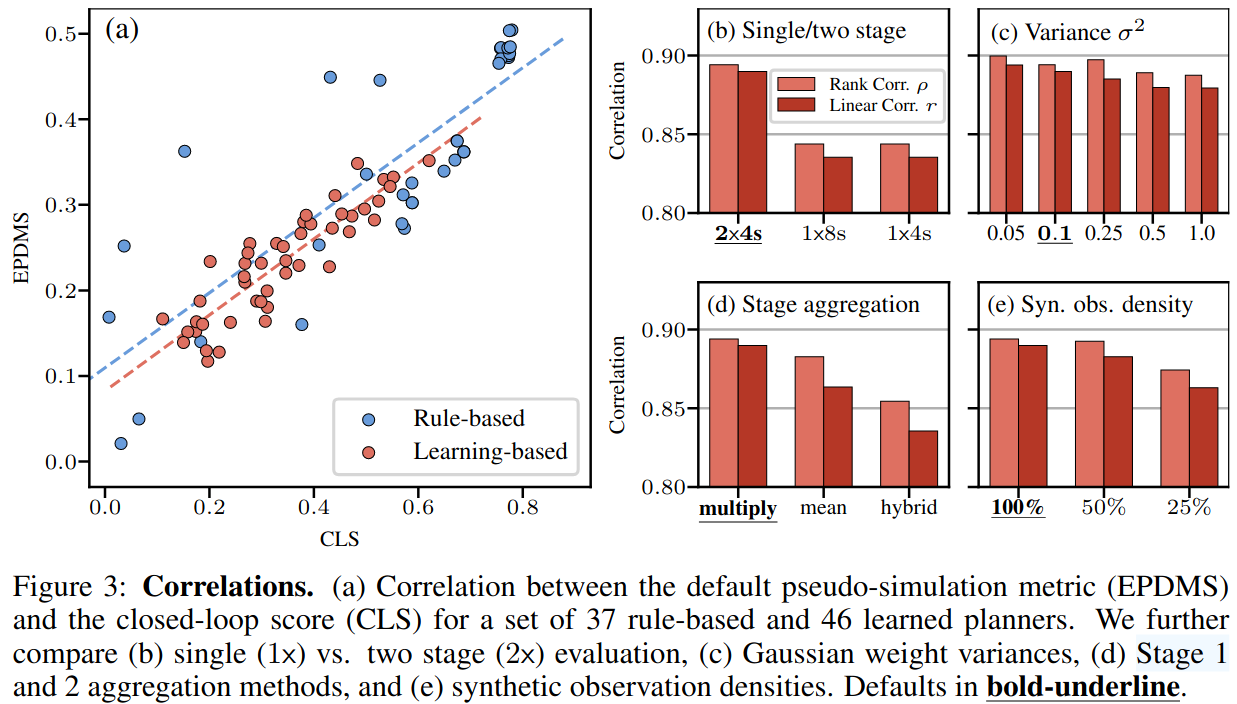
结论:
- 图 (a) 显示闭环得分 CLS 和伪闭环得分 EPDMS 之间有较强的一致性,learning-based 的方法一致性更强。此外还可以看到 EPDMS 得分普遍比 CLS 要低,这是因为 pseudo-simulation 相比闭环暴露出了算法更多的失败情况。通过引入一些合成观测,pseudo-simulation 有效地揭示了标准测试过程中可能不会遇到的边缘情况。
- 图 (b) 测试了 pseudo-simulation 两阶段 2x4s, 以及单阶段 1x8s 和 1x4s 下的得分和闭环之间的一致性,两阶段与闭环的一致性更高
- 图 (c-d) 测试阶段 2 中对不同生成观测得分进行高斯加权时使用的方差 \(\sigma^2\) 以及两阶段不同得分聚合方法对最终与闭环的一致性的影响
- 方差越小,一致性越高,即阶段 2 采样点与阶段 1 的 end point距离越近的得分占比越高,一致性越高
- 图(e) 在阶段 2 采样得到的合成观测数目与一致性的关系,在 nuPlan 闭环中测试的是一个 8s/10hz 的轨迹,每个场景 planner 会测试 80 次得到闭环得分,在 pseudo 中阶段 1 会计算一次得分,阶段 2 平均有 12 个合成输入,一共 13 次得分计算,和闭环相比是 6 倍的差距,在此基础上进行采样差距更大,尽管采样 25%,与闭环的一致性仍然高达 0.85
3. 缺点
- 指标与实车部署后的性能之间的关系仍然不清楚,评测和实车可能还是有 gap
- 需要比较多的预处理计算,主要是要先做场景重建,场景多起来后比较耗时
- 重建的结果,在新视角下仍然会有虚影
- 场景中的其他 agents 的反应仍然是规则化的,无法适应高动态场景
Pipeline

 浙公网安备 33010602011771号
浙公网安备 33010602011771号