redis数据持久化
数据持久化
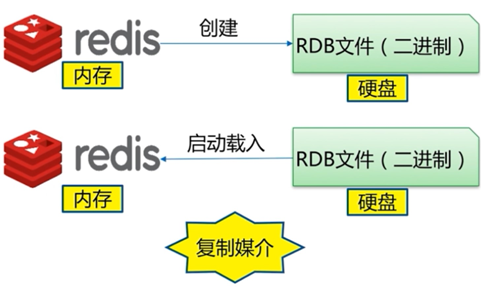
将内存中的缓存按策略保存在磁盘中,实现数据持久化。当断电时,重启开机可以直接读入磁盘的数据到内存中
两种持久化保存机制:
- 快照: RDB,相当于mysql全量备份
- 写日志: AOF,相当于mysql的binlog
RDB模式:
基于时间的快照,其默认只保留当前最新的一次快照,特点是执行速度比较快,缺点是可能会丢失从上次快照到当前时间点之间未做快照的数据
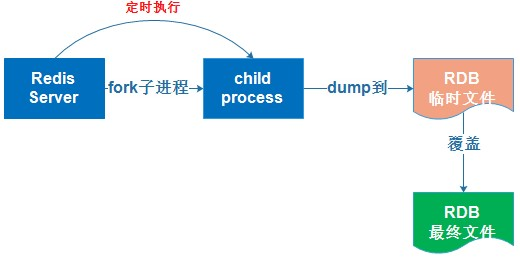
RDB bgsave工作原理:
master主进程先fork出一个子进程,使用写时复制机制,子进程将内存的数据保存为一个临时文件: tmp-.rdb,临时文件写入完成,再把原来的rdb文件替换
注意点:
- 因为直接替换RDB文件的时候,可能会出现突然断电等问题,而导致RDB文件还没有保存完整就因为突然关机停止保存,而导致数据丢失的情况.后续可以手动将每次生成的RDB文件进行备份,这样可以最大化保存历史数据
RDB模式的优缺点:
优点:
- RDB快照保存了某个时间点的数据,可以通过脚本执行bgsave(非阻塞)或者save(阻塞)命令自定义时间点备份,可以保留多个备份,当出现问题可以恢复到不同时间点的版本
- 可以最大化IO性能,因为父进程在保存RDB文件的时候唯一要做的是fork出一个子进程,然后所有操作都给这个子进程进行,父进程无需任何的IO操作
- RDB在大量数据比如几个G的数据,恢复的速度比AOF的快
缺点: #对数据完成性有要求的不推荐使用RDB
- 不能实时的保存数据,会丢失自上一次执行RDB备份到当前的内存数据
- 数据量非常大的时候,从父进程fork的时候需要时间,保存数据也要时间,可能是毫秒或者秒或者分钟,这取决于cpu是否繁忙和磁盘IO性能
RDB相关配置:
详细配置解读,看博主的: redis缓存数据库
save 900 1 900秒内有1个键数据发生更改就自动RDB备份
save 300 10
save 60 10000
dbfilename dump.rdb rdb快照文件名
dir ./ #编译安装时默认放在启动redis的工作目录,建议明确指定存入目录
stop-writes-on-bgsave-error yes 快照出错时是否禁止redis写入操作
rdbcompression yes 快照文件是否压缩
rdbchecksum yes 快照文件是否校验
实现RDB方式:
改配置文件、手动执行
- save指令: 同步,前台执行会阻塞其他命令,在,不推荐使用
- bgsave指令: 异步,后台执行不影响其他命令
- 自动: 指定规则,自动执行
- 配置文件中的save参数设置: save 900 1
- 关闭自动保存: save "" ,并注释其他save
例: rdb自动备份脚本(基于bgsave异步方式)
#!/bin/bash
. /etc/init.d/functions
BK=/backup/redis-rdb
DIR=/data/redis
FILE=/dump.rdb
PS=123456
res=`redis-cli -a $PS --no-auth-warning info Persistence|grep rdb_bgsave_in_progress|cut -d ':' -f2`
DT=`date +%F_%H:%M`
redis-cli -h 127.0.0.1 -a $PS --no-auth-warning bgsave
until [ $res -eq 0 ] ;
do
sleep 1
res=`redis-cli -a $PS --no-auth-warning info Persistence|grep rdb_bgsave_in_progress|cut -d ':' -f2'
done
[ -e $BK ] || install -d $BK -o redis -g redis
mv $DIR/$FILE $BK/dump-${DT}.rdb
action "RDB file save ok"
AOF模式(append only file):
按照操作顺序依次将操作添加到指定的日志文件当中,特点是数据安全性相对较高,缺点是即使有些操作是重复的也会全部记录,也就是文件大小只增不自动减(包括删除)
原理:
AOF和RDB一样使用了写时复制机制,AOF默认为每秒钟fsync一次,即执行的命令就保存到AOF文件当中,这样即使redis服务器发生故障的话顶多也就丢失1秒钟之内的数据
也可以设置不同的fsync策略(always),每次执行命令fsync在后台执行线程,主线程可以继续处理用户的正常请求而不受到写入AOF文件的IO影响

注意:
- 同时启用rdb、aof,恢复时aof文件优先级高于rdb文件,也就是只使用aof文件恢复
- aof默认是关闭的,第一次开启后重启,会因为aof优先级高于rdb,而默认没有aof文件存在,导致所有数据丢失
AOF 相关配置:
详细配置解读,看博主的: redis缓存数据库
appendonly yes
appendfilename "appendonly.aof" AOF文件名
appendfsync everysec aof策略配置,no为关闭,由操作系统来负责数据同步到磁盘(一般30s一次)
dir /path
no-appendfsync-on-rewrite yes 在rewrite期间,是否把新记录的追加到buffer区,主要考虑磁盘IO和请求阻塞时间
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb 触发aof rewrite的最小文件大小
aof-load-truncated yes 是否加载由于其他原因导致的末尾异常的AOF文件(主进程被kill/断电等)
开启aof方法:
第一次启动必须按顺序改,否则数据直接丢失,就要提桶跑路了(滑稽)
#先通过变量方式,临时启动aof,将数据保存
redis-cli config set appendonly yes
#然后再改配置文件,永久启动
vim /etc/redis.conf
appendonly yes
systemctl restart redis
ll -h /var/lib/redis/ #此时,就有了aof文件
数据恢复:
与mysql的二进制日志恢复误删除数据一样
博主测试过,在redis 5.0.3版本之前可以手动修改aof文件,5.0.3版本开始,数据存为二进制格式,不能再编辑
如果想和以前一样能手动编辑此文件,必须在第一次安装redis时就配置好aof-use-rdb-preamble no,不然后续再修改,文件的前面部分依然后二进制数据(当然也有办法,不过不推荐新手小白去做,因为操作不好会导致数据清零)
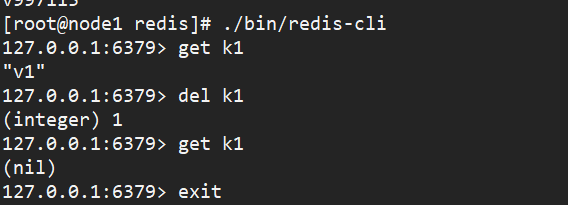
#模拟数据删除
redis-cli del k1
#修复数据,找到del行,*2代表2个指令,$3为指令索引,$2为key的索引,都要删掉
vim appendonly.aof
#修改完成后重启redis,重载aof文件后数据恢复

AOF rewrite重写:
当删除数据库中的内容时,aof文件只会记录该操作,但文件大小并不会释放,所以需要手动整理aof文件,将一些重复的、可合并的、过期的数据重写到一个新的aof文件
aof重写过程:
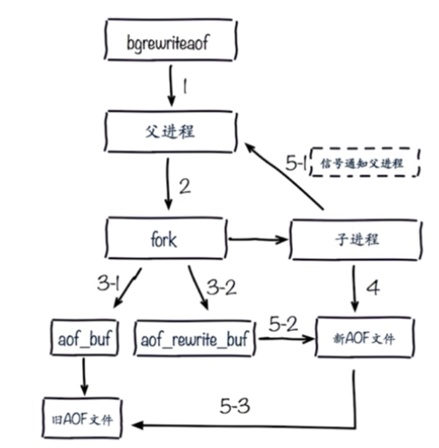
- 执行bgrewriteaof,父进程开启一个子进程来处理这个命令
- 子进程会开启两个buffer缓冲区,一个是存放当前rewrite整理数据的,一个是存放当前正在写入或后面写入redis库中的数据。前者会一直读取、整理久aof文件的数据;后者的数据直接存入到旧的aof文件中
- 子进程把rewrite缓冲区整理的数据写到临时的aof文件,写入完成后,通知父进程,再覆盖旧的aof文件
手动执行AOF重写:
BGREWRITEAOF
时间复杂度: O(N), N 为要追加到 AOF 文件中的数据数量
执行一个 AOF文件 重写操作。重写会创建一个当前 AOF 文件的体积优化版本
即使 BGREWRITEAOF 执行失败,也不会有任何数据丢失,因为旧的 AOF 文件在 BGREWRITEAOF 成功之前不会被修改
重写操作只会在没有其他持久化工作在后台执行时被触发,也就是说:
如果 Redis 的子进程正在执行快照的保存工作,那么 AOF 重写的操作会被预定(scheduled),等到保存工作完成之后再执行 AOF 重写。在这种情况下, BGREWRITEAOF 的返回值仍然是 OK ,但还会加上一条额外的信息,说明 BGREWRITEAOF 要等到保存操作完成之后才能执行。在 Redis 2.6 或以上的版本,可以使用 INFO [section] 命令查看 BGREWRITEAOF 是否被预定
如果已经有别的 AOF 文件重写在执行,那么 BGREWRITEAOF 返回一个错误,并且这个新的BGREWRITEAOF 请求也不会被预定到下次执行
从 Redis 2.4 开始, AOF 重写由 Redis 自行触发, BGREWRITEAOF 仅仅用于手动触发重写操作
手动bgwriteaof
bgrewriteaof
AOF模式优缺点:
优点:
- 安全性相对较高,默认1s一次追加数据,哪怕有故障也只会丢失1s的数据
- 根据所使用的fsync策略(fsync是同步内存中redis所有已经修改的文件到存储设备),默认是appendfsync everysec,即每秒执行一次 fsync,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync会在后台线程执行,所以主线程可以继续努力地处理命令请求)
- 能保障数据的一致性,在追加写入时,发生故障,服务恢复后redis-check-aof工具可检查
- 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中不需要seek, 即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,可以通过 redis-check-aof 工具来解决数据一致性的问题
- 重写时的操作时绝对安全的,在整理临时aof文件,新的数据可以一直写入到旧aof中,哪怕故障,丢失的仅是临时整理的aof数据,旧的是完整的且有新内容
- Redis可以在 AOF文件体积变得过大时,自动地在后台对AOF进行重写,重写后的新AOF文件包含了恢复当前数据集所需的最小命令集合。整个重写操作是绝对安全的,因为Redis在创建新 AOF文件的过程中,append模式不断的将修改数据追加到现有的 AOF文件里面,即使重写过程中发生停机,现有的 AOF文件也不会丢失。而一旦新AOF文件创建完毕,Redis就会从旧AOF文件切换到新AOF文件,并开始对新AOF文件进行追加操作
- 可用于数据重建,记录了所有的修改操作
- AOF文件有序地保存了对数据库执行的所有写入操作,这些写入操作以Redis协议的格式保存,因此 AOF文件的内容非常容易被人读懂,对文件进行分析(parse)也很轻松。导出(export)AOF文件也非常简单:举个例子,如果你不小心执行了FLUSHALL.命令,但只要AOF文件未被重写,那么只要停止服务器,移除 AOF文件末尾的FLUSHAL命令,并重启Redis ,就可以将数据集恢复到FLUSHALL执行之前的状态
缺点:
- 重复的操作会记录,aof文件要大于rdb文件
- aof在恢复大数据时,速度比rdb慢
- 根据fsync策略不同,aof速度可能慢于rdb
- bug 出现的可能性更多
---.
RDB和AOF的选择:
- 仅用来缓存,可以承受数据的少量丢失,通常生产环境只需要启用rdb即可(默认开启)
- 用来存储数据,对数据有安全性有要求,一般同时开启rdb、aof,不建议只开aof

 浙公网安备 33010602011771号
浙公网安备 33010602011771号